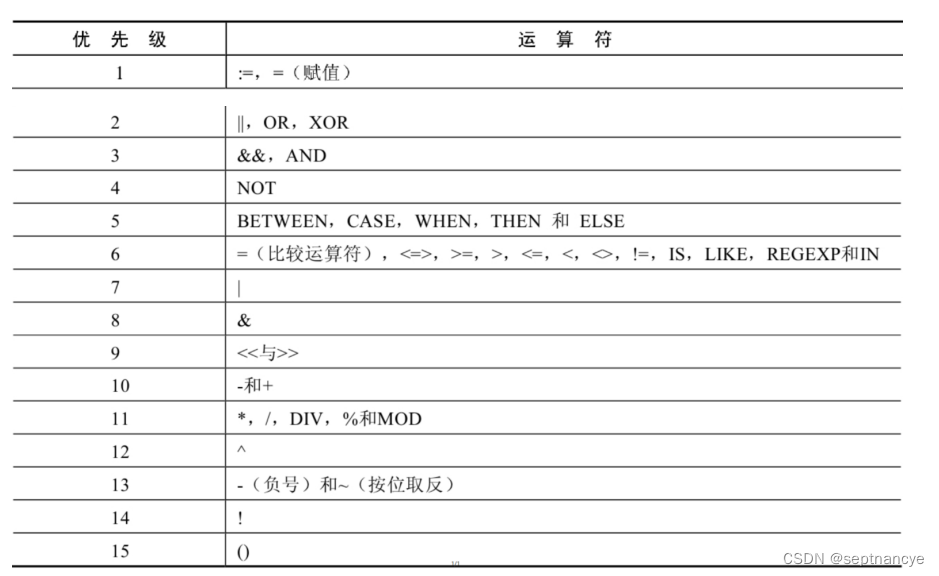
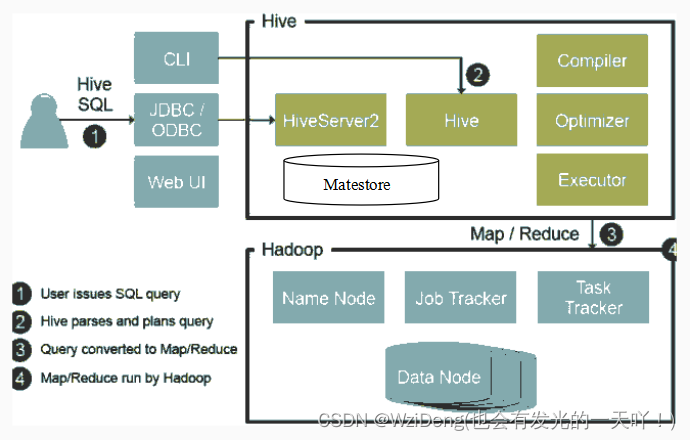
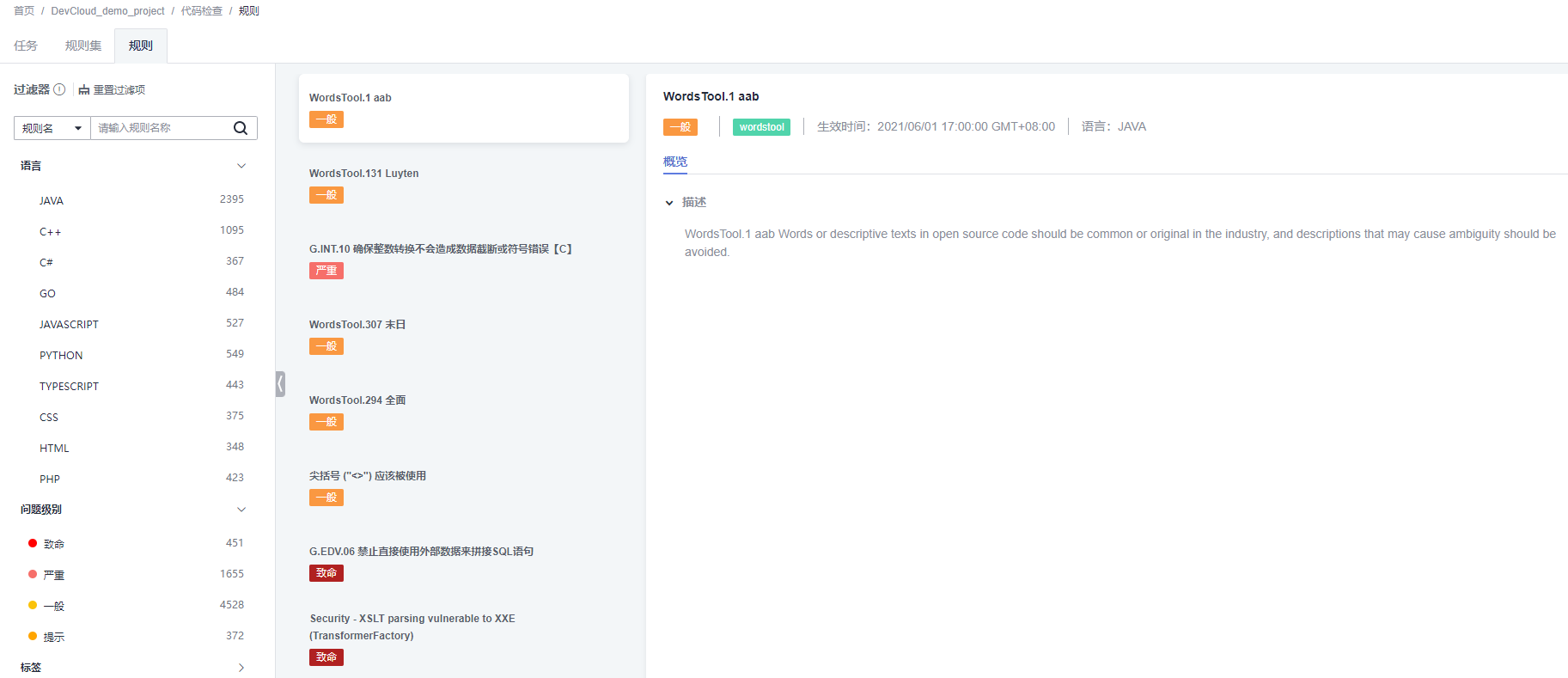
====================== 待续 ========================
代码粗解
在 data_lorder.py文件中,定义了几个用于处理不同数据集的类,这里只关注Dataset_ETT_hour类。Dataset_ETT_hour类用来加载、处理ETTH数据集,主要包含以下4个方法:__read_data__, def __getitem__(self, index),__len__(self)和inverse_transform。
1. __read_data__()
对ETTh的数据处理主要有以下几个步骤:
(1) 将ETTh1.csv中数据读取加载到一个DataFrame对象中
import pandas
root_path = 'D:\Contributions\J21_PINN\PYFORMER\dataset'
data_path = 'ETTh1.csv'
df_raw = pd.read_csv(os.path.join(root_path, data_path))
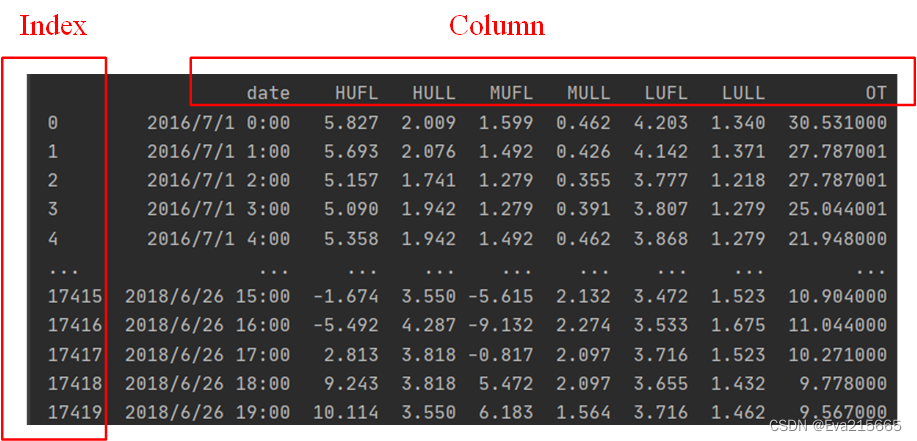
加载的数据如下图所示,共有8列数据,第1列是时间戳,后7列是特征数据,其中最后一列OT是油液的温度,也是要预测的量。
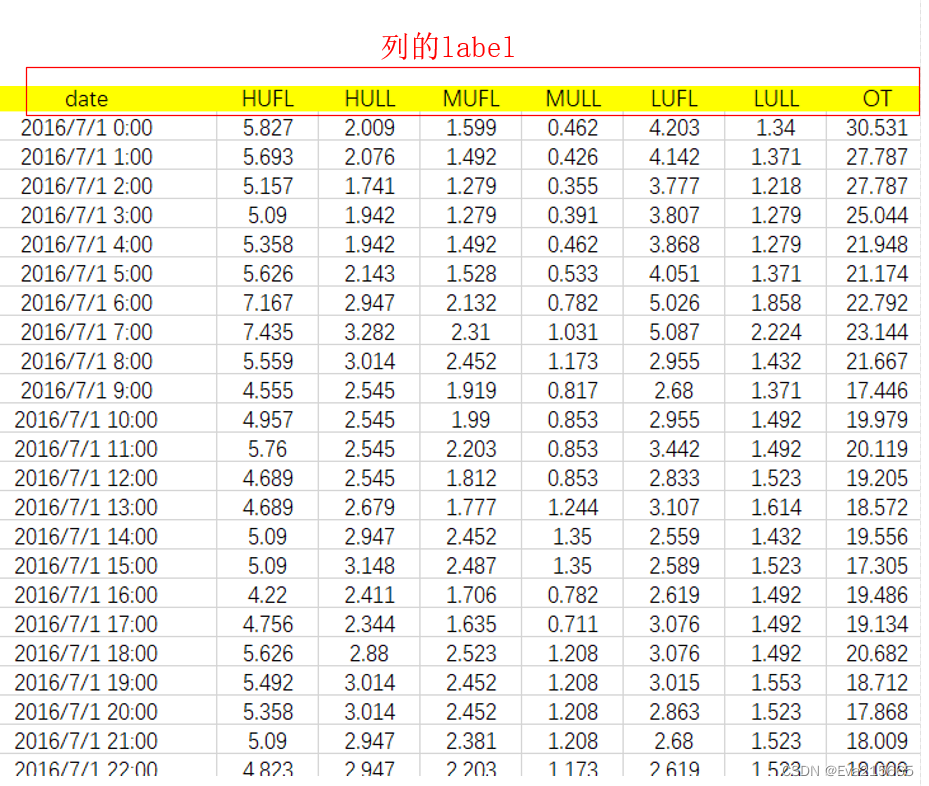
把df_raw打印出来,可以看出,当原始数据加载进DataFrame类对象后,对自动给数据加行号Index,默认是从1开始的自然数编号。
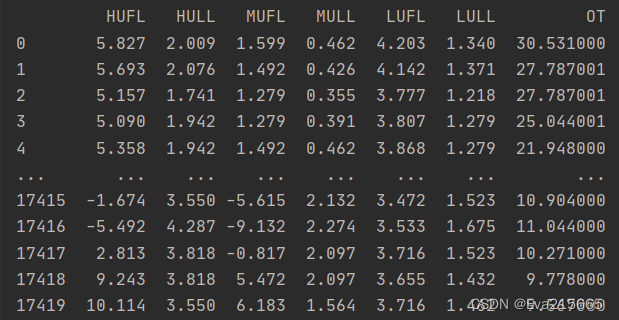
(2). 取列的label,同时对列切片,切片范围:第1列到最后一列
cols_data = df_raw.columns[1:] # 从1切片,即去掉"date"列
print("The label of each coloumn is: ", cols_data)
df_data = df_raw[cols_data] #取cols_data列
执行上述代码后,date列被扔掉,df_data内容如下图所示
(3). 构造时间模型
先确定边界,边界主要用于确定train,test,和val数据的切片范围,例如本例中,border1s=[0, 8256, 11136], border2s=[8640, 11520, 14400],对于train数据,切片范围0:8640,对于test,切片范围8256:11520,对于val数据,切片范围11136:14400。
border1s = [0, 12 * 30 * 24 - seq_len, 12 * 30 * 24 + 4 * 30 * 24 - seq_len] #border1s数组[0, 8256, 11136]
border2s = [12 * 30 * 24, 12 * 30 * 24 + 4 * 30 * 24, 12 * 30 * 24 + 8 * 30 * 24] #border2s数组[8640, 11520, 14400]
border1 = border1s[self.set_type] #
border2 = border2s[self.set_type]
从df_raw中取出date列,并对其切片,切片范围:border1:border2,数值与初始化类对象时传入的flag实参有关,具体的:if flag=train,self.set_type=0, if flag=test,self.set_type=1, if flag=val,self.set_type=2
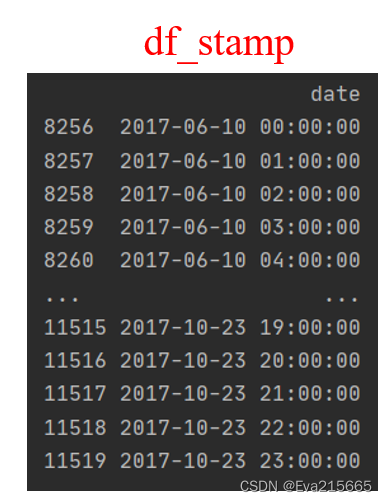
df_stamp = df_raw[['date']][border1:border2]
处理成日期格式,pd.to_datetime函数详见官网,它支持多种类型的输入,并且依据输入类型的不同,输出类型也不同。下面这行代码中,df_stamp.date类型为Series,Series类对象的属性和方法,详见官网
df_stamp['date'] = pd.to_datetime(df_stamp.date)
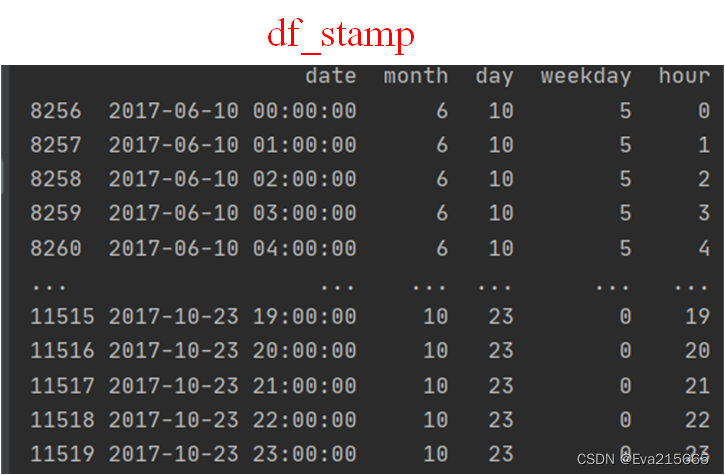
为df_stamp增加month、day、weekday、hour列,并且从date中提取相应数据
df_stamp['month'] = df_stamp.date.apply(lambda row: row.month, 1)
df_stamp['day'] = df_stamp.date.apply(lambda row: row.day, 1)
df_stamp['weekday'] = df_stamp.date.apply(lambda row: row.weekday(), 1)
df_stamp['hour'] = df_stamp.date.apply(lambda row: row.hour, 1)
执行上述代码后,df_stamp变为下图
丢弃date列,DataFrame.drop函数中的axis参数:axis=0 或者axis=index,则丢弃行,axis=1或者axis=column,丢弃列,默认axis=0
data_stamp = df_stamp.drop(['date'], axis=1)
执行上述代码后,data_stamp变为
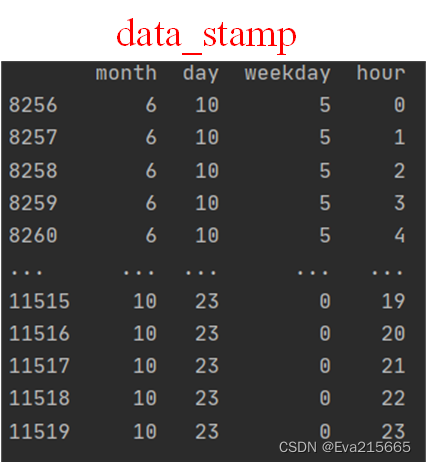
将DataFrame类型的data_stamp变为numpy.ndarray类型,执行下面代码后,data_stamp就变为了形状为(3264,5)的二维张量,类型为numpy.ndarray,如下图所示
data_stamp = data_stamp.values

(4). 最后返回处理过的数据
在__read_data__()函数中,返回data_x, data_y, data_stamp,这是已经按照初始化类对象时传入的参数flag进行切片以后的数据。
# 此时,data_x, data_y已按照flag的值,对data进行了切片处理
self.data_x = data[border1:border2]
self.data_y = data[border1:border2]
self.data_stamp = data_stamp
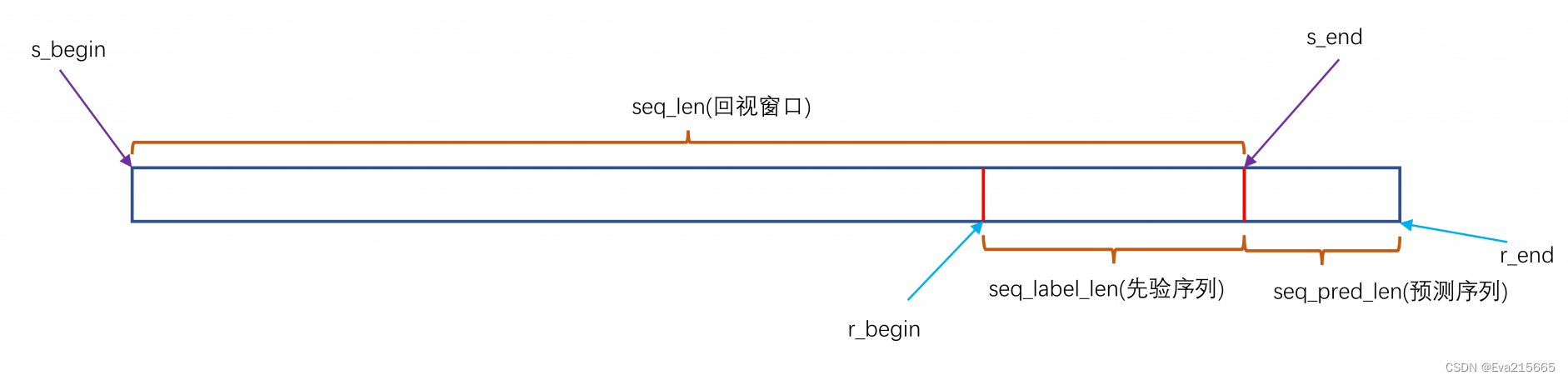
2 __getitem__()
对__getitem__()进行说明
def __getitem__(self, index):
# 随机取得标签,起点
s_begin = index
# 训练区间:终点(起点+回视窗口)
s_end = s_begin + self.seq_len
# 有标签区间 + 无标签区间(预测时间步长):终点-先验序列窗口
r_begin = s_end - self.label_len
# 终点 + 预测序列长度
r_end = r_begin + self.label_len + self.pred_len
# 取训练数据,seq_x = [起点,起点+回视窗口]
seq_x = self.data_x[s_begin:s_end]
# seq_y = [终点-先验序列窗口,终点+预测序列长度]
seq_y = self.data_y[r_begin:r_end]
# 取训练数据对应时间特征,取对应时间戳
seq_x_mark = self.data_stamp[s_begin:s_end]
# 取有标签区间+无标签区间(预测时间步长)对应时间戳
seq_y_mark = self.data_stamp[r_begin:r_end]
return seq_x, seq_y, seq_x_mark, seq_y_mark
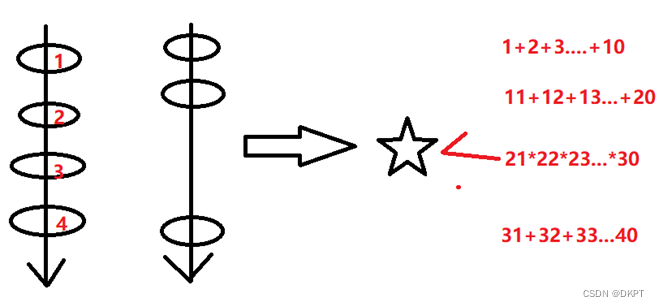
从时间序列模型SCINet搬运过来一幅图,帮助理解上述代码的含义
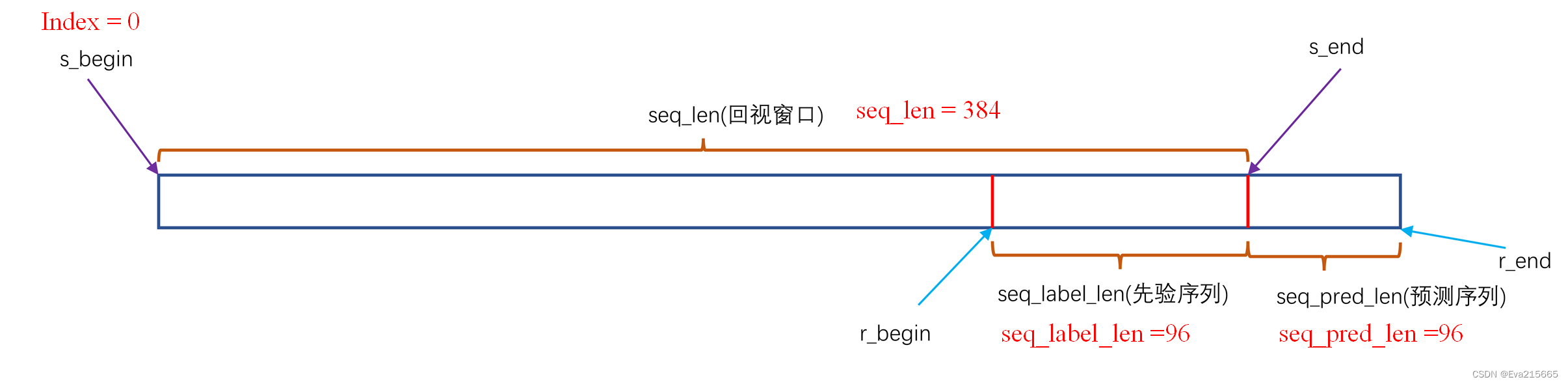
到现在为止,我们已经构建好了Dataset_ETT_hour类,下面来简单测试一下这个类,看看输出的处理后的数据长什么样子。首先指定类初始化的几个参数,例如root_path,其他几个参数flag, target, sclae都有默认值,如果不需要改,可以省略。
root_path = 'D:\Contributions\J21_PINN\PYFORMER\dataset'
ETTh_data = Dataset_ETT_hour(root_path=root_path, flag='train', target='OT', scale=True) #实例化
index = 0
seq_x, seq_y, seq_x_mark, seq_y_mark = ETTh_data.__getitem__(index=index)
print(seq_x)
print("seq_x.shape = ", seq_x.shape)
print(seq_y)
print("seq_y.shape = ", seq_y.shape)
我们设定index=0,那么s_begin等几个参数的值如下
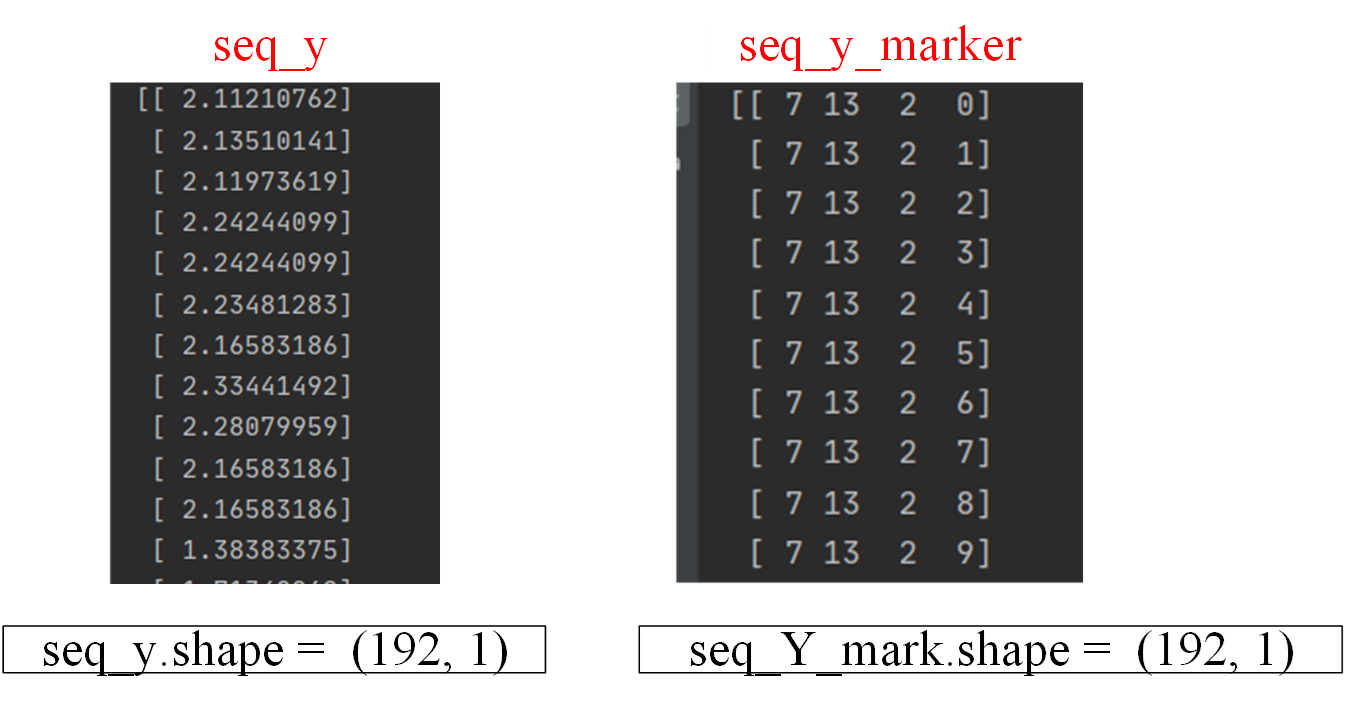
seq_x及其shape如下,对照原始的.csv文档,发现并没有seq_x中的这些数据,原因是因为初始化Dataset_ETT_hour类时,指定了scale=True,所以这里输出的数据,是标准化以后的数据。如果scale=False,那么输出的数据就是原始数据。Target取了默认OT列,所以seq_x,seq_y仅是温度这一列数据。
把seq_x, seq_x_mark, seq_y,seq_y_mark打印出来,可以看出,seq_x_mark是seq_x对应的时间戳

命令行参数库argparse用法
插播一个关于命令行参数库argparse的用法,详见B站上一个16分钟的视频,测试代码如下
"""运行下面的代码,请在terminal中:
1. cd到pyformer路径下,例如 cd D:\Contributions\J21_PINN\PYFORMER\pyformer
2. 输入 python test.py mul --a=3 --b=5 --verbose
"""
# 1. 如何读取命令行中传递进来的参数
# sys.argv获取命令行中所有参数
# format: script的路径,其他参数...
# 2, 专门处理命令行的Library: argparse
# - 添加optional argument参数,有add_argument("--a", type = int, help = "xxx")
# -默认是可选的,意味着可以不用填写
# - 添加positional argument位置参数
# -默认是不可选的,必须填写,否则报错
# - 添加flags,标记,开关那种形式actional参数
# 比如说,添加一个参数,是否需要打印信息,--verbose
import sys
import argparse
# 1. 先创建解释器
parser = argparse.ArgumentParser()
# 同样实现乘法操作 output = a * b
# 添加a参数
parser.add_argument("method", type = str, help="Method") # method是位置参数,不可选,必须指定,否则报错
parser.add_argument("--a", type = int, default=5, help = "operator A") # a是可选参数,可以不指定,可以给默认值
parser.add_argument("--b", type = int, default=6, help = "operator B") # b是可选参数,可以不指定,可以给默认值
parser.add_argument("--verbose", action="store_true", default = 0, help = "Print Message") # 开关类参数
args = parser.parse_args()
print(args)
print(args.a*args.b)