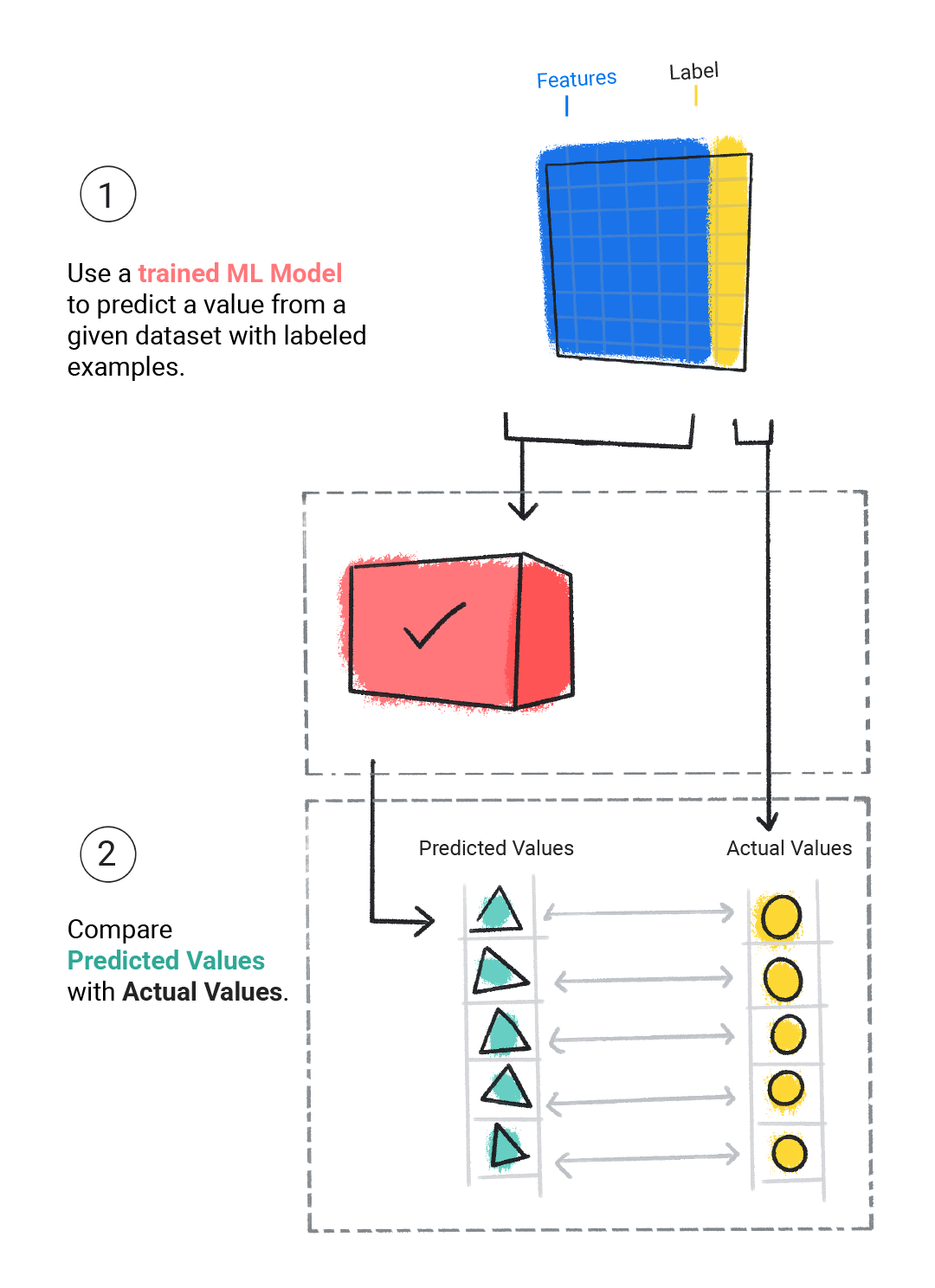
1.概述
最近又是一轮代码review , 发现了一些实现去重的代码,在使用 list.contain …
我沉思,是不是其实很多初学者也存在这种去重使用问题?
所以我选择把这个事情整出来,分享一下。
2.contain 去重
首先是造出一个 List 模拟数据,一共2W条,里面有一半数据1W条是重复的:
public static List<String> getTestList() {
List<String> list = new ArrayList<>();
for (int i = 1; i <= 10000; i++) {
list.add(String.valueOf(i));
}
for (int i = 10000; i >= 1; i--) {
list.add(String.valueOf(i));
}
return list;
}
先看看我们用 contain 去重的代码:
/**
* 使用 list.contain 去重
*
* @param testList
*/
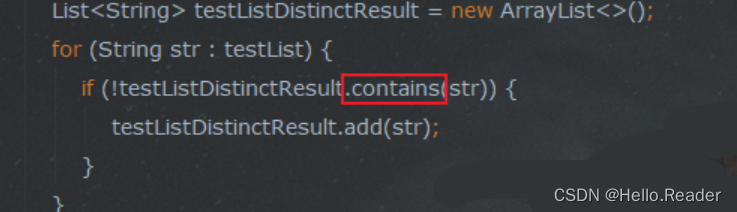
private static void useContain2Distinct(List<String> testList) {
System.out.println("contains 开始去重,条数:" + testList.size());
List<String> testListDistinctResult = new ArrayList<>();
for (String str : testList) {
if (!testListDistinctResult.contains(str)) {
testListDistinctResult.add(str);
}
}
System.out.println("contains 去重完毕,条数:" + testListDistinctResult.size());
}
我们调用一下看看耗时:
public static void main(String[] args) {
List<String> testList = getTestList();
StopWatch stopWatch = new StopWatch();
stopWatch.start();
useContainDistinct(testList);
stopWatch.stop();
System.out.println("去重 最终耗时" + stopWatch.getTotalTimeMillis());
}
耗时:
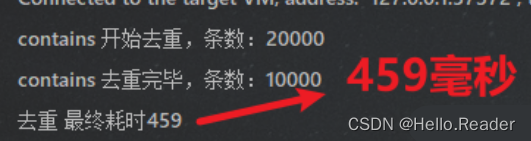
评价:list.contain 的效率,我的建议是,知道就行,别用。
3.HashSet 去重
众所周知 Set 不存在重复数据, 所以我们来看看使用 HashSet 去重的性能:
ps:这里是采取使用 set 的 add 方法做去重
/**
* 使用set去重
*
* @param testList
*/
private static void useSetDistinct(List<String> testList) {
System.out.println("HashSet.add 开始去重,条数:" + testList.size());
List<String> testListDistinctResult = new ArrayList<>(new HashSet(testList));
System.out.println("HashSet.add 去重完毕,条数:" + testListDistinctResult.size());
}
我们调用一下看看耗时:
public static void main(String[] args) {
List<String> testList = getTestList();
StopWatch stopWatch = new StopWatch();
stopWatch.start();
useSetDistinct(testList);
stopWatch.stop();
System.out.println("去重 最终耗时" + stopWatch.getTotalTimeMillis());
}
耗时:
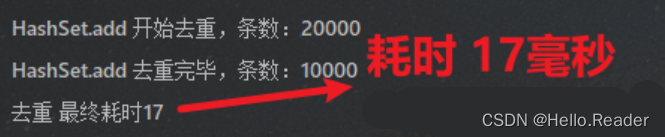
评价:HashSet 的效率,我的建议是推荐。
我们创建了一个高质量的技术交流群,与优秀的人在一起,自己也会优秀起来,赶紧点击加群,享受一起成长的快乐。
4.list.contains
为什么耗时差距这么大?
不多说,我们看源码:
list.contains(o):
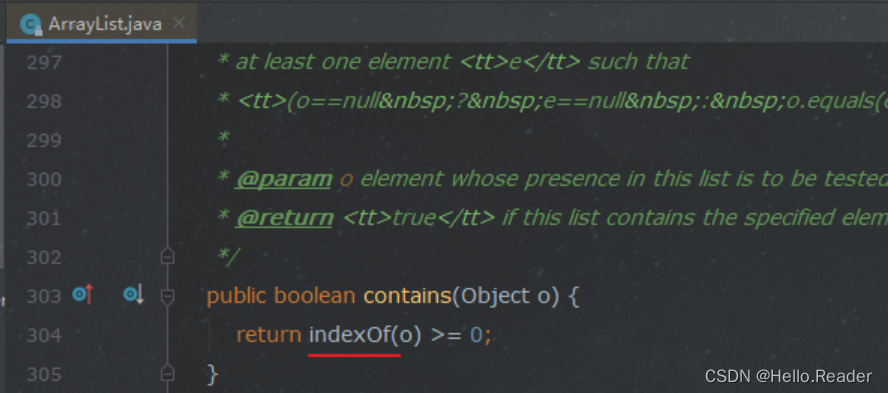 可以看到里面用到了 index(o) :
可以看到里面用到了 index(o) :
时间复杂度 :O(n) n: 元素个数
那么我们看看 set.add(o) 是怎么样的
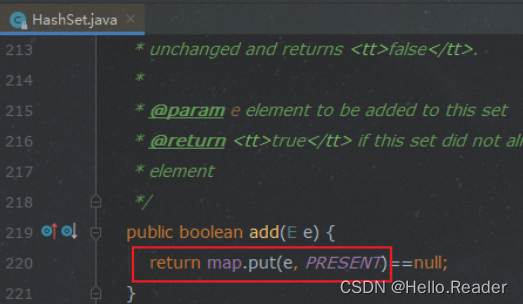
map的add , 老生常谈就不谈了,hash完 直接塞到某个位置, 时间复杂度 :O(1) 。
所以 O(n) 和 O(1) 谁快谁慢?显然。
 ps:顺嘴说下 hashset 的 contain
ps:顺嘴说下 hashset 的 contain
时间复杂度也是:O(1)

5.传统去重
那么我们最后再看看别的去重:
双for循环 ,remove去重
/**
* 使用双for循环去重
* @param testList
*/
private static void use2ForDistinct(List<String> testList) {
System.out.println("list 双循环 开始去重,条数:" + testList.size());
for (int i = 0; i < testList.size(); i++) {
for (int j = i + 1; j < testList.size(); j++) {
if (testList.get(i).equals(testList.get(j))) {
testList.remove(j);
}
}
}
System.out.println("list 双循环 去重完毕,条数:" + testList.size());
}
public static void main(String[] args) {
List<String> testList = getTestList();
StopWatch stopWatch = new StopWatch();
stopWatch.start();
use2ForDistinct(testList);
stopWatch.stop();
System.out.println("去重 最终耗时" + stopWatch.getTotalTimeMillis());
}
耗时:
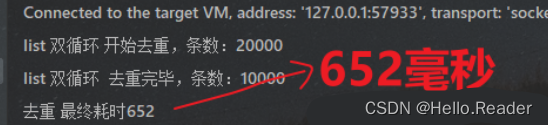
评价:知道就行,图个乐,别用,贼慢,而且代码看起来乱
stream的distinct去重:
/**
* 使用Stream 去重
*
* @param testList
*/
private static void useStreamDistinct(List<String> testList) {
System.out.println("stream 开始去重,条数:" + testList.size());
List<String> testListDistinctResult = testList.stream().distinct().collect(Collectors.toList());
System.out.println("stream 去重完毕,条数:" + testListDistinctResult.size());
}
public static void main(String[] args) {
List<String> testList = getTestList();
StopWatch stopWatch = new StopWatch();
stopWatch.start();
useStreamDistinct(testList);
stopWatch.stop();
System.out.println("去重 最终耗时" + stopWatch.getTotalTimeMillis());
}
耗时:
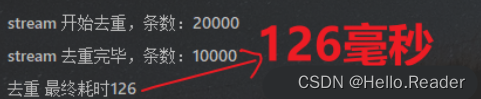
评价:还不错,主要是代码也蛮简洁,有一点点动心。
最后,如果你还有其他高效去重方法的话,欢迎留言区分享一下呗~
![[CKA]考试之七层负载均衡Ingress](https://img-blog.csdnimg.cn/cfb3764d4d7d4891921e4527d28ade48.png)




![[CVPR 2023] Imagic:使用扩散模型进行基于文本的真实图像编辑](https://img-blog.csdnimg.cn/img_convert/5c990ea9f7674e7e1bab2c127615339c.png)