狭义的Hadoop VS 广义的Hadoop
- 广义的Hadoop:指的是Hadoop生态系统,Hadoop生态系统是一个很庞大的概念,hadoop是其中最重要最基础的一个部分,生态系统中每一子系统只解决某一个特定的问题域(甚至可能更窄),不搞统一型的全能系统,而是小而精的多个小系统;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QnQNF0jk-1687952907173)(img/hadoop-%E7%94%9F%E6%80%81.png)]](https://img-blog.csdnimg.cn/8cafc5ee611d4823b43b33dd32838cb7.png)
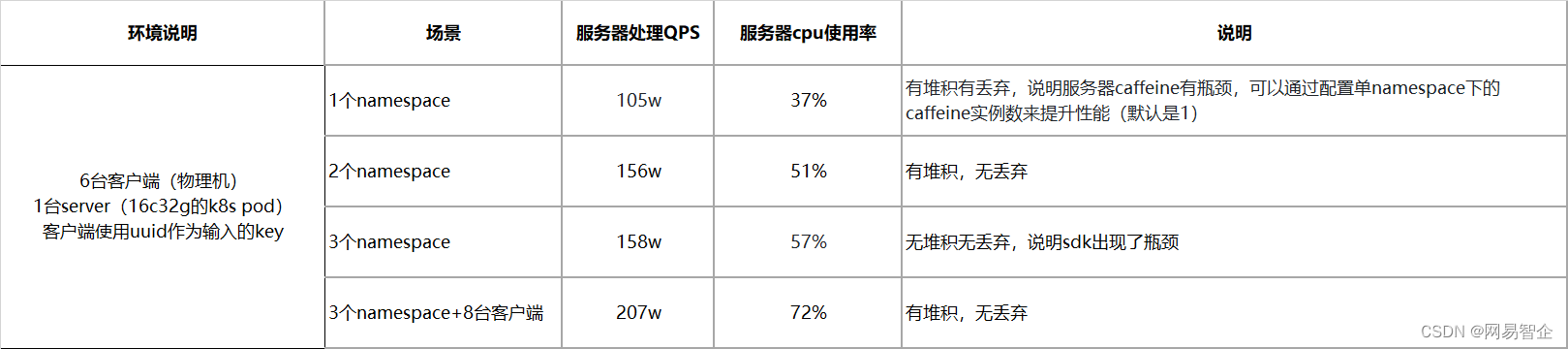
Hive:数据仓库
R:数据分析
Mahout:机器学习库
pig:脚本语言,跟Hive类似
Oozie:工作流引擎,管理作业执行顺序
Zookeeper:用户无感知,主节点挂掉选择从节点作为主的
Flume:日志收集框架
Sqoop:数据交换框架,例如:关系型数据库与HDFS之间的数据交换
Hbase : 海量数据中的查询,相当于分布式文件系统中的数据库
Spark: 分布式的计算框架基于内存
- spark core
- spark sql
- spark streaming 准实时 不算是一个标准的流式计算
- spark ML spark MLlib
Kafka: 消息队列
Storm: 分布式的流式计算框架 python操作storm
Flink: 分布式的流式计算框架
Hadoop生态系统的特点
-
开源、社区活跃
-
囊括了大数据处理的方方面面
-
成熟的生态圈