文章目录
- 前言
- 1. batchsize和推理速度的关系
- 2. 修改batchsize尝试
- 2.1 benifit(好处)
- 2.1 编码batchsize下的推理
- 2.2 发现问题
- 2.2.1 推理结束后,占用显存不释放。
- 2.3 其它有用的参数设置
前言
yolov5的detect.py 是默认batchsize=1的,而直接修改batchsize为更大的值,会使detect.py 不工作.
因此本篇文章想解决两个问题:
1.设置多大的bz合适
2.如何修改detect.py 使其满足自定义的bz
1. batchsize和推理速度的关系
ref:https://github.com/ultralytics/yolov5/discussions/6649
ref:https://docs.google.com/spreadsheets/d/1Nm3jofjdgKja0AZHV8Jk_m8TgcF7jenCSA06DuEG2C0
基于.pt的测试文档
基于.pt 格式的推理速度。

结论:较小的模型增大bz收益不明显,模型越大,增大bz收益越明显。

例如,
对s模型 bz = 1 推理用时为1.0 bz= 8 推理用时 7 32时 推理用时 11.7 128 15.2
对m模型 bz = 1 推理用时为1.0 bz= 8 推理用时 7 32时 推理用时 9.2 128 8.4
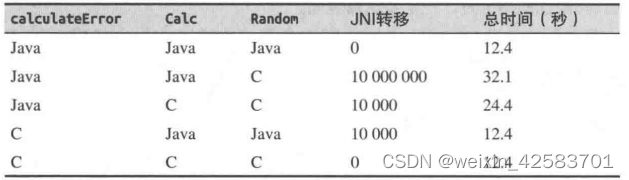
有一个大佬还做了如下测试:

同时大佬还提到,设备硬件不同,结果也不同。

2. 修改batchsize尝试
2.1 benifit(好处)
由1batchsize和推理速度的关系 我们可以看到,做batchsize的增大,即批量传入图片做推理对性能提升是有帮助的。
然后去github上找好的范例:
相关的有
- https://github.com/ultralytics/yolov5/issues/7565

疑问是不清楚它是并行推理还是串行推理,这个截图的入参方式,我猜测大概率是串行的,没用。
但是这个issue给了一个很好的指引,它是想确认:

作者的回复是:train 用640*640,然后export和deploy 用你需要的矩形。
这也是回答了我长久以来心中的疑问。
2.https://github.com/ultralytics/yolov5/issues/10362
这个issue 提到在export的时候可以dynamic batchsize,这样可以不固定batchsize。
3.https://github.com/ultralytics/yolov5/issues/9511
这个issue和我想做的事情完全一样。

第一个红框说的是,detect.py run inference at batch-size 1, 但是 you can use PyTorch Hub models to run inference at any batchsize
这里和作者讨论的事,可以在detect.py 直接修改batch_size, 我的版本yolov5 tag 6.1, 它就没有batchsize这个参数。

2.1 编码batchsize下的推理
根据以上的回答,yolov5的作者把我们引向了这里:https://docs.ultralytics.com/yolov5/
重点看这里:https://docs.ultralytics.com/yolov5/tutorials/pytorch_hub_model_loading/
import torch
path_weight = '/home/jianming_ge/workplace/yolov5_template/yolov5_template/weights/yolov5m6.pt'
model = torch.hub.load('/home/jianming_ge/workplace/yolov5_template/yolov5_template', 'custom', path=path_weight, source='local',autoshape = True)
img_path1 = "/home/jianming_ge/workplace/yolov5_template/yolov5_template/data/images11/bus.jpg"
# 循环32次执行
imgs = [Image.open(img_path1)]
%timeit [model(imgs) for _ in range(32)] # batch-size 1
# batch_size = 32 执行
%timeit model(imgs * 32) # batch-size 32

32张单图片 耗时 739ms
batch_size = 32 耗时 291ms
%timeit 是python的语法糖,可以用来测试耗时,默认运行7次,求其平均的耗时。
ref:https://github.com/ultralytics/yolov5/issues/9987, 这个ref 作者明确说了,你的batch_size就是传过来的list的长度。也就是说可以自定义了。

2.2 发现问题
2.2.1 推理结束后,占用显存不释放。


推理结束后,它依然会占用最大的显存10000Mb不释放。应该如何破?? 权重加载的时候才2000Mb。
解决方案:
orch.cuda.empty_cache() 加上这句话,它在推理结束后就只保留原始的2000MB的显存使用情况了。
ref:https://blog.csdn.net/weixin_44826203/article/details/130401177
import torch
from PIL import Image
import time
path_weight = '/home/jianming_ge/workplace/yolov5_template/yolov5_template/weights/yolov5m6.pt'
model = torch.hub.load('/home/jianming_ge/workplace/yolov5_template/yolov5_template', 'custom', path=path_weight, source='local',autoshape = True)
img_path1 = "/home/jianming_ge/workplace/yolov5_template/yolov5_template/data/images11/bus.jpg"
imgs = [Image.open(img_path1)]
for _ in range(10):
results = model(imgs * 128)
results.print()
torch.cuda.empty_cache()
time.sleep(2)
time.sleep(1000)
2.3 其它有用的参数设置
ref:https://docs.ultralytics.com/yolov5/tutorials/pytorch_hub_model_loading/#detailed-example

后面还有分显卡推理啥的,yolov给封装的很好
pytorch的显存知识总结:https://zhuanlan.zhihu.com/p/424512257 这个娃是研究并行计算的猛人!