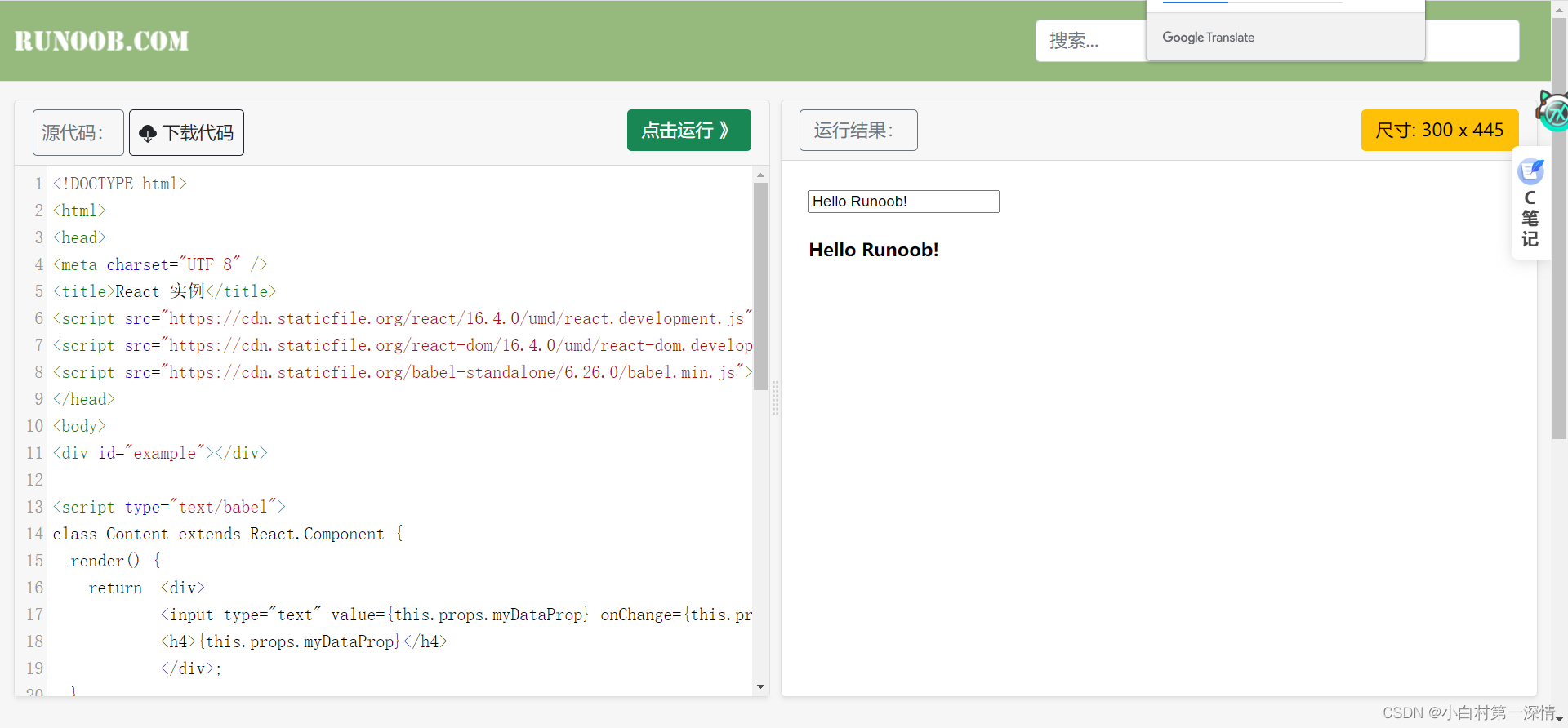
功能1:让模型具有memory
可以看到,langchain作为访问gpt的一个插件,可以让gpt模型通过memory变量将之前的对话记录下来,从而使模型具有记忆(在不改变模型参数的情况下)。
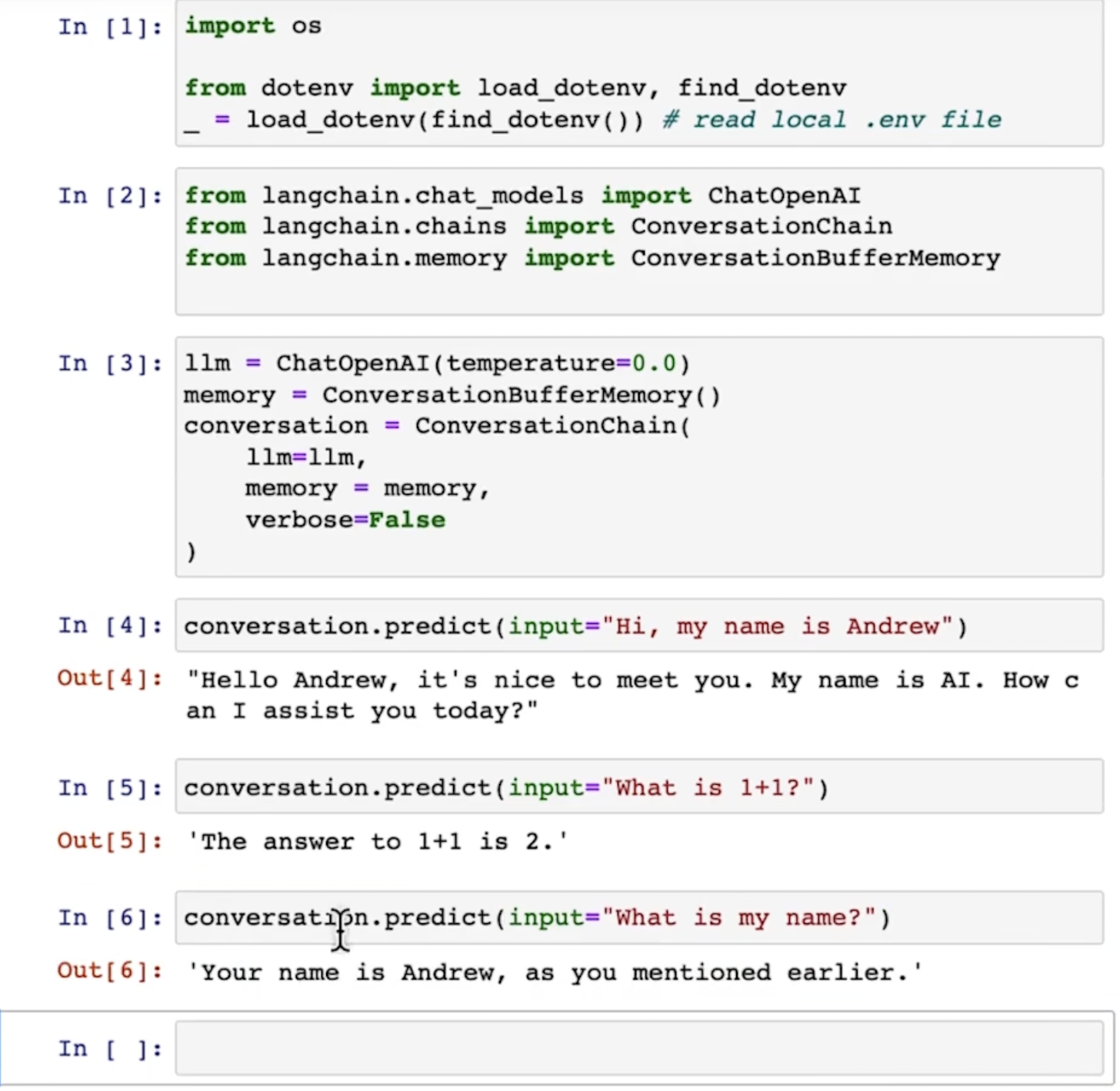
查看memory变量包含了什么:

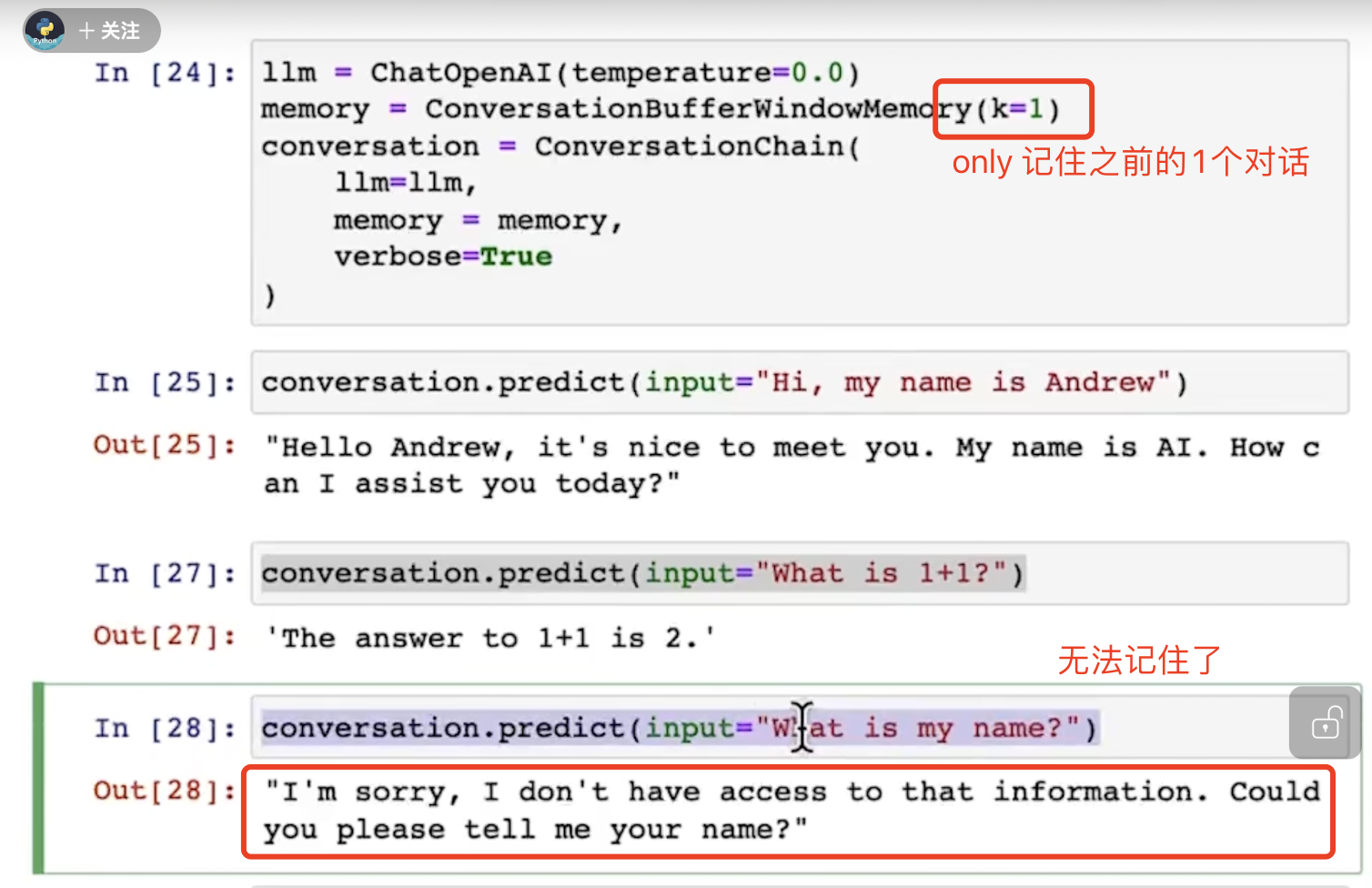
可以通过参数k(或者max_tokens等参数)设置记忆的长度(记住之前的几个对话):
为什么用langchain
大型模型是没有“状态”这个概念的(相比lstm这类模型)。
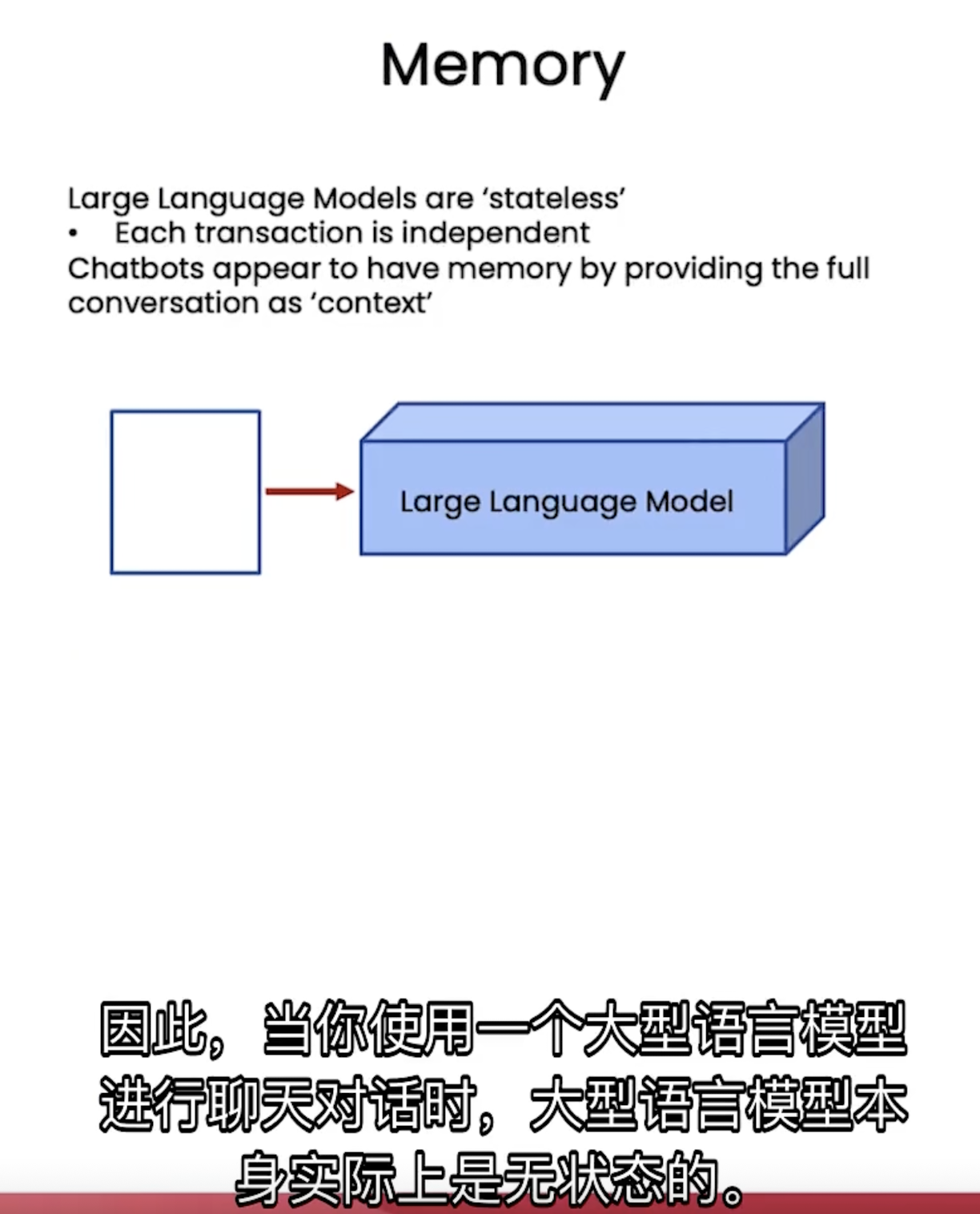
langchain这个插件就能解决这个问题。
功能2: 前后文联系
即下一个对话(输出)需要用到上一个对话中的某些信息(作为输入)。
普通链
假设读取了一个csv文件:
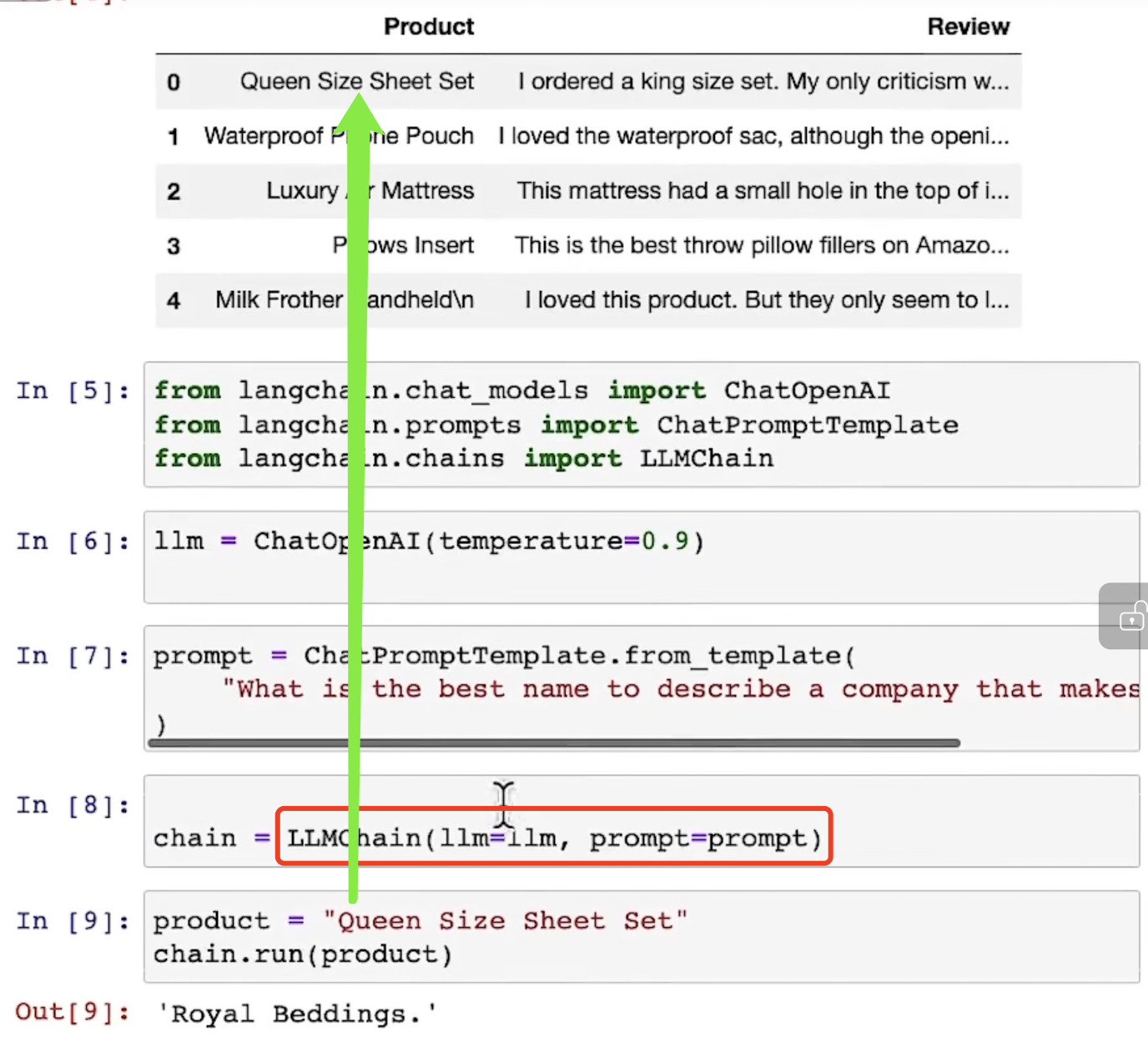
llmchain这个函数需要接受两个变量,模型和prompt:
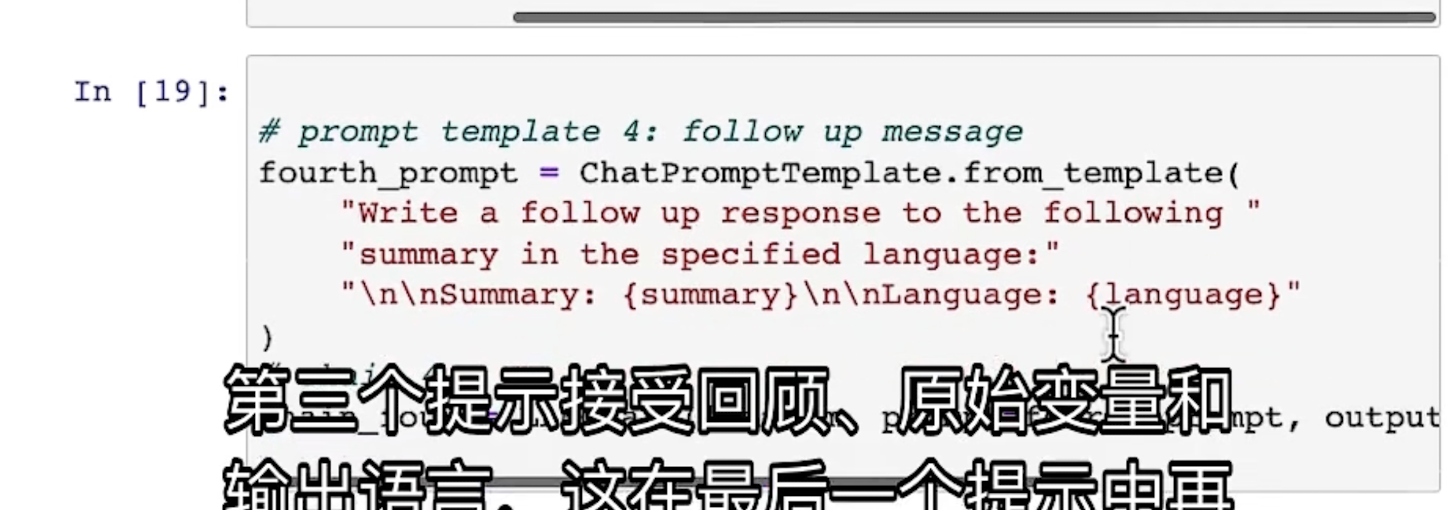
Sequetial Chain

这种类型的chain,前后的对话是有输入-输出之间的关系。
来看一下如何使用:
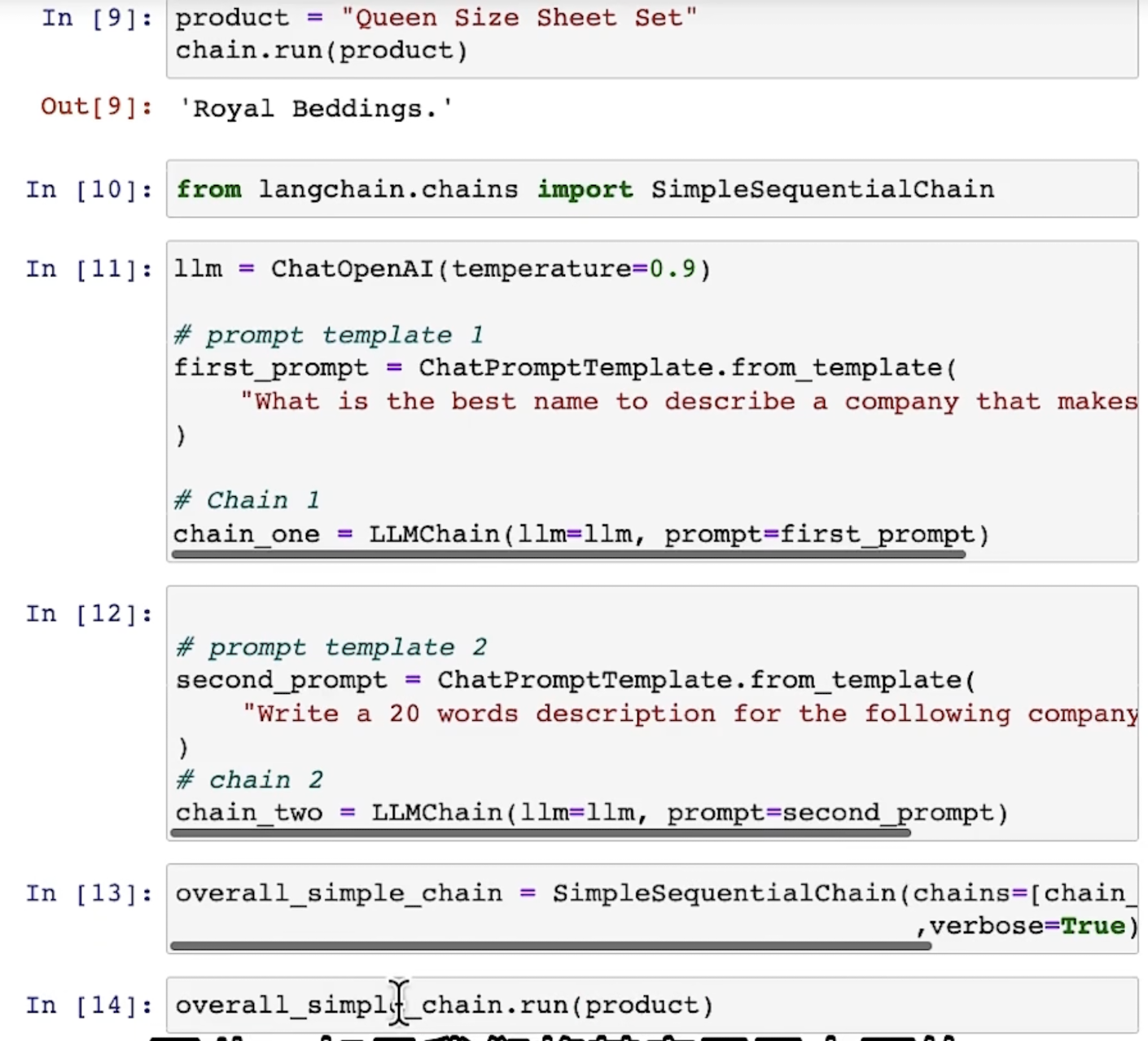
输出如下:
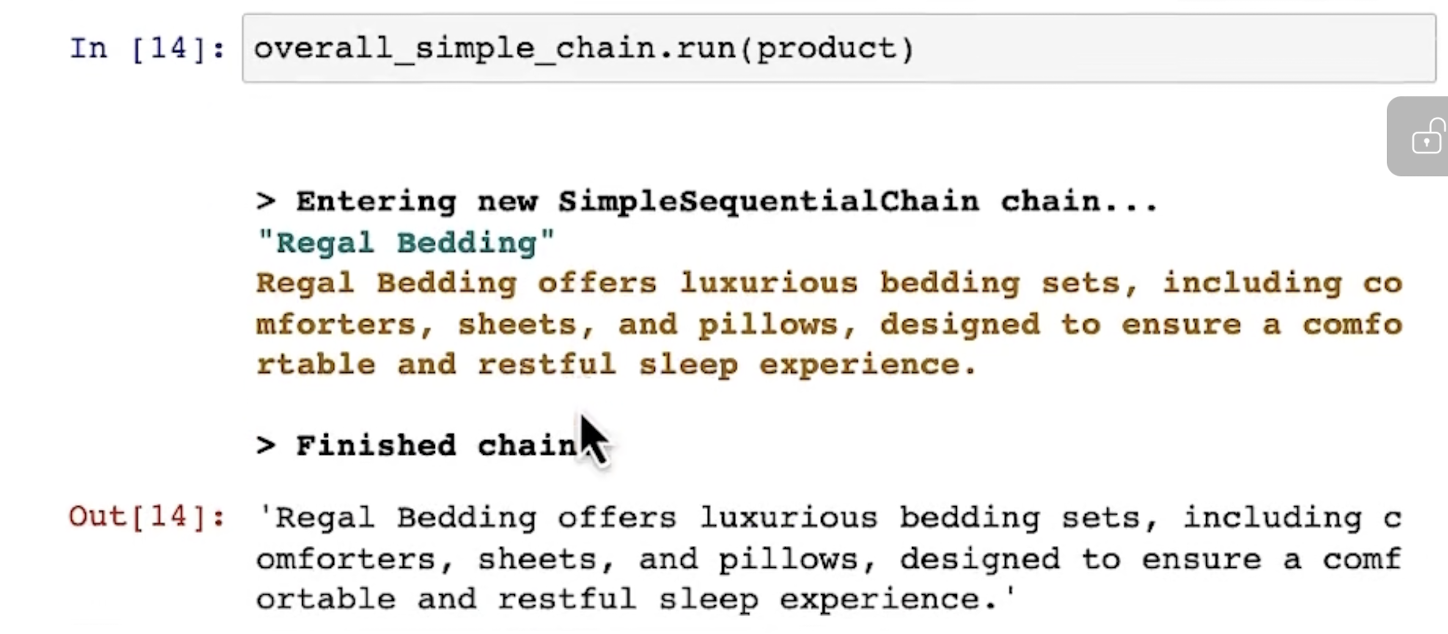
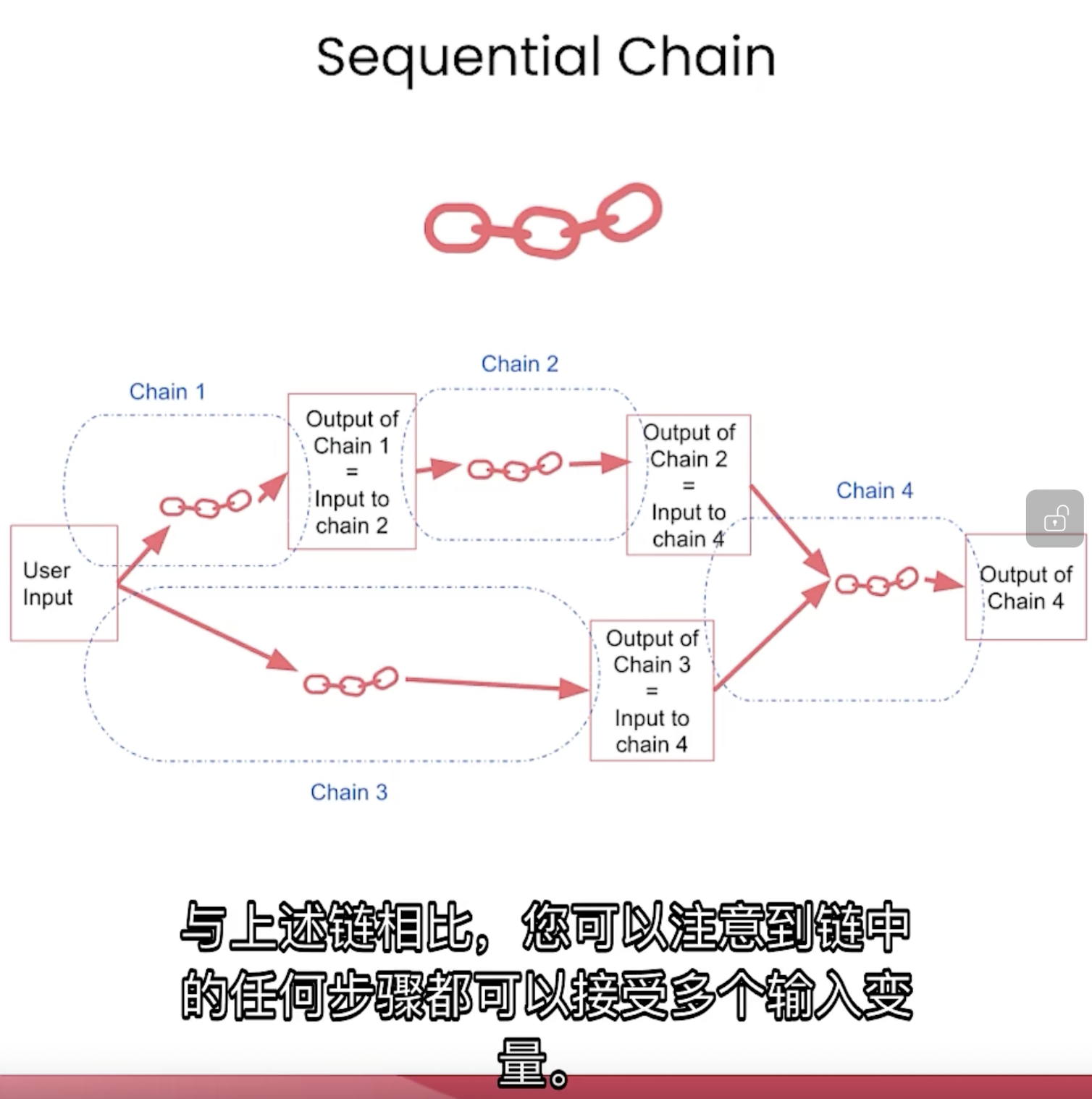
simple chain的示意图如下:
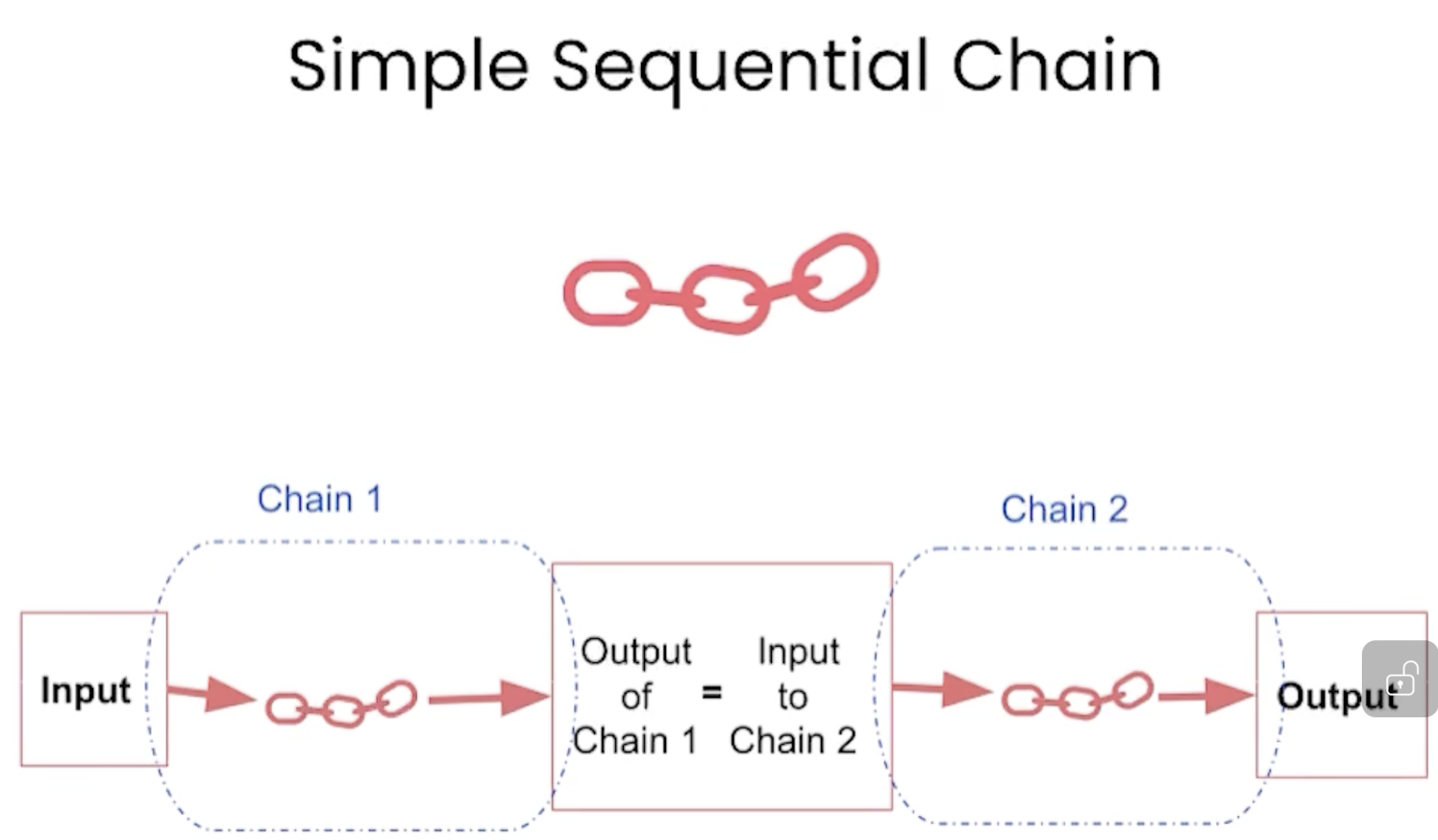
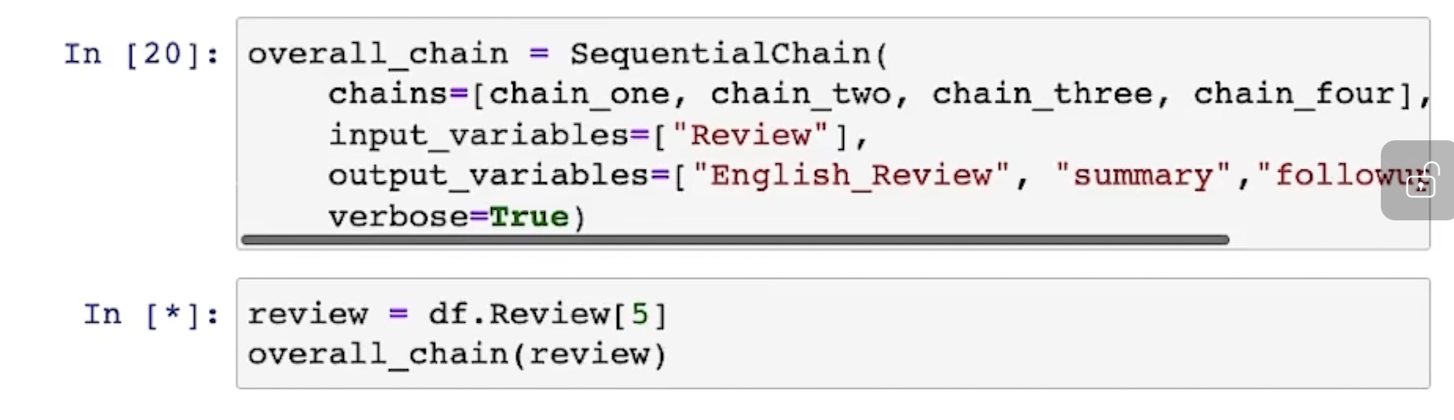
当多个对话杂糅时,可以这样操作:
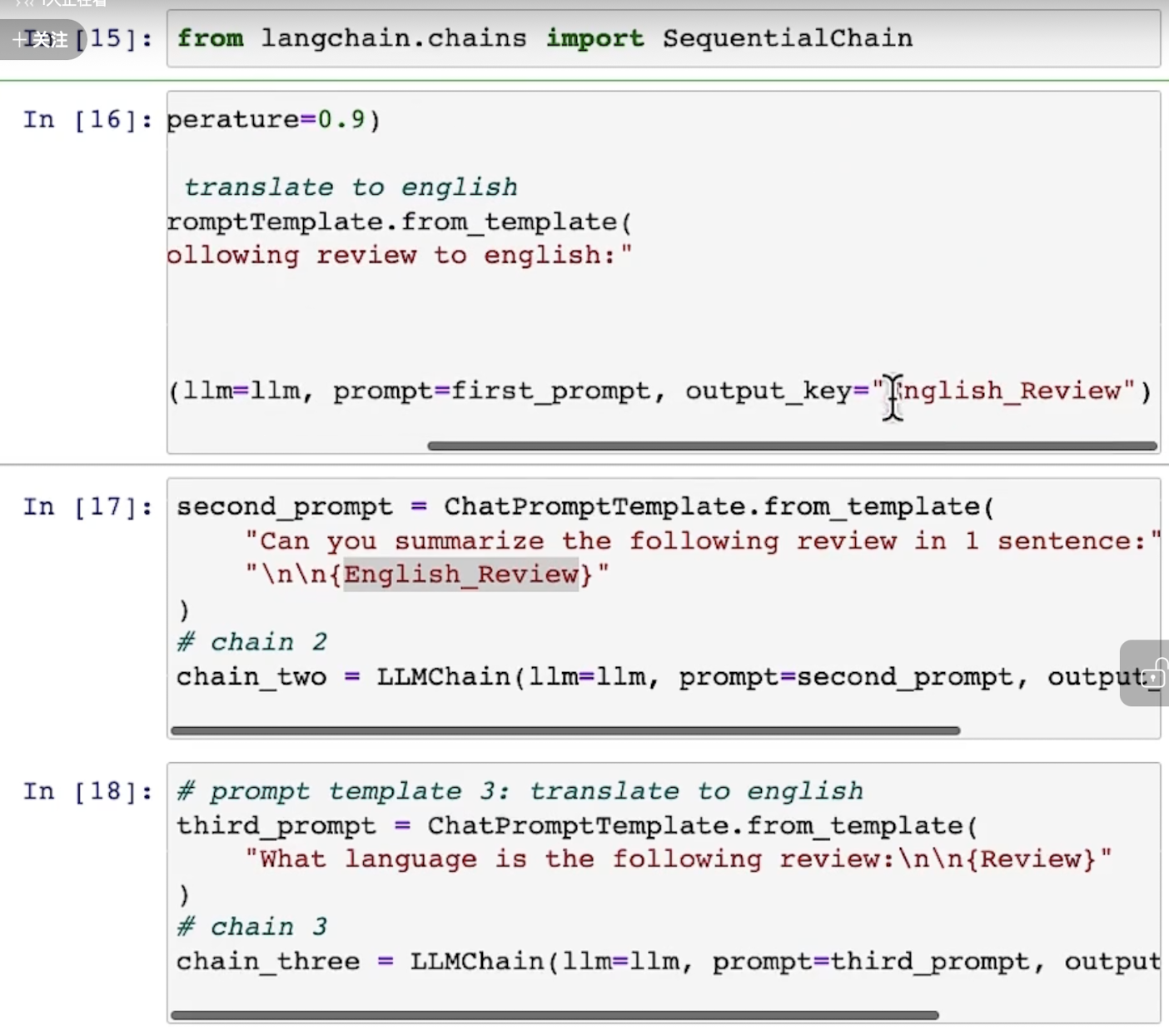
此时的示意图如下:
Router Chain
用于不同领域的处理,针对不同的领域,给出不同的prompt(需要自己提前定义有哪几种prompt)。
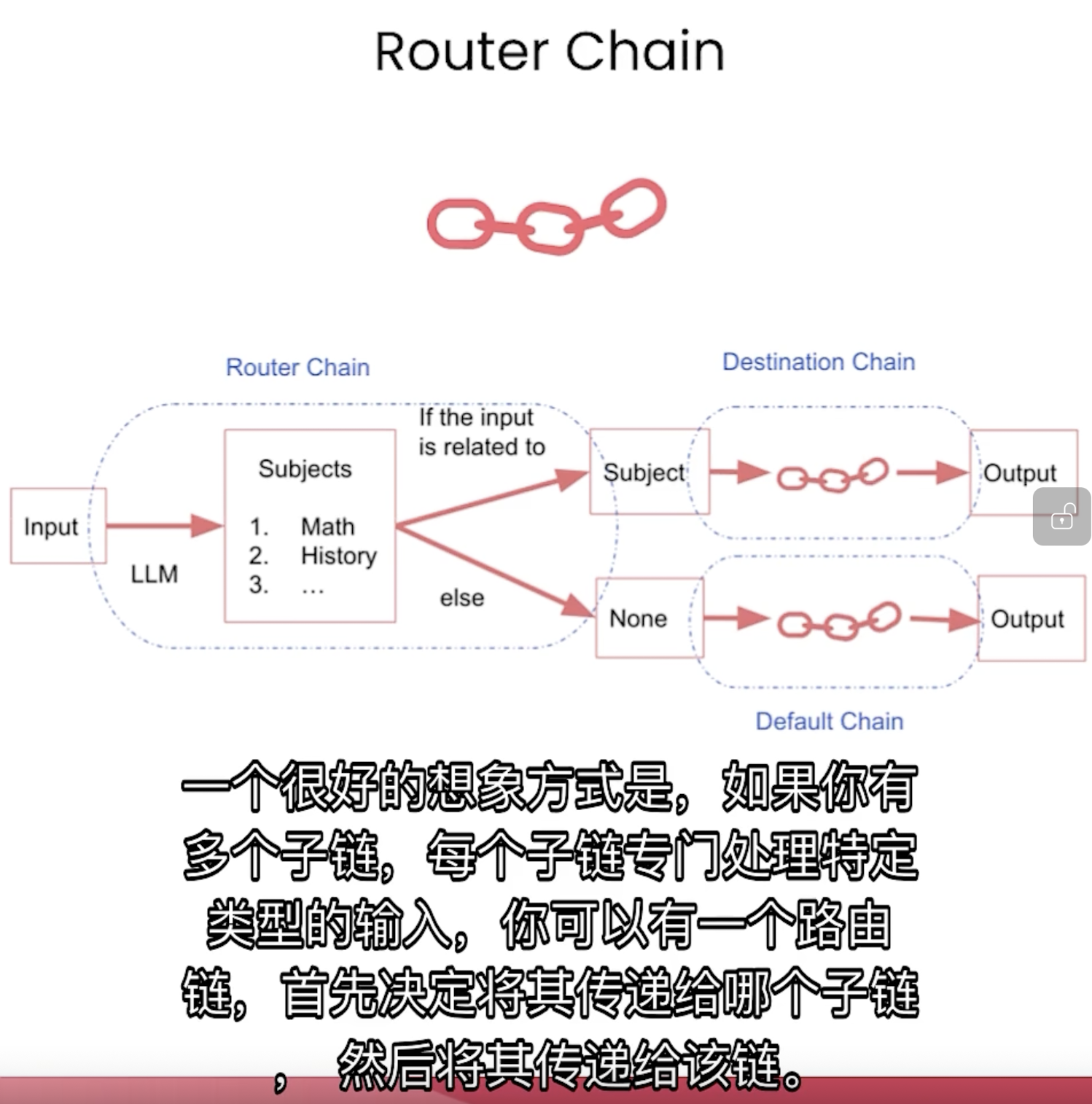
具体举例说明,比如有多个学科的老师,需要回答某一领域的问题时,先定义不同学科的prompt:
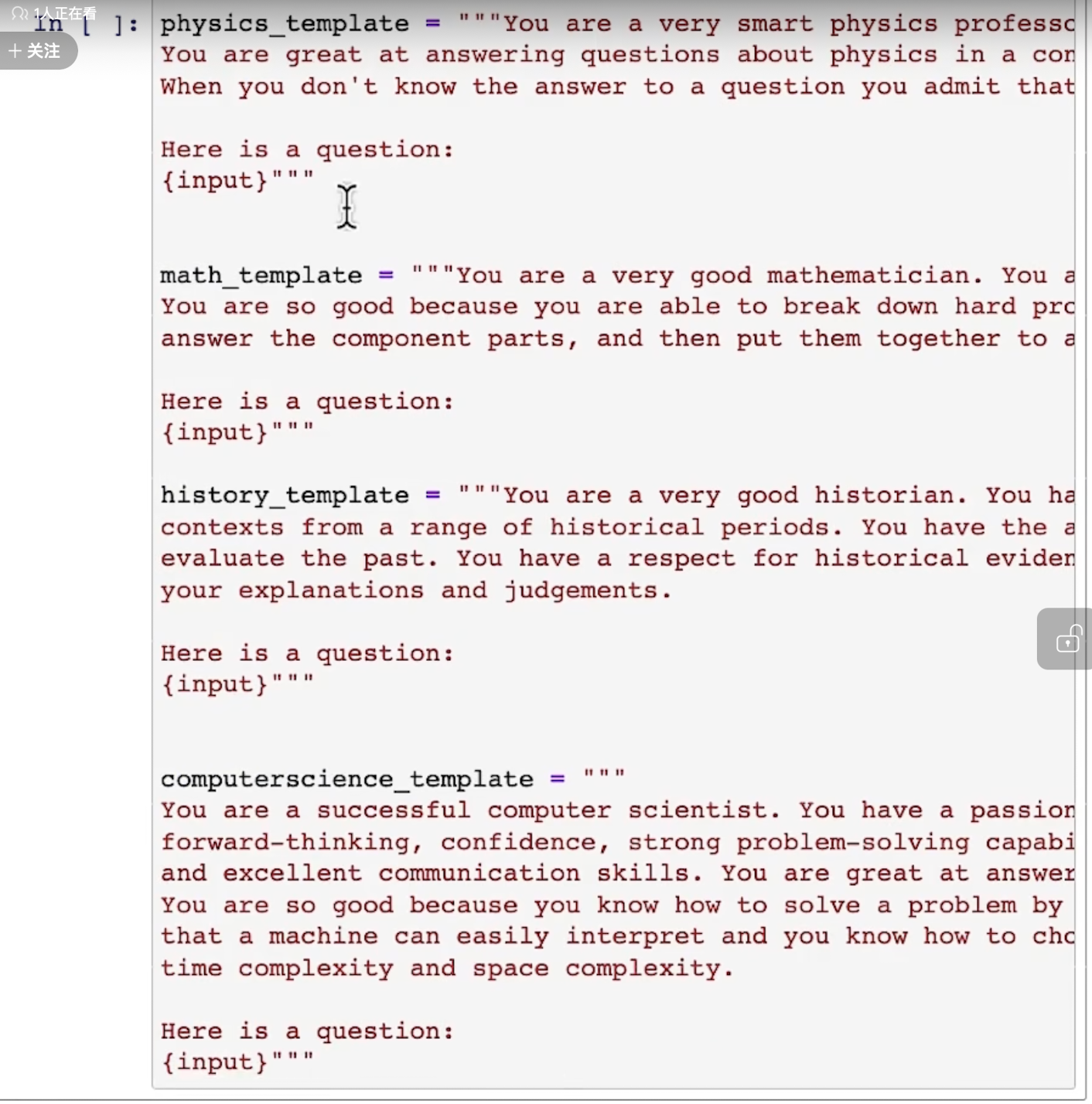
再定义所有promt的信息:
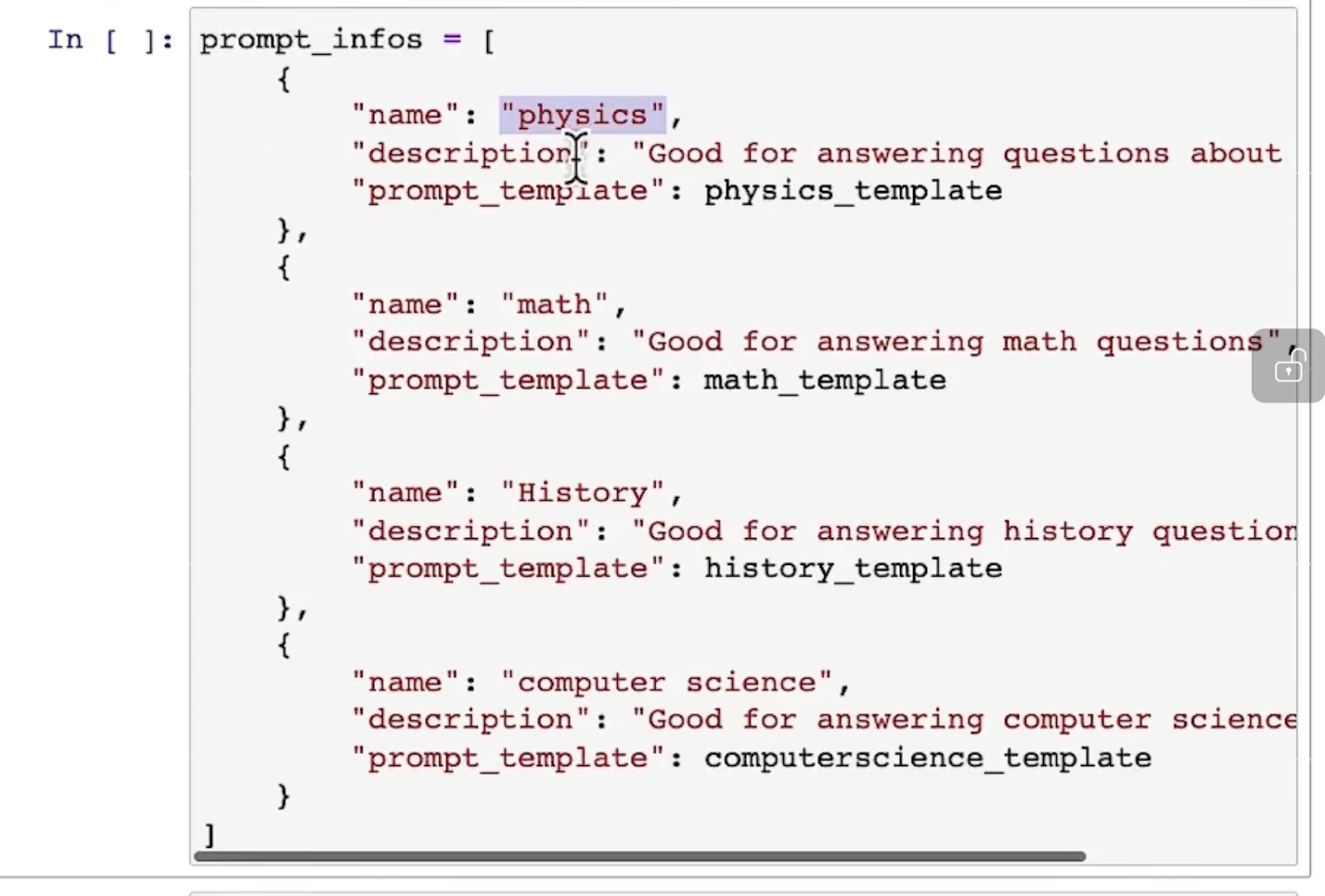
然后开始调用 MultiPromptChain 等函数:
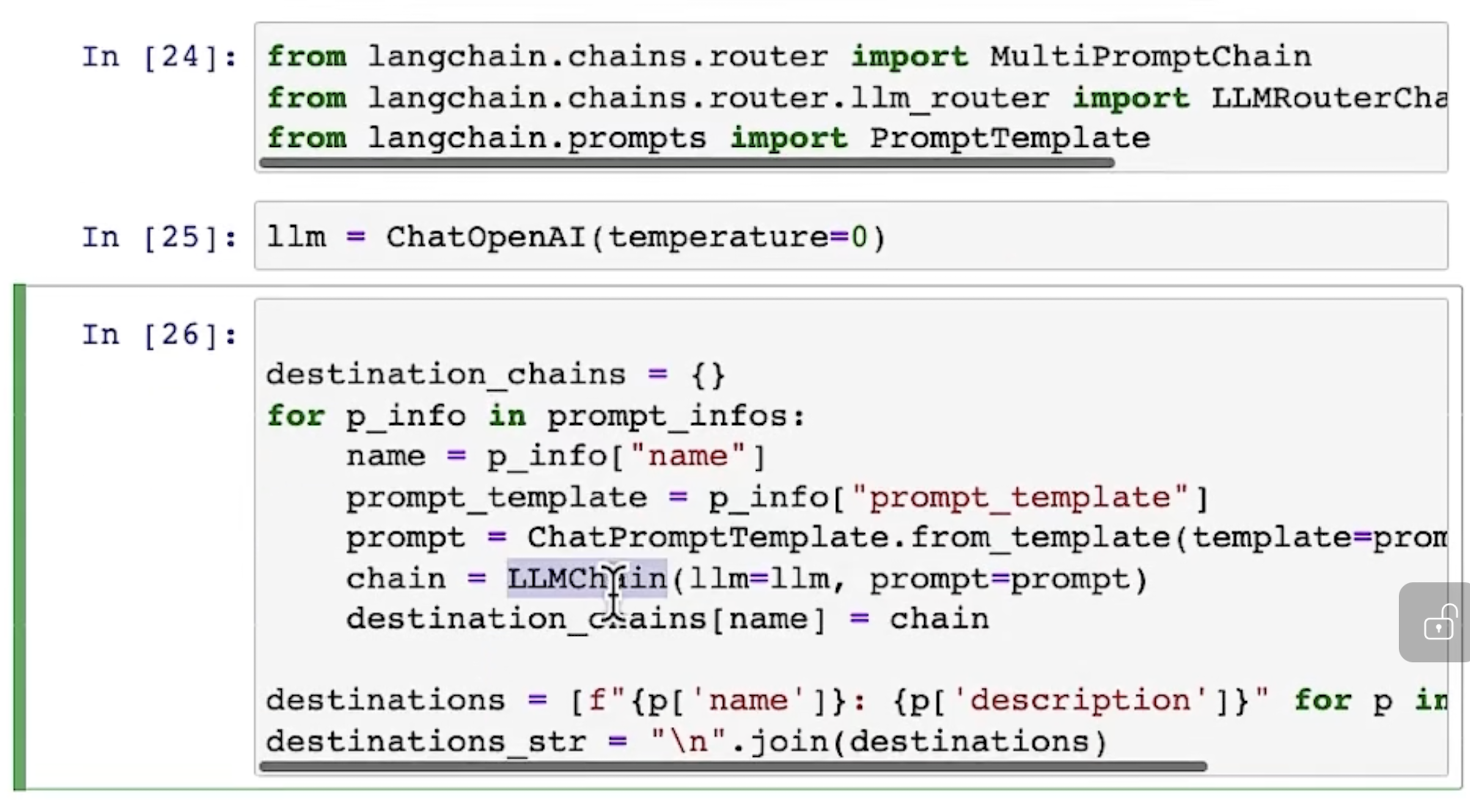
还要定义defalt chain:


功能3:根据文档回答问题
需要用到 embedding 和 向量储存(Vector Database)技术,在所上传的文档中进行检索、匹配等操作。
来康康怎么实现的,假设上传一个 csv 文件,需要 gpt 根据所上传的文件回答问题。
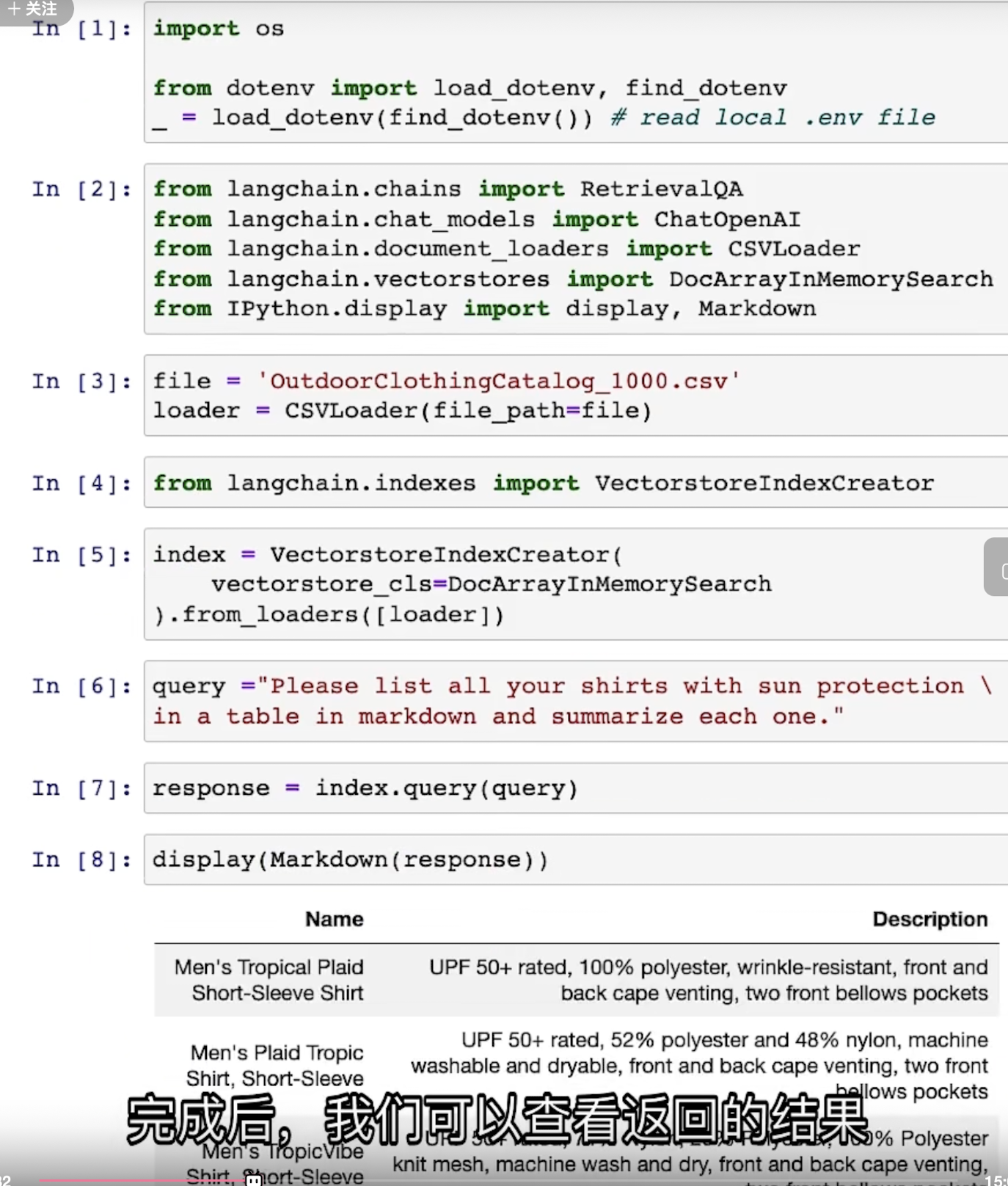
但是有时候文档很大时,gpt无法输入这么长的内容(LLM模型一次性输入的token是有限制的):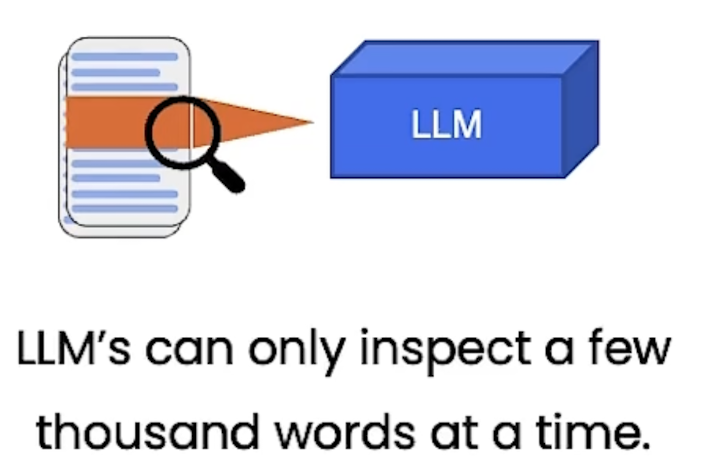
这时候就要引入embeding和向量储存技术了。
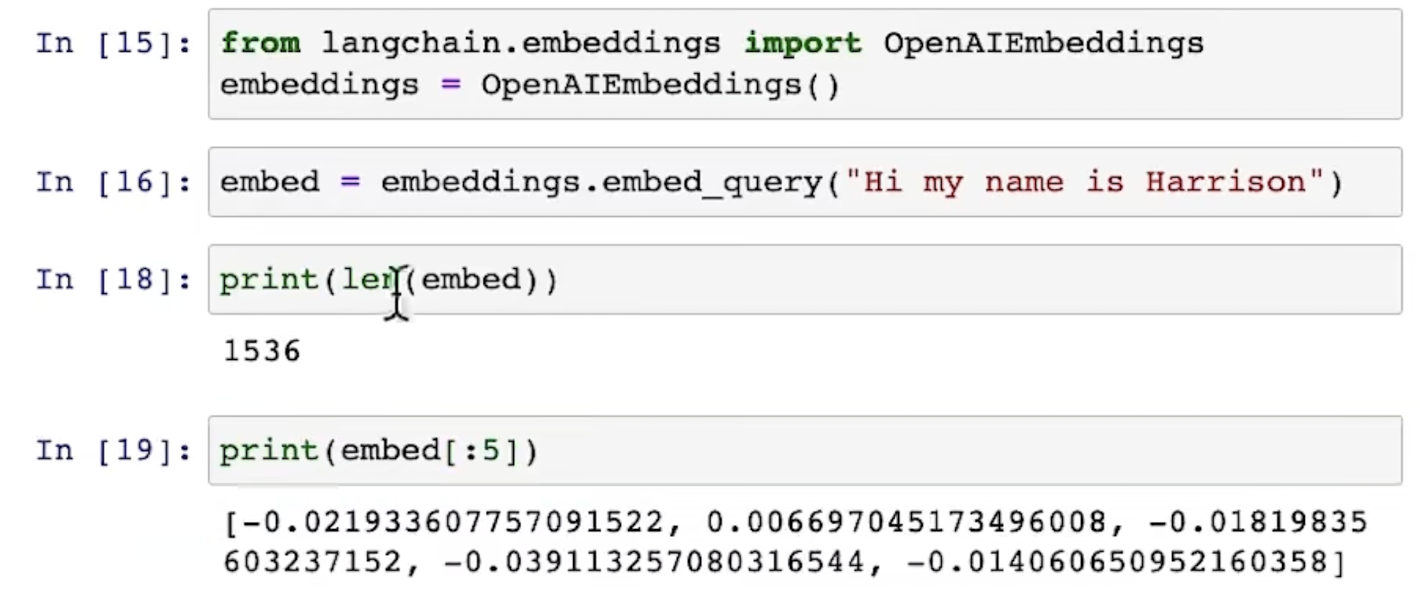
embedding
即用 vector 表达某一段话的内容, 当两句话相似度比较高的时候, 他们对应embedding 的结果也非常相似:
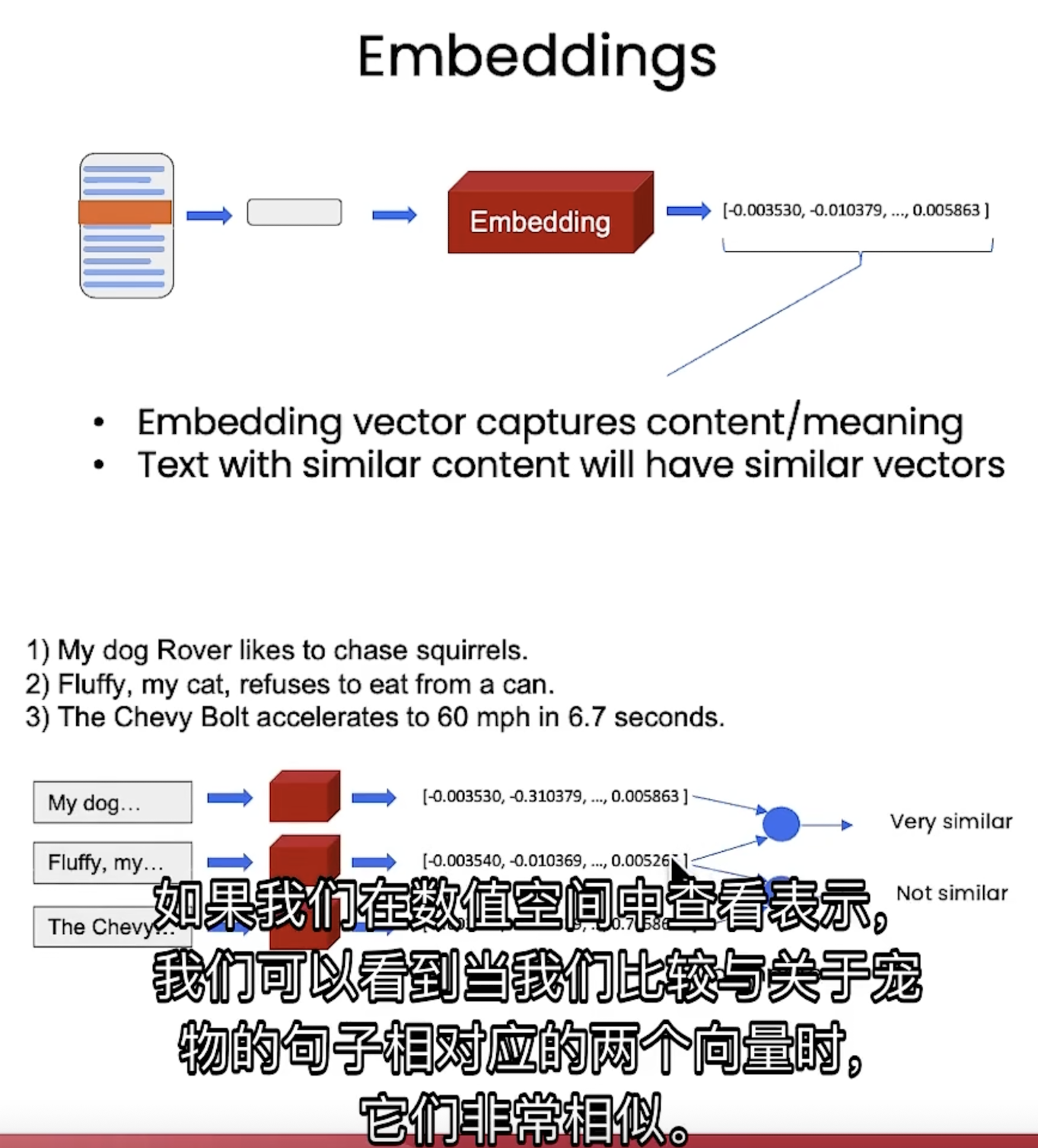
Vector Database
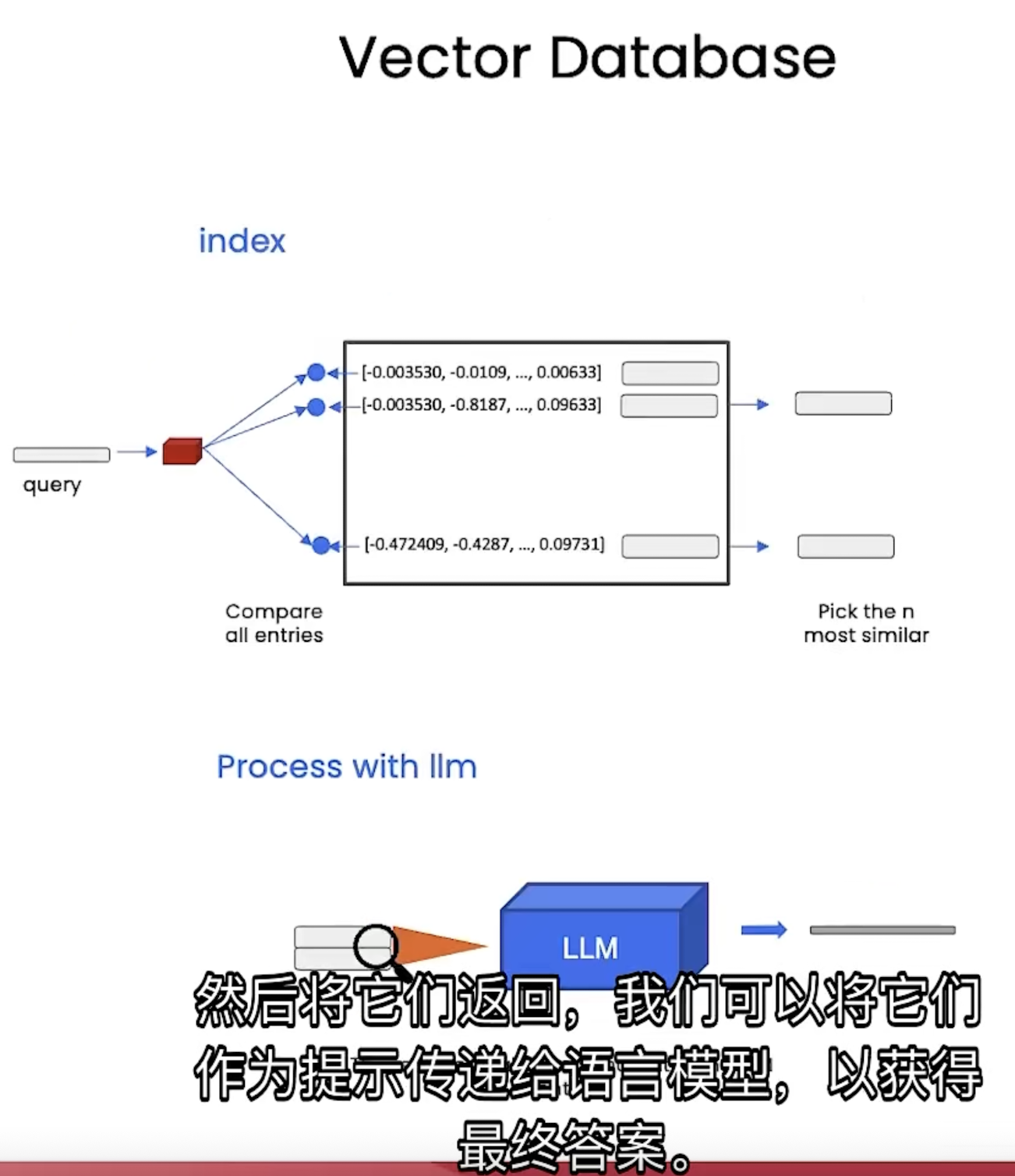
把每一段内容进行embedding,然后按照index的方式储存他们的embedding。

在输入 query 进行查询的时候,将 query 也 embbedding 化,然后查询它和之前储存的所有句子的 embdding的相似度,选取相似度比较高的几个句子,从而进行回答:
代码实现
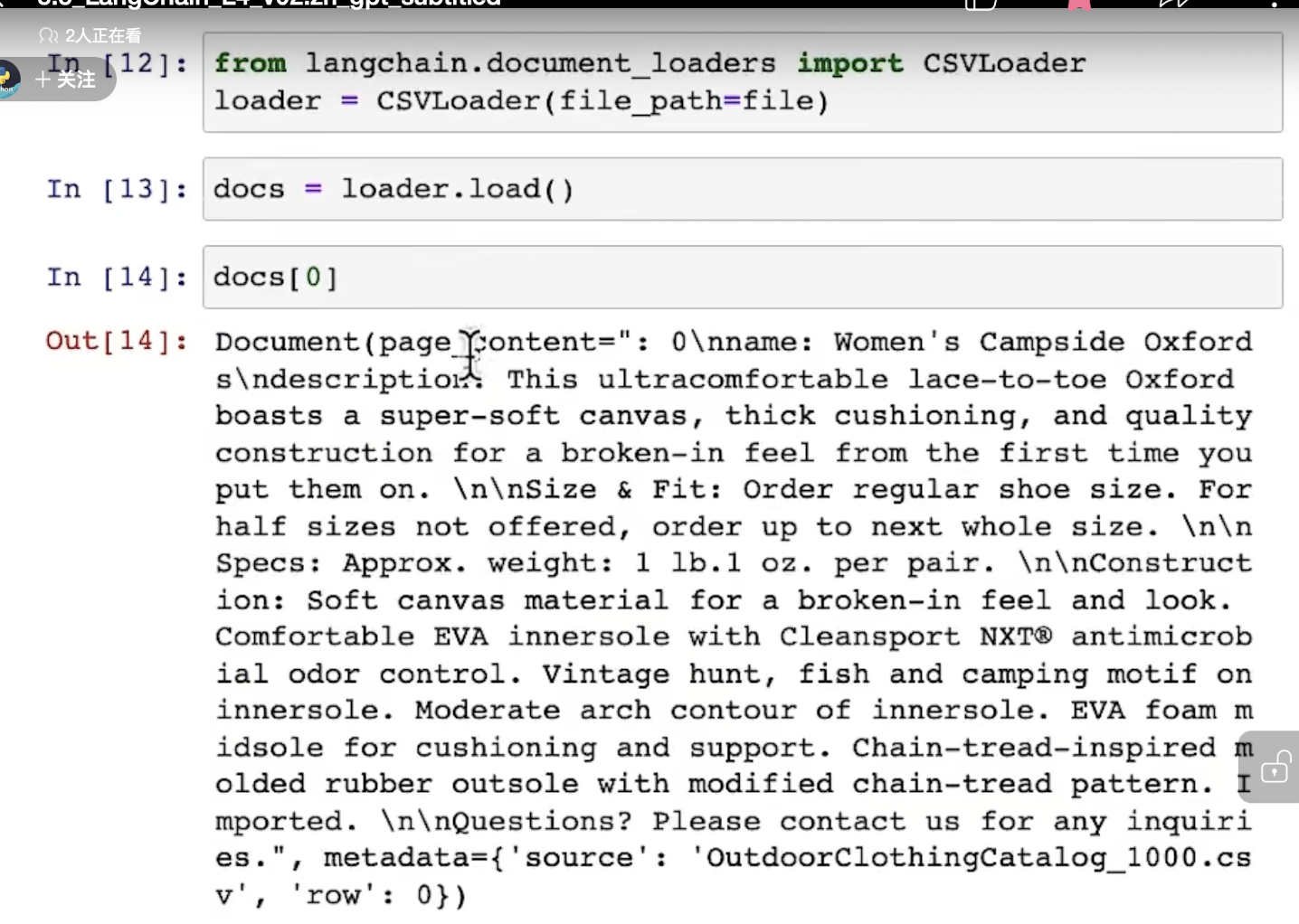
加载一个文档:
查看 embedding 的用法,可以看到其有1536纬度:
建立 vector database 并查找高相似度的句子:

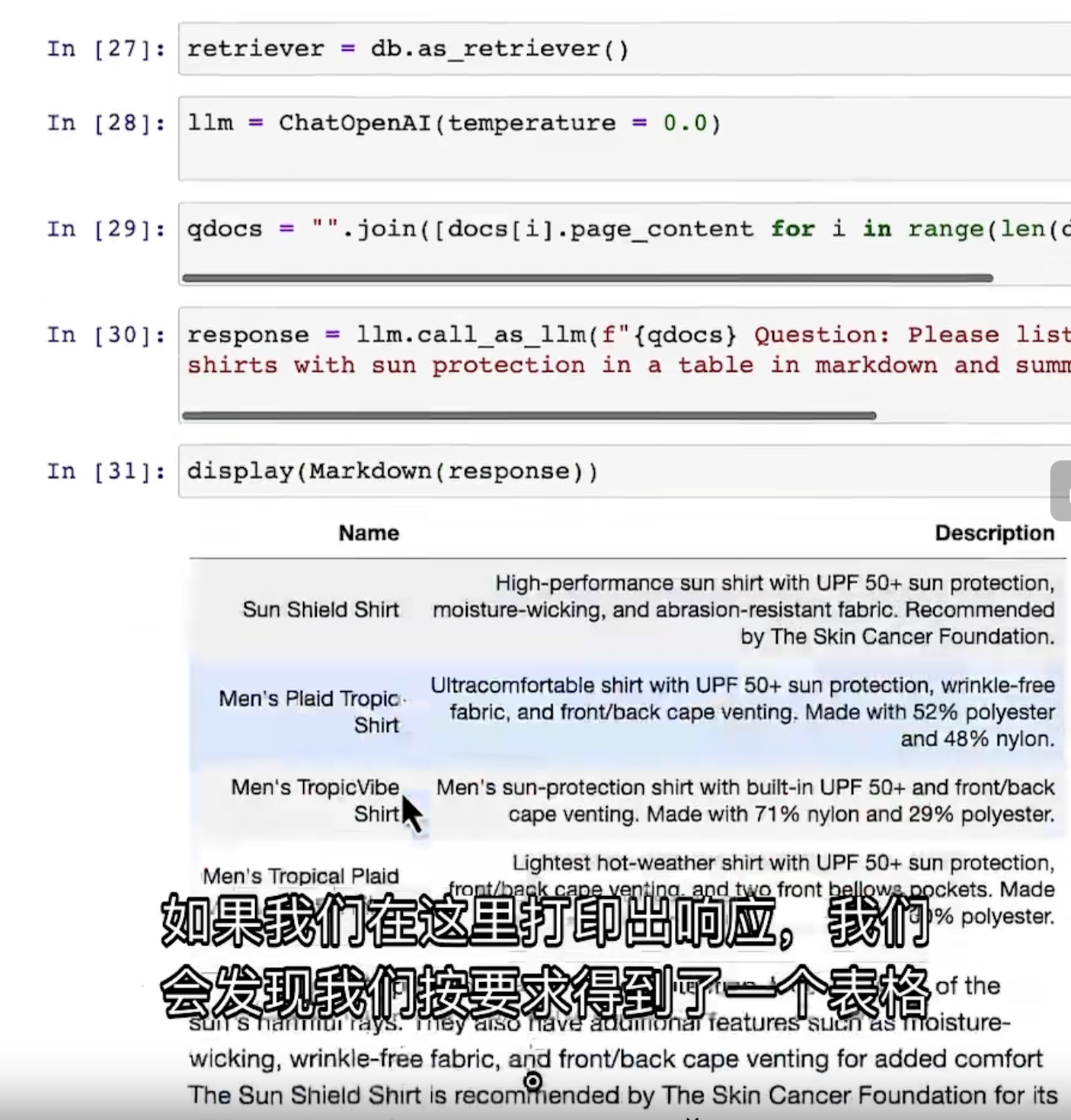
返回了四个文档:

取回所需要(相似度高)的内容: