6. Kafka-Eagle监控
Kafka-Eagle框架用于监控Kafka集群运行状况。官网https://kafka-eagle.org
6.1 Mysql
前置mysql。
6.2 Kafka环境
- 关闭集群 kf.sn stop
- 修改vim /bin/kafka-server-start.sh 并同步到其他节点
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-server -Xms2G -Xmx2G XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 XX:IniyiatingHeapOccupancyPercent=70"
export JMX_PORT="9999"
# export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
6.3 Kafka-Eagle安装
管网下载:https://kafka-eagle.org压缩包kafka-eagle-bin-2.0.8.tar.gz并解压。
在conf目录的sustem-config。properties中配置监控信息。
#kafka集群配置
efak.zk.cluster.alias=cluster1
cluster.zk.list=node1:2181,node2:2181,node3:2181/kafka
... ...
#offset存储位置
cluster1.efak.offset.storage=kafka
#cluster1.efak.offset.storage=zk
... ...
#mysql连接配置
efak.driver=com.mysql.jdbc.Driver
efak.url=jdbc:mysql://localhost:3306/kafka-eagle/?useUnicode=true
efak.username=root
efak.password=root
添加环境变量:sudo vim /etc/profile.d/my_env.sh
# kafkaEFAK
export KE_HOME=/export/server/efak
export PATH=$PATH:$KE_HOME/bin
source /etc/profile 生效
启动:注:先启动ZK以及KAFKA。 kf.sh start
停止:bin/ke.sh stop
6.3 Kafka-Eagle访问
浏览器输入ip:8048
原理:通过拦截器注入,获取数据呈现即可。
7. Kafka-Kraft模式
7.1 Kafka-Kraft架构
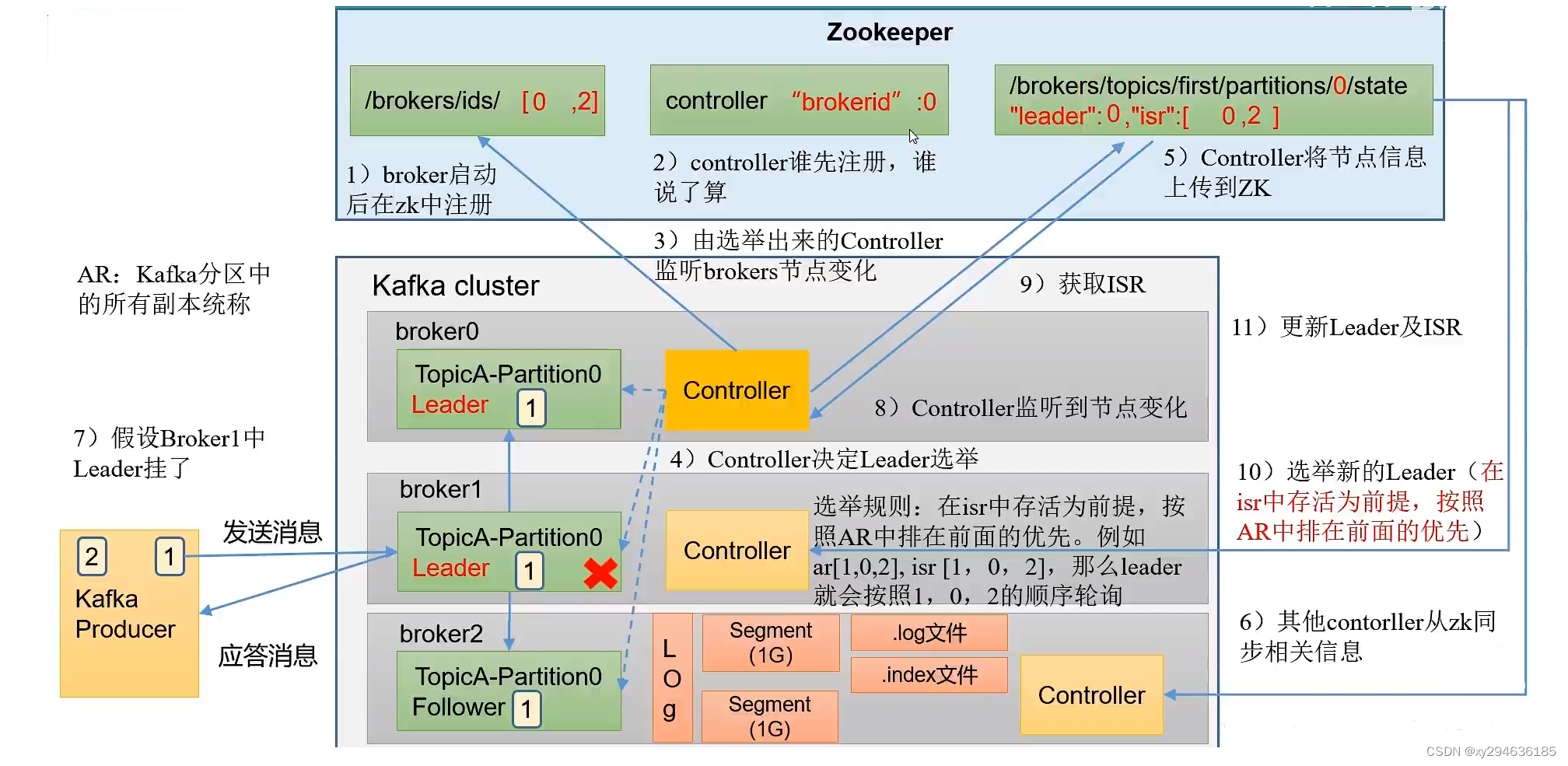
kafka2.8.0之前由zookeeper存储元数据,运行时动态选举controller,由controller进行kafka集群管理。
之后改为kfaft模式,由三台controller节点代替zookeeper,元数据存储在controller,直接进行kafka集群管理
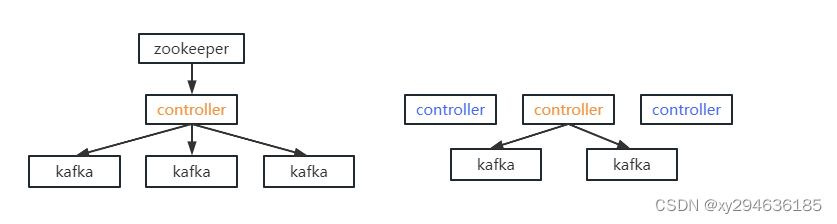
好处:
- kafka不在依赖外部框架,可独立运行
- controller管理集群时,不在从zookeeper中读取数据,集群性能提高。
- 由于不依赖zookeeper,集群扩展不再受zookeeper读写能力限制
- controller不再动态选举,而是由配置文件规定。不像之前随机controller节点高负载
7.2 kafka-kraft集群部署
- 解压kafka_2.12-3.0.0.tgz -C /export/server/
- 设置kafka软连接
- 在node1上修改/export/server/kafka/config/karaft/server.properties并同步到集群中其他节点:
process.roles=broker,controller(kafka角色:既是broker从机又是controller主机,主机类似zk功能)
node.id=1(节点node,全局唯一)
controller.quorum.voters=2@node1:9093,3@node2:9093(全controller列表)
advertised.listeners=PLAINTEXT://node1:9092(对外暴露的端口)
log.dirs=/export/server/kafka/data(数据存储地址) - 分发kafka配置,对node.id,advertised.listeners进行修改
- 初始化居群数据目录
- 首先生成存储目录唯一ID:bin/kafka-storage.sh random-uuid (eg:123456)
- 用该ID格式化kafka存储目录(其余节点):
bin/kafka-storage.sh format -t 123456 -c /export/server/kafka/config/kraft/server.properties
- 启动kafka集群node1,2,3
bin/kafka-server-start.sh -daemon config/kraft/server/properties - 停止kafka集群
bin/kafka-server-stop.sh
7.3kafka-kraft集群启停脚本
- 在home/xuyu/bin目录下创建文件kafka.sh:vim kafka.sh
#! /bin/bash
case $1 in
"start") {
for i in node1 node2 node3
do
echo "--- start $i kafka ---"
ssh $i "/export/server/kafka/bin/kafka-server-start.sh -daemon /export/serverkafka/config/kraft/server.properties"
done
};;
"stop"){
for i in node1 node2 node3
do
echo "--- stop $i kafka ---"
ssh $i "/export/server/kafka/bin/kafka-server-stop.sh"
done
};;
esac
- 添加执行权限
chmod +x kafka.sh - 启停集群命令
kafka.sh start
kafka.sh stop
8 Kafka硬件配置选择(生成调优)
8.1 场景说明
100万日活,每人每天100条日志,每天总共的日志条数是100万100条=1亿条。
处理日志速度:1亿/24小时/60分/60秒=1150条/每秒钟。
每条日志大小:0.5k-2K(取1k)。1150条/每秒钟1k=1m/s。
高峰期每秒钟:1150条*20倍=23000条。每秒数据量:20MB/s。
8.2 服务器台数选择
服务器台数 = 2 * (生产者峰值生成速率 * 副本数 / 100) + 1 = 2 *(20m/s * 2 / 100) + 1 = 3
8.3 磁盘选择
kafka 按照顺序读写:机械硬盘和固态硬盘顺序读写速度差不多。随机读写:选固态硬盘。
一天占用:1亿条 * 1k = 100G。保存3天:100G*3天/0.7=1T
建议三台服务器总磁盘大小>1T
8.4 内存选择
kafka内存=堆内存(kafka内部配置)+页缓存(服务器内存)。
- kafka堆内存建议每个节点:10-15G
vim kafka-server-start.sh:
if ["x$KAFKA_HEAP_OPTS"="x"]; then
export KAFKA_HEAP_OPTS="-Xmx10G -Xms10G"
fi
查看kakfa进程号:jps
查看kafka的GC情况:jstat -gc 进程号 ls 10(YGC:年轻代垃圾回收次数)
查看kafka的堆内存:jmap -heap 进程号(如果G1 Heap占用70%以上需要清除)
页缓存:linux系统服务器内存,1个segment(1G)中的25%的数据在内存中就好。
每个节点页缓存大小=(分区数1G25%)/节点数 = (101G25%)/3=1G。建议服务器内存大于11G。
8.5 CPU选择
num.io.threads=8:负责写磁盘的线程数,整个参数值要占总核数的50%
num.replica.fetchers=1:副本拉取线程数,这个参数占总核数的20%的1/3。
num.network.threads=3:数据传输线程数,这个参数占总核数的50%的2/3。
建议32个cpu core
8.6 网络选择
网络带宽=峰值吞吐量=20MB/s。千兆网卡即可。
100Mbps单位bit:10M/s单位是byte;1byte=8bit,100Mbps/8=12.5M/s
一般百兆网卡(100Mbps)、千兆网卡(1000Mbps),万兆网卡(10000Mbps)。
9 Kafka生产者
Updating Broker Config
read-only:Requires a broker restart for update
per-broker:May be update dynamically for each broker
cluster-wide:May be update dynamically as a cluster-wide default
9.1 Kafka生产者核心参数配置
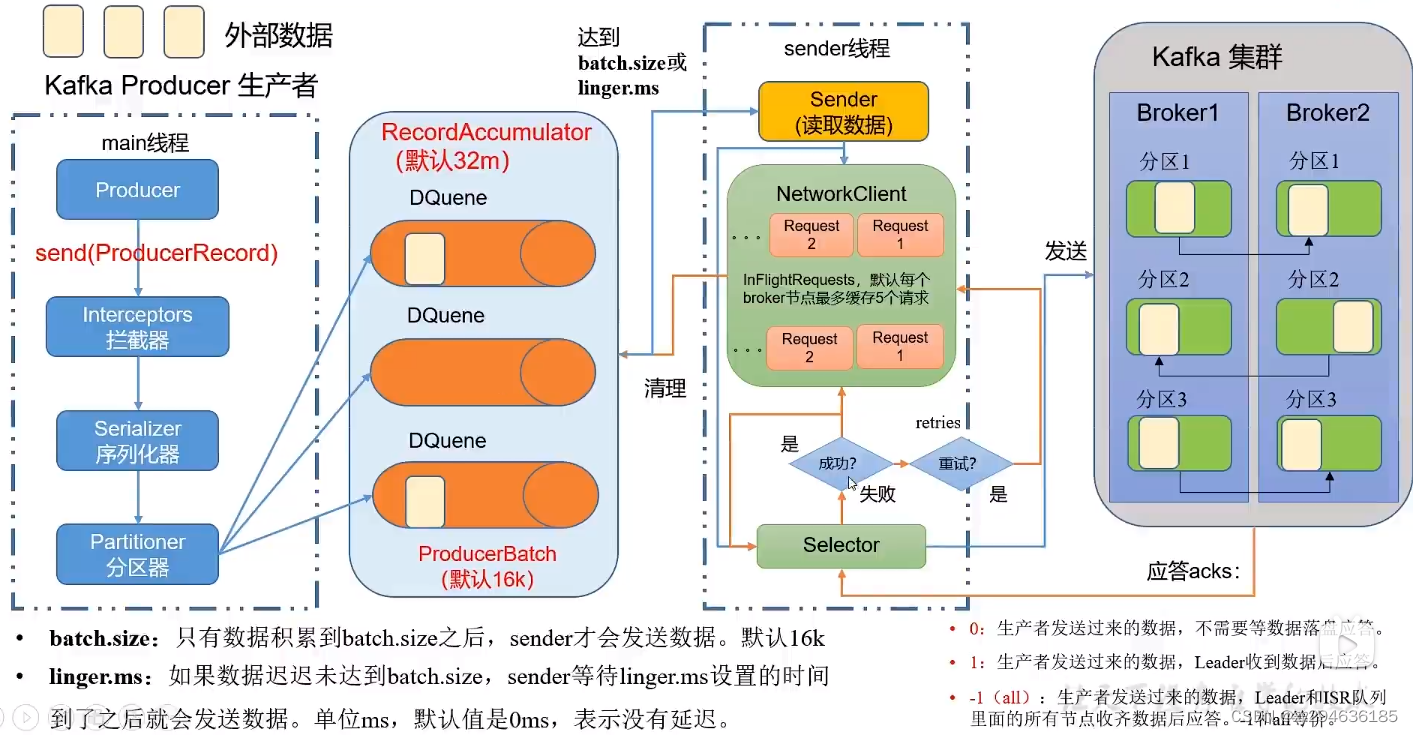
bootstrap.servers:生产者连接集群的broker地址清单,多个用逗号隔开
key/value.serializer:key和value序列化类型。全类名
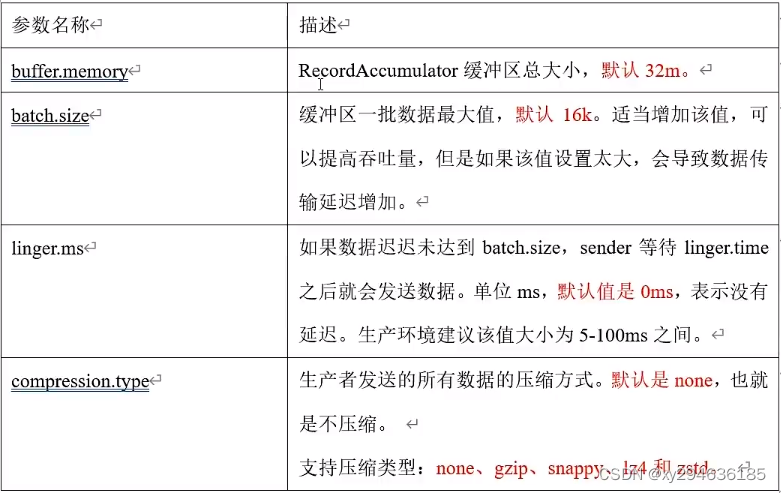
buffer.memory:RecordAccumulator缓冲区总大小,默认32m
batch.size:缓冲区一批数据最大值,默认16k,增加会导致延迟过高。
linger.ms:如果数据没到batch.size,sender的等待时间,默认0ms。一般5-100ms。
acks:生产者发来数据:0:不落盘。1:Leader落盘后应答。-1:leader和isr队列落盘后应答。
max.in.flight.requests.per.connection:允许最多没有返回ack次数,默认5,开启幂等性要保证该值为1-5的数字。
retries:当消息发送错误时重试次数,默认int_max(21亿)还要有序需设置:MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION=1否则重试此失败消息时,其他消息可能成功
retry.backoff.ms:两次重试之间的时间间隔,默认100ms
enable.idempotence:是否开启幂等,默认true
compression.type:生产者发送的所有数据压缩方式。默认none。支持类型:none,gzip,snappy,lz4,zstd
9.2 Kafka生产者如何提高吞吐量
9.3 Kafka数据去重
先开启幂等,kafka事务API:
初始化事务:void initTransactions();
开启事务:void beginTransaction()
在事务内提交已经消费的偏移量:void sendOffsetsToTransaction(Map<TopicPartition,OffsetAndMetadata> offsets,String consumerGId)
提交事务:void commitTransaction()
放弃事务:void abortTransaction()
9.4 数据有序
单分区内有序;多分区,分区间无序(实现需要在接收端按顺序排序,效率低,见前文)
10 Kafka Broker
replica.lag.time.max.ms:ISR中,follower心跳,超过阈值(默认30s)将被踢出。
auto.leader.rebalance.enable:自动leader partition平衡。默认true,建议关闭
leader.imbalance.per.broker.percentage:每个broker允许不平衡比率。默认10%
leader.imbalance.check.interval.seconds:检查leader负载是否平衡间隔,默认300s
log.segment.bytes:log划分块的大小,默认1G
log.index.interval.bytes:日志index文件(.log)索引间隔大小,默认4kb
log.retention.hours:kafka数据保存时间,默认7天
log.retention.minutes:同上,分钟级别,默认关闭
log.retention.ms:同上,毫秒级别,默认关闭
log.retention.check.interval.ms:检查数据是否超时,默认5min
log.retention.bytes:超过设置的所有日志总大小,删除最早的segment。默认-1(无穷大)
log.cleanup.policy:所有数据启用删除策略,默认delete
num.io.threads:写磁盘线程数,占总核数50%,默认8
num.replica.fetchers:副本拉取线程数,占总核数50%的1/3,默认1
num.network.threads:副本传输数据线程数,占总核数50%的2/3,默认3
log.flush.interval.messages:强制页缓存刷新条数,默认long最大值,不建议修改
log.flush.interval.ms:刷数据间隔,默认null,不建议修改
11 Kafka 消费者


bootstrap.servers:向kafka集群建立初始连接用到的host/port列表
key/value.deserializer:反序列化类型
group.id:组id
enable.auto.commit:消费偏移量,默认true
auto.commit.interval.ms:提交偏移量频率,默认5s
auto.offset.reset:当kafka没有初始偏移量或偏移量不存在,earliest(重置为最早),latest(默认,重置为最新偏移量),none(原来的量不存在则抛异常),anything(直接向消费者抛异常)
offsets.tpoic.num.partitions:consumer_offsets的分区数,默认50,不建议修改
heartbeat.interval.ms:kafka消费者与coordinator之间的心跳时间,默认3s
session.timeout.ms:kafka消费者与coordinator之间的超时时间,默认45s
max.poll.interval.ms:消费消息最大时长,默认5min
fetch.max.bytes:默认Default:50m,消费者端一批消息的最大字节数。
max.poll.records:一次poll拉取数据返回消息的最大条数,默认500
partition.assignment.startegy:消费者分区策略,Range,RoundRobin,Sticky,CooperativeSticky
12 Kafka 总体
12.1 提升吞吐量
- 提升生产吞吐量
- buffer.memory:发送消息缓冲区,默认32m
- batch.size:发送消息大小,默认16K,太卡会卡
- linger.ms:发送时间间隔,默认0,一般5-100ms
- compression.type:压缩方式,默认none,会增加cpu开销
- 增加分区
- 消费者提高吞吐量
- 调整fetch.max.bytes大小,默认50m
- 调整max.poll.records大小,默认500条
- 增加下游消费者处理能力
12.2 数据精确一次
- 生产者角度
- acks设置为-1
- 幂等性(enable.idempotence=true)+事务
- broker服务端角度
- 分区副本大于等于2(–replication-factor 2)
- ISR里应答的最小副本数大于等于2(min.insync.replicas=2)
- 消费者
- 事务+手动提交offset(enable.auto.commit=false)
- 消费者输出的目的地必须支持事务(Mysql,kafka)
12.3 合理设置分区数
- 创建一个只有1个分区的topic
- 测试这个topic的producer和consumer吞吐量
- 假设他们分别为Tp和Tc,单位是MB/s
- 假设总的目标吞吐量为Tt,那么分区数=Tt/min(Tp,Tc)
例如:生产者20m/s,消费者50m/s,期望100m/s。
分区数:100/20=5分区,建议生产环境搭建完集群进行压测,灵活调整分区。
12.4 单条日志大于1m
message.max.bytes:broker接收每批次消息最大值,默认1m
max.request.size:生产者发往broker每个请求最大值。针对topic级别设置消息体的大小,默认1m
replica.fetch.max.bytes:副本同步数据,每批次消息最大值,默认1m
fetch.max.bytes:消费者获取服务器端一批消息最大字节数,默认50m
12.5 服务器挂了
如果生产环境某个kafka节点挂了:
- 先尝试重启
- 增加内存,cpu,带宽
- 如果将整个kafka节点误删除,如果副本数大于等于2,可按照服役新节点的方式重新服役一个新节点,并执行负载均衡。
12.6 集群压力测试
- kafka压测:官方自带脚本
生产者:kafka-producer-pref-test.sh
消费者:kafka-consumer-perf-test.sh - producer压测
创建test topic:
./kafka-topics.sh --bootstrap-server node1:9092 --create --replication-factor 3 --partitions 3 --topic test
在客户端的kafka/bin下执行test:
./kafka-producer-perf-test.sh --topic test --record-size 1024 --num-records 1000000 -throughput 10000 --producer-props bootstrap.servers=node1:9092,node2:9092,node3:9092 batch.size=16384 linger.ms=0
- record-size:一条信息大小,单位字节,测试为1K
- num-records:共发送消息数,测试为100万
- throughput是每秒发送消息数,-1表示不限流,测试为1万/s
- producer-props:配置生产者相关参数:batch.size为16K
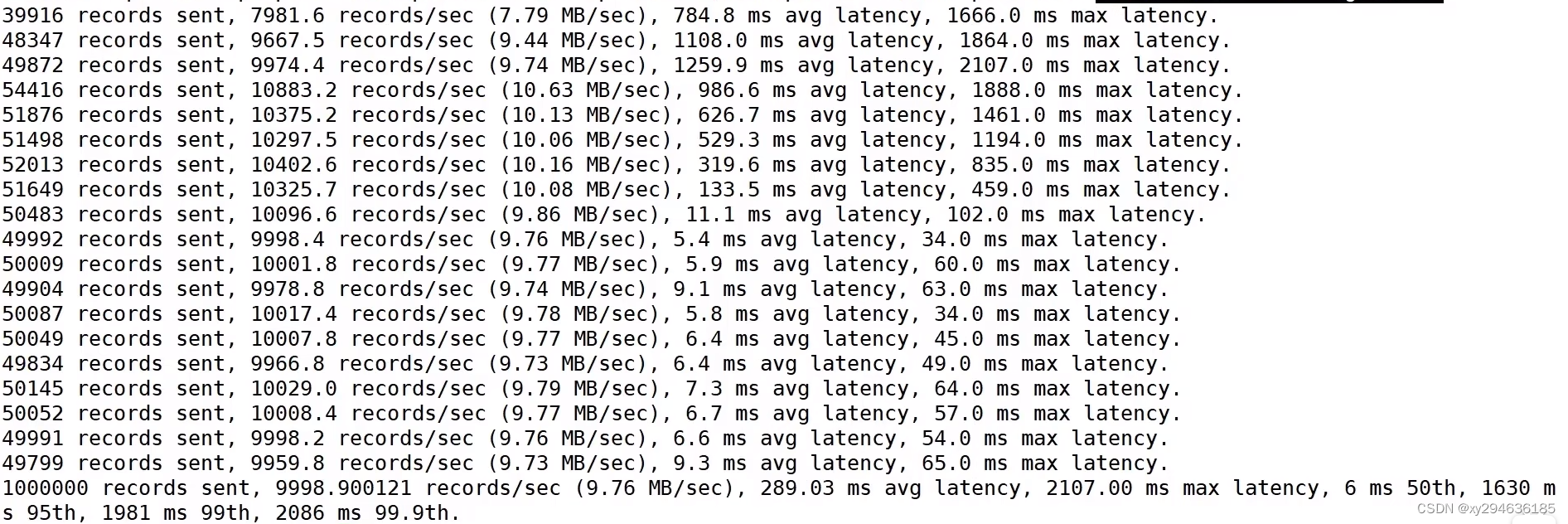
1). 调整batch.size大小
batch.size默认16K,改为4K:
./kafka-producer-perf-test.sh --topic test --record-size 1024 --num-records 1000000 -throughput 10000 --producer-props bootstrap.servers=node1:9092,node2:9092,node3:9092 batch.size=4096 linger.ms=0

2). 调整linger.ms时间
linger.ms默认0,改为50ms
./kafka-producer-perf-test.sh --topic test --record-size 1024 --num-records 1000000 -throughput 10000 --producer-props bootstrap.servers=node1:9092,node2:9092,node3:9092 batch.size=4096 linger.ms=50

3). 压缩测试:略
./kafka-producer-perf-test.sh --topic test --record-size 1024 --num-records 1000000 -throughput 10000 --producer-props bootstrap.servers=node1:9092,node2:9092,node3:9092 batch.size=4096 linger.ms=50 compression.type=snappy
4). 调整缓存大小
buffer.memory默认32m,改为64m
./kafka-producer-perf-test.sh --topic test --record-size 1024 --num-records 1000000 -throughput 10000 --producer-props bootstrap.servers=node1:9092,node2:9092,node3:9092 batch.size=4096 linger.ms=50 buffer.memory=67108864

总结:

- consumer压测
1). 修改kafka/config/consumer.properties文件中的拉取条数
max.pol.records=500
2). 客户端消费100万日志进行压测
./kafka-consumer-perf-test.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic test --messages 1000000 --consumer.config config/consumer.properties
- –bootstrap:kafka集群地址
- –topic:topic名称
- –messages:总共消费消息数,100万

3). 一次拉取2000条
max.pol.records=2000

4). 调整fetch.max.bytes大小为100m
修改kafka/config/consumer.properties文件中的拉取条数:fetch.max.bytes=104857600

总结:
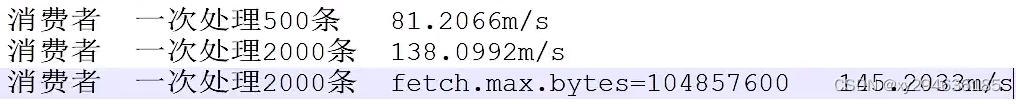
13 Kafka 源码解析
13.1 源码下载
http://kafka.apache.org/downloads