图像处理中的注意力机制
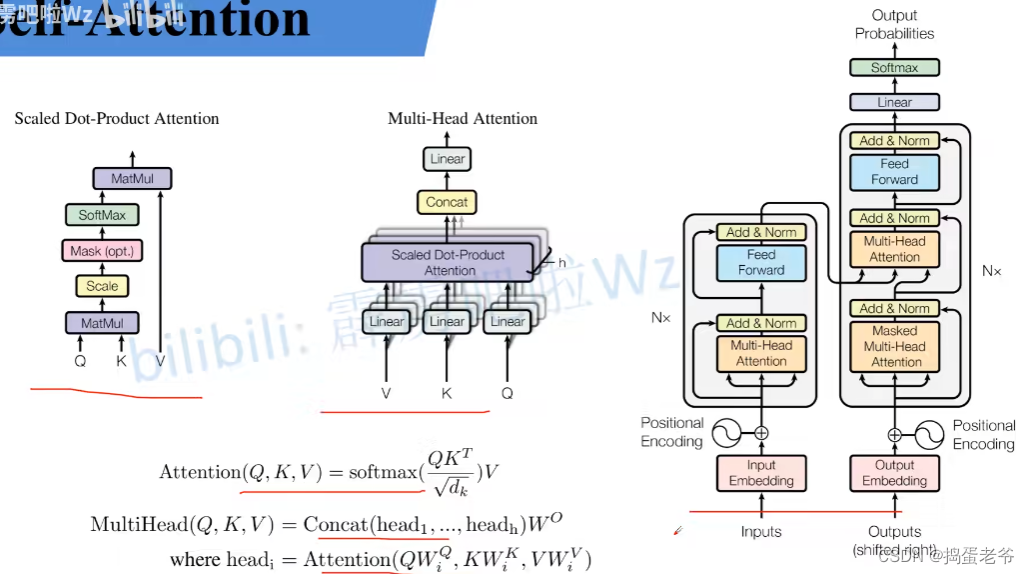
Transformer&Self-Attention
- QKV原理

Self-Attention以及Multi-Head Attention
Self-Attention
- 不同任务(李宏毅的注意力机制)
- 1.输入n输出n:sequence labeling
- 2.输入n输出1:标签
-3. 输入n输出m:seq2seq
- 针对sequence labeling问题可以开一个window把附近的词都考虑到,例如:I saw a saw标记词性,但这样window很大会带来很多参数和overfit,所以引入注意力self-attention
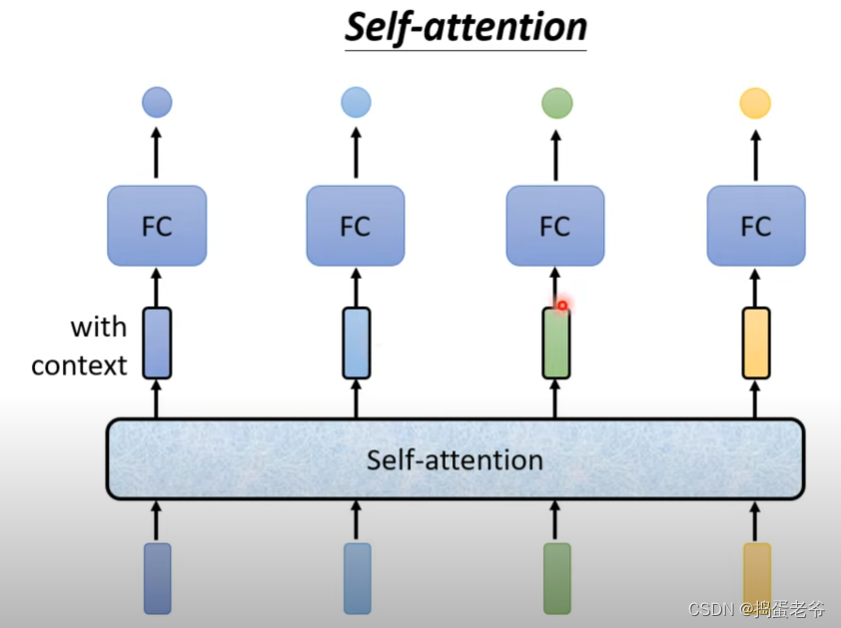
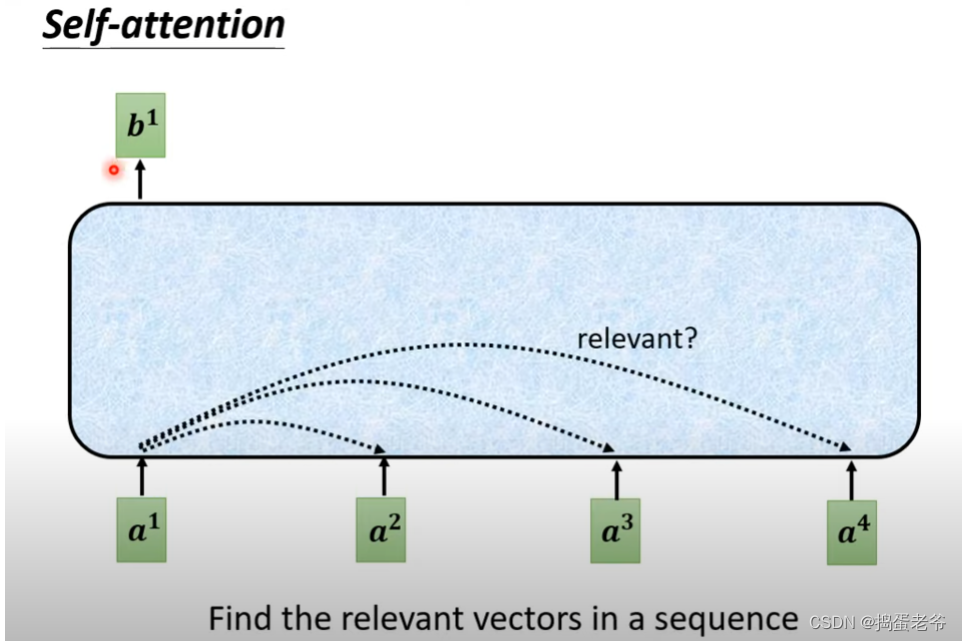
- 找到与自己相关的每个词的相关性,注意重要的信息
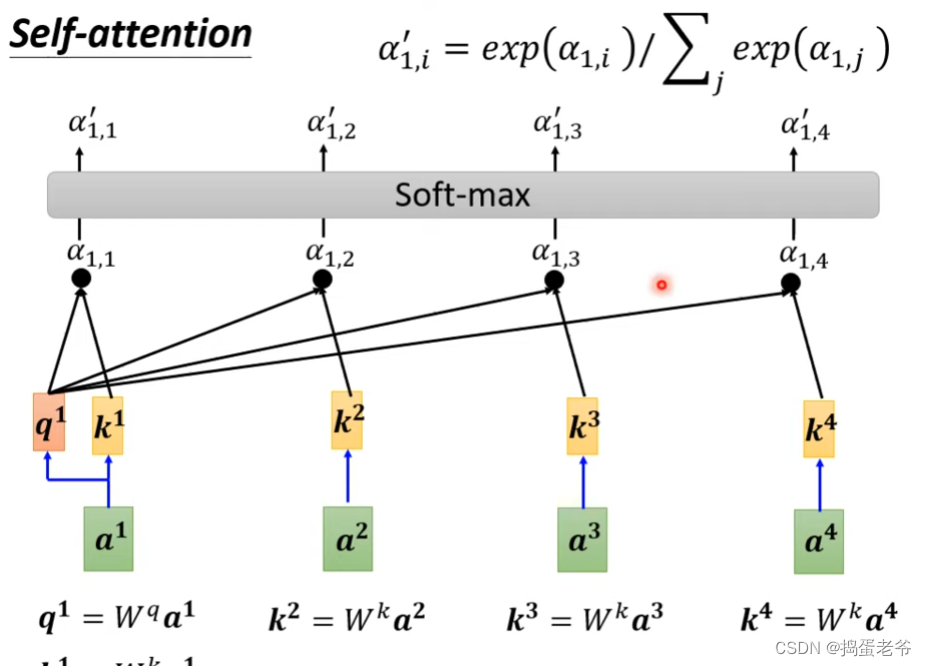
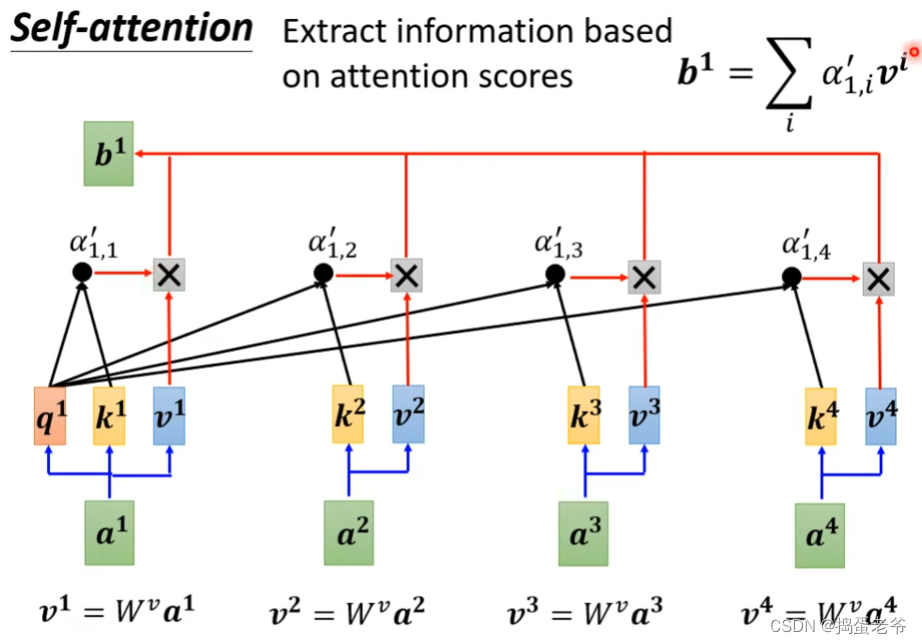
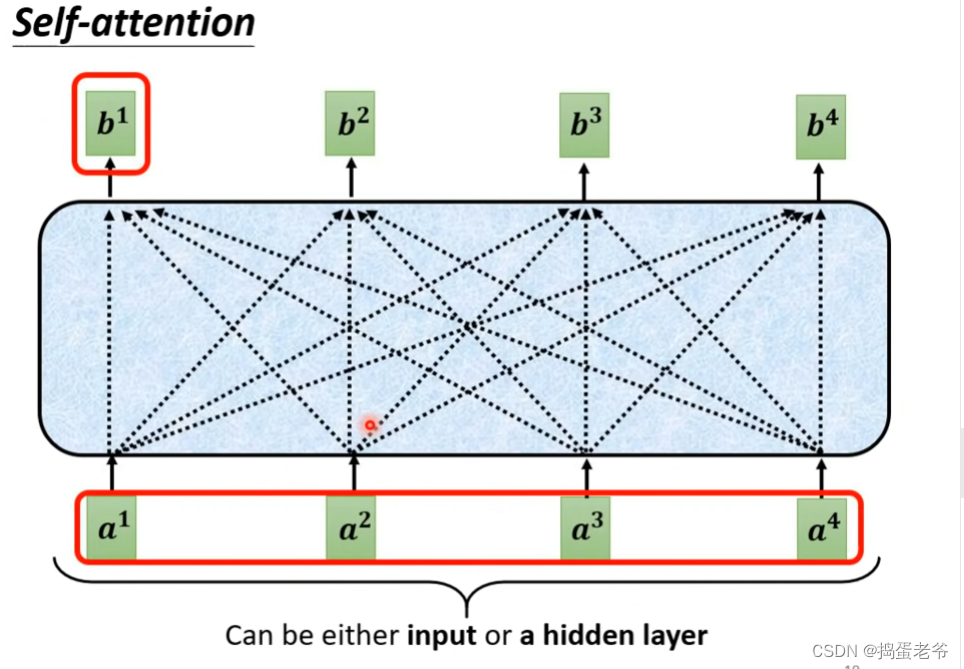
- 注意整个计算过程是可以并行的
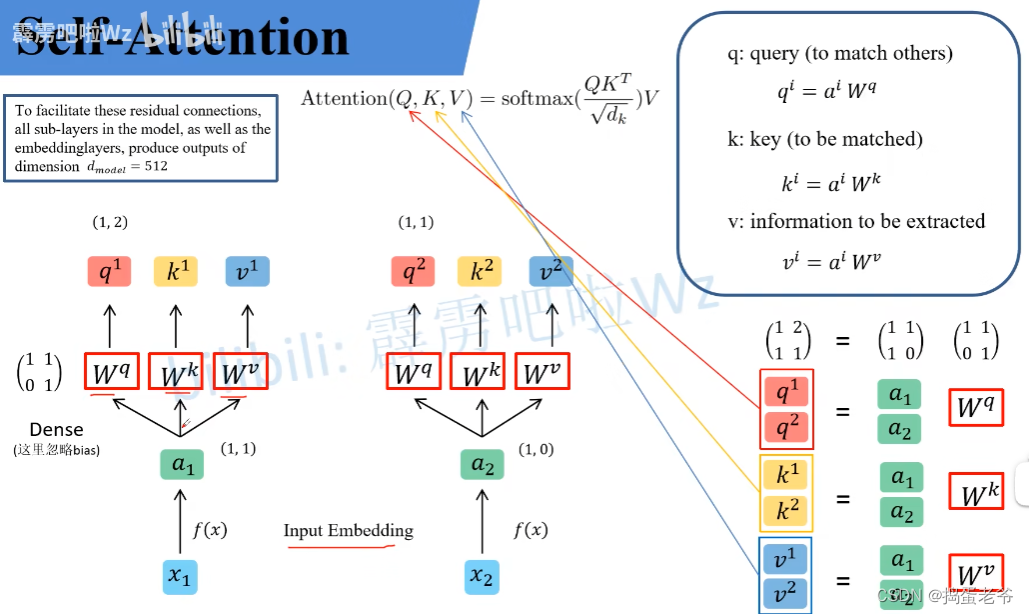
- 矩阵的角度思考
- qkv的计算,每一个a都要产生对应的qkv,w权重是学出来的
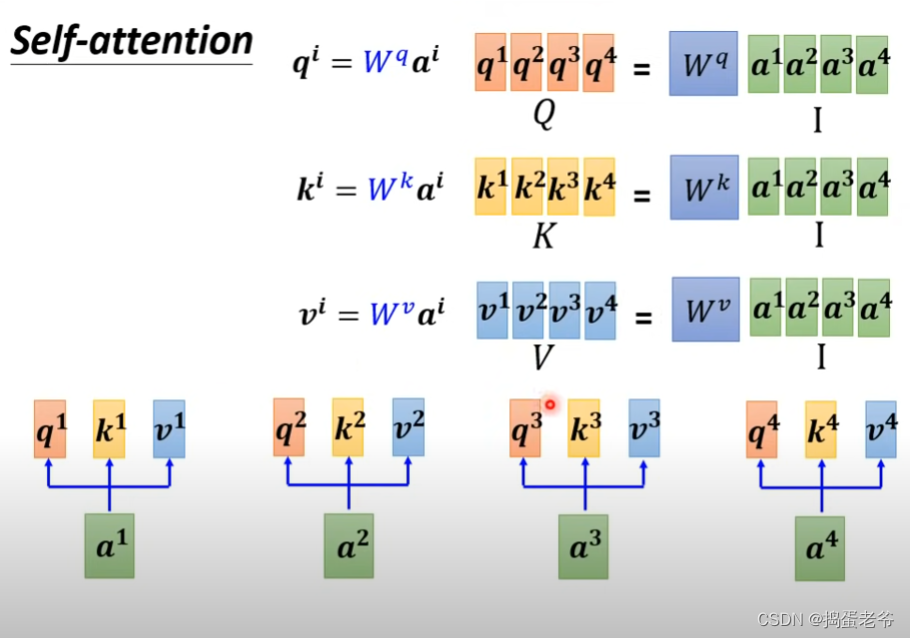
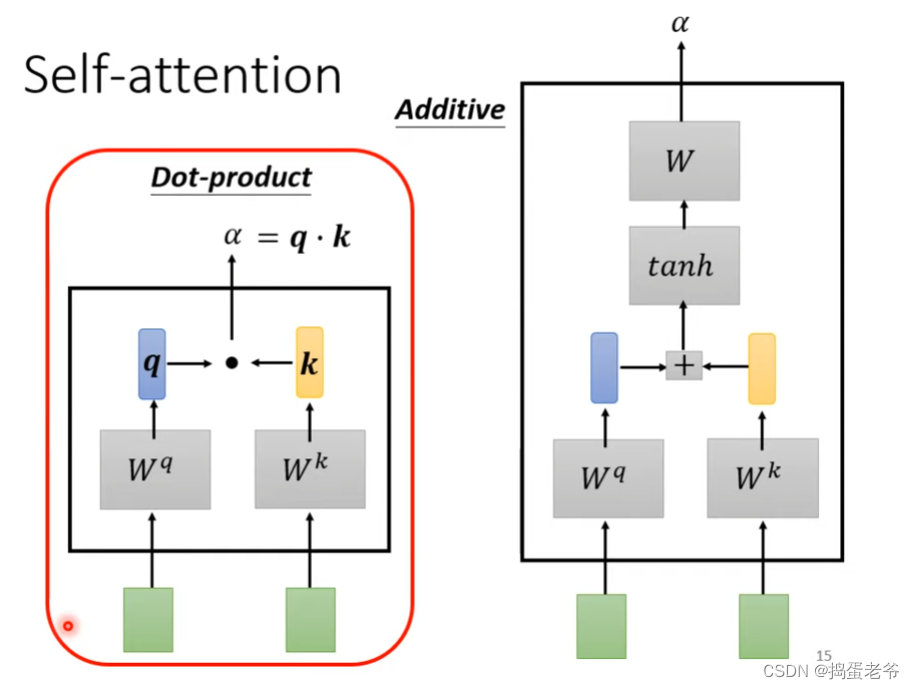
- 计算相似度的本质是向量的内积(点乘):
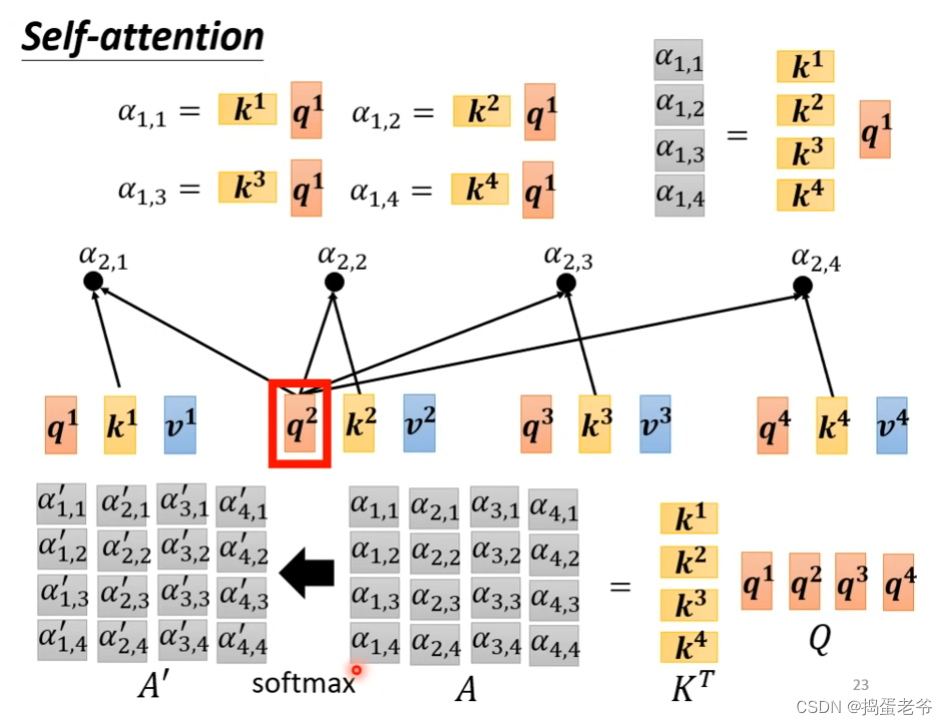
- qkv的计算,每一个a都要产生对应的qkv,w权重是学出来的
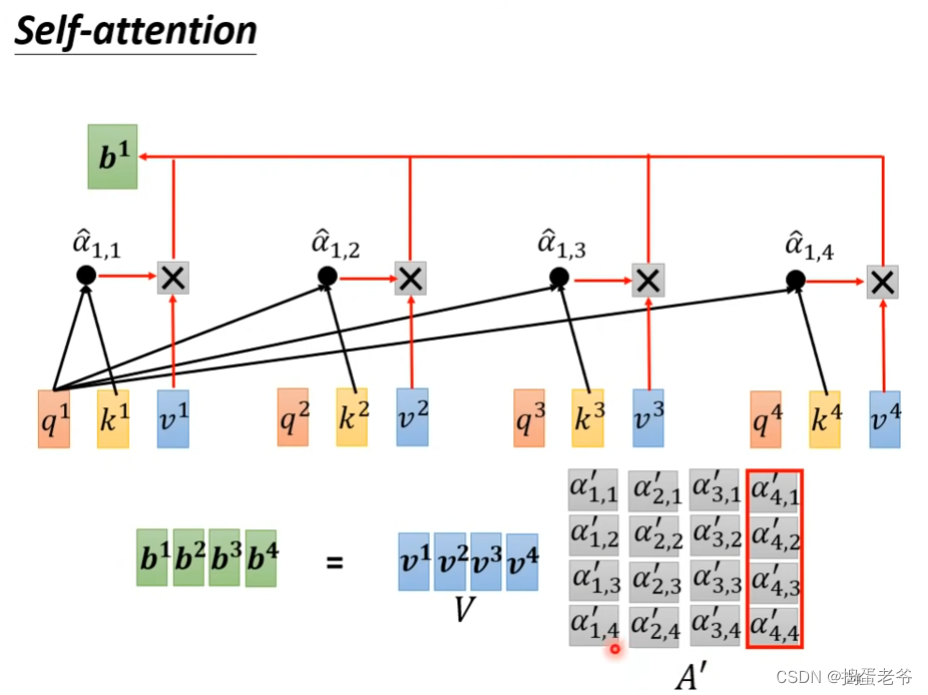
- 总结self-attention
- 找出qkv:使用学习的权重
- 找到相关性的得到weight
- 最后对v做加权和(weighted sum)
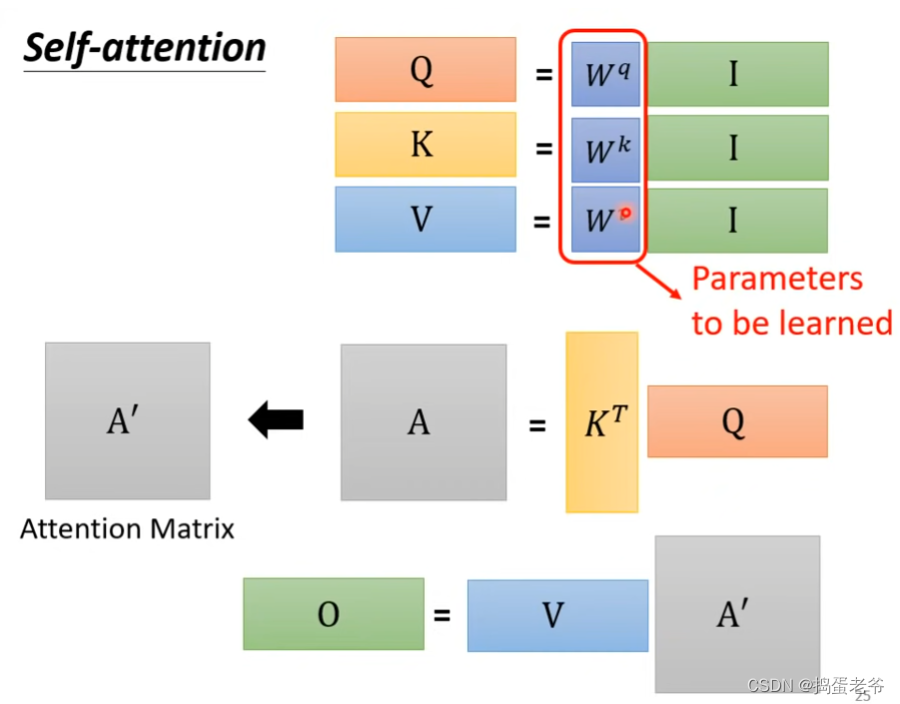
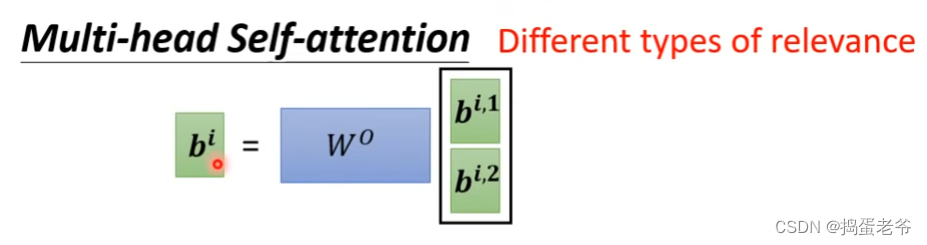
Multi-Head Attention
- 2 head举例
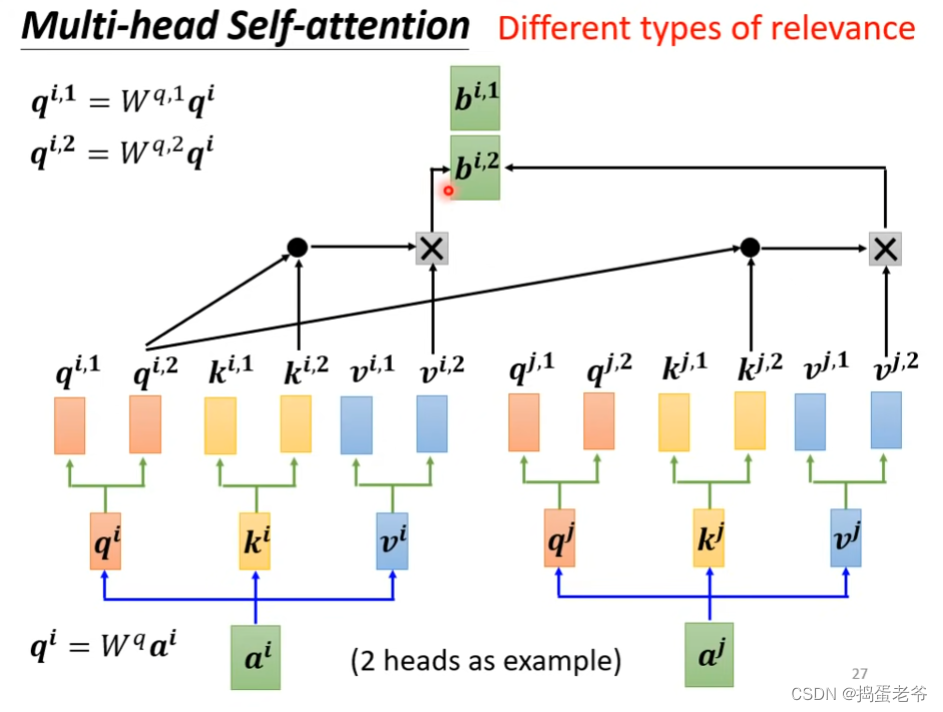
- 到这里会发现一直没有体现位置信息(a1和a2,与a1和a3的计算没有区别),所以要对位置进行编码
- hand-crafted(人为地)
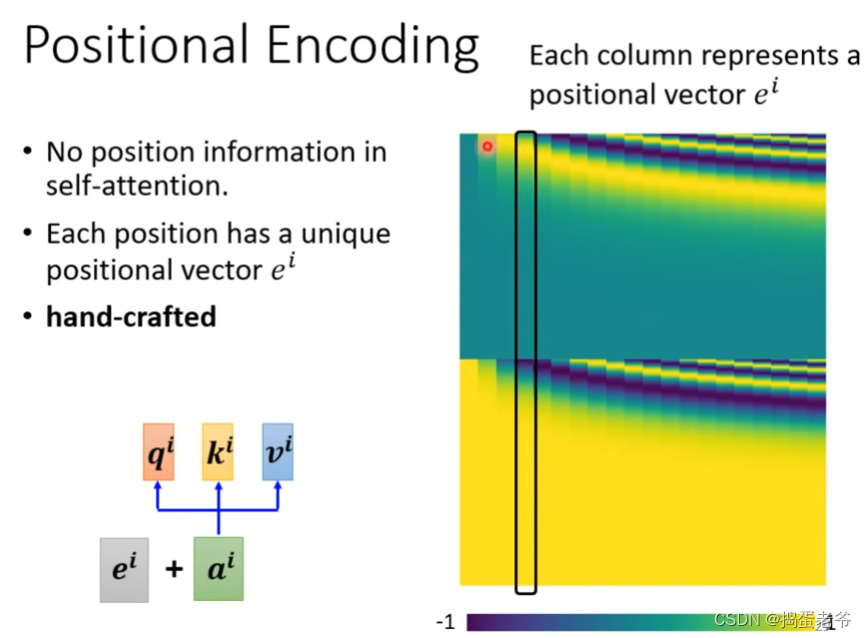
- hand-crafted(人为地)
- 应用(输入是一个很长的向量)
- nlp的bert
- 图像(图看成向量集vector set)
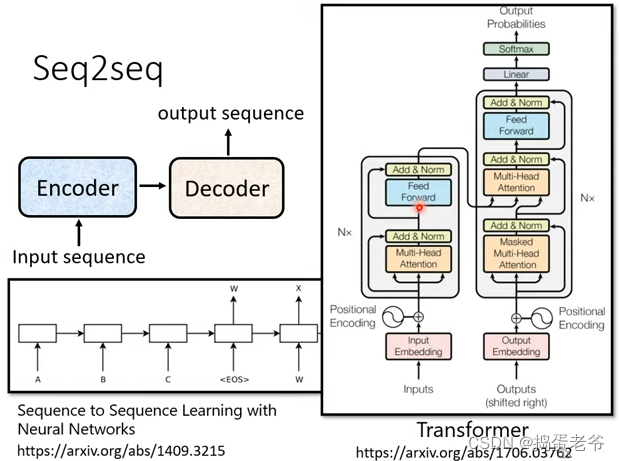
Transformer
- seq2seq处理的问题
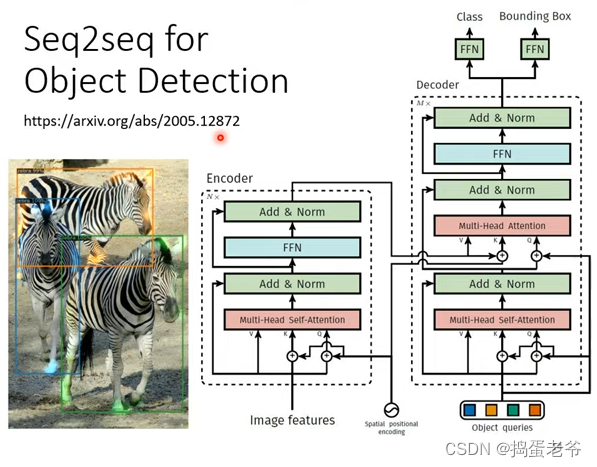
- 模型结构
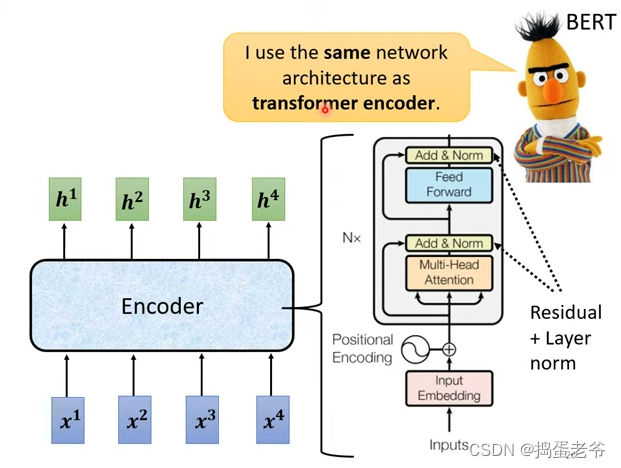
Encoder
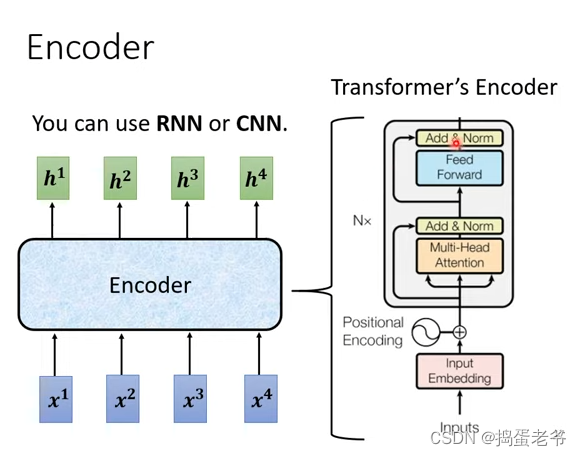
- self-attention的做法
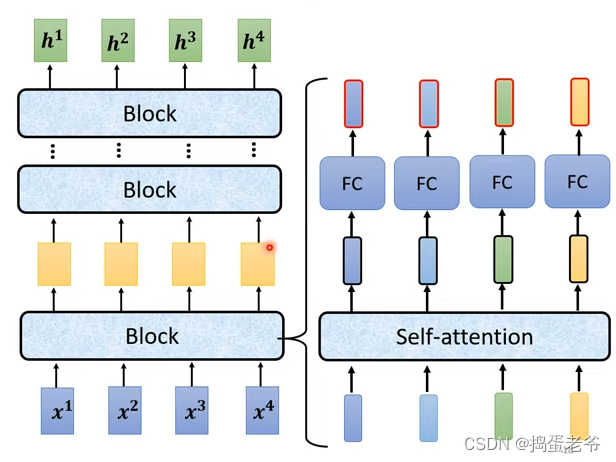
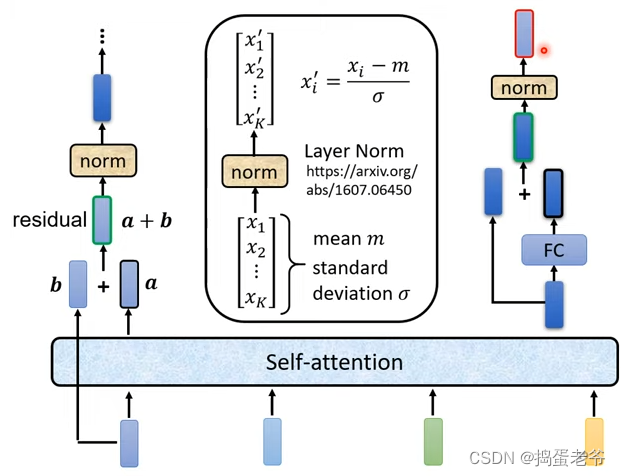
- transform的做法
Decoder
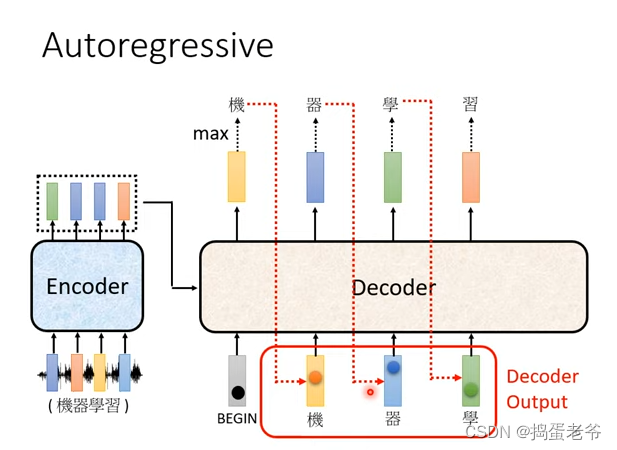
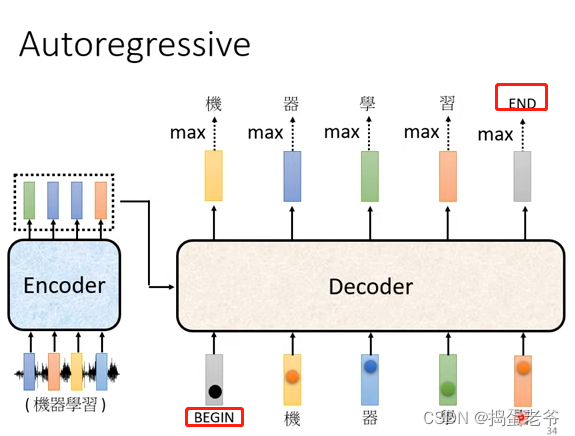
- Autoregressive
- Decode的作用
- Decoder的结构
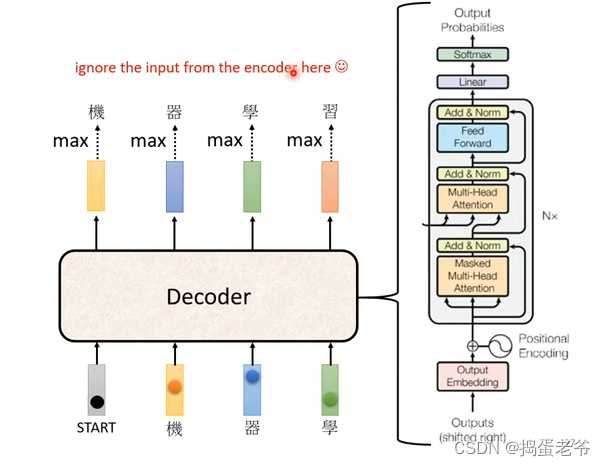
- Mask self-attention
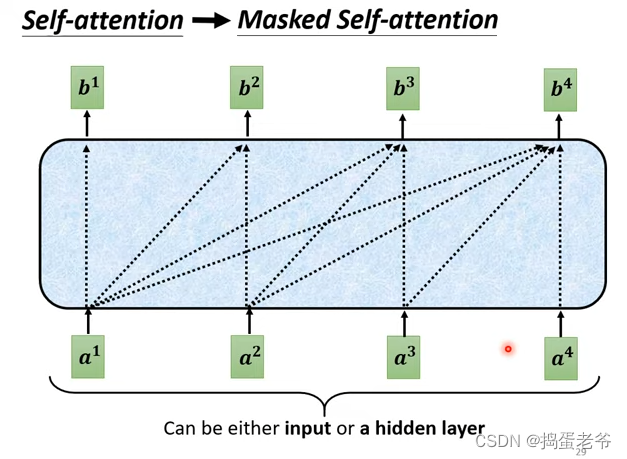
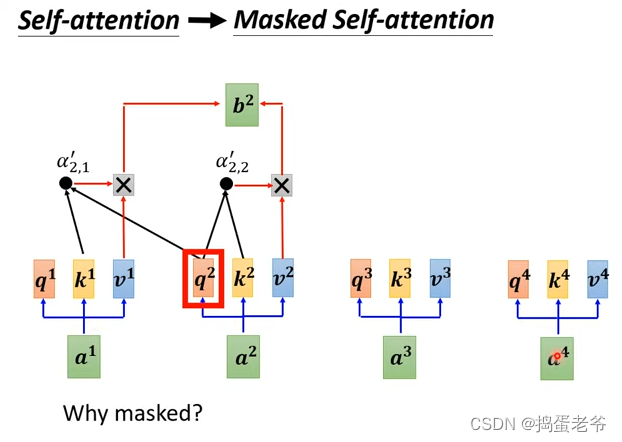
- 为什么要使用mask:因为输入是一个一个产生的b2产生前没有a3,a4(只能考虑左边)
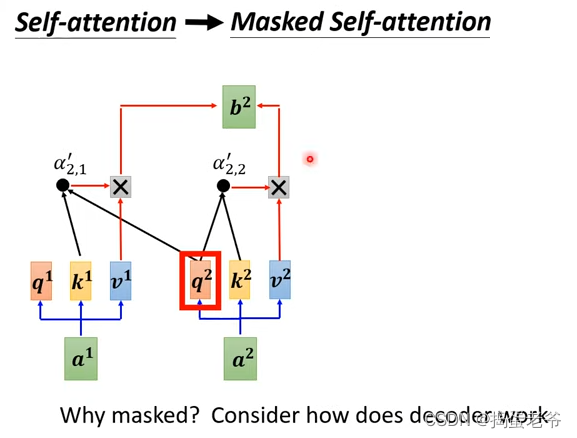
- Decode的作用
- 结束标志
- NAT
- 可以并行
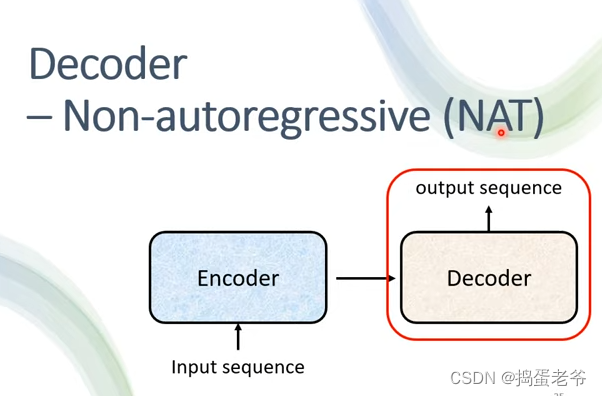
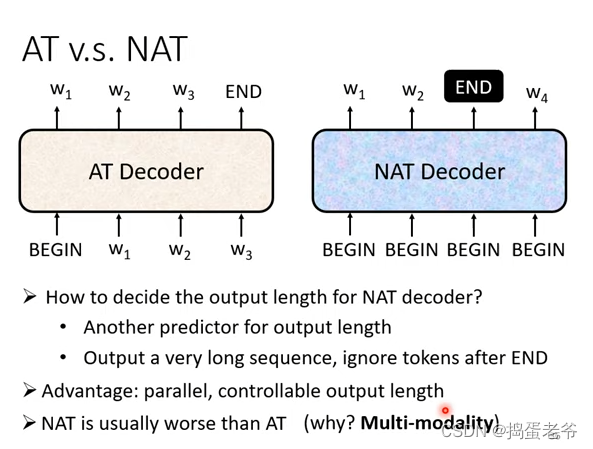
- 可以并行
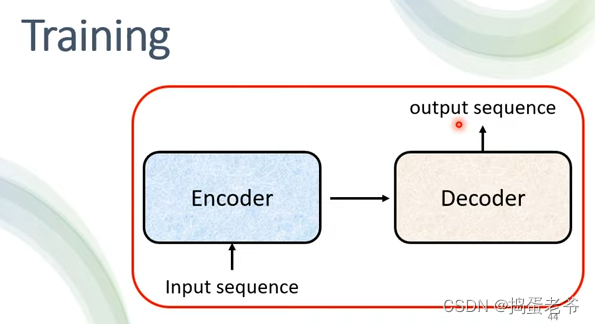
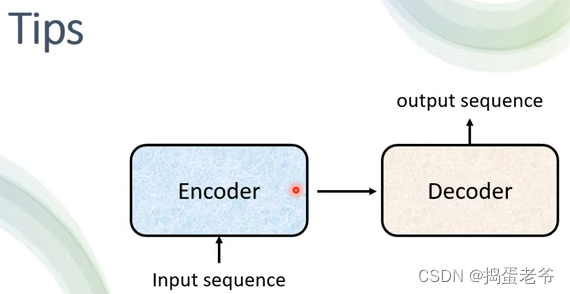
- 链接Encoder和Decoder
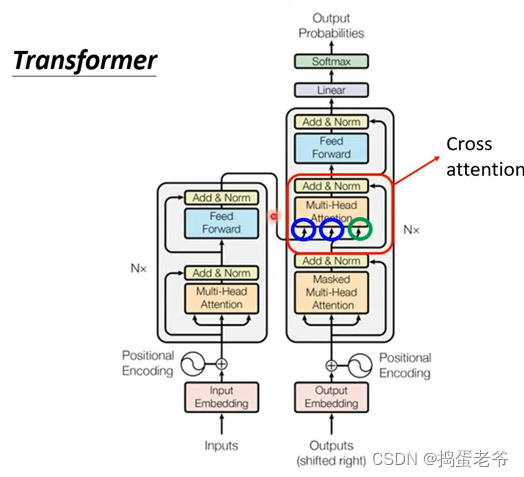
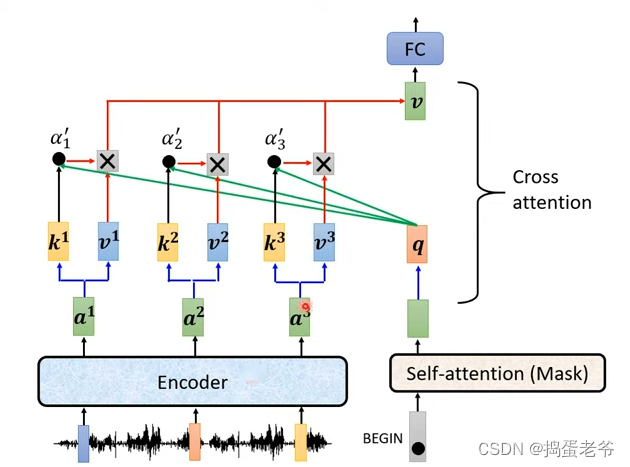
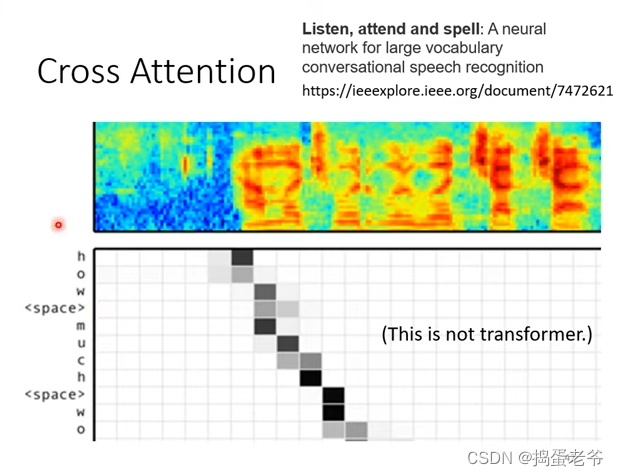
train
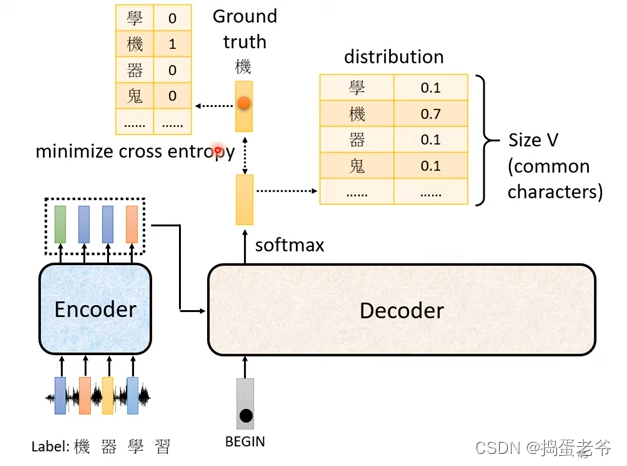
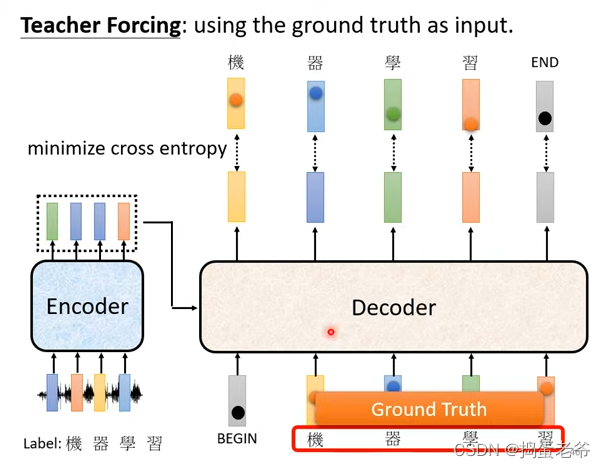
- 技巧
- 复制一部分内容

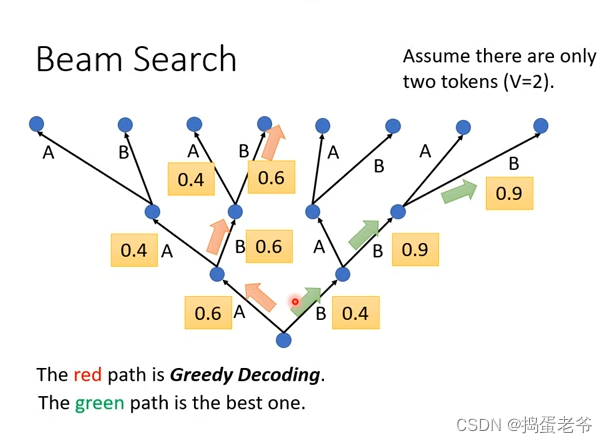
-Beam Search

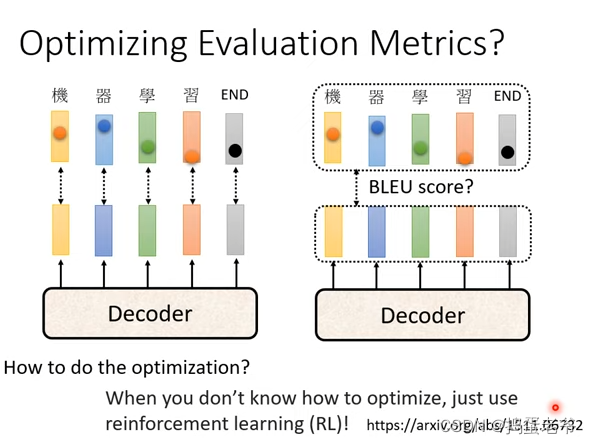
- 复制一部分内容
- 训练和测试不一致:训练都是正确的,测试可能有错误的
- 可以给点错误的
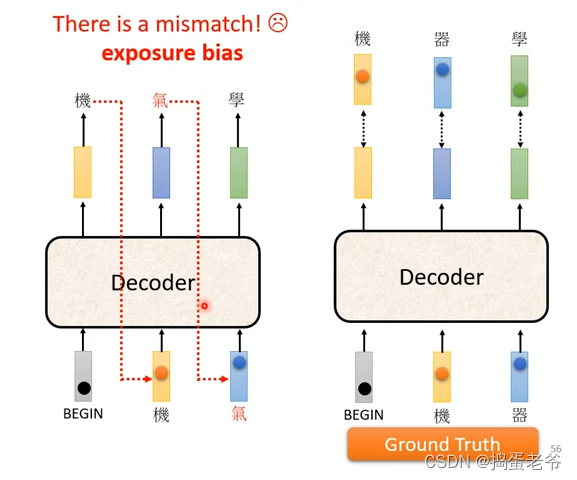
- 可以给点错误的

![关于SpringBoot、Nginx 请求参数包含 [] 特殊符号 返回400状态](https://img-blog.csdnimg.cn/7efd894b6f054017a7d2c48b475f4d51.png)