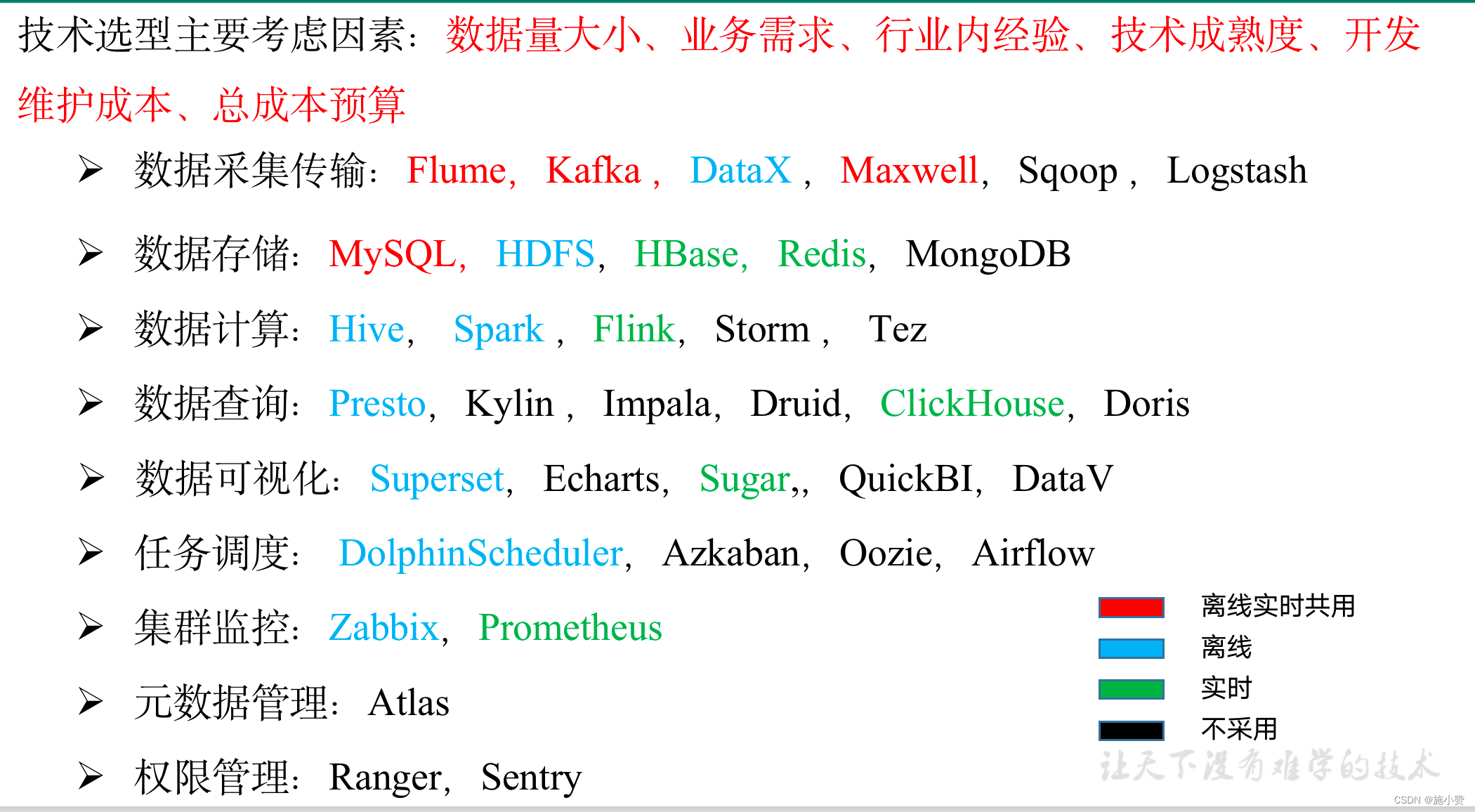
技术选型参考:
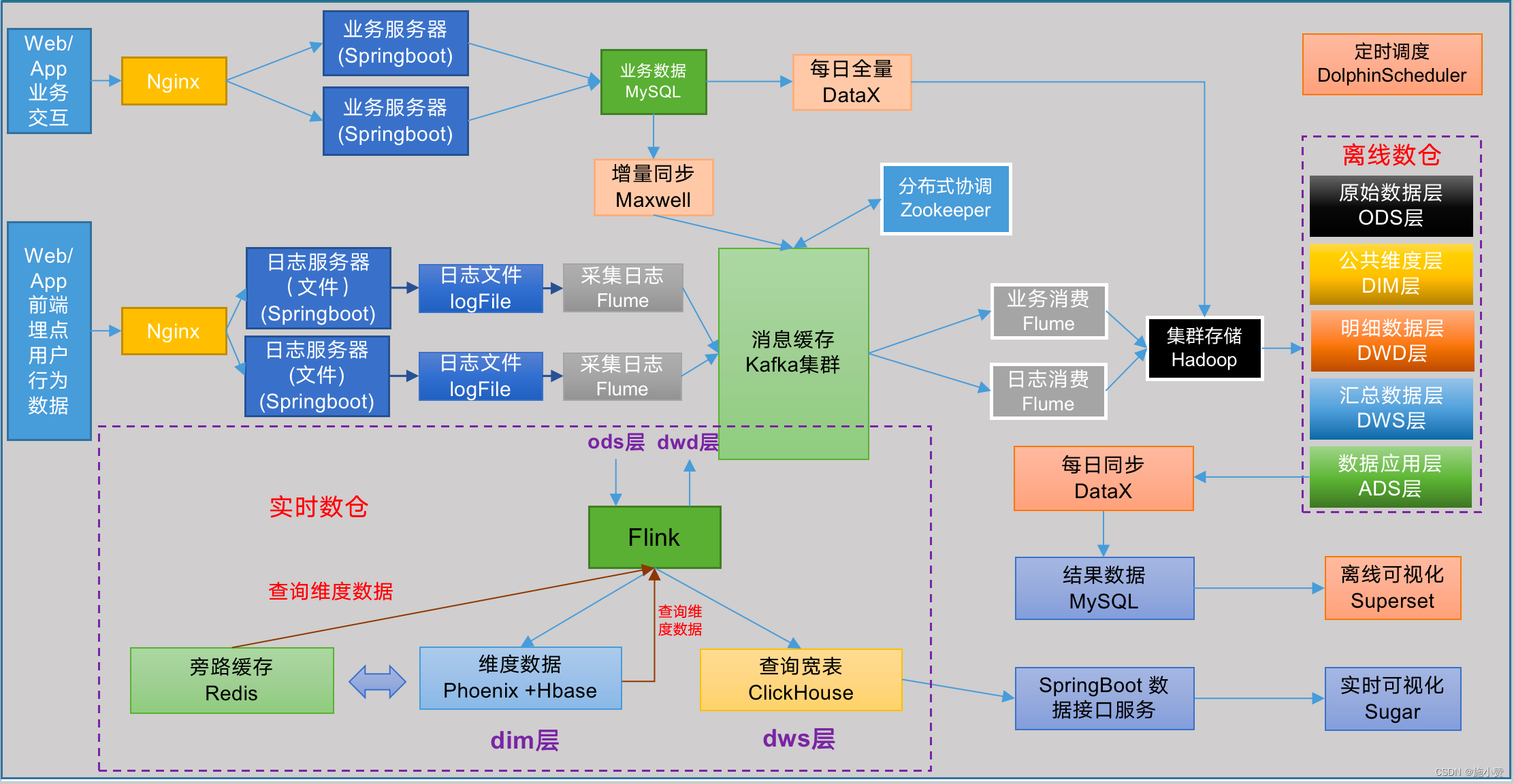
系统数据流程图
框架发行版本选型
1)如何选择Apache/CDH/HDP版本?
(1)Apache:运维麻烦,组件间兼容性需要自己调研。(一般大厂使用,技术实力雄厚,有专业的运维人员) (建议使用)
(2)CDH:国内使用最多的版本,但CM不开源,今年开始收费,一个节点1万美金/年。
(3)HDP:开源,可以进行二次开发,但是没有CDH稳定,国内使用较少
2)云服务选择
(1)阿里云的EMR、MaxCompute、DataWorks
(2)亚马逊云EMR
(3)腾讯云EMR
(4)华为云EMR
具体版本型号
Apache框架版本
| 框架 | 版本 |
| Hadoop | 3.1.3 |
| Zookeeper | 3.5.7 |
| MySQL | 5.7.16 |
| Hive | 3.1.2 |
| Flume | 1.9.0 |
| Kafka | 3.0.0 |
| Spark | 3.0.0 |
| DataX | 3.0.0 |
| Superset | 1.3.2 |
| DolphinScheduler | 2.0.3 |
| Maxwell | 1.29.2 |
| Flink | 1.13.0 |
| Redis | 6.0.8 |
| Hbase | 2.0.5 |
| ClickHouse | 20.4.5.36-2 |
注意事项:框架选型尽量不要选择最新的框架,选择最新框架半年前左右的稳定版。
服务器选型:
服务器选择物理机还是云主机?
1)物理机:
以128G内存,20核物理CPU,40线程,8THDD和2TSSD硬盘,戴尔品牌单台报价4W出头。一般物理机寿命5年左右。
需要有专业的运维人员,平均一个月1万。电费也是不少的开销。
2)云主机
云主机:以阿里云为例,差不多相同配置,每年5W。
很多运维工作都由阿里云完成,运维相对较轻松
3)企业选择
金融有钱公司和阿里没有直接冲突的公司选择阿里云
中小公司、为了融资上市,选择阿里云,拉倒融资后买物理机。
有长期打算,资金比较足,选择物理机。
集群规模
1)如何确认集群规模?(假设:每台服务器8T磁盘,128G内存)
(1)每天日活跃用户100万,每人一天平均100条:100万*100条=1亿条
(2)每条日志1K左右,每天1亿条:100000000 / 1024 / 1024 = 约100G
(3)半年内不扩容服务器来算:100G*180天=约18T
(4)保存3副本:18T*3=54T
(5)预留20%~30%Buf=54T/0.7=77T
(6)算到这:约8T*10台服务器
2)如果考虑数仓分层?数据采用压缩?需要重新再计算
集群资源规划设计
在企业中通常会搭建一套生产集群和一套测试集群。生产集群运行生产任务,测试集群用于上线前代码编写和测试。
1)生产集群
(1)消耗内存的分开
(2)数据传输数据比较紧密的放在一起(Kafka 、Zookeeper)
(3)客户端尽量放在一到两台服务器上,方便外部访问
(4)有依赖关系的尽量放到同一台服务器(例如:Hive和mysql)
| Master | Master | core | core | core | common | common | common |
| nn | nn | dn | dn | dn | JournalNode | JournalNode | JournalNode |
| rm | rm | nm | nm | nm | |||
| zk | zk | zk | |||||
| hive | hive | hive | hive | hive | |||
| kafka | kafka | kafka | |||||
| spark | spark | spark | spark | spark | |||
| datax | datax | datax | datax | datax | |||
| Ds-master | Ds-master | Ds-worker | Ds-worker | Ds-worker | |||
| maxwell | |||||||
| supset | |||||||
| mysql | |||||||
| flume | flume | ||||||
| flink | flink | ||||||
| clickhouse | |||||||
| redis | |||||||
| hbase |
2)测试集群服务器规划
| 阿里云 | 外网:47.97.164.xxx 内网:172.25.249.xxx | 外网:47.98.116.xxx 内网:172.25.249.xxx | 外网:121.40.67.xxx 内网:172.25.249.xxx | |
| 服务名称 | 子服务 | 服务器 hadoop102 | 服务器 hadoop103 | 服务器 hadoop104 |
| HDFS | NameNode | √ | ||
| DataNode | √ | √ | √ | |
| SecondaryNameNode | √ | |||
| Yarn | NodeManager | √ | √ | √ |
| Resourcemanager | √ | |||
| Zookeeper | Zookeeper Server | √ | √ | √ |
| Flume(采集日志) | Flume | √ | √ | |
| Kafka | Kafka | √ | √ | √ |
| Flume(消费Kafka日志) | Flume | √ | ||
| Flume(消费Kafka业务) | Flume | √ | ||
| Hive | √ | √ | √ | |
| MySQL | MySQL | √ | ||
| DataX | √ | √ | √ | |
| Maxwell | Maxwell | √ | ||
| Spark | √ | √ | √ | |
| DolphinScheduler | ApiApplicationServer | √ | ||
| AlertServer | √ | |||
| MasterServer | √ | |||
| WorkerServer | √ | √ | √ | |
| LoggerServer | √ | √ | √ | |
| Superset | Superset | √ | ||
| Flink | √ | |||
| ClickHouse | √ | |||
| Redis | √ | |||
| Hbase | √ | |||
| 服务数总计 | 21 | 11 | 12 |






![[AJAX]原生AJAX——服务端如何发出JSON格式响应,客户端如何处理接收JSON格式响应](https://img-blog.csdnimg.cn/2c23e9e2336341c3a70eded9223e4f10.png)