二、数据流风格软件体系结构
概念
- 数据流系统的各软件组件在无数据到达时处于休眠状态,当有数据到达时,该软件组件被激活,开始对数据进行处理。
- 数据流风格软件体系结构将整个软件系统看作由一系列作用在连续数据集合上的“变换”组成。数据和作用于其上的操作是互相独立的。
- 软件系统被分解为一些数据处理单元或称为组件,数据流控制数据处理顺序。
在数据流风格体系结构中的组件是可以被重复使用的,且在保证输入与输出接口都不变的情况下,可以独立修改一个组件,而不影响其他的组件。
注意同步问题
代码
数据流风格软件体系结构是一种基于数据流和数据转换的软件设计方法。在数据流风格中,系统由一系列的数据流和数据转换组件构成,数据在组件之间流动,经过转换和处理,最终产生所需的输出结果。
下面是一个简单的代码示例,演示了数据流风格软件体系结构的实现:
# 数据输入组件
def input_component():
data = get_input_data()
return data
# 数据转换组件
def transform_component(data):
transformed_data = perform_transformation(data)
return transformed_data
# 数据处理组件
def process_component(data):
result = process_data(data)
return result
# 数据输出组件
def output_component(result):
display_result(result)
# 主函数,按照数据流顺序调用组件
def main():
# 数据输入
data = input_component()
# 数据转换
transformed_data = transform_component(data)
# 数据处理
result = process_component(transformed_data)
# 数据输出
output_component(result)
# 调用主函数启动程序
main()
在上述代码示例中,每个组件都有特定的功能和责任:
input_component负责获取输入数据,并将数据传递给下一个组件。transform_component对输入数据进行转换或处理,生成转换后的数据。process_component对转换后的数据进行进一步的处理或计算,生成最终的结果。output_component将结果进行展示或输出。
通过按照数据流的顺序调用这些组件,数据在系统中流动和转换,最终得到期望的输出结果。
数据流风格软件体系结构的优点包括:
- 可维护性:每个组件都专注于特定的数据处理任务,易于理解和维护。
- 可扩展性:可以添加新的组件来处理不同的数据流,扩展系统的功能。
- 可重用性:每个组件可以独立地被其他系统或模块重用。
- 灵活性:可以根据需要重新组合和连接组件,以满足不同的业务需求。
数据流风格软件体系结构在许多领域中都有应用,特别是在数据处理和转换方面,例如数据流处理系统、ETL(Extract, Transform, Load)工具等。它提供了一种简洁而直观的方式来设计和实现数据驱动的软件系统。
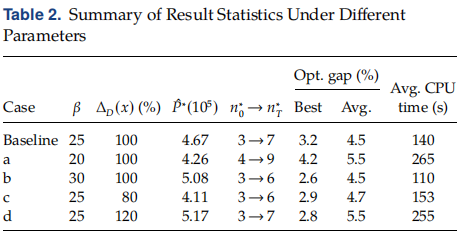
控制流 vs. 数据流
数据流风格三种例子
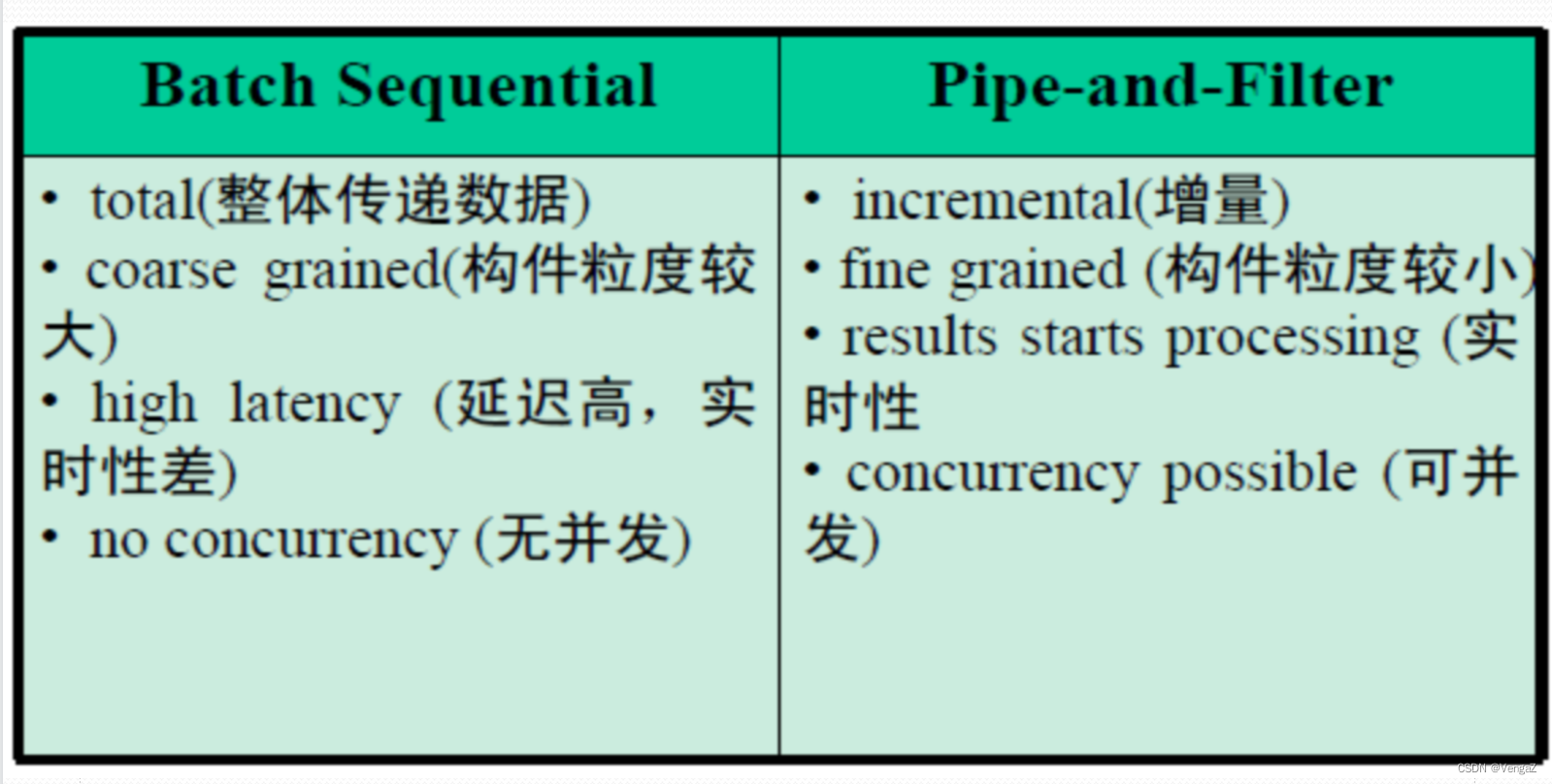
Batch Sequential(批处理)
Pipe-and-Filter(管道-过滤器)
Process Control(控制)
Batch Sequential(批处理)
在该系统中,组件为独立的程序,并且这些组件按照先后顺序处理,即只有当一个组件的运行彻底结束以后,下一个组件才能开始执行。可以认为,数据在处理步骤之间的传输是成批(块)的,而不是以数据流的方式进行的。这也是"顺序批处理"名称的由来。
批处理系统特点
- 每个处理程序模块都是互为独立的程序
- 只有上一步程序彻底完成,下一步程序才能开始
- 数据作为一个整体进行传输
- 因为以上的特点,所以不必对其组件进行同步处理
- 因为几个组件只能按照顺序运行,而不能同步运行,所以性能可能比那些能按照几个组件同时运行的程序要差一些
- 使用顺序批处理结构设计的软件不适用于要求对数据进行实时处理的系统
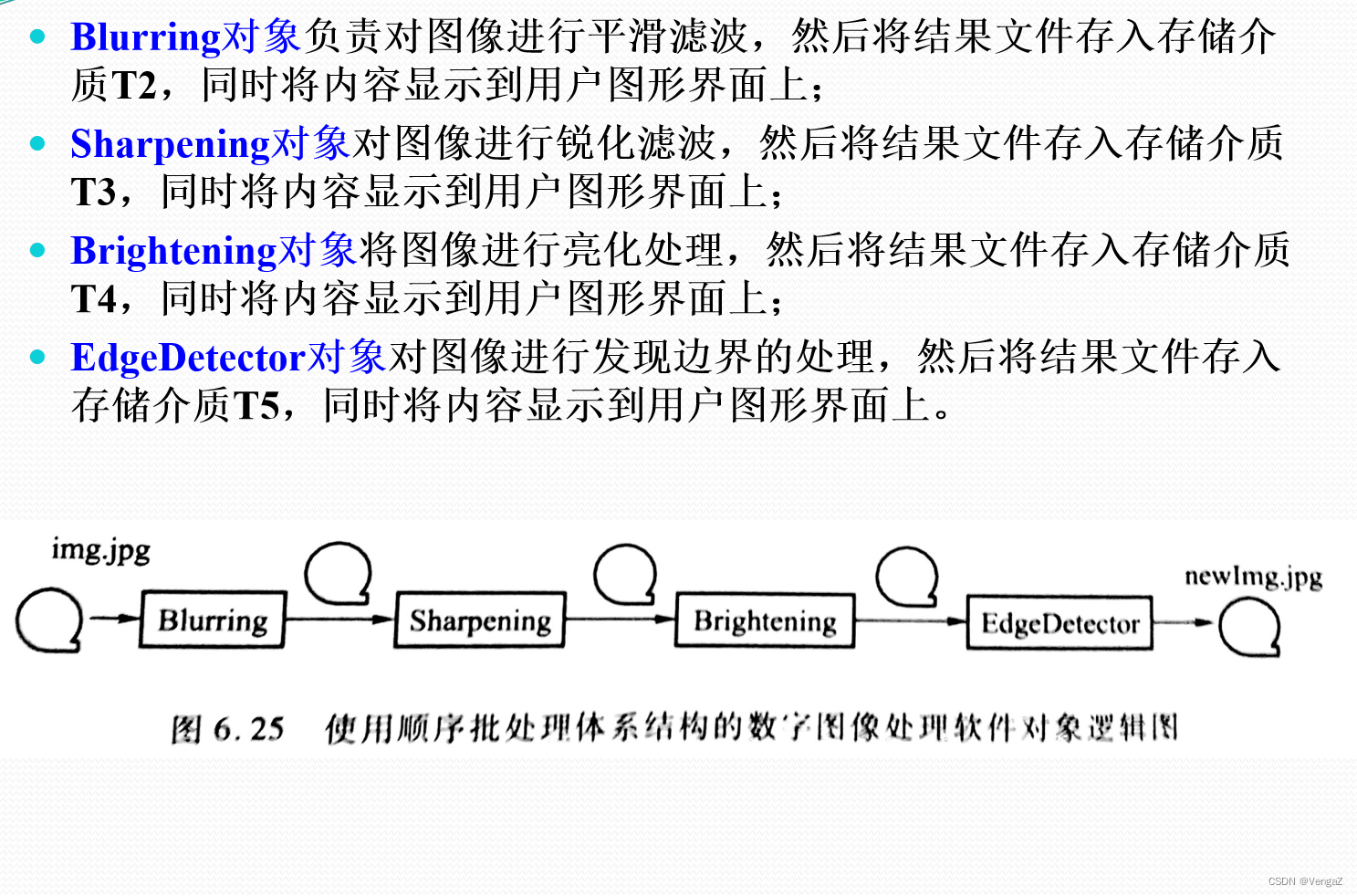
批处理系统案例:数字图像处理软件

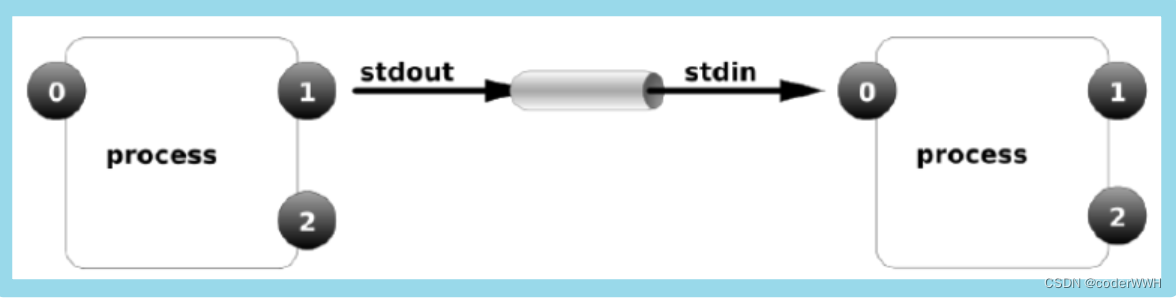
Pipe-and-Filter(管道-过滤器)
在管道-过滤器软件体系结构中,每个组件都有一组输入和输出,组件读入输入数据流,经过数据处理,然后产生输出数据流。
在输入被完全消费之前,输出便产生了
组件被称为过滤器,这种风格的连接件就像是数据流传输的管道
过滤器
过滤器三个部分组成
- Input Port 负责存储待处理的数据
- Filter 负责处理数据
- Output Port 负责存储已经处理完的数据
管道
管道的三个组件
- Input Stream 输入流
- Pipe 管道
- Output Stream 输出流
作用:在过滤器之间传送数据
单向流
可能具有缓冲区
管道形成传输图
不同的管道中流动的数据流,具有不同的数据格式
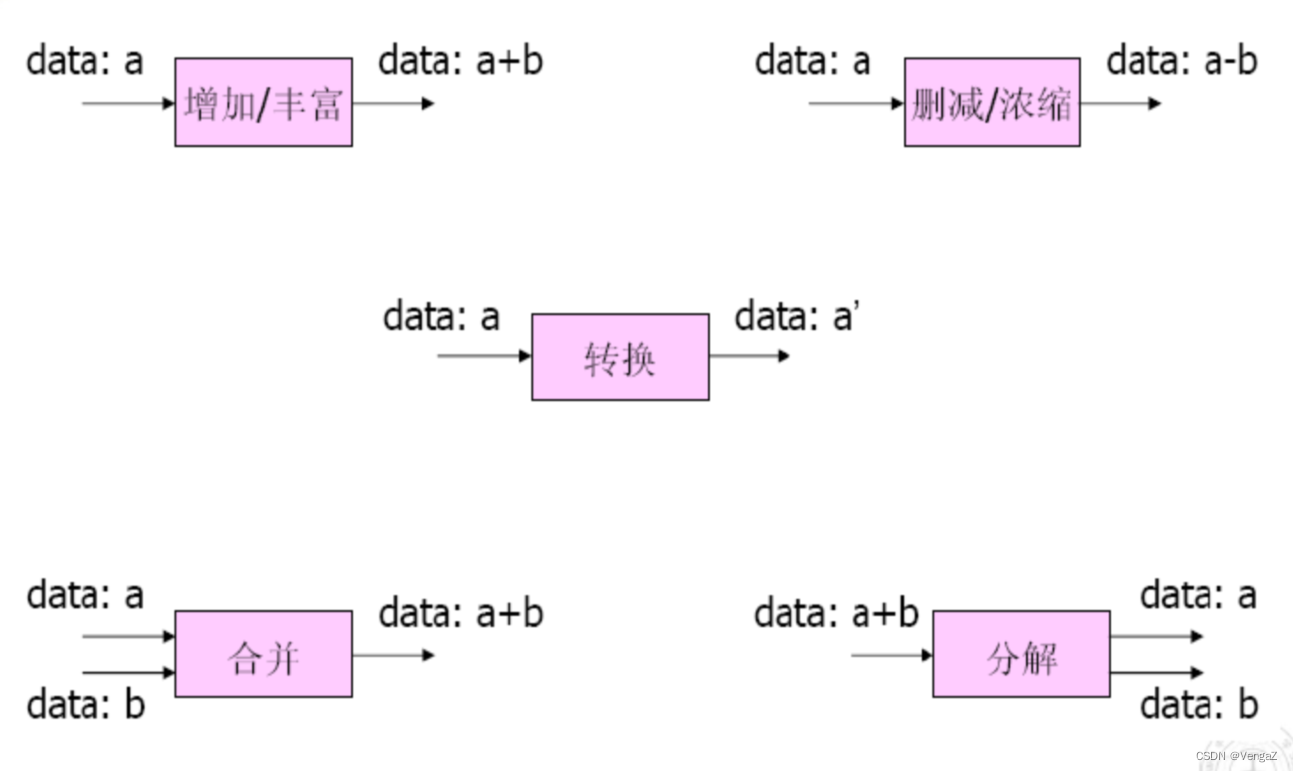
原因:数据在流过每一个过滤器时,被过滤器进行了丰富、精炼、转换、融合、分解等操作,因而发生了变化
管道-过滤器软件体系优点
并发性:对于海量数据处理问题,可以提高高通量的产出
可复用性:封装了过滤器,使得过滤器可以被非常容易地插入与替换
将每个过滤器的输入/输出限制为单一的,则管道-过滤器退化为顺序批处理系统(Batch sequential)
管道过滤器构成的网络,其输出的正确姓与过滤器的递增处理顺序无关
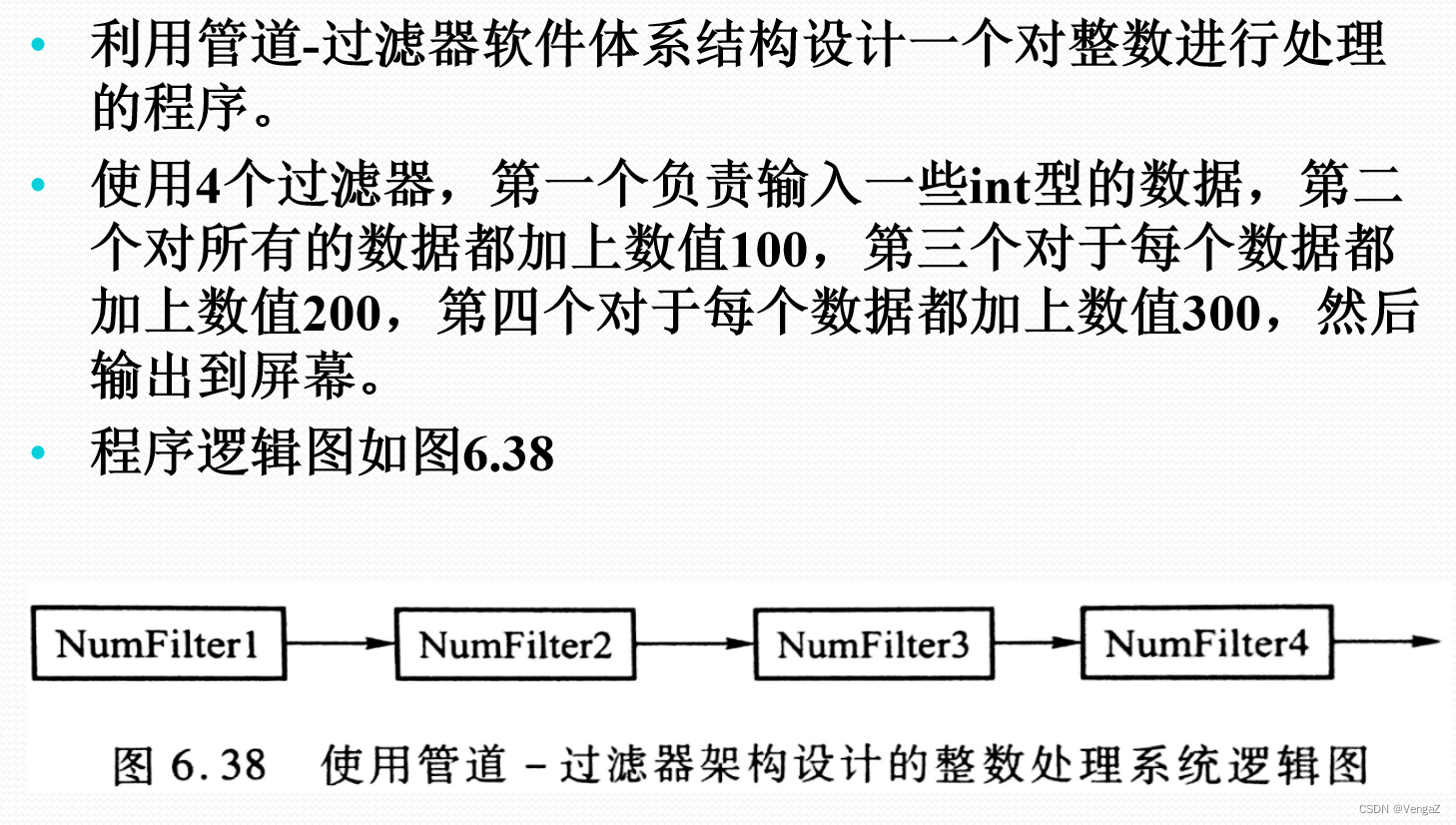
案例分析:主动型过滤器实例
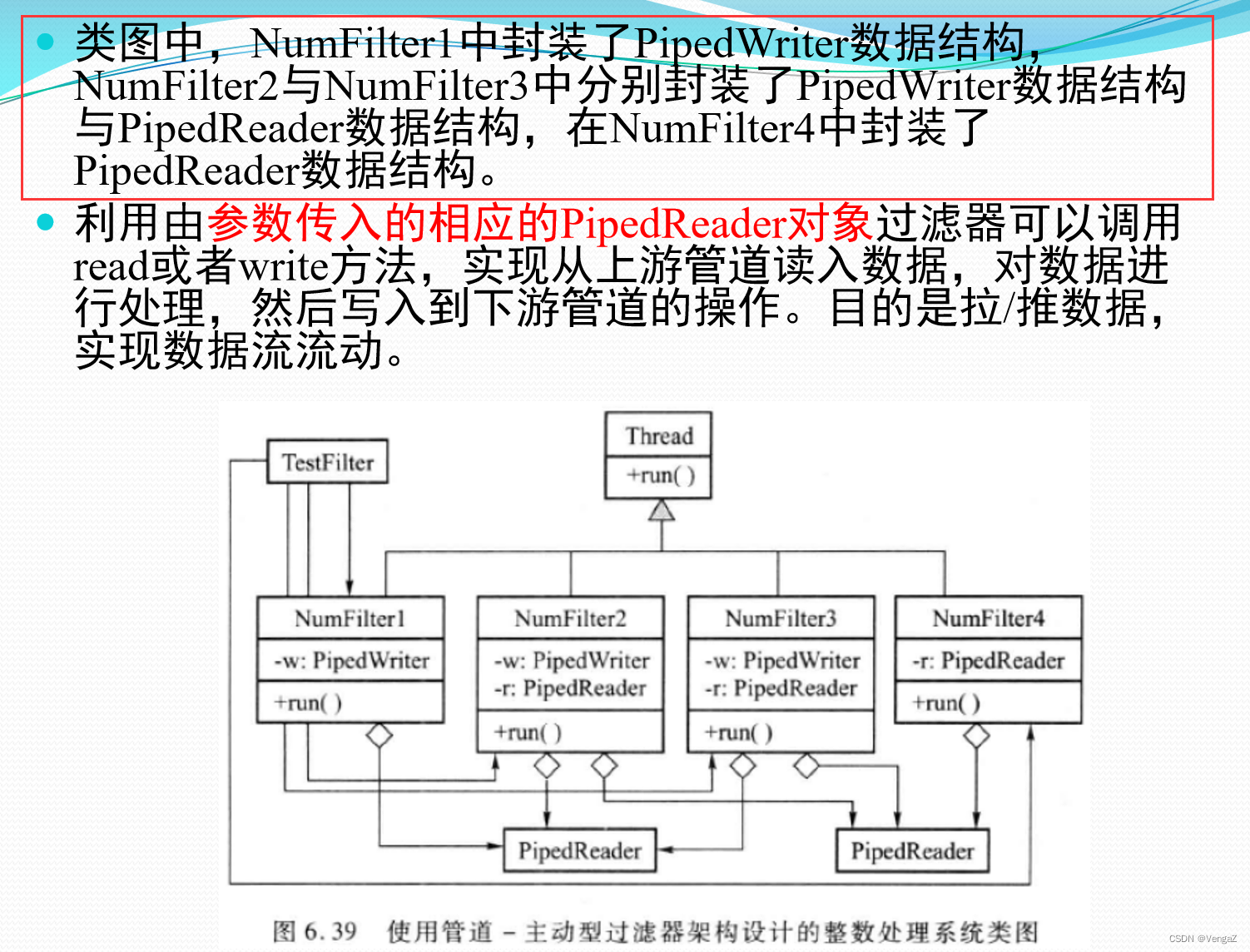
类图
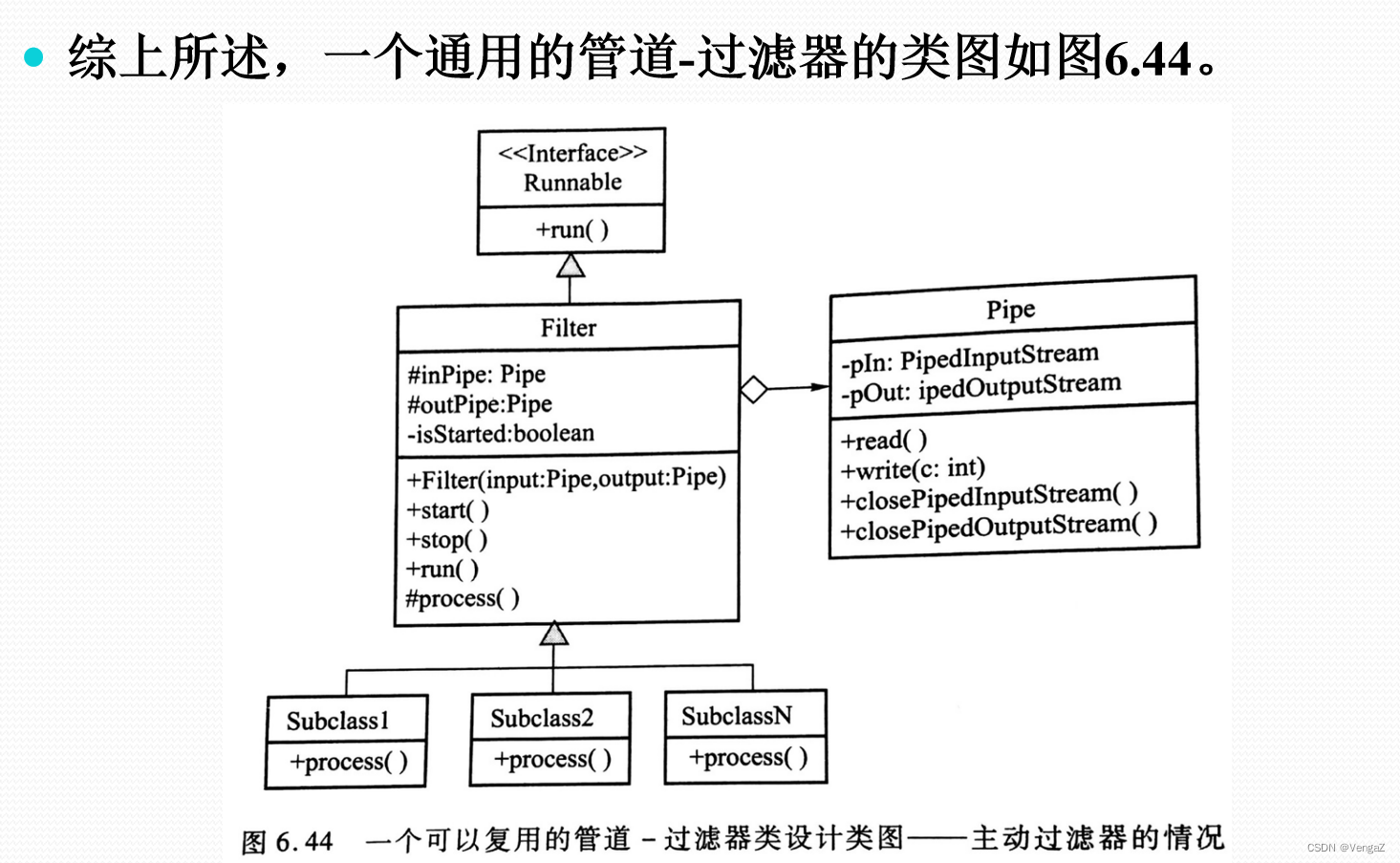
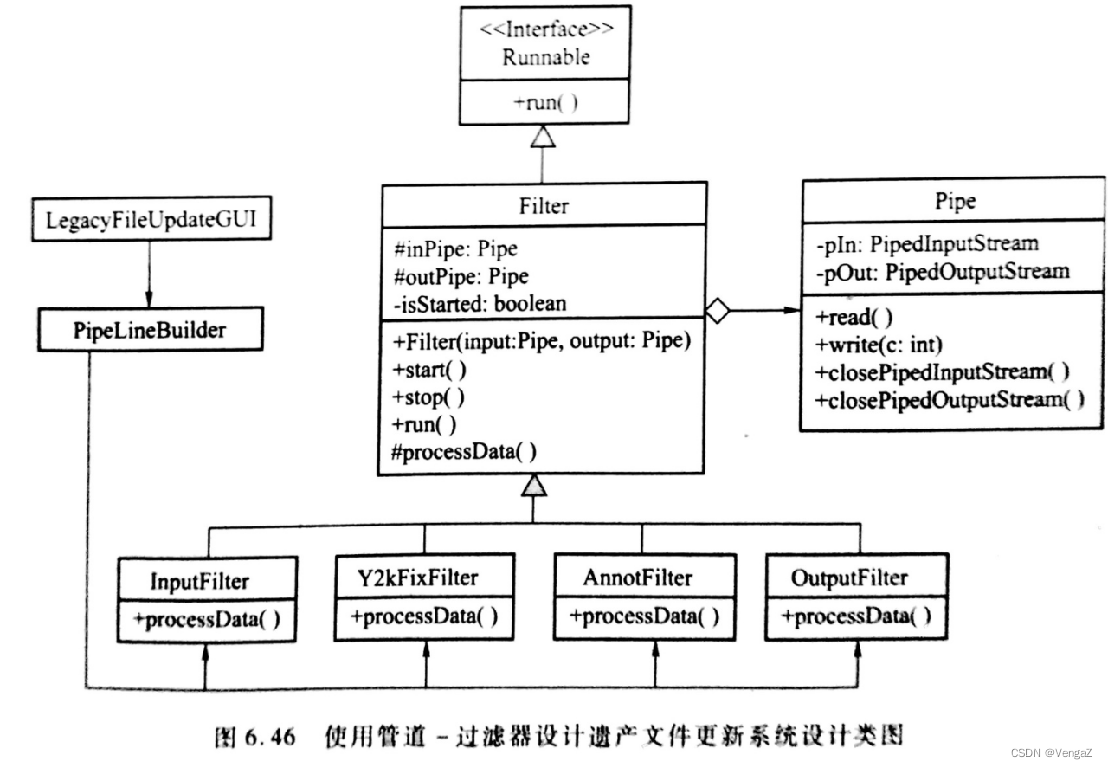
案例分析:设计遗产文件更新系统

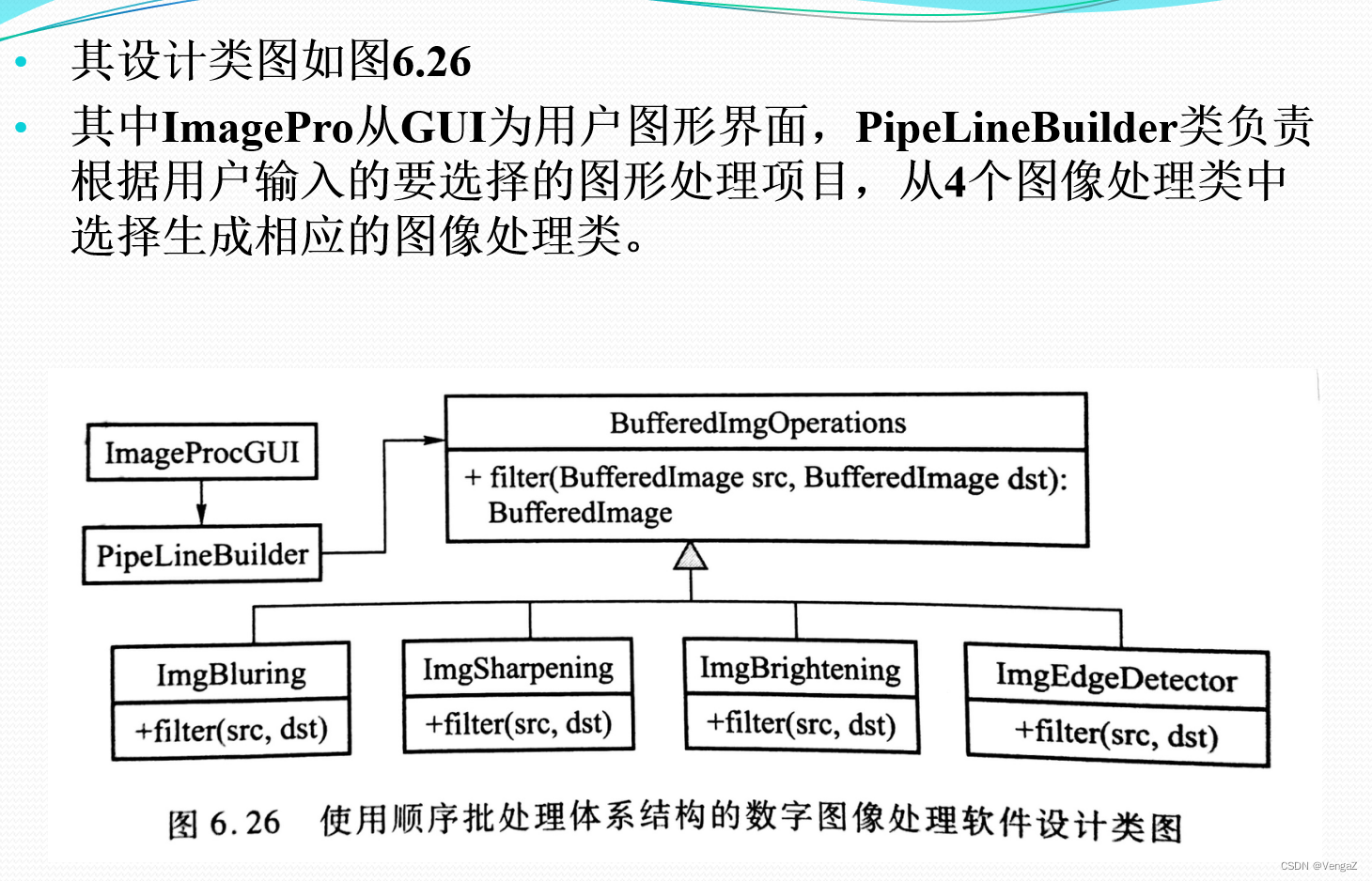
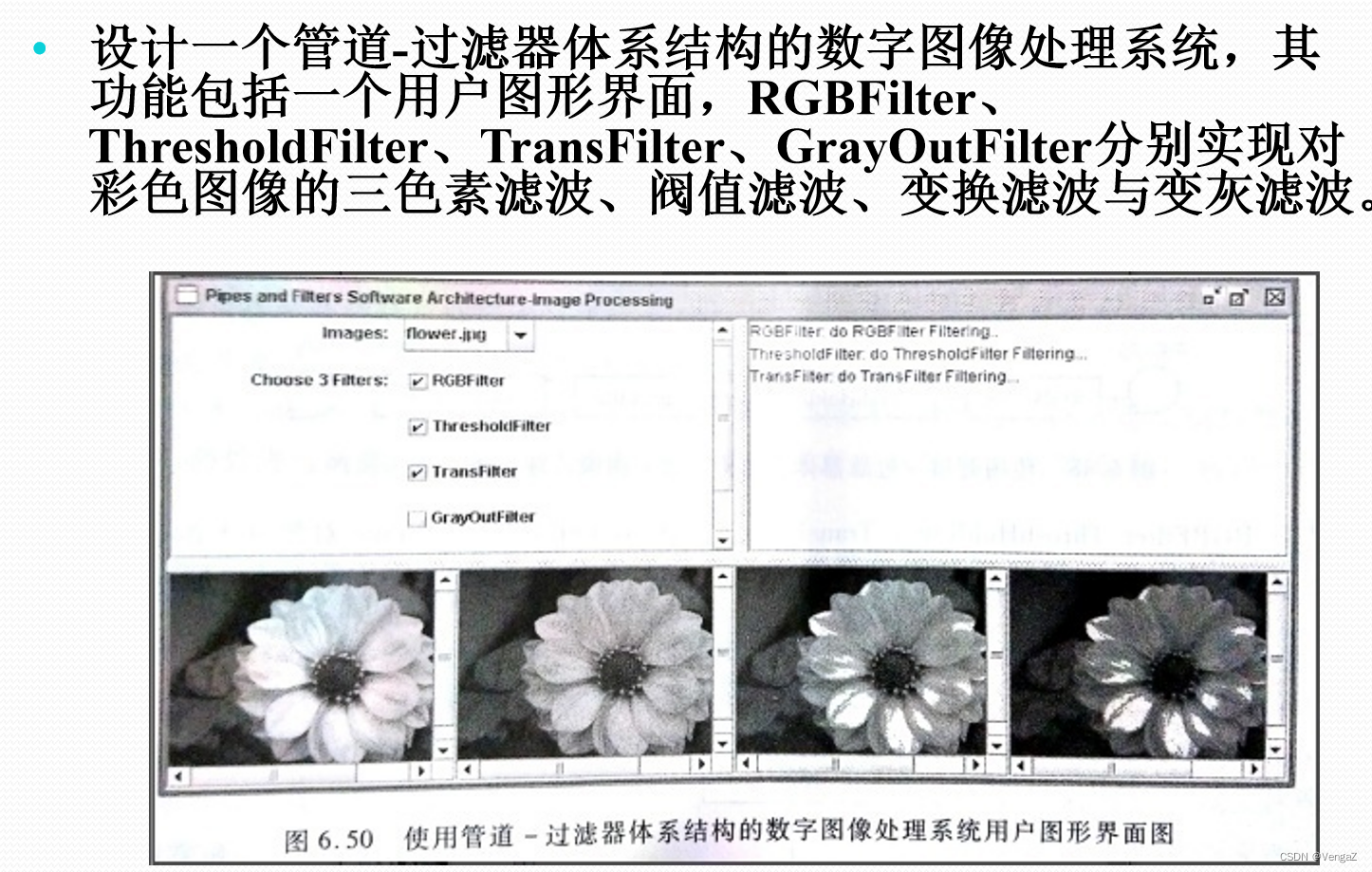
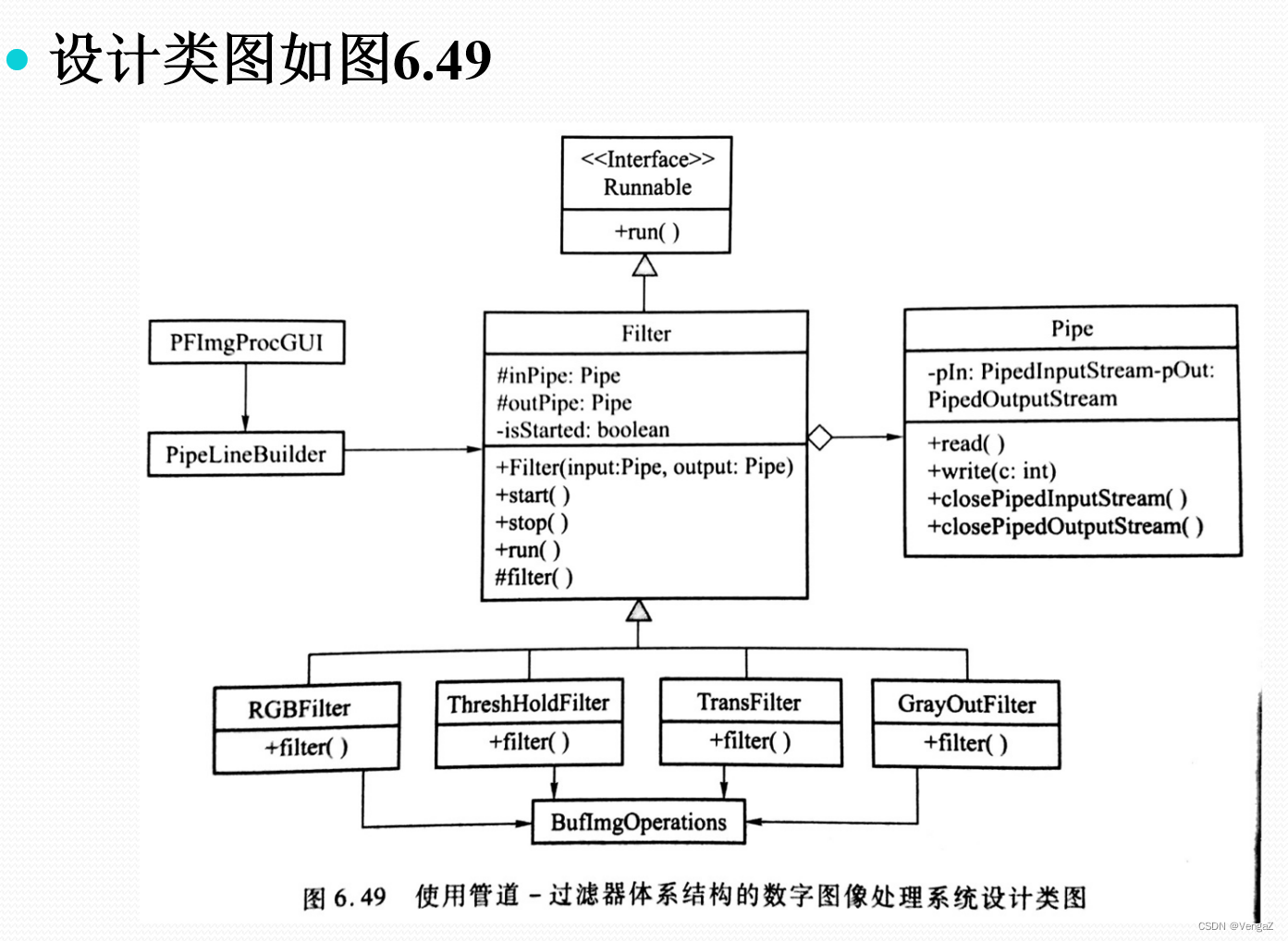
案例分析:数字图像处理系统
不适合于需要共享大量数据的应用设计。
不适合处理交互的应用。当需要增量地显示改变时,这个问题尤为严重;
顺序批处理系统与管道-过滤器软件体系结构的比较


Process Control(控制)


作业


a、逻辑图:

b、设计类图:
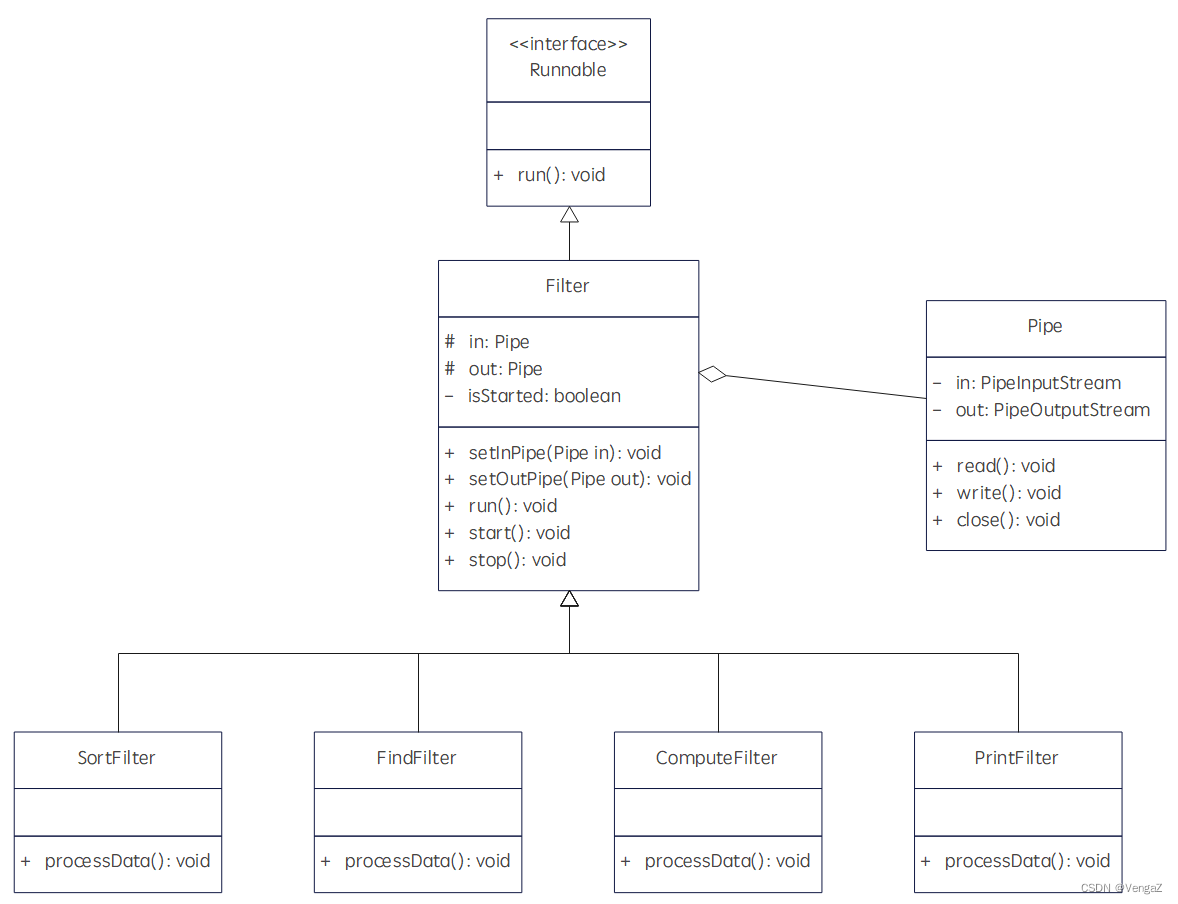
c、每个方法的功能:
Filter类:setInPipe()和setOutPipe()负责设置输入输出管道,Start()和Stop()负责控制过滤器开始工作和暂停工作;
Filter类的子类:processData()负责实现每个子类对应的功能;
Pipe类:read()和write()实现数据的读取与写入,close()实现流的关闭。

a、逻辑图:

b、设计类图:
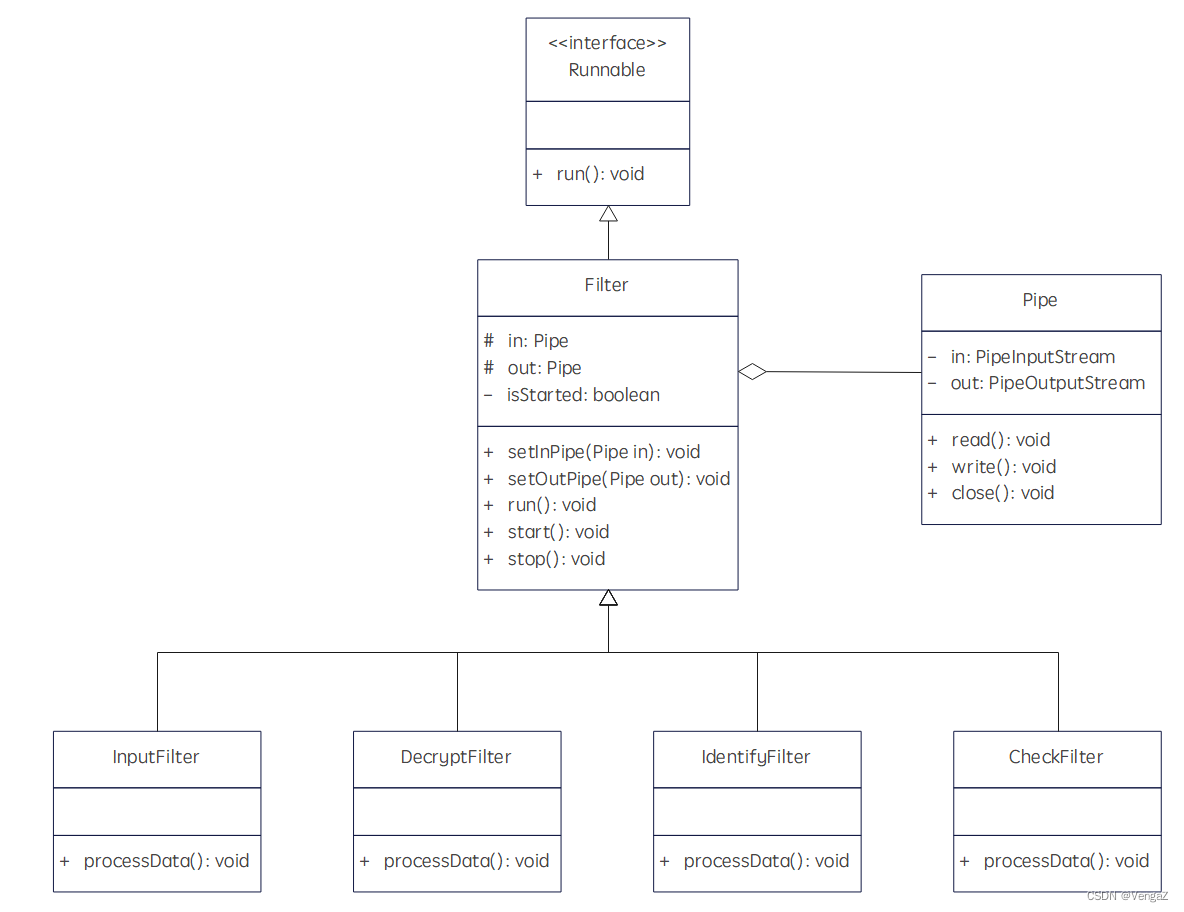
c、每个方法的功能:
Filter类:setInPipe()和setOutPipe()负责设置输入输出管道,Start()和Stop()负责控制过滤器开始工作和暂停工作;
Filter类的子类:processData()负责实现每个子类对应的功能;
Pipe类:read()和write()实现数据的读取与写入,close()实现流的关闭。


![[C++] 万字 - C++异常处理分析介绍: 异常概念、异常抛出与捕获匹配原则、重新抛出、异常安全、异常体系...](https://img-blog.csdnimg.cn/img_convert/d4987f9daa571c9cdbb2716cce51c015.gif)