(由于是学习,所以文章会有一些报错及解决办法)
在Kaggle()获取数据集:(没有账号先去注册一个账号,在注册时可能会出现的问题见Kaggle注册出现一排“Captcha must be filled out.”!)
https://www.kaggle.com/competitions/dogs-vs-cats/data

获取到的数据集:(后面几期再分享)

一共25000张图片,猫猫狗狗各占一半。图片名称为:"cat.x.jpg"
对图片名称进行处理:
import ospath="D:\\Users\\Twilight\\PycharmProjects\\catdog\\train\\"filenames=[name for name in os.listdir(path)]j=0k=0catList=[]dogList=[]for i,filename in enumerate(filenames):src=path+filenamenamelist=filename.split('.')if namelist[0]=='cat':j=j+1dst=namelist[0]+str(j)+'.0'+'.'+namelist[2] #猫标签设置为0catList.append(dst)#获得cat的图片名集合else:k=k+1dst=namelist[0]+str(k)+'.1'+'.'+namelist[2] #狗标签设置为1dogList.append(dst)#获得dog的图片名集合dst=path+dstos.rename(src,dst)
这里报错了,解决一下:

emm,就是代码第二行两个反斜杠忘加了:
path="D:\\Users\\Twilight\\PycharmProjects\\Resnet18\\train\\"运行完后:

这里改名称只是习惯问题,重要的是标签问题,0代表猫猫,1代表狗狗,指明图片的类别,并在构建Dataset类时发挥作用。另外,catList和dogList分别存储了猫猫和狗狗的图片名称的路径,是为了划分训练集和测试集。
紧接着,实现自己的Dataset类:

代码:(训练集和测试集按8:2)
import torchimport osfrom torch.utils.data import Datasetfrom torchvision import transformsfrom PIL import Imageimport numpy as npclass MyDataset(Dataset):def __init__(self,path_file,namelists,transform=None):self.path_file=path_fileself.imgs=namelistsself.transform=transformdef __len__(self):return len(self.imgs)def __getitem__(self, idx):#get the imageimg_path = os.path.join(self.path_file,self.imgs[idx])image=Image.open(img_path)image=image.resize((28,28))#修改图片大小,默认大小if self.transform:image = self.transform(image)#get the labelstr1=self.imgs[idx].split('.')label=eval(str1[1])return image, label
报错:
这个报错之前有个类似的,在anoconda下载,前面有文章写到:PyTorch安装
然后导入DataLoader:
train_loader=torch.utils.data.DataLoader(train_data, batch_size=32, shuffle=True)test_loader=torch.utils.data.DataLoader(test_data, batch_size=32, shuffle=True)
运行完了测试一下:
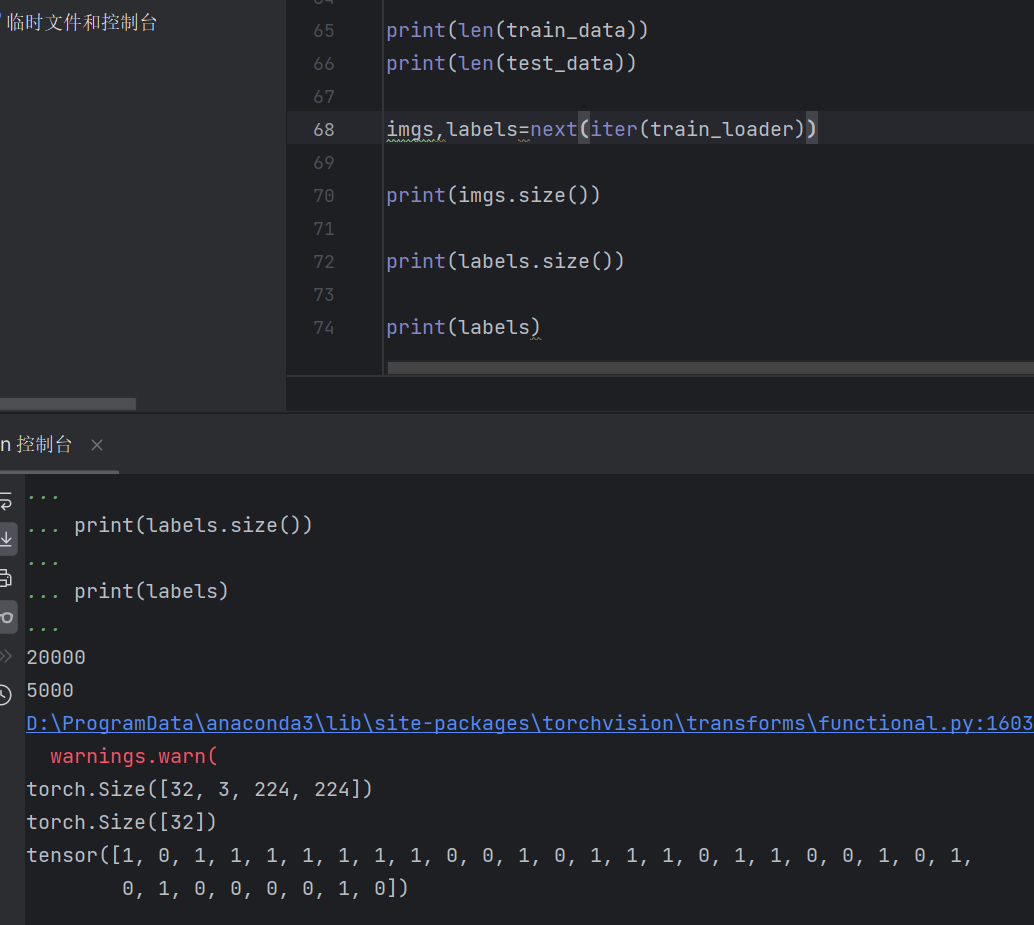
很好,没有问题。(如果有问题可能就是前面多次调试、运行代码造成的,可以重新创一个项目来运行。)【如果有时间再讲解代码】