深入了解glibc的互斥锁
互斥锁是多线程同步时常用的手段,使用互斥锁可以保护对共享资源的操作。共享资源也被称为临界区,当一个线程对一个临界区加锁后,其他线程就不能进入该临界区,直到持有临界区锁的线程释放该锁。
本文以glibc中mutex的实现为例,讲解其背后的实现原理。
glibc mutex类型
glibc的互斥锁的类型名称为pthread_mutex_t,其结构可以用下面的结构体表示:
typedef struct {
int __lock;
int __count;
int __owner;
int __nusers;
int __kind;
// other ignore
} pthread_mutex_t;
其中:
- __lock表示当前mutex的状态,0表示没有被加锁,1表示mutex已经被加锁,2表示mutex被某个线程持有并且有另外的线程在等待它的释放。
- __count表示mutex被加锁的次数,对于不可重入锁,该值为0或者1,对于可重入锁,count可以大于1。
- __owner用来记录持有当前mutex的线程id。
- __nusers用于记录多少个线程持有该互斥锁,一般来说该值只能是0或者1,但是对于读写锁,多个读线程可以共同持有锁,因此nusers通常用于读写锁的场景下。
- __kind表示锁的类型。
pthread_mutex_t锁可以是如下的类型:
- PTHREAD_MUTEX_TIMED_NP: 普通锁,当一个线程加锁以后,其余请求锁的线程将形成一个等待队列,并在解锁后按优先级获得锁。这种锁策略保证了资源分配的公平性。当锁unlock时,会唤醒等待队列中的一个线程。
- PTHREAD_MUTEX_RECURSIVE_NP: 可重入锁,如果线程没有获得该mutex的情况下,争用该锁,那么与PTHREAD_MUTEX_TIMED_NP一样。如果一个线程已经获取锁,其可以再次获取锁,并通过多次unlock解锁。
- PTHREAD_MUTEX_ERRORCHECK_NP: 检错锁,如果同一个线程请求同一个锁,则返回EDEADLK,而不是死锁,其他点和PTHREAD_MUTEX_TIMED_NP相同。
- PTHREAD_MUTEX_ADAPTIVE_NP: 自适应锁,此锁在多核处理器下首先进行自旋获取锁,如果自旋次数超过配置的最大次数,则也会陷入内核态挂起。
mutex的加锁过程
本文使用的源码是glibc-2.34版本,http://mirror.keystealth.org/gnu/libc/glibc-2.34.tar.gz。
本文主要侧重于讲解互斥锁从用户态到内核态的加锁过程,而不同类型锁的实现细节,本文不重点讨论。后续将在其他文章中做探讨。
下面就以最简单的类型PTHREAD_MUTEX_TIMED_NP来跟踪加锁过程,从___pthread_mutex_lock开始看起,其定义在pthread_mutex_lock.c中。
如下所示,PTHREAD_MUTEX_TIMED_NP的锁会调用lll_mutex_lock_optimized方法进行加锁,如下所示:
if (__builtin_expect (type & ~(PTHREAD_MUTEX_KIND_MASK_NP
| PTHREAD_MUTEX_ELISION_FLAGS_NP), 0))
return __pthread_mutex_lock_full (mutex);
if (__glibc_likely (type == PTHREAD_MUTEX_TIMED_NP))
{
FORCE_ELISION (mutex, goto elision);
simple:
/* Normal mutex. */
LLL_MUTEX_LOCK_OPTIMIZED (mutex);
assert (mutex->__data.__owner == 0);
}
lll_mutex_lock_optimized也定义在pthread_mutex_lock.c文件中,从注释了解到,这是为单线程进行的优化,如果是单线程,则直接将mutex的__lock的值修改为1(因为不存在竞争),如果不是单线程,则调用lll_lock方法。
#ifndef LLL_MUTEX_LOCK
/* lll_lock with single-thread optimization. */
static inline void
lll_mutex_lock_optimized (pthread_mutex_t *mutex)
{
/* The single-threaded optimization is only valid for private
mutexes. For process-shared mutexes, the mutex could be in a
shared mapping, so synchronization with another process is needed
even without any threads. If the lock is already marked as
acquired, POSIX requires that pthread_mutex_lock deadlocks for
normal mutexes, so skip the optimization in that case as
well. */
int private = PTHREAD_MUTEX_PSHARED (mutex);
if (private == LLL_PRIVATE && SINGLE_THREAD_P && mutex->__data.__lock == 0)
mutex->__data.__lock = 1;
else
lll_lock (mutex->__data.__lock, private);
}
# define LLL_MUTEX_LOCK(mutex) \
lll_lock ((mutex)->__data.__lock, PTHREAD_MUTEX_PSHARED (mutex))
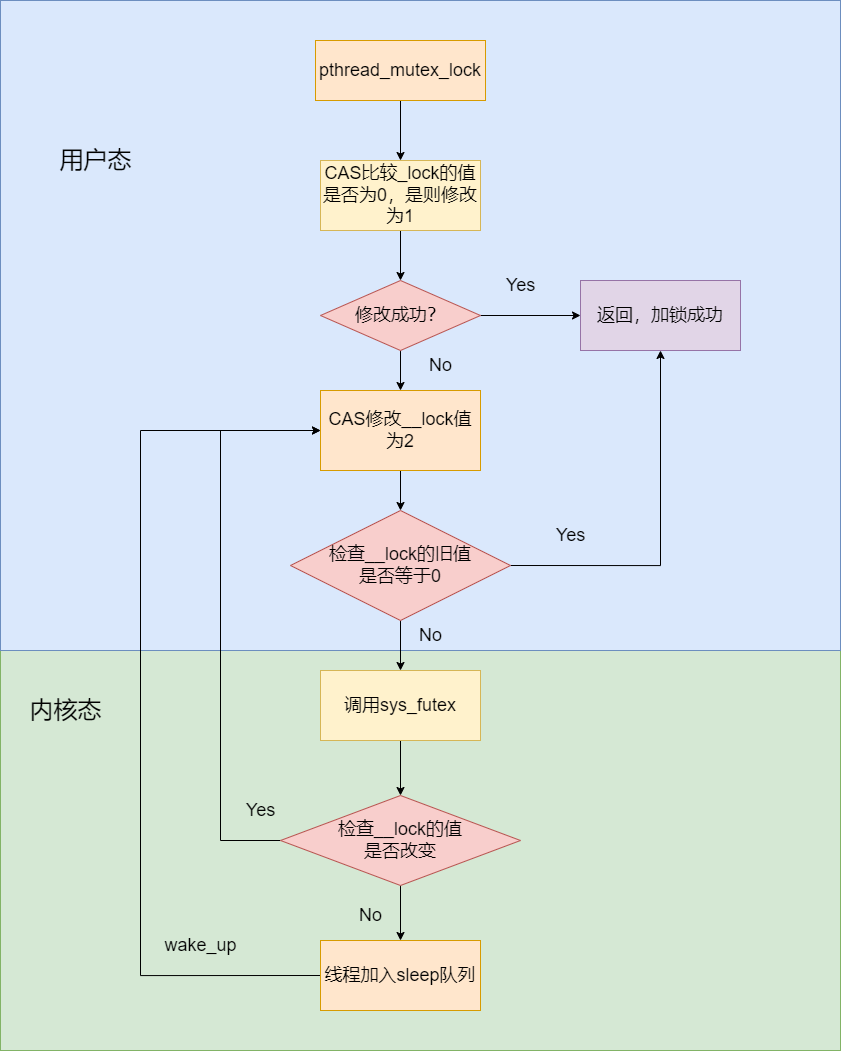
lll_lock定义在lowlevellock.h文件中,又会调用到**__lll_lock方法,由于存在竞争,因此在__lll_lock方法中使用了CAS方法**尝试对mutex的__lock值进行修改。
CAS是compare-and-swap的含义,其是原子变量的实现的基础,其伪代码如下所示,即当内存mem出的值如果等于old_value,则将其替换为new_value,这个过程是原子的,底层由CMPXCHG指令保证。
bool CAS(T* mem, T new_value, T old_value) {
if (*mem == old_value) {
*mem = new_value;
return true;
} else {
return false;
}
}
__lll_lock中的atomic_compare_and_exchange_bool_acq就是上述所说的CAS方法,如果futex = 0,则尝试将其修改为1,表示加锁成功, 如果futex >= 1,则会调用**__lll_lock_wait_private或者__lll_lock_wait**。注意这里的futex其实就是mutex结构体中的__lock。
#define __lll_lock(futex, private) \
((void) \
({ \
int *__futex = (futex); \
if (__glibc_unlikely \
(atomic_compare_and_exchange_bool_acq (__futex, 1, 0))) \
{ \
if (__builtin_constant_p (private) && (private) == LLL_PRIVATE) \
__lll_lock_wait_private (__futex); \
else \
__lll_lock_wait (__futex, private); \
} \
}))
#define lll_lock(futex, private) \
__lll_lock (&(futex), private)
__lll_lock_wait_private和__lll_lock_wait是类似的,这里首先会调用atomic_exchange_acquire将futex的旧值和2进行交换,返回值是futex的旧值。
因此如果其返回值不为0,代表当前锁还是加锁状态,可能需要进入内核态等待(调用futex_wait)。如果其返回0,则代表,当前锁已经被释放,加锁成功,退出循环。
注意futex值修改为2的目的是为了提高pthread_mutex_unlock的效率。在pthread_mutex_unlock中,会调用atomic_exchange_rel()无条件的把mutex->__lock的值更新为0,并且检查mutex->__lock的原始值,如果原始值为0或者1,表示没有竞争发生,自然也就没有必要调用futex系统调用,浪费时间。只有检查到mutex->__lock的值大于1的时候,才需要调用futex系统调用,唤醒等待该锁上的线程。
void
__lll_lock_wait_private (int *futex)
{
if (atomic_load_relaxed (futex) == 2)
goto futex;
while (atomic_exchange_acquire (futex, 2) != 0)
{
futex:
LIBC_PROBE (lll_lock_wait_private, 1, futex);
futex_wait ((unsigned int *) futex, 2, LLL_PRIVATE); /* Wait if *futex == 2. */
}
}
libc_hidden_def (__lll_lock_wait_private)
void
__lll_lock_wait (int *futex, int private)
{
if (atomic_load_relaxed (futex) == 2)
goto futex;
while (atomic_exchange_acquire (futex, 2) != 0)
{
futex:
LIBC_PROBE (lll_lock_wait, 1, futex);
futex_wait ((unsigned int *) futex, 2, private); /* Wait if *futex == 2. */
}
}
__lll_lock_wait_private和__lll_lock_wait调用了futex_wait,该函数相对简单,其内部将会调用lll_futex_timed_wait方法。
static __always_inline int
futex_wait (unsigned int *futex_word, unsigned int expected, int private)
{
int err = lll_futex_timed_wait (futex_word, expected, NULL, private);
switch (err)
{
case 0:
case -EAGAIN:
case -EINTR:
return -err;
case -ETIMEDOUT: /* Cannot have happened as we provided no timeout. */
case -EFAULT: /* Must have been caused by a glibc or application bug. */
case -EINVAL: /* Either due to wrong alignment or due to the timeout not
being normalized. Must have been caused by a glibc or
application bug. */
case -ENOSYS: /* Must have been caused by a glibc bug. */
/* No other errors are documented at this time. */
default:
futex_fatal_error ();
}
}
lll_futex_timed_wait方法其实是对sys_futex系统调用的封装,其最终将调用sys_futex方法。
# define lll_futex_timed_wait(futexp, val, timeout, private) \
lll_futex_syscall (4, futexp, \
__lll_private_flag (FUTEX_WAIT, private), \
val, timeout)
# define lll_futex_syscall(nargs, futexp, op, ...) \
({ \
long int __ret = INTERNAL_SYSCALL (futex, nargs, futexp, op, \
__VA_ARGS__); \
(__glibc_unlikely (INTERNAL_SYSCALL_ERROR_P (__ret)) \
? -INTERNAL_SYSCALL_ERRNO (__ret) : 0); \
})
#define __NR_futex 202
#undef INTERNAL_SYSCALL
#define INTERNAL_SYSCALL(name, nr, args...) \
internal_syscall##nr (SYS_ify (name), args)
#undef SYS_ify
#define SYS_ify(syscall_name) __NR_##syscall_name
#undef internal_syscall4
#define internal_syscall4(number, arg1, arg2, arg3, arg4) \
({ \
unsigned long int resultvar; \
TYPEFY (arg4, __arg4) = ARGIFY (arg4); \
TYPEFY (arg3, __arg3) = ARGIFY (arg3); \
TYPEFY (arg2, __arg2) = ARGIFY (arg2); \
TYPEFY (arg1, __arg1) = ARGIFY (arg1); \
register TYPEFY (arg4, _a4) asm ("r10") = __arg4; \
register TYPEFY (arg3, _a3) asm ("rdx") = __arg3; \
register TYPEFY (arg2, _a2) asm ("rsi") = __arg2; \
register TYPEFY (arg1, _a1) asm ("rdi") = __arg1; \
asm volatile ( \
"syscall\n\t" \
: "=a" (resultvar) \
: "0" (number), "r" (_a1), "r" (_a2), "r" (_a3), "r" (_a4) \
: "memory", REGISTERS_CLOBBERED_BY_SYSCALL); \
(long int) resultvar; \
})
sys_futex的函数原型如下所示:
int sys_futex (int *uaddr, int op, int val, const struct timespec *timeout);
其作用是原子性的检查uaddr中计数器的值是否为val,如果是则让进程休眠,直到FUTEX_WAKE或者超时(time-out)。也就是把进程挂到uaddr相对应的等待队列上去。
这里实际上就是检查mutex的**__lock是否等于2**。
- 如果不等于2,意味着,锁可能已经被释放,不需要将线程添加到sleep队列,sys_futex直接返回,重新尝试加锁。
- 如果等于2,则意味着用户态到内核段的这段时间内,锁的值没有发生变化,于是将线程添加到sleep队列,等待其他线程释放锁。
glibc的mutex的加锁是用户态的原子操作和内核态sys_futex共同作用的结果,上述过程可以用下面这张流程图来概括: