1、RDD概述
1.1 什么是RDD
RDD(Resilient Distributed Dataset)叫弹性分布式数据集,是Spark中对于分布式数据集的抽象。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
1.2 RDD五大特性
1、一组分区,即是数据集的基本组成单位,标记数据是哪个分区的
2、一个计算每个分区的函数
3、RDD之间的依赖关系
4、一个Partitioner,即RDD的分片函数:控制分区的数据流向(键值对)
5、一个列表,储存存取每个Partition的优先位置(prefered Location)。如果节点和分区个数不对应优先把分区设置在那个节点。移动数据不如移动计算,除非资源不够。
2、RDD编程
2.1 RDD的创建
在Spark中创建RDD的创建方式可以分为三种:
1、从集合中创建
2、从外部储存创建
3、从其他RDD创建
2.1.1 IDEA环境准备
1、创建一个maven工程,工程名称叫SparkCore
2、在pom文件中添加spark-core的依赖和scala的编译插件
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.3.0</version>
</dependency>
</dependencies>
3、如果不想运行时打印大量日志,可以在resources文件夹中添加log4j2.properties文件,并添加日志配置信息
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
# Set the default spark-shell log level to ERROR. When running the spark-shell, the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=ERROR
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=ERROR
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERROR
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERROR
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
2.1.2 创建IDEA快捷键
创建SparkContext和SparkConf时存在的模板代码,我们可以设置idea快捷键一键生成。
1、点击File->Settings…->Editor->Live Templates->output->Live Template

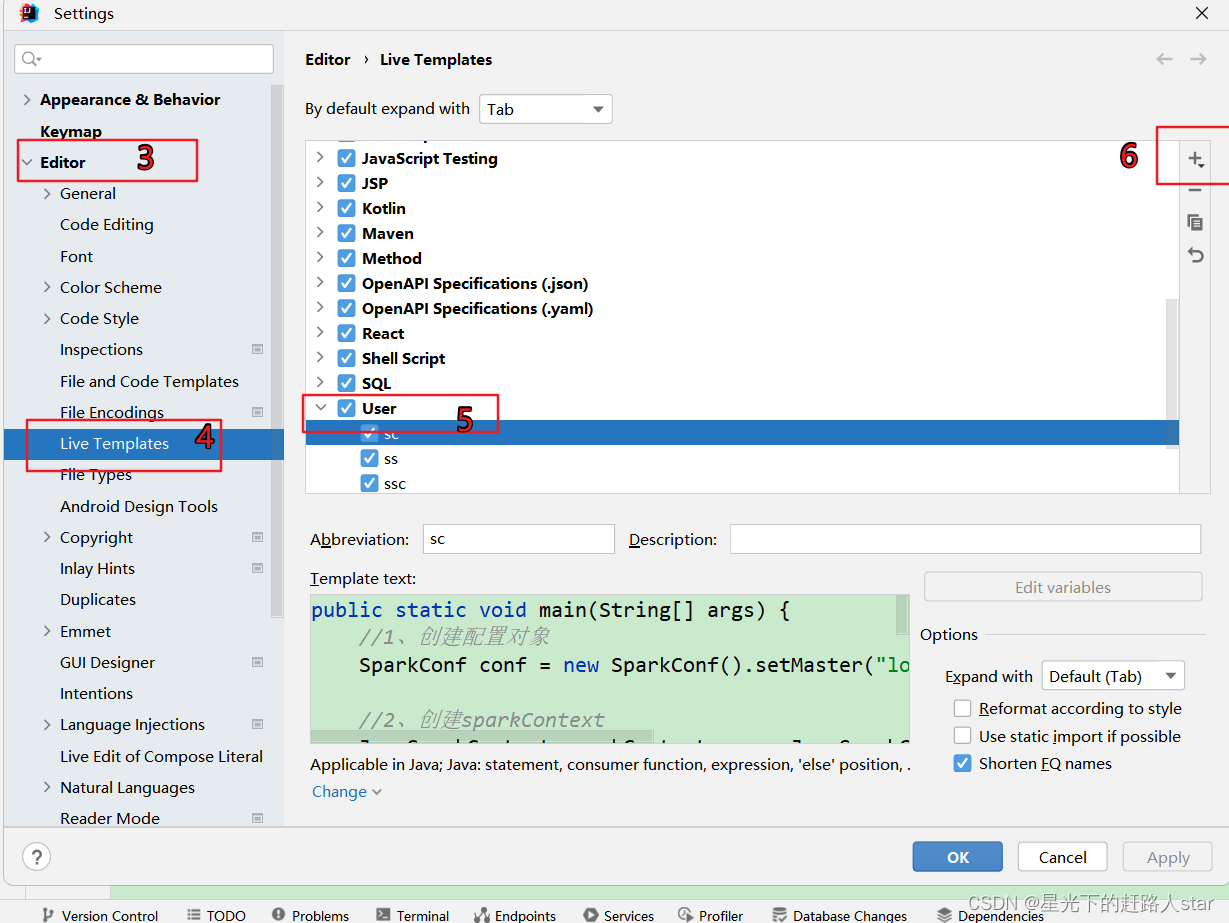
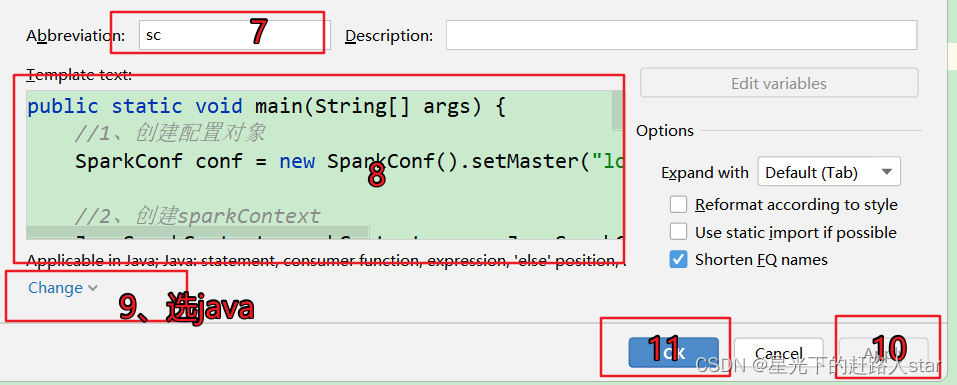
//第八步的代码
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// TODO. 编写代码
// x. 关闭sc
sc.stop();
设置自动导包

2.1.3 从集合中创建
1、创建包com.zhm.spark
2、创建类Test01_createRDDWithList
public class Test01_createRDDWithList {
public static void main(String[] args) {
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
//2、创建sparkContext
JavaSparkContext sparkContext = new JavaSparkContext(conf);
//3、Todo 编写代码--由字符串数组创建RDD
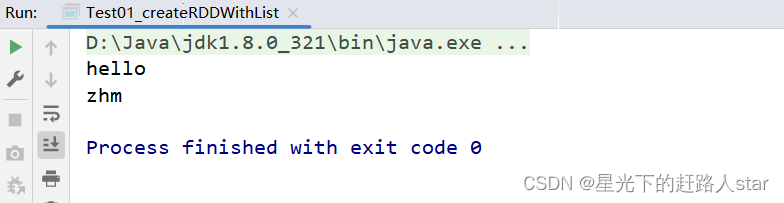
JavaRDD<String> stringRDD = sparkContext.parallelize(Arrays.asList("hello", "zhm"));
//4、收集RDD
List<String> result = stringRDD.collect();
//5、遍历打印输出结果
result.forEach(System.out::println);
//6、 关闭 sparkContext
sparkContext.stop();
}
}
运行结果:
2.1.4从外部储存系统的数据集创建
外部存储系统的数据集创建RDD如:本地的文件系统,还有所有Hadoop支持的数据集,比如HDFS、HBase等。
1、数据准备
在新建的SparkCore项目名称上右键–>新建input文件夹–>在input文件夹上右键–>新建word.txt。编辑如下内容
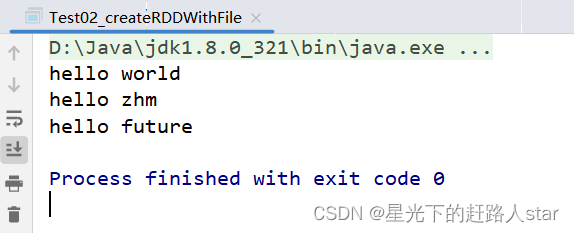
hello world
hello zhm
hello future
2、创建RDD
public class Test02_createRDDWithFile {
public static void main(String[] args) {
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
//2、创建SparkContext
JavaSparkContext javaSparkContext = new JavaSparkContext(conf);
//3、编写代码--读取路径./input下的文件,并创建RDD
JavaRDD<String> fileRDD = javaSparkContext.textFile("./input/word.txt");
//4、收集RDD
List<String> result = fileRDD.collect();
//5、遍历打印输出结果
result.forEach(System.out::println);
//6、关闭 sparkContext
javaSparkContext.stop();
}
}
运行结果:
2.2 分区规则
2.2.1 从集合创建RDD
1、创建一个包名:com.zhm.spark.partition
2、代码验证
package com.zhm.spark.partition;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.util.Arrays;
/**
* @ClassName Test01_ListPartition
* @Description TODO
* @Author Zouhuiming
* @Date 2023/6/27 11:42
* @Version 1.0
*/
public class Test01_ListPartition {
public static void main(String[] args) {
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
//2、创建sparkContext
JavaSparkContext javaSparkContext = new JavaSparkContext(conf);
//3、编写代码
// 0*(5/2)=0 1*(5/2)=2.5 (0,2.5] 左开右闭 1,2
//1*(5/2)=2.5 2*(5/2)=5 (2.5,5]左开右闭 3,4,5
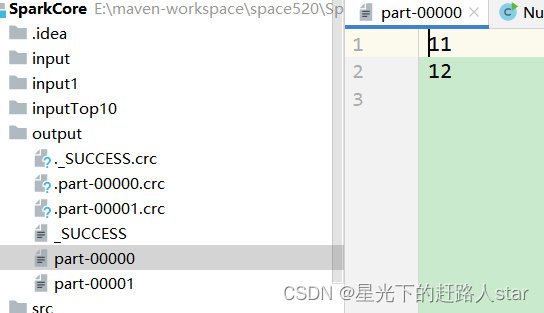
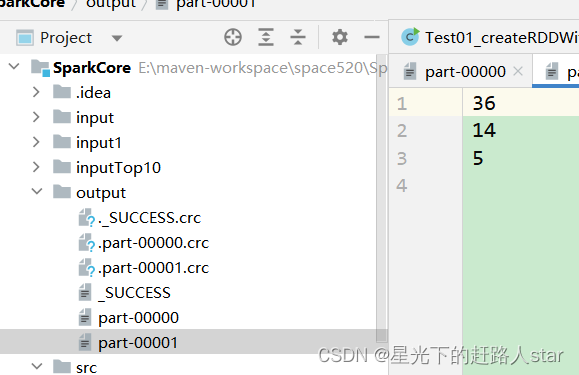
JavaRDD<Integer> integerRDD = javaSparkContext.parallelize(Arrays.asList(11, 12, 36, 14, 05), 2);
// 4、将RDD储存问文件观察文件判断分区
integerRDD.saveAsTextFile("output");
// JavaRDD<String> stringRDD = javaSparkContext.parallelize(Arrays.asList("1", "2", "3", "4", "5"),2);
// stringRDD.saveAsTextFile("output");
//5、关闭javaSparkContext
javaSparkContext.stop();
}
}
运行结果:
2.2.2 从文件创建RDD
package com.zhm.spark.partition;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
/**
* @ClassName Test02_FilePartition
* @Description TODO
* @Author Zouhuiming
* @Date 2023/6/27 13:54
* @Version 1.0
*/
public class Test02_FilePartition {
public static void main(String[] args) {
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
//2、创建sparkContext对象
JavaSparkContext javaSparkContext = new JavaSparkContext(conf);
//3、编写代码
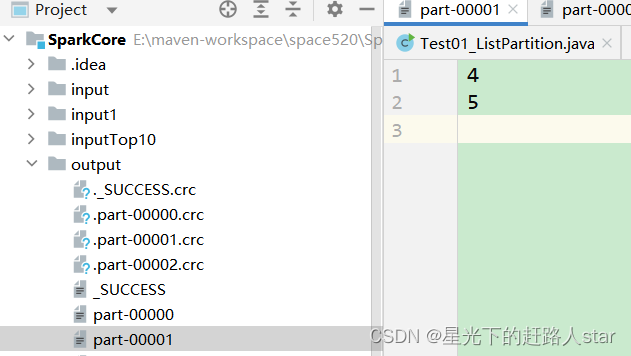
JavaRDD<String> stringJavaRDD = javaSparkContext.textFile("input/1.txt",3);
//4、将stringJavaRDD储存到文件中
stringJavaRDD.saveAsTextFile("output");
//5、关闭资源
javaSparkContext.stop();
}
}
运行结果:

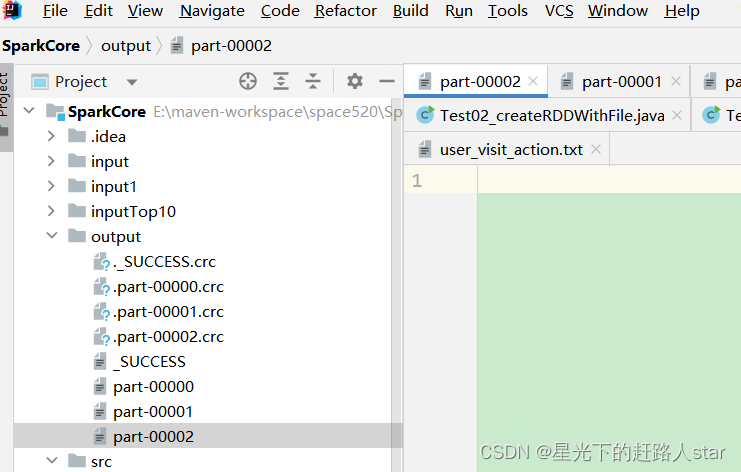
1、分区规则
(1)分区数量的计算方式:
如果: JavaRDD stringJavaRDD = javaSparkContext.textFile(“input/1.txt”,3);

- totalSize = 10 // totalSize指的是文件中的真实长度,这里需要确认你的文件换行符,不同的换行符是不一样的
- goalSize = 10 / 3 = 3(byte) //表示每个分区存储3字节的数据
- 分区数= totalSize/ goalSize = 10 /3 => 3,3,4
- 由于第三个分区的4子节大于3子节的1.1倍,符合hadoop切片1.1倍的策略,因此会多创建一个分区,即3,3,3,1
(2)Spark读取文件,采用的是hadoop的方式读取,所以一行一行读取,跟字节数没有关系
(3)数据读取位置计算是以偏移量为单位来进行计算的。
(4)数据分区的偏移量范围的计算

2.3 Transformation 转换算子
2.3.1 Value类型
创建包名com.zhm.spark.operator.value
2.3.1.1 map()映射
1、用法:给定映射函数f,map(f)以元素为粒度对RDD做数据转换
2、映射函数f:
(1)映射函数f可以带有明确签名函数,也可以是匿名内部函数
(2)映射函数f的参数类型必须与RDD的元素类型保持一致,而输出类型则任由开发者自行决定。
3、解释说明:
函数f是一个函数可以写作匿名子类,它可以接受一个参数。当某个RDD执行map方法时,会遍历该RDD中的每一个数据项,并一次应用f函数,从而产生一个新的RDD。即这个新RDD中的每一个元素都是原来RDD中每一个元素依次应用f函数而得到的。
4、需求:将Lover.txt文件中的每行结尾拼接“Thank you”
5、具体实现
package com.zhm.spark.operator.value;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
/**
* @ClassName StudyMap
* @Description 对单个元素进行操作
* @Author Zouhuiming
* @Date 2023/6/27 14:04
* @Version 1.0
*/
public class StudyMap {
public static void main(String[] args) {
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
//2、创建sparkContext
JavaSparkContext sparkContext = new JavaSparkContext(conf);
//3、编写代码 对元素进行操作
JavaRDD<String> stringJavaRDD = sparkContext.textFile("input/Lover.txt");
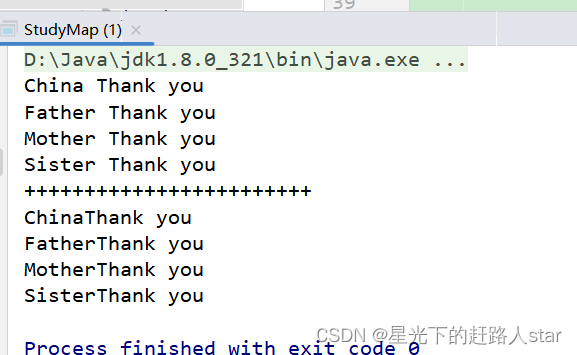
JavaRDD<String> mapRDD = stringJavaRDD.map(s -> s + " Thank you");
JavaRDD<String> mapRDD1 = stringJavaRDD.map(new Function<String, String>() {
@Override
public String call(String s) throws Exception {
return s + "Thank you";
}
});
//4、遍历打印输出结果
mapRDD.collect().forEach(System.out::println);
System.out.println("++++++++++++++++++++++++");
mapRDD1.collect().forEach(System.out::println);
//5 关闭 sparkContext
sparkContext.stop();
}
}
运行结果
2.3.1.2 flatMap()扁平化
flatMap其实和map算子一样,flatMap也是用来做数据映射的。
1、用法:flatMap(f),以元素为粒度,对RDD进行数据转换。
2、特点:
不同于map映射函数f的类型是(元素)->(元素)
flatMap的映射函数类型是(元素)->(集合)
3、过程:
(1)以元素为单位,创建集合
(2)去掉集合“外包装”,提前集合元素
4、功能说明
与map操作类似,将RDD中的每一个元素通过应用f函数依次转换为新的元素,并封装到RDD中。
区别:在flatMap操作中,f函数的返回值是一个集合,并且会将每一个该集合中的元素拆分出来放到新的RDD中。
5、案例说明:创建一个集合,集合里面存储的还是子集合,把所有子集合中数据取出放入到一个大的集合中。
6、具体实现
package com.zhm.spark.operator.value;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
/**
* @ClassName StudyFLatMap
* @Description 炸裂
* @Author Zouhuiming
* @Date 2023/6/27 14:09
* @Version 1.0
*/
public class StudyFLatMap {
public static void main(String[] args) {
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
//2、创建sparkContext
JavaSparkContext sparkContext = new JavaSparkContext(conf);
//3、编写逻辑代码--创建列表arrayList,其中每个元素的类型是字符串列表
ArrayList<List<String>> arrayList = new ArrayList<>();
arrayList.add(Arrays.asList("1","2","3"));
arrayList.add(Arrays.asList("4","5","6"));
arrayList.add(Arrays.asList("7","8","9"));
//4、根据arraylist创建RDD
JavaRDD<List<String>> listJavaRDD = sparkContext.parallelize(arrayList);
//5、使用flatMap将RDD中每个元素进行转换打散,泛型为打散之后的数据
JavaRDD<String> stringJavaRDD = listJavaRDD.flatMap(new FlatMapFunction<List<String>, String>() {
@Override
public Iterator<String> call(List<String> strings) throws Exception {
return strings.iterator();
}
});
//6、收集RDD,并打印输出
System.out.println("---------输出集合构建的RDD之flatMap测试------------");
stringJavaRDD.collect().forEach(System.out::println);
//Todo 从文件读取数据的话要自己实现将元素转换为集合
//7、读取文件中的数据
JavaRDD<String> javaRDD = sparkContext.textFile("input/word.txt");
//8、将每行数据按空格切分之后,转换为一个list数组再将String数组转换为list集合返回list集合的迭代器
JavaRDD<String> stringJavaRDD1 = javaRDD.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) throws Exception {
String[] split = s.split(" ");
return Arrays.asList(split).iterator();
}
});
//9、收集RDD,并打印输出
System.out.println("-----输出文件系统构建的RDD之flatMap测试---");
stringJavaRDD1.collect().forEach(s -> {
System.out.println(s);
});
//10 关闭 sparkContext
sparkContext.stop();
}
}
运行结果
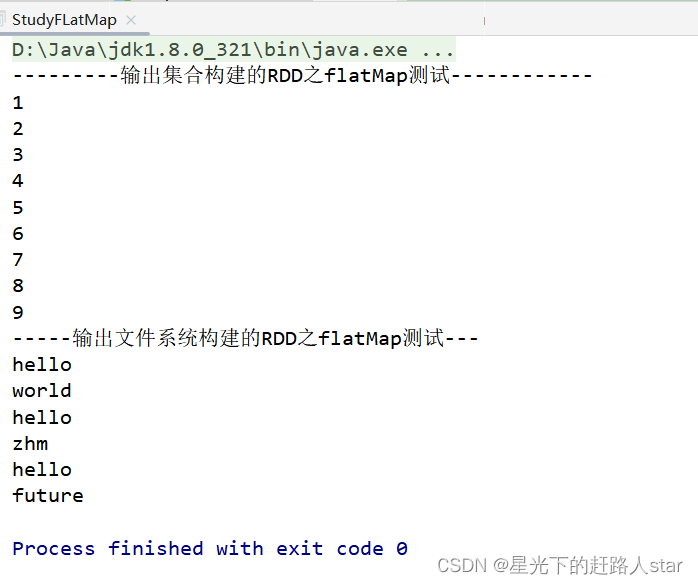
2.3.1.3 filter()过滤
1、用法:filter(f),以元素为粒度对RDD执行判定函数f
2、判定函数
(1)f,指的是类型为(RDD元素类型)=> (Boolean)的函数
(2)判定函数f的形参类型,必须与RDD的元素类型保持一致,而f的返回结果,只能是True或者False。
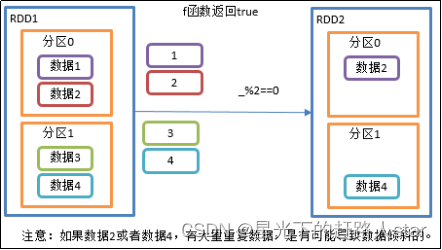
3、功能说明
(1)在任何一个RDD上调用filter(f)方法时,会对该RDD中每一个元素应用f函数
(2)作用是保留RDD中满足f(即f返回值为True)的数据,过滤掉不满足f(即f返回值为false)的数据。
4、需求说明:创建一个RDD,过滤出对2取余等于0的数据
5、代码实现
package com.zhm.spark.operator.value;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import java.util.Arrays;
/**
* @ClassName StudyFilter
* @Description 过滤元素
* @Author Zouhuiming
* @Date 2023/6/27 14:26
* @Version 1.0
*/
public class StudyFilter {
public static void main(String[] args) {
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
//2、创建sparkContext
JavaSparkContext sparkContext = new JavaSparkContext(conf);
//3、Todo 根据集合创建RDD
JavaRDD<Integer> javaRDD = sparkContext.parallelize(Arrays.asList(1, 2, 3, 4, 5), 2);
// 根据数据与2取模,过滤掉余数不是0的数据元素
JavaRDD<Integer> filterRDD = javaRDD.filter(new Function<Integer, Boolean>() {
@Override
public Boolean call(Integer integer) throws Exception {
return integer % 2 == 0;
}
});
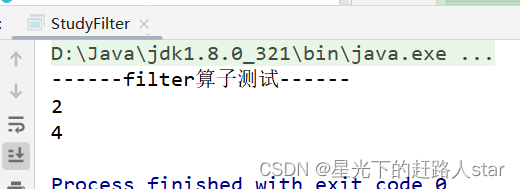
System.out.println("------filter算子测试------");
filterRDD.collect().forEach(System.out::println);
//x 关闭 sparkContext
sparkContext.stop();
}
}
运行结果:
2.3.1.4 groupBy()分组
1、用法:groupBy(f) ,以元素为粒度对每个元素执行函数f。
2、函数f:
(1)函数f为用户自定义实现内容,返回值任意
(2) 函数返回值为算子groupBy返回值的key,元素为value。
(3)算子groupBy的返回值为新的重新分区的K—V类型RDD
3、功能说明:分组,按照传入函数的返回值进行分组。将相同的key对应的值放入一个迭代器。
4、案例说明:创建一个RDD,按照元素模以2的值进行分组。
5、代码实现
package com.zhm.spark.operator.value;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import java.util.Arrays;
/**
* @ClassName StudyGroupBy
* @Description TODO
* @Author Zouhuiming
* @Date 2023/6/27 14:32
* @Version 1.0
*/
public class StudyGroupBy {
public static void main(String[] args) throws InterruptedException {
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
//2、创建sparkContext
JavaSparkContext sparkContext = new JavaSparkContext(conf);
//3、Todo 根据集合创建RDD
JavaRDD<Integer> javaRDD = sparkContext.parallelize(Arrays.asList(1, 2, 3, 4, 5), 2);
//4、储存到文件查看groupby之前的情况
javaRDD.saveAsTextFile("outputGroupByBefore");
//5、对RDD执行groupBy操作,计算规则是value%2
JavaPairRDD<Integer, Iterable<Integer>> integerIterableJavaPairRDD = javaRDD.groupBy(new Function<Integer, Integer>() {
@Override
public Integer call(Integer integer) throws Exception {
return integer % 2;
}
});
//6、类型可以容易修改
JavaPairRDD<Boolean, Iterable<Integer>> booleanIterableJavaPairRDD = javaRDD.groupBy(new Function<Integer, Boolean>() {
@Override
public Boolean call(Integer integer) throws Exception {
return integer % 2 == 0;
}
});
//7、输出结果
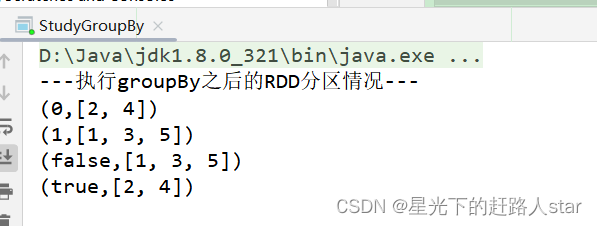
System.out.println("---执行groupBy之后的RDD分区情况---");
integerIterableJavaPairRDD.collect().forEach(System.out::println);
booleanIterableJavaPairRDD.collect().forEach(System.out::println);
//x 关闭 sparkContext
Thread.sleep(1000000000L);
sparkContext.stop();
}
}
运行结果:
6、说明:
(1)groupBy会存在shuffle过程
(2)shuffle:将不同的分区数据进行打乱重组的过程
(3)shuffle一定会落盘。可以在local模式下执行程序,通过4040看效果。
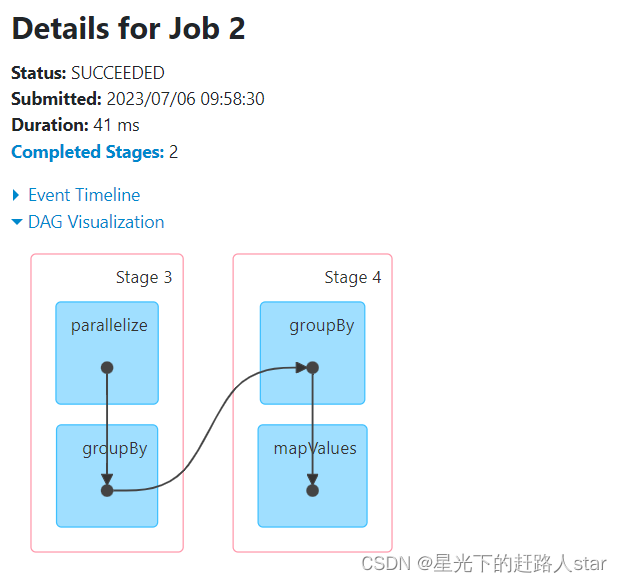
2.3.1.5 distinct()去重
1、用法:distinct(numPartitions), 实现对RDD进行分布式去重。
2、参数numPartitions:指定去重后的RDD的分区个数。
3、功能说明:对内部的元素去重,并将去重后的元素放到新的RDD中。
4、代码实现
package com.zhm.spark.operator.value;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.util.Arrays;
/**
* @ClassName StudyDistinct
* @Description 去重
* @Author Zouhuiming
* @Date 2023/6/27 14:44
* @Version 1.0
*/
public class StudyDistinct {
public static void main(String[] args) throws InterruptedException {
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
//2、创建sparkContext
JavaSparkContext sparkContext = new JavaSparkContext(conf);
//3、Todo 根据集合创建RDD
JavaRDD<Integer> javaRDD = sparkContext.parallelize(Arrays.asList(1, 2, 3, 1, 2, 3, 4, 5, 6), 2);
//4、使用distinct算子实现去重,底层使用分布式去重,慢但是不会OOM
JavaRDD<Integer> distinctRDD = javaRDD.distinct();
//5、收集打印
distinctRDD.collect().forEach(System.out::println);
Thread.sleep(100000000L);
//6 关闭 sparkContext
sparkContext.stop();
}
}
运行结果:

5、distinct会存在shuffle过程。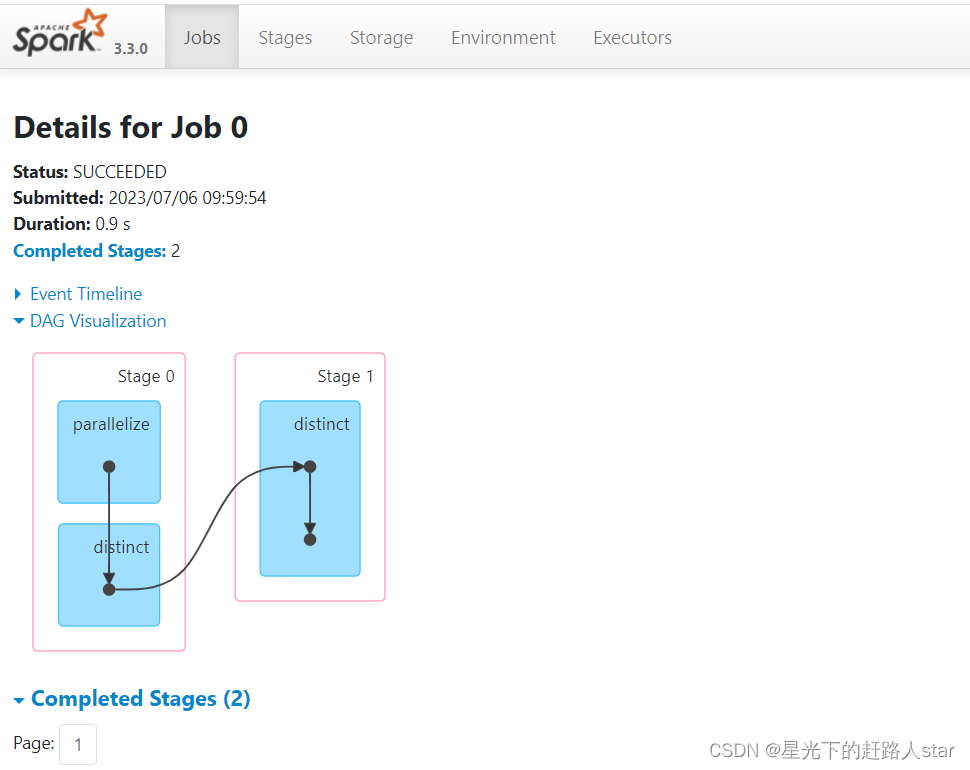
2.3.1.6 sortBy()排序
1、用法:RDD.sortBy(f, ascending, numpartitions)
2、参数介绍:
(1)函数f: 对每个元素都执行函数f,返回值类型和元素中的类型一致
(2)ascending:数据类型为Boolean,默认是True,参数决定了排序后,RDD中的元素的排列顺序,即升序/降序
(3)numpartitions:排序后的RDD的分区数。
3、功能说明
该操作用于排序数据。在排序之前,可以将数据通过f函数进行处理,之后按照f函数处理的结果进行排序,默认为正序排列。默认排序后新产生的RDD的分区数与原RDD的分区数一致。Spark的排序结果是全局有序。
4、案例需求说明:创建一个RDD,按照数字大小分别实现正序和倒序排序
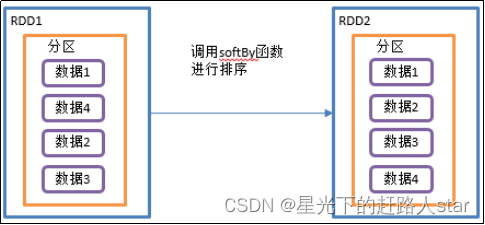
5、代码实现
package com.zhm.spark.operator.value;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import java.util.Arrays;
/**
* @ClassName StudySortBy
* @Description TODO
* @Author Zouhuiming
* @Date 2023/6/27 14:48
* @Version 1.0
*/
public class StudySortBy {
public static void main(String[] args) {
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
//2、创建sparkContext
JavaSparkContext sparkContext = new JavaSparkContext(conf);
//3、Todo
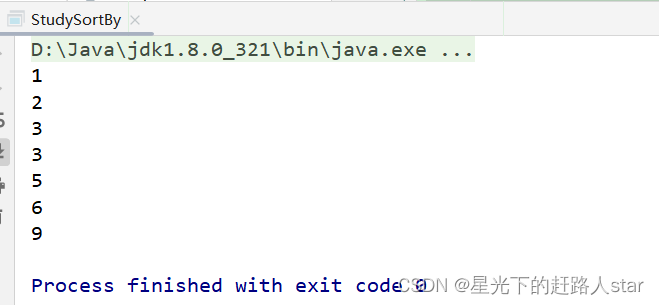
JavaRDD<Integer> javaRDD = sparkContext.parallelize(Arrays.asList(1, 3, 2, 9, 6, 5, 3), 2);
//4、使用sortBy算子对javaRDD进行排序(泛型->以谁作为标准排序,true->为正序)
JavaRDD<Integer> javaRDD1 = javaRDD.sortBy(new Function<Integer, Integer>() {
@Override
public Integer call(Integer integer) throws Exception {
return integer;
}
}, true, 2);
//5、收集输出
javaRDD1.collect().forEach(System.out::println);
//x 关闭 sparkContext
sparkContext.stop();
}
}
运行结果:
2.3.2 Key-Value类型
创建包名:com.zhm.spark.operator.keyvalue
2.3.2.1 mapToPair()
1、用法:RDD.mapToPair(f) ,对父RDD中的每条记录都执行函数f,得到新的记录<k, v>
2、作用:将Value类型转换为key-Value类型
3、代码实现
package com.zhm.spark.operator.keyvalue;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
/**
* @ClassName StudyMapToPair
* @Description 将不是kv类型的RDD转换为kv类型的RDD
* @Author Zouhuiming
* @Date 2023/6/27 14:52
* @Version 1.0
*/
public class StudyMapToPair {
public static void main(String[] args) {
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
//2、创建sparkContext
JavaSparkContext sparkContext = new JavaSparkContext(conf);
//3、Todo
JavaRDD<Integer> javaRDD = sparkContext.parallelize(Arrays.asList(1, 2, 3, 4, 5, 6), 2);
//4、使用mapToPair算子对javaRDD转换为kv类型的RDD
JavaPairRDD<Integer, Integer> pairRDD = javaRDD.mapToPair(new PairFunction<Integer, Integer, Integer>() {
@Override
public Tuple2<Integer, Integer> call(Integer integer) throws Exception {
return new Tuple2<>(integer, integer);
}
});
//5、收集输出
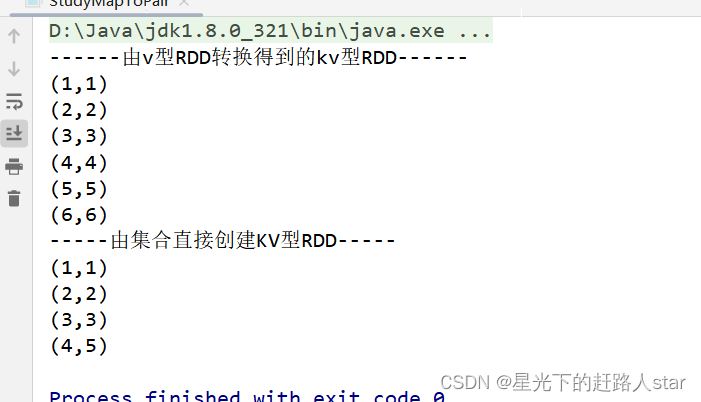
System.out.println("------由v型RDD转换得到的kv型RDD------");
pairRDD.collect().forEach(System.out::println);
//Todo 由集合直接创建KV型RDD
JavaPairRDD<Integer, Integer> integerIntegerJavaPairRDD = sparkContext.parallelizePairs(Arrays.asList(new Tuple2<>(1, 1), new Tuple2<>(2, 2), new Tuple2<>(3, 3), new Tuple2<>(4, 5)));
//6、收集输出
System.out.println("-----由集合直接创建KV型RDD-----");
integerIntegerJavaPairRDD.collect().forEach(System.out::println);
sparkContext.stop();
}
}
运行结果:
2.3.2.2 mapValues()只对Value进行操作
1、用法:newRDD = oldRdd.mapValues(func)
2、参数函数func:自定义实现的函数,仅对oldRdd中(k,v)数据的v作用。
3、功能说明:针对于(K,V)形式的类型只对V进行操作
4、需求说明:创建一个pairRDD,并将value添加字符尾缀" Fighting"
5、代码实现
package com.zhm.spark.operator.keyvalue;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import scala.Tuple2;
import java.util.Arrays;
/**
* @ClassName StudyMapValues
* @Description 对kv类型的RDD的v进行操作
* @Author Zouhuiming
* @Date 2023/6/27 15:01
* @Version 1.0
*/
public class StudyMapValues {
public static void main(String[] args) {
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
//2、创建sparkContext
JavaSparkContext sparkContext = new JavaSparkContext(conf);
//3、Todo
JavaPairRDD<Integer, Integer> javaPairRDD = sparkContext.parallelizePairs(Arrays.asList(new Tuple2<>(1, 1), new Tuple2<>(2, 2), new Tuple2<>(3, 3),
new Tuple2<>(4, 4), new Tuple2<>(5, 5)), 2);
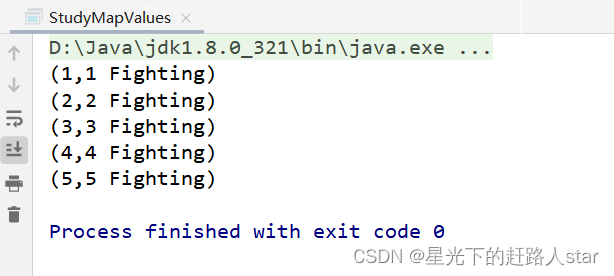
//4、为kv型RDD的v拼接尾缀"Fighting"
JavaPairRDD<Integer, String> resultRDD = javaPairRDD.mapValues(new Function<Integer, String>() {
@Override
public String call(Integer integer) throws Exception {
return integer + " Fighting";
}
});
//5、打印收集
resultRDD.collect().forEach(System.out::println);
//6 关闭 sparkContext
sparkContext.stop();
}
}
运行结果:
2.3.2.3 groupByKey()按照K重新分组
1、用法:KVRDD.groupByKey();
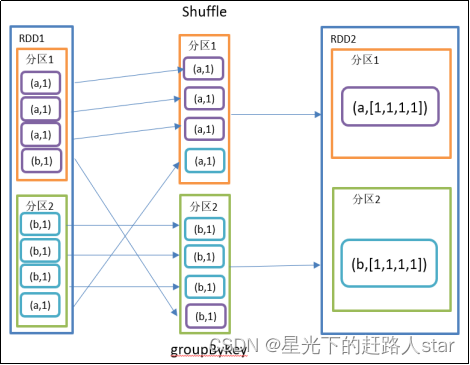
2、功能说明
groupByKey对每个key进行操作,但只生成一个结果集,并不进行聚合。
该操作可以指定分区器或者分区数(默认使用HashPartitioner)
3、需求说明
统计单词出现次数
4、代码实现
package com.zhm.spark.operator.keyvalue;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
/**
* @ClassName StudyGroupByKey
* @Description 分组聚合
* @Author Zouhuiming
* @Date 2023/6/27 15:07
* @Version 1.0
*/
public class StudyGroupByKey {
public static void main(String[] args) {
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
//2、创建sparkContext
JavaSparkContext sparkContext = new JavaSparkContext(conf);
//3、Todo
JavaRDD<String> javaRDD = sparkContext.parallelize(Arrays.asList("a", "a", "a", "b", "b", "b", "b", "a"), 2);
//4、根据JavaRDD创建KVRDD
JavaPairRDD<String, Integer> pairRDD = javaRDD.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<>(s, 1);
}
});
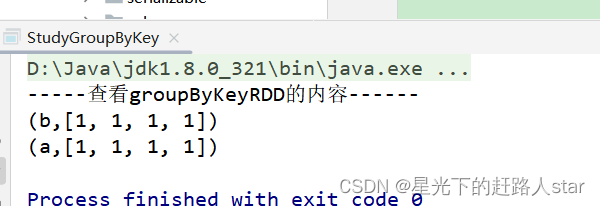
//5、聚合相同的key
JavaPairRDD<String, Iterable<Integer>> groupByKeyRDD = pairRDD.groupByKey();
//6、收集并输出RDD内容
System.out.println("-----查看groupByKeyRDD的内容------");
groupByKeyRDD.collect().forEach(System.out::println);
sparkContext.stop();
}
}
5、运行结果:
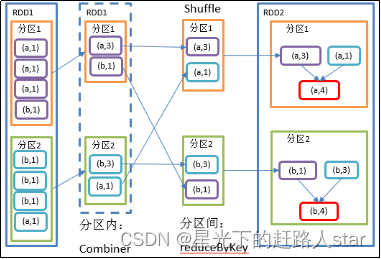
2.3.2.4 reduceByKey()按照K聚合V
1、用法:KVRDD.reduceByKey(f);
2、功能说明:将RDD[K,V]中的元素按照相同的K的V进行聚合。存在多种重载形式,可设置新RDD的分区数。
3、需求说明:统计单词出现次数
4、代码实现
package com.zhm.spark.operator.keyvalue;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
/**
* @ClassName StudyReduceByKey
* @Description TODO
* @Author Zouhuiming
* @Date 2023/6/27 15:15
* @Version 1.0
*/
public class StudyReduceByKey {
public static void main(String[] args) {
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
//2、创建sparkContext
JavaSparkContext sparkContext = new JavaSparkContext(conf);
//3、Todo
JavaRDD<String> javaRDD = sparkContext.parallelize(Arrays.asList("a", "a", "a", "b", "b", "b", "b", "a"), 2);
//4、根据JavaRDD创建KVRDD
JavaPairRDD<String, Integer> javaPairRDD = javaRDD.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<>(s, 1);
}
});
//5、聚合相同的key,统计单词出现的次数
JavaPairRDD<String, Integer> result = javaPairRDD.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer integer, Integer integer2) throws Exception {
return integer + integer2;
}
});
//6、收集并输出RDD的内容
System.out.println("查看--result--的内容");
result.collect().forEach(System.out::println);
//x 关闭 sparkContext
sparkContext.stop();
}
}
运行结果:
2.3.2.5 reduceByKey和groupByKey区别
1、educeByKey:按照key进行聚合,在shuffle之前有combine(预聚合)操作,返回结果是RDD[K,V]。
2、 groupByKey:按照key进行分组,直接进行shuffle。
3、在不影响业务逻辑的前提下,优先选用reduceByKey。求和操作不影响业务逻辑,求平均值影响业务逻辑。影响业务逻辑时建议先对数据类型进行转换再合并。
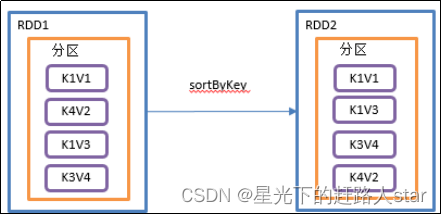
2.3.2.6 sortByKey()按照K进行排序
1、用法:kvRDD.sortByKey(true/false)
2、功能说明:在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD。
3、参数说明:true:为升序排列,false为降序排列
4、需求说明:创建一个pairRDD,按照key的正序和倒序进行排序
5、代码实现
package com.zhm.spark.operator.keyvalue;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
/**
* @ClassName StudySortByKey
* @Description TODO
* @Author Zouhuiming
* @Date 2023/6/27 15:47
* @Version 1.0
*/
public class StudySortByKey {
public static void main(String[] args) {
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
//2、创建sparkContext
JavaSparkContext sparkContext = new JavaSparkContext(conf);
//3、Todo 创建kvRDD
JavaPairRDD<Integer, String> javaPairRDD = sparkContext.parallelizePairs(Arrays.asList(new Tuple2<>(4, "d"), new Tuple2<>(3, "c"), new Tuple2<>(1, "a"),
new Tuple2<>(2, "b")));
//4、收集输出
System.out.println("排序前:");
javaPairRDD.collect().forEach(System.out::println);
//5、对RDD按照key进行排序
JavaPairRDD<Integer, String> sortByKeyRDD = javaPairRDD.sortByKey(true);
//收集输出
System.out.println("排序后:");
sortByKeyRDD.collect().forEach(System.out::println);
//x 关闭 sparkContext
sparkContext.stop();
}
}
运行结果:

2.4 Action行动算子
行动算子是触发了整个作业的执行。因为转换算子都是懒加载,并不会立即执行。
创建包名:com.zhm.spark.operator.action
2.4.1 collect():以数组的形式返回数据集
1、用法:RDD.collect();
2、功能说明:在驱动程序中,以数组Array的形式返回数据集的所有元素。

注意:所以的数据都会被拉取到Driver端,慎用
3、需求说明:创建一个RDD,并将RDD内容收集到Driver端打印(代码实现在最后面)
2.4.2 count()返回RDD中元素个数
1、用法:RDD.count(),返回值为Long类型
2、功能说明:返回RDD中元素的个数

3、需求说明:创建一个RDD,统计该RDD的条数(代码实现在最后面)
2.4.3 first()返回RDD中的第一个元素
1、用法:RDD.first(), 返回值类型是元素类型
2、功能说明:返回RDD中的第一个元素
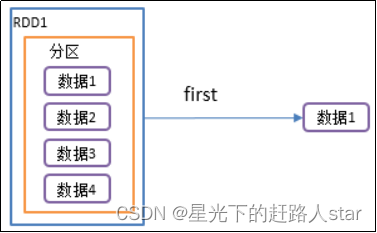
3、需求说明:创建一个RDD,返回该RDD中的第一个元素(代码实现在最后面)
2.4.4 take()返回由RDD前n个元素组成的数组
1、RDD.take(int num), 返回值为RDD中元素类型的List列表
2、功能说明:返回一个由RDD的前n个元素组成的数组
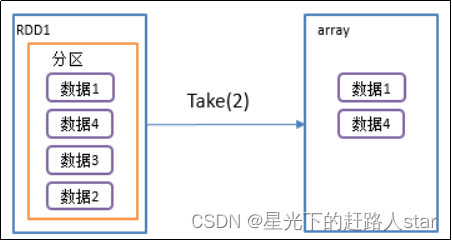
3、需求说明:创建一个RDD,取出前3个元素(代码实现在最后面)
2.4.5 countByKey()统计每种key的个数
1、用法:pairRDD.countByKey(), 返回值类型为Map<[RDD中key的类型] , Long>
2、功能说明:统计每种key的个数
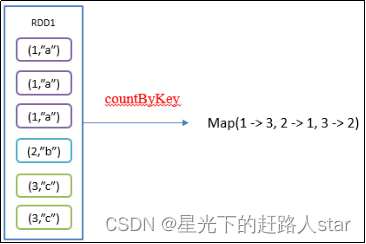
3、需求说明:创建一个PairRDD,统计每种key的个数(代码实现在最后面)
2.4.6 save相关算子
1、saveAsTextFile(path)
(1)功能:将RDD保存成Text文件
(2)功能说明:将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本。
2、 saveAsObjectFile(path)
(1)功能:序列化成对象保存到文件
(2)功能说明:用于将RDD中的元素序列化成对象,存储到文件中。
(代码实现在最后面)
2.4.7 foreach()遍历RDD中每一个元素
1、功能:遍历RDD中的每个元素,并依次应用函数

2、需求说明:创建一个RDD,对每个元素进行打印
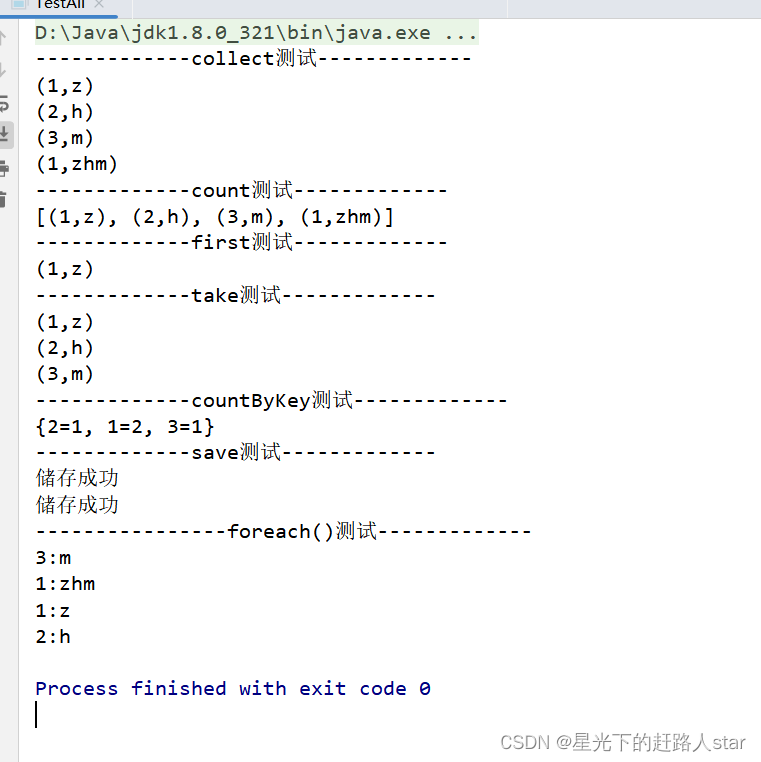
2.4.8 所有的代码实现
package com.zhm.spark.operator.action;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
import java.util.Arrays;
/**
* @ClassName TestAll
* @Description TODO
* @Author Zouhuiming
* @Date 2023/6/28 13:47
* @Version 1.0
*/
public class TestAll {
public static void main(String[] args) {
//设置往HDFS储存数据的用户名
System.setProperty("HADOOP_USER_NAME","zhm");
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("TestAll");
//2、创建sparkContext
JavaSparkContext sparkContext = new JavaSparkContext(conf);
//3、获取RDD
// JavaRDD<Integer> javaRDD = sparkContext.parallelize(Arrays.asList(1, 2, 3, 4, 5, 6, 7));
JavaPairRDD<Integer, String> javaPairRDD = sparkContext.parallelizePairs(Arrays.asList(new Tuple2<>(1, "z"), new Tuple2<>(2, "h"), new Tuple2<>(3, "m"),
new Tuple2<>(1, "zhm")
),2);
//4、collect():以数组的形式返回数据集
//注意:所有的数据都会被拉取到Driver端,慎用
System.out.println("-------------collect测试-------------");
javaPairRDD.collect().forEach(System.out::println);
//5、count():返回RDD中元素个数
System.out.println("-------------count测试-------------");
System.out.println(javaPairRDD.collect());
//6、first():返回RDD中第一个元素
System.out.println("-------------first测试-------------");
System.out.println(javaPairRDD.first());
//7、take():返回RDD前n个元素组成的数组
System.out.println("-------------take测试-------------");
javaPairRDD.take(3).forEach(System.out::println);
//8、countByKey统计每种key的个数
System.out.println("-------------countByKey测试-------------");
System.out.println(javaPairRDD.countByKey());
//9、save相关的算子
//以文本格式储存数据
javaPairRDD.saveAsTextFile("outputText");
//以对象储存数据
javaPairRDD.saveAsObjectFile("outputObject");
//10、foreach():遍历RDD中每一个元素
javaPairRDD.foreach(new VoidFunction<Tuple2<Integer, String>>() {
@Override
public void call(Tuple2<Integer, String> integerStringTuple2) throws Exception {
System.out.println(integerStringTuple2._1+":"+integerStringTuple2._2);
}
});
//x 关闭 sparkContext
sparkContext.stop();
}
}
运行结果