数据集,这次这个是分了类的【文末分享】
各12500张:
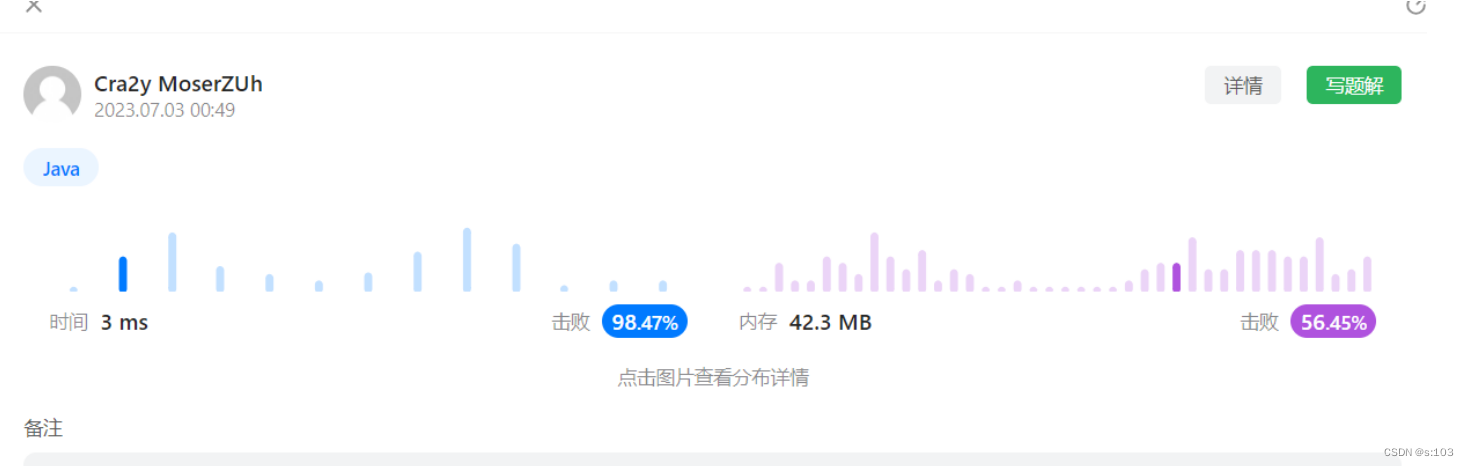
两点需要注意:
①猫狗分类是彩色图片,所以是3个channel;
②猫狗分类的图片大小不一,但是CNN的输入要求是固定大小,所以要resize。
划分训练集和测试集:
文件夹如下:
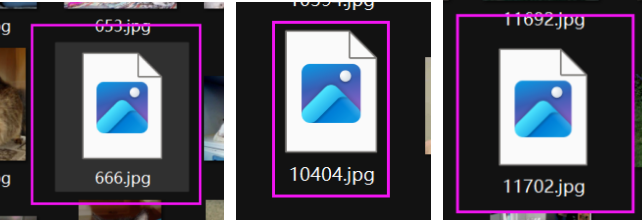
这里要注意,文件里面有三个图片是打不开的,这会导致后续运行时报错,打不开的三个图片分别是:猫猫666,猫猫10404,狗狗11702:【要么替换图片要么直接删掉(这个我选择的是替换)】
然后按照8:2来划分:(移动文件的过程,从train随机选取一些图片到test中)
import os,shutildef mymovefile(srcfile,dstfile):if not os.path.isfile(srcfile):print("src not exist!")else:fpath,fname=os.path.split(dstfile) #分离文件名和路径if not os.path.exists(fpath):os.makedirs(fpath) #创建路径shutil.move(srcfile,dstfile) #移动文件test_rate=0.2#训练集和测试集的比例为8:2。img_num=12500test_num=int(img_num*test_rate)import randomtest_index = random.sample(range(0, img_num), test_num)file_path=r"D:\Users\Twilight\PycharmProjects\CNN\PetImages"tr="train"te="test"cat="Cat"dog="Dog"#将上述index中的文件都移动到/test/Cat/和/test/Dog/下面去。for i in range(len(test_index)):#移动猫srcfile=os.path.join(file_path,tr,cat,str(test_index[i])+".jpg")dstfile=os.path.join(file_path,te,cat,str(test_index[i])+".jpg")mymovefile(srcfile,dstfile)#移动狗srcfile=os.path.join(file_path,tr,dog,str(test_index[i])+".jpg")dstfile=os.path.join(file_path,te,dog,str(test_index[i])+".jpg")mymovefile(srcfile,dstfile)
猫狗分类的数据集预处理:
import numpy as npfrom torchvision import transforms,datasets#定义transformstransforms = transforms.Compose([transforms.RandomResizedCrop(150),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])])train_data = datasets.ImageFolder(os.path.join(file_path,tr), transforms)test_data=datasets.ImageFolder(os.path.join(file_path,te), transforms)
RandomResizedCrop(150)是用来把图片的每一个channel大小都变成(150,150);
mean=[0.485, 0.456, 0.406],有3个数的原因是猫狗分类是彩色图片,所以有3个channel,所以每一个channel上都有一个平均值,同理,std也是;
上面的data已经把猫狗的图片都囊括了,而且标签已经自动变成了0和1。这就是ImageFolder的威力。
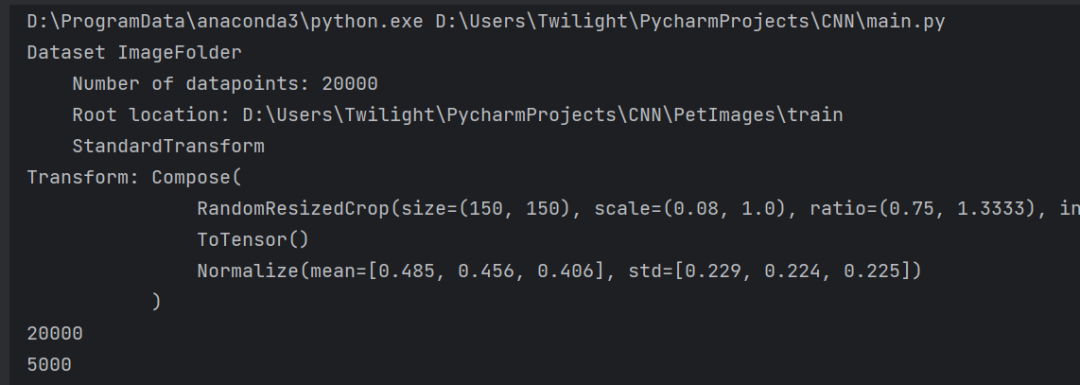
做一下测试:
#测试print(train_data)print(len(train_data))print(len(test_data))
print(train_data[0][0])print(train_data[0][1])
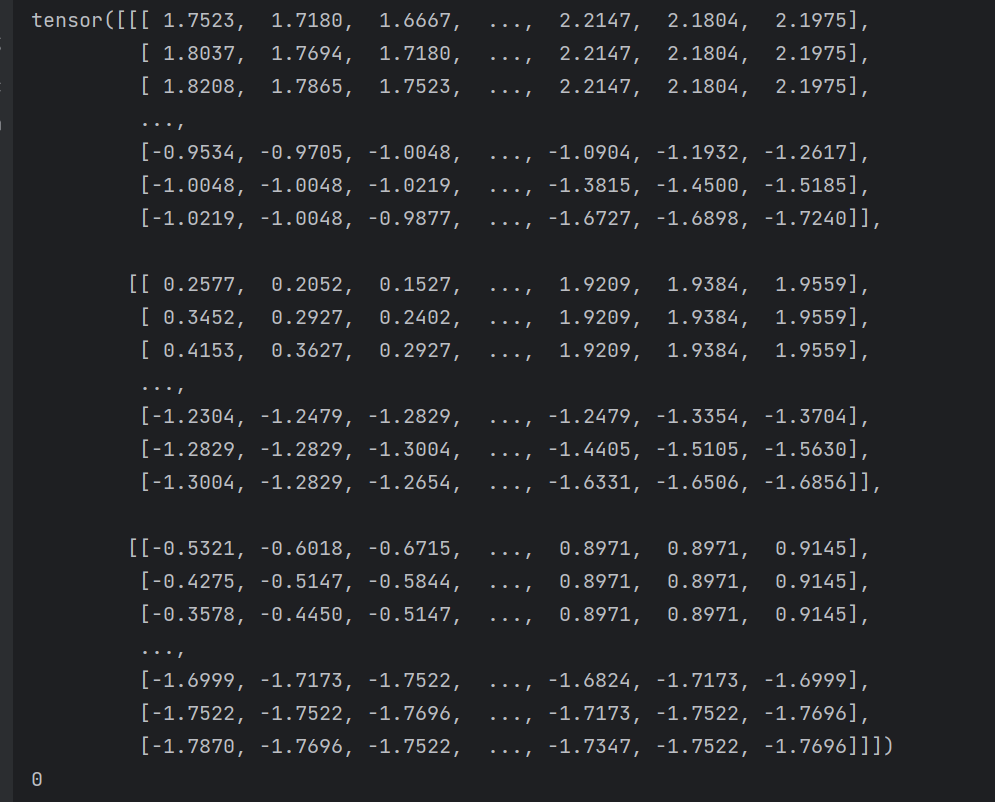
第一张[0]训练图片的具体情况:前面是图片[0],后面是标签[1]。标签0代表猫猫,1代表狗狗:因为在/train的文件夹下Cat在Dog的前面,所以前者是0,后者是1。
print(train_data[0][0].shape)print(train_data[1][0].shape)
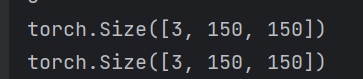
每一张图片都是(3,150,150),3表示3个channel。
结果分析:(都是合理的)
网络架构以及训练结果

from torch.utils import databatch_size=32train_loader = data.DataLoader(train_data,batch_size=batch_size,shuffle=True,pin_memory=True)test_loader = data.DataLoader(test_data,batch_size=batch_size)import torchimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optim#架构会有很大的不同,因为28*28-》150*150,变化挺大的,这个步长应该快一点。class CNN(nn.Module):def __init__(self):super(CNN,self).__init__()self.conv1=nn.Conv2d(3,20,5,5)#和MNIST不一样的地方,channel要改成3,步长我这里加快了,不然层数太多。self.conv2=nn.Conv2d(20,50,4,1)self.fc1=nn.Linear(50*6*6,200)self.fc2=nn.Linear(200,2)#这个也不一样,因为是2分类问题。def forward(self,x):#x是一个batch_size的数据#x:3*150*150x=F.relu(self.conv1(x))#20*30*30x=F.max_pool2d(x,2,2)#20*15*15x=F.relu(self.conv2(x))#50*12*12x=F.max_pool2d(x,2,2)#50*6*6x=x.view(-1,50*6*6)#压扁成了行向量,(1,50*6*6)x=F.relu(self.fc1(x))#(1,200)x=self.fc2(x)#(1,2)return F.log_softmax(x,dim=1)lr=1e-4device=torch.device("cuda" if torch.cuda.is_available() else "cpu" )model=CNN().to(device)optimizer=optim.Adam(model.parameters(),lr=lr)def train(model,device,train_loader,optimizer,epoch,losses):model.train()for idx,(t_data,t_target) in enumerate(train_loader):t_data,t_target=t_data.to(device),t_target.to(device)pred=model(t_data)#batch_size*2loss=F.nll_loss(pred,t_target)#Adamoptimizer.zero_grad()loss.backward()optimizer.step()if idx%10==0:print("epoch:{},iteration:{},loss:{}".format(epoch,idx,loss.item()))losses.append(loss.item())def test(model,device,test_loader):model.eval()correct=0#预测对了几个。with torch.no_grad():for idx,(t_data,t_target) in enumerate(test_loader):t_data,t_target=t_data.to(device),t_target.to(device)pred=model(t_data)#batch_size*2pred_class=pred.argmax(dim=1)#batch_size*2->batch_size*1correct+=pred_class.eq(t_target.view_as(pred_class)).sum().item()acc=correct/len(test_data)# print("accuracy:{},average_loss:{}".format(acc,average_loss))print("accuracy:{}".format(acc))num_epochs=10losses=[]from time import *begin_time=time()for epoch in range(num_epochs):train(model,device,train_loader,optimizer,epoch,losses)# test(model,device,test_loader)end_time=time()print(test(model,device,test_loader))
每一轮的部分截图:
精确度:
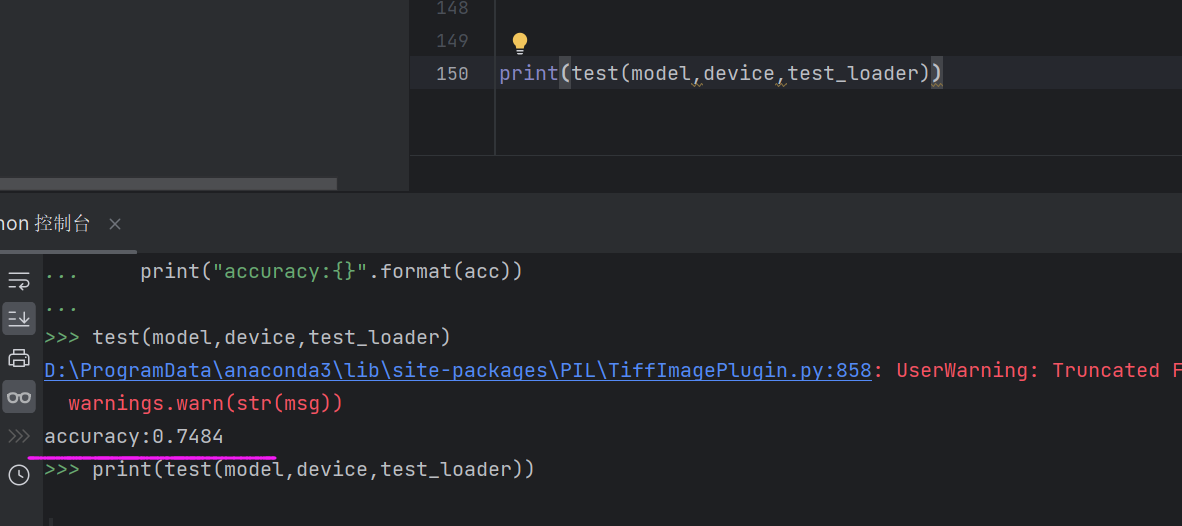
【修改网络架构,因为是彩色的,有3个channel,而且训练资源有限,增大了卷积的步长 -->self.conv1=nn.Conv2d(3,20,5,5)的最后一个参数5,即卷一次,移动5个格子,不写默认是1格。这样做,可以快速把图片缩小,原来是150*150的图片,这样可以变成30*30。】
资料分享栏目
数据集之猫狗分类(kaggle+分了类的)
链接:https://pan.baidu.com/s/1NByVZwxUk4nmCCTCetqgCA
提取码:rmmx