分两个文件讲解:1、train.py训练文件 2、test.py测试文件.
1、train.py训练文件
1)从主函数入口开始,设置相关参数
# 主函数入口
if __name__ == '__main__':
# ----------------------------#
# 是否使用Cuda
# 没有GPU可以设置成Fasle
# ----------------------------#
cuda = True
# ----------------------------#
# 是否使用预训练模型
# ----------------------------#
pre_train = True
# ----------------------------#
# 是否使用余弦退火学习率
# ----------------------------#
CosineLR = True
# ----------------------------#
# 超参数设置
# lr:学习率
# Batch_size:batchsize大小
# ----------------------------#
lr = 1e-3
Batch_size = 2
Init_Epoch = 0
Fin_Epoch = 100
2)创建模型
# 创建模型
model = ResNet(Bottleneck, [3, 4, 6, 3], num_classes=10)
#判断是否需要预训练模型,在1)已经设置pre_train=True,这里会加载预训练模型,
#为"logs/resnet50-mnist.pth"。
#这里加载的是预训练模型的权重参数,实例化到本地模型ResNet上
if pre_train:
model_path = 'logs/resnet50-mnist.pth'
model.load_state_dict(torch.load(model_path))
#判断cuda是否可用,如果cuda可用,模型将调用GPU,否则将调用CPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
3)创建数据集
# ----------------------------#
root='data/' :路径
train=True :训练设置为True
transform=transforms.ToTensor() :转化成Tensor
download=True :下载
# ----------------------------#
train_dataset = datasets.MNIST(root='data/', train=True,
transform=transforms.ToTensor(), download=True)
#这里train = False, download=False,此时下载验证集
test_dataset = datasets.MNIST(root='data/', train=False,
transform=transforms.ToTensor(), download=False)
4)加载数据集
# ----------------------------# #DataLoader加载数据集 batch_size=Batch_size 批量输入 shuffle=True 打乱数据 num_workers=0 单个工作进程 # ----------------------------# gen = DataLoader(dataset=train_dataset, batch_size=Batch_size, shuffle=True, num_workers=0) gen_test = DataLoader(dataset=test_dataset, batch_size=Batch_size // 2, shuffle=True, num_workers=0)
5)设置损失函数和优化器
#损失函数为交叉熵损失 softmax_loss = torch.nn.CrossEntropyLoss() #优化器选择Adams optimizer = torch.optim.Adam(model.parameters(), lr)
6)设置学习率
#如果CosineLR = True,学习率为CosineAnnealingLR,否则为StepLR
if CosineLR:
lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=5, eta_min=1e-10)
else:
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.92)
7)训练
# ----------------------------#
epoch_size 训练集一次加载多少个batch
epoch_size_val 验证集一次加载多少个batch
# ----------------------------#
epoch_size = len(gen)
epoch_size_val = len(gen_test)
# ----------------------------#
Init_Epoch 起始训练为0
Fin_Epoch 终止训练为100次
fit_one_epoch()函数进行训练数据
lr_scheduler.step()一次训练结束后,学习率进行更新
# ----------------------------#
for epoch in range(Init_Epoch, Fin_Epoch):
fit_one_epoch(net=model, softmaxloss=softmax_loss, epoch=epoch, epoch_size=epoch_size,epoch_size_val=epoch_size_val, gen=gen, gen_test=gen_test, Epoch=Fin_Epoch, cuda=cuda)
lr_scheduler.step()
2、test.py测试文件
展示运行结果
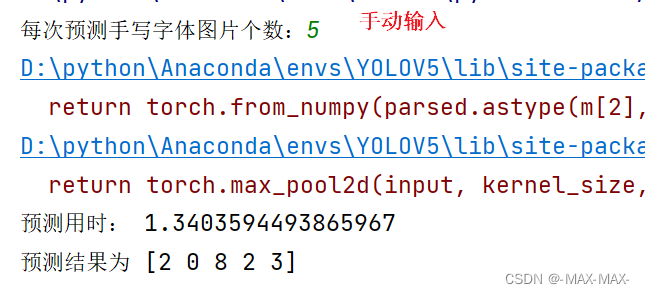
1)整段讲解
import torch from nets.resnet50 import ResNet,Bottleneck import os from torchvision import datasets, transforms from torch.utils.data import DataLoader from torch.autograd import Variable import torchvision import cv2 import time # 设置权重文件路径 PATH = './logs/resnet50-mnist.pth' # 谁知手动输入单次识别字数 Batch_Size = int(input('每次预测手写字体图片个数:')) # 加载模型 model = ResNet(Bottleneck, [3, 4, 6, 3], num_classes=10) model.load_state_dict(torch.load(PATH)) model = model.cuda() # 进入测试程序 model.eval() # 设置测试数据集并加载 test_dataset = datasets.MNIST(root='data/', train=False, transform=transforms.ToTensor(), download=False) gen_test = DataLoader(dataset=test_dataset, batch_size=Batch_Size, shuffle=True) # 进入循环 while True: # 获取图片和标签 images, lables = next(iter(gen_test)) img = torchvision.utils.make_grid(images, nrow=Batch_Size) img_array = img.numpy().transpose(1, 2, 0) # 获取开始时间 start_time = time.time() # 输出预测结果 outputs = model(images.cuda()) _, id = torch.max(outputs.data, 1) end_time = time.time() # 打印用时和预测结果,由于输出的id为tensor,这里必须转换为numpy print('预测用时:', end_time-start_time) print('预测结果为', id.data.cpu().numpy()) # 展示图片 cv2.imshow('img', img_array) cv2.waitKey(0)