前言:
训练复杂度 O=E*T*Q
| 参数 | 全称 |
| E 迭代次数 | Number of the training epochs |
| T数据集大小 | Number of the words in the training set |
| Q 模型计算复杂度 | Model computational complexity |
E,T 一般都认为相同,所以这里面主要讨论Q,模型本身的训练复杂度
目录
- NN-LM
- RNN-LM
- SKIP-grame
- CBOW
一 NNLM

输入 N个词预测下一个词
1.1 模型Forward:
1 输入 N 个[d,1] 的one-hot 向量
2 concat 后
3 经过第一个线性层 torch.nn.Linear
输出[h,1]
其中参数
4 经过一个激活函数
5 经过第二个线性层 torch.nn.Linear
参数
6 经过softmax 后得到输出
1.2 Q 模型计算复杂度:
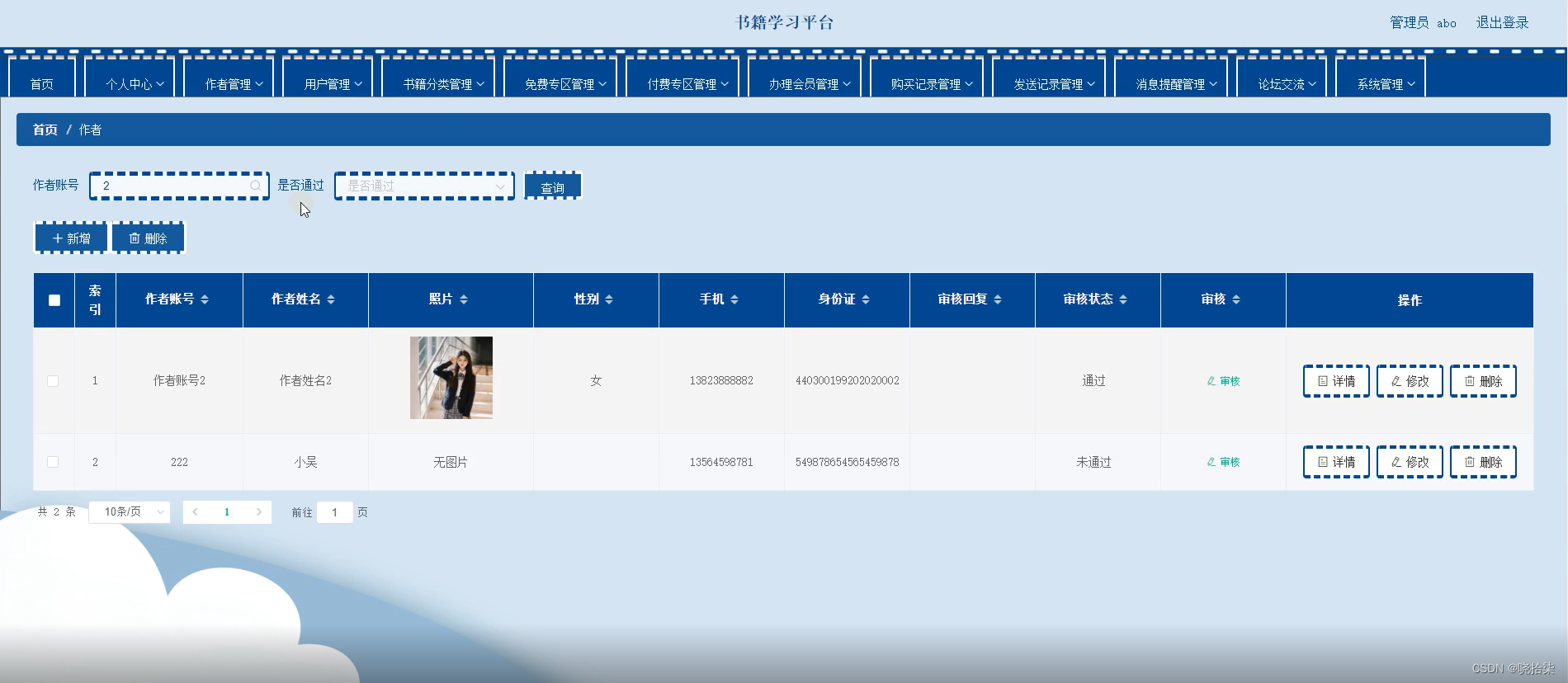
二 RNN-LM
2.1 模型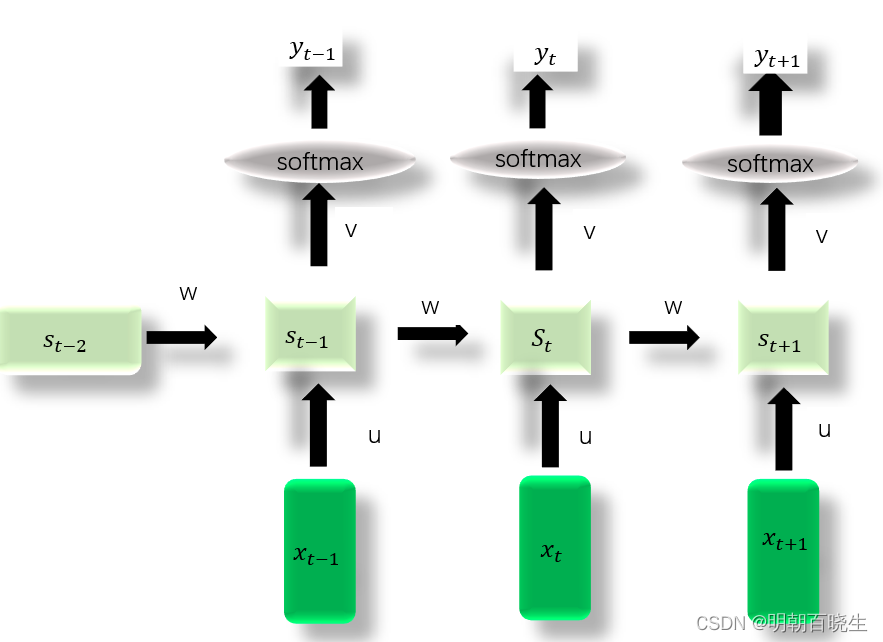
2.2 模型Forward
1 当前时刻的输入单词
2 当前时刻隐藏层
其中:
3 当前时刻的输出
其中:
所以
三 SKIP-grame

跟https://mp.csdn.net/mp_blog/creation/editor/131523503
稍微有点不一样, 前面讲的
,
这里直接用一个
代表该单词。前面博客只是为了
更深入的了解为什么要用[d,1]向量代表该单词
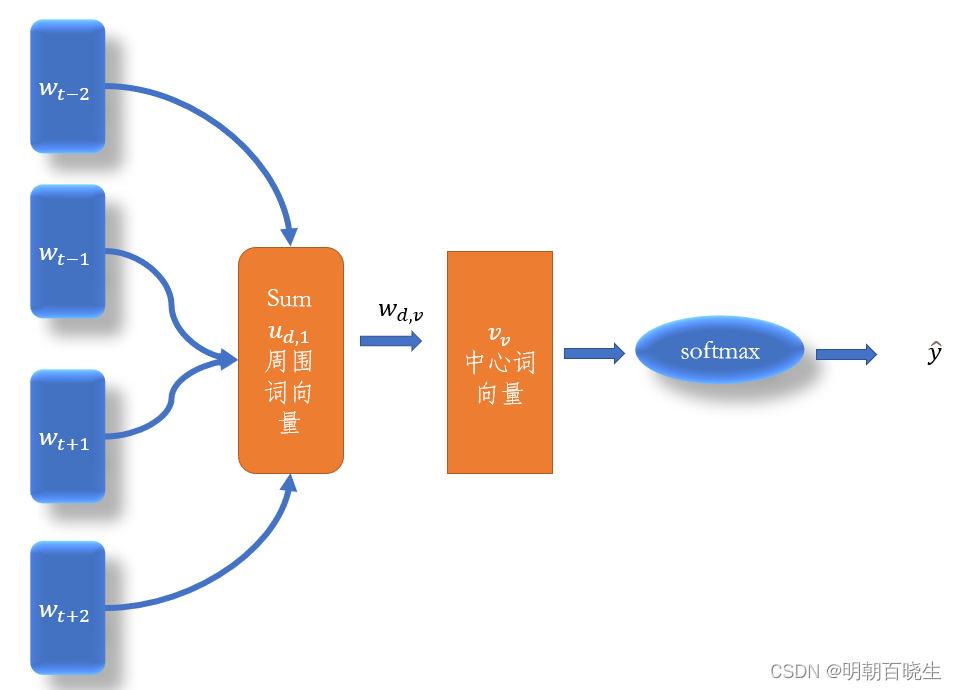
假设利用当前的中心词预测周围N个词
当为Hierarchical softmax时候
当采用 Negative Sampling 时
Q = N(d+d*(k+1))
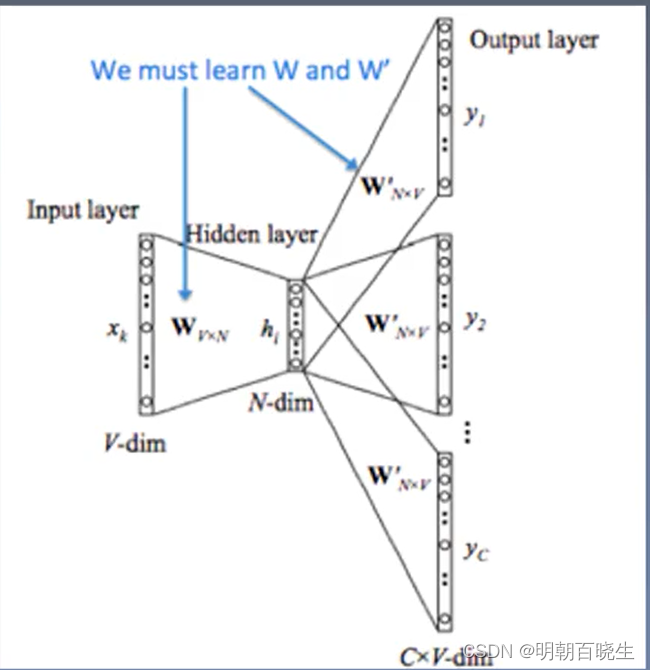
四 CBOW
层次softmax
负采样