CtFS(FAST'22)
- 1. 背景(Background)
- 1.1 NVM
- 1.2 NVM文件系统
- 1.3 快速索引方案
- 2. 观察与动机(Observation & Motivation)
- 3. CtFS设计与实现(Design & Implementation)
- 3.1 系统概览(Architecture)
- 3.2 文件系统结构(`ctU`)
- 3.3 内核子系统(`ctK`)
- 3.4 文件系统操作
- 3.5 其他优化
- 3.6 文件系统保护
- 4. 评估(Evaluation)
- 4.1 微基准测试
- 4.1.1 追加写
- 4.1.2 其他负载
- 4.1.3 大页优化分析
- 4.2 真实应用
- 4.3 资源开销测试
- 4.4 可拓展性
- 5. 总结
导读:
- CtFS最为核心的地方是利用持久化内存NVM的内存特性,构建了基于连续虚拟地址空间的NVM文件系统,从而可以通过硬件MMU快速索引。CtFS通过构建全局持久化页表(Persistent Page Table,PPT)来完成虚拟空间到NVM地址的映射。相比SCMFS,CtFS通过对虚拟空间进行精细化分以及
pswap()技术保证文件的大小动态缩减(这是SCMFS所未提及的问题)。- CtFS的动机是发现现有的文件系统索引开销较大,因此使用硬件MMU加速索引可以基本避免索引的软件开销。这个Idea看起来在重庆大学提出的SIMFS中也是类似的思想。但相比于SIMFS,CtFS需要将PPT的部分拷贝到DRAM中,而SIMFS为每个文件部署Page Table,并且可以直接嵌入到进程Page Table中访问。但令人奇怪的是,CtFS并没有与SIMFS做对比,可能没有调研到SIMFS文件系统。
- 总之,设计基于虚拟地址空间访问的NVM文件系统是个人看来比较有吸引力的工作,这既能够发挥NVM的存储性能,又能很好地利用NVM的内存特性。后续对NVM的研究中可以时常思考这一点。
1. 背景(Background)
1.1 NVM
以下内容为个人评述
商用NVM,Optane DCPMM宣布停产,这对于学术界或者工业界都不算一个好消息。NVM的研究是否还能继续?很多人开溜,又要去追CXL(CXL是一种新型互联标准,似乎可以为高速设备提供内存访问接口)。个人认为无论是CXL还是NVM其本意都是将存储器的大容量与内存的便捷高效访问结合起来。因此,在NVM上的研究可能可以迁移到基于CXL协议的设备上。其二,虽然Intel的Optane DCPMM停产,但是嵌入式领域还有大量NVM设备,例如:NOR Flash,这个设备支持字节级寻址,同时支持持久性保存。因此,对NVM的研究仍然是有意义的。后续的研究需要继续充分探索、挖掘NVM的特性。
1.2 NVM文件系统
文章将现有NVM文件系统划分为两个技术点
- 使用DAX:EXT4-DAX、XFS-DAX、PMFS等
- 用户态访问:ZoFS(见这里)、SplitFS(见这里)等
但是本文认为现有的这些文件系统都是基于树型索引,例如,为了将一个文件的offset转换为NVM上的块地址,需要使用软件方法便利查找树型索引,这对于快速PM设备来说会带来较大的开销。
1.3 快速索引方案
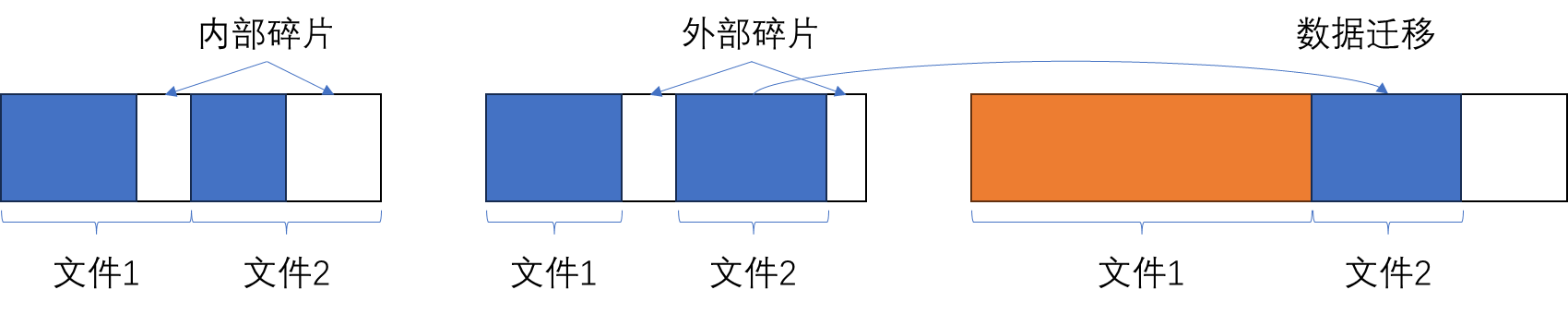
为了避免索引开销,可以使用连续分配的文件系统,即,文件的空间是连续的,知道文件数据的首地址后,做简单的加法就可以找到offset对应的数据块地址。但是,这种方案存在三个挑战:
- 固定文件分配大小会产生内部碎片问题;
- 可变文件分配大小会产生外部碎片问题;
- 为支持连续空间,文件大小变化(尤其是增长)会带来严重的数据迁移问题;
仔细一想,这些问题其实与操作系统内存管理产生的问题一致。示意图如下
现有的解决方案有2种:
- 只读文件系统
- 基于连续虚拟地址的文件系统:SCMFS、SIMFS(原文没有)等。核心是保证虚拟内存的连续性,并通过硬件MMU做虚拟地址到NVM地址的翻译;
然而,CtFS认为现有的基于虚拟内存的方案只考虑了High-Level的设计,缺乏对真实实践的思考,例如:没有详细说明文件是如何分配以及更新的。事实上,SIMFS已经把这些问题考虑得比较清楚了。不过CtFS与SIMFS的解决方案很不同,本文不做赘述。
2. 观察与动机(Observation & Motivation)
CtFS主要针对EXT4-DAX和SplitFS进行观察,也对应于1.2节提到的两种类型的文件系统(DAX和用户态访问)。这里再回顾一下SplitFS,其搭建在EXT4-DAX之上,使用mmap()对NVM空间进行直接访问。具体来说,SplitFS的用户态库维护了一系列2MB的mmap()映射区域,这些映射区域属于一个在EXT4-DAX中创建的文件。为了访问SplitFS中文件的offset,SplitFS首先需要找到该offset在EXT4-DAX中对应文件的offset,然后再由EXT4-DAX通过搜索extent树来获取真实的NVM地址。
测试负载主要选择如下6种:
- Append:向一个空文件中重复追加写4KB数据;
- SWE(Empty):向一个空文件中顺序写入10GB数据。其中,每次利用
pwrite()写入1GB数据; - SW/SR:顺序读写10GB数据,每次I/O量为1GB;
- RR/RW:以4KB对齐方式在一个10GB文件中读写数据,数据读写总量为10GB(即总共2621440次)
测试结果如下:
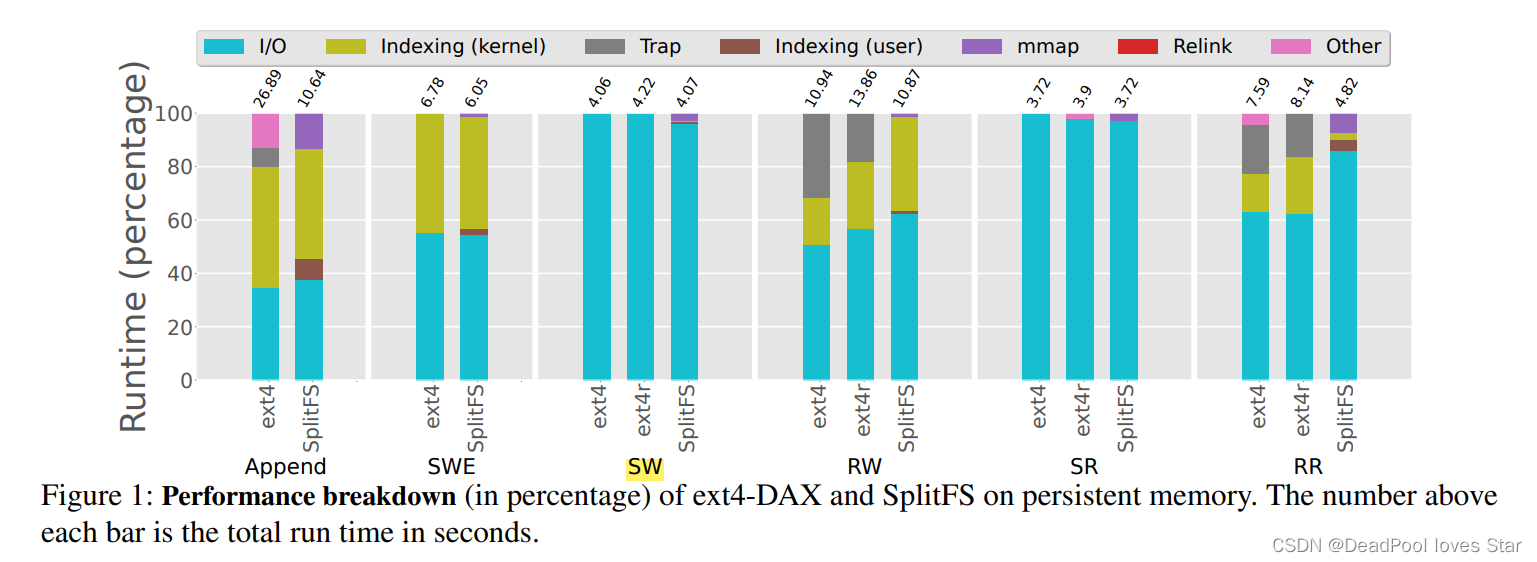
其中,ext4和ext4r分别对应于在连续分配和随机分配的文件上跑测试。连续分配的文件类似SWE。随机分配的文件以稀疏文件方式给出。二者最大区别在于extent的深度。连续分配的文件可以被extent更好地表示,随机分配的则需要更多的extent才能表示。例如,对于一个10GB的文件,连续分配只需要12个extents,而随机分配则需要256个extents。
可以看出来,ext4的内核部分索引时间占据较大,尤其是在Append、SWE、RW、RR负载下,主要因为这些负载IO次数较多,会造成较多extent树访问。SplitFS底层基于ext4索引,因此相应的负载也占据较大的内核索引延迟。
由此,CtFS进一步观察到索引带来的开销,构成了本文使用硬件MMU索引的动机。
3. CtFS设计与实现(Design & Implementation)
3.1 系统概览(Architecture)
CtFS是一个用户态文件系统,其在用户态访问元数据和数据。文件或目录被分配在连续虚拟内存空间中。相较于传统文件系统的从offset到NVM块地址索引,CtFS将该过程移交给MMU完成。具体而言,CtFS有如下4点设计目标:
- POSIX兼容性:CtFS用户态文件系统基本需要通过提供POSIX兼容接口为应用使用;
- 同步写入:CtFS保证写操作都是同步的,即
fsync()在CtFS中没有啥作用; - 崩溃一致性:CtFS使用
Redo Log和pswap()(个人觉得比较类似COW)保证元数据和数据一致性。 - 并发操作:使用读写锁保证并发操作;
与NOVA与SplitFS类似,CtFS同样提供sync模式与strict模式,前者不保证数据一致性,而后者保证数据一致性。下图显示了CtFS的基本架构。其中,Partition代表各文件占据的虚拟内存空间。
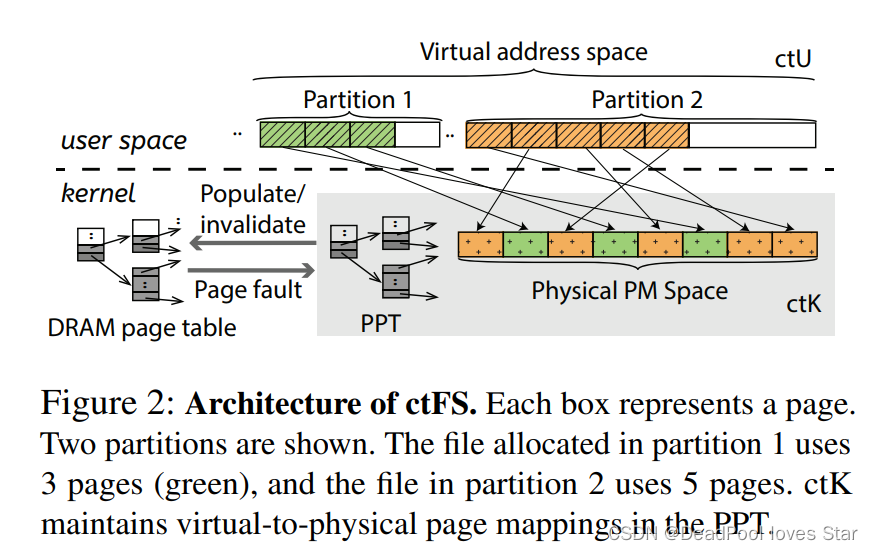
主要由用户态库ctU和内核子系统ctK构成。前者提供文件系统基本语义,后者提供虚拟内存相关实现。ctU在虚拟内存空间中管理文件系统结构,ctK提供虚拟地址到NVM物理地址的映射。映射由存储在NVM上的Persistent Page Table(PPT)完成。当ctU发生page fault时,ctK就会查询PPT并将对应映射插入内核页表中。当PPT中的映射无效后,ctK就会从内核页表中移除相应映射,并刷下相应的TLB项。
3.2 文件系统结构(ctU)
ctU主要用于管理连续的虚拟地址空间。它采用一种类似伙伴分配器的方式进行空间的管理。如下图所示。ctU将虚拟地址空间划分为L0-L910个大小层级。L0是以4KB为单位的Partition,L9是以512GB为单位的Partition。每个层级之间大小相差8倍(而非伙伴分配器的2倍),从个人角度来看,这样的设计对文件系统使用更友好。
-
文件管理:CtFS总是分配比文件大小更大的
Partition即可,例如,为1KB的文件分配4KB的Partition(L0层级),这样子每个文件都拥有连续的虚拟地址空间; -
文件系统布局:下图显示了CtFS在虚拟空间中的布局结构。CtFS将1TB的连续虚拟地址空间划分为两个
L9的Partition,第一个Partition被用于存储文件系统元数据,例如:超级块、索引节点(Inode)等。Inode中存放着该文件数据对应的虚拟地址起始地址。第二个Partition则被用于存放文件系统的数据存储。每个
Partition有三种状态,分别是:已分配(Allocated,A)、已划分(Partitioned,P)以及空(Empty,E)。为文件分配的Partition被标记为A。被标记为P的Partition被划分为8个下一层级Partition。例如,图中,一个L9的Partition被分成了8个L8的Partition,并且第1、3个L8的Partition仍然处于划分状态P,这意味着这两个L8的Partition将被继续划分为2$\times$8个L7的Partition。以此类推。
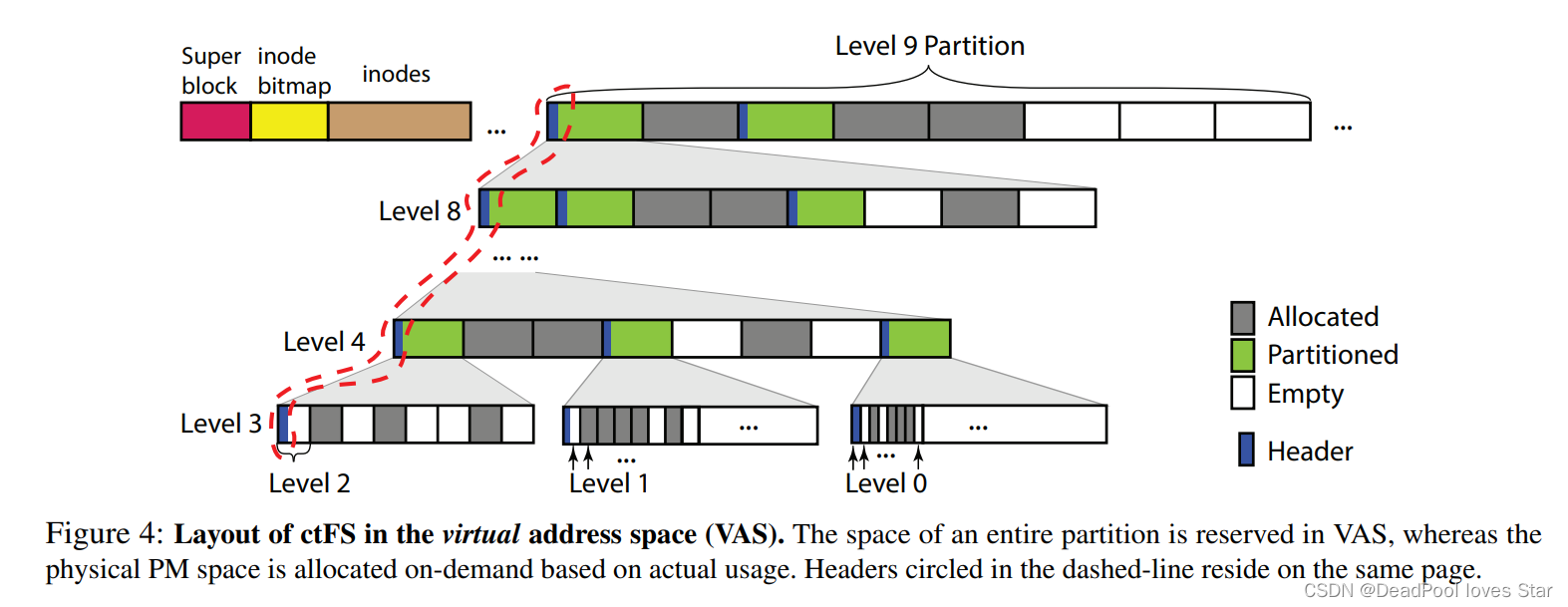
作者进一步总结了这种层级架构的性质:
- 对于任何
Partition,其父亲Partition必须处于被划分的P状态(容易理解) - 对于任何
Partition中的地址,其父亲Partition也含有该地址(因为是父亲划分下来的) - 只要
L9的Partition能够与512GB对齐,则任何子Partition的起始地址都可以与Partition的大小对齐
- 对于任何
-
Partition头(Header):每个
P状态的Partition都需要一个头结构来记录元数据信息,例如Partition的状态。ctU将头结构存储在每个Partition对应的第一个4KB页面。ctU使用2个比特来表示Partition的三个状态。为了加速Partition分配,头结构会含有一个空闲等级字段记录最高的有空闲Partition的层级。例如,上图中L9 Partition的空闲等级为8,因为其子Partition(即L8)有至少一个空闲Partition(共三个L8空闲Partition);L8 Partition的空闲等级为7,因为其子Partition(即L7)有2个空闲的Partition。据此,如果需要分配一个等级为LN的Partition,ctU就会避免查找空闲等级小于N的且状态为P的Partition。因为
ctU将头结构放在每个P Partition对应的第一个页面。因此,第一个页面永远不能为A状态,因为第一个被划分出来的Partition应该继续被划分以为文件分配空间。换句话说,含有头结构的Partition的所有第一个子Partition将一直处于P状态直到无法划分为止(L0-L3被定义为不可再分)。ctU将每个层级的头结构都存储在同一个页面中。L3 Partition的空间可以被分成512个L0 Partition、64个L1 Partition以及8个L2 Partiton,这些子Partition空间通过位图结构管理。这一部分总觉得作者写作太差,读起来非常费劲,第一个NVM页面与第一个子
Partition纠缠不清,头结构的存储方式图中看起来是共用一个头结构,文章却说圈起来的头结构都在同一个页面……看了他们的Presentation,才稍微搞清楚一点:每个层级的头结构其实是分开的,一起构成一个大的头,如下图所示
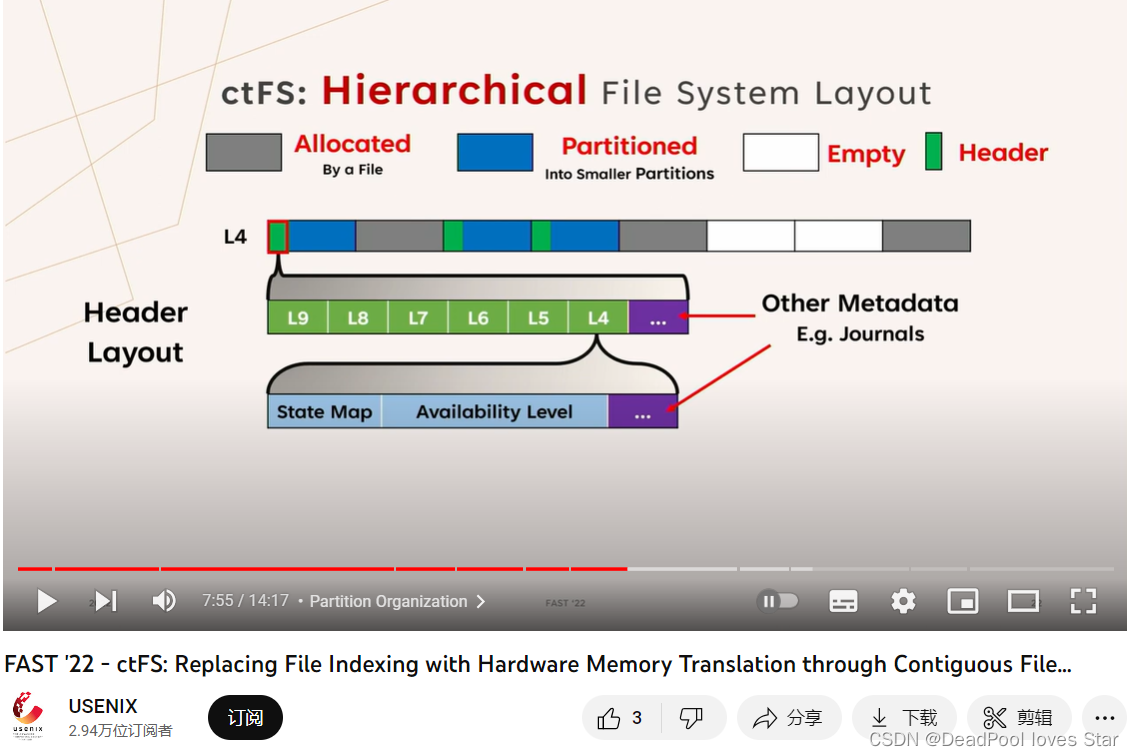
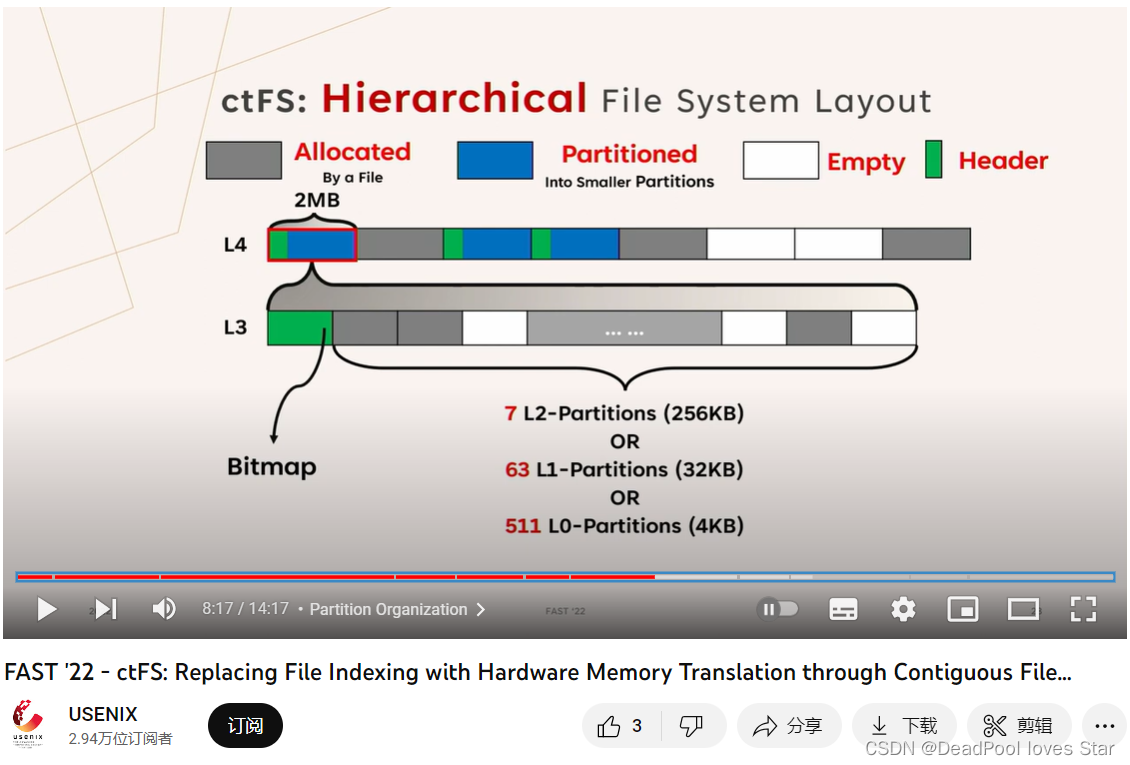
用更通俗的语言来说:被划分的Partition会有一个头结构,由于第一个子Partition和这个被划分的Partition的起始地址相同,因此第一个子Partition也有这个相同的头结构,因此也处于被划分的状态,这导致所有第一个子Partition都被划分直到不可划分为止。为了记录不同划分层级的空闲等级,这个头结构需要包含所有划分等级的元数据信息,如上面第一张图所示,L9-L4的信息被存在一个类似数组的地方。这个头结构使用一个4KB的NVM页面存储。此外,文章也没有说明位图到底是如何存储的,通过上面第二张图可以看出,位图似乎是被嵌入到了头结构中。 -
虚拟地址空间分配:初始化时,
ctU会申请1TB的虚拟内存区域(用于提供两个L9 Partition)。这里需要说明的是进程地址空间不会与ctU使用的虚拟地址空间产生冲突,这是Linux Kernel保证的。 -
TLB使用:对于CtFS来说,通过
ctK的映射保证能够从虚拟地址访问NVM的物理地址,此时会消耗TLB Entry。因此,相较于其他文件系统,CtFS不会产生更多的TLB使用。分析如下:- 非DAX文件系统:文件数据被缓存在内存Buffer中。与CtFS类似,这些缓存Buffer在内存中的数据会占据TLB项,数量取决于访问的数据量;
- 对于DAX文件系统:NVM的地址空间同样被映射到内核页表中,因此,对NVM的直接访问同样会占据TLB Entry,因此,CtFS也不会占据更多的TLB Entry;
3.3 内核子系统(ctK)
这一节作者主要介绍两个部分。其一是Persistent Page Table(PPT),其二是pswap()技术。
PPT与传统的Linux四级页表类似,但PPT被持久化在NVM设备上,且其虚拟地址到物理地址的映射都采用的相对地址。这是因为:① 由于地址空间随机化导致ctU起始虚拟地址不同;② 由于硬件配置不同NVM的起始物理地址可能不同。这里需要说明的是ctK仅有一个PPT,但是每个进程都有一个各自的页表,因此,ctK只能将PPT中的映射关系拷贝到页表中。
pswap()是CtFS提出的一种针对页表的快速交换技术,个人感觉类似SplitFS搞的relink()那一套,不过pswap()的通用性更强,因为他针对持久化页表做出了新的设计。pswap()的功能是原子地交换PPT中两段相同大小的虚拟地址空间。举个例子,页表A指向一段物理地址看空间A,页表B指向物理地址空间B,pswap()后,页表A指向物理地址空间B,页表B指向物理地址空间A。在pswap()过程中,ctK会无效化原来页表A和页表B在进程页表中的映射,并且刷下相应的TLB Entry。因为这样比直接更新映射更高效。pswap()利用Redo Log保证了崩溃一致性,且支持并发操作(只要操作的空间不交叠,否则串行执行。ctK使用二叉搜索树记录将要执行的pswap())。
为了避免pswap()进行过多页表项交换,CtFS定义了swap-aligned,这里不赘述swap-aligned的含义。只需了解拥有swap-aligned性质的页表可以大大减少页表项的交换,如下图所示。这里只需通过修改4个页表项(一个PUD项、一个PMD项以及两个PTE项)即可完成pswap()。图中红蓝项即是被交换的项。其实,完全可以把页表想象成数据索引,pswap()就是对索引进行交换。
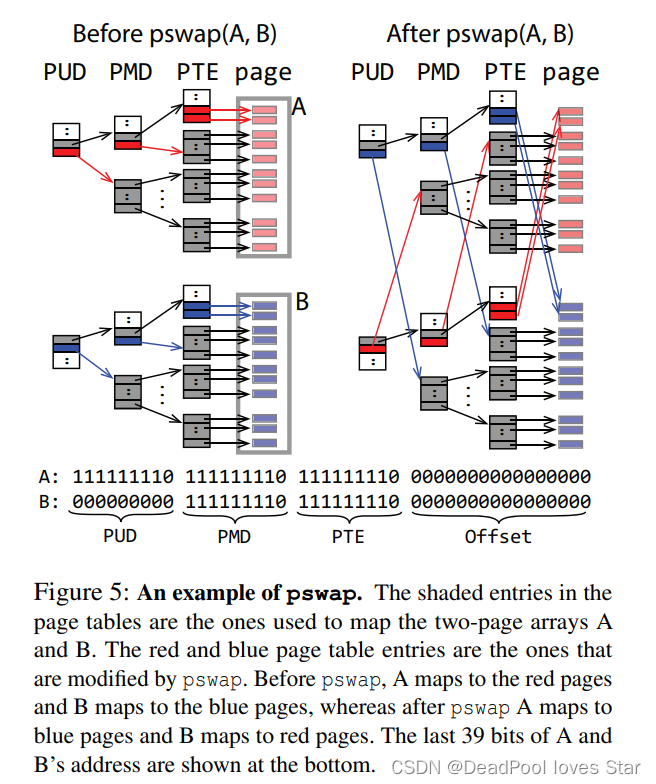
作者将由memcpy()实现的pswap()(没有说得太清楚,应该是使用Log直接交换物理空间的数据,造成二次数据拷贝)与ctK使用的pswap()做对比,可以发现pswap()有较大的优势。

3.4 文件系统操作
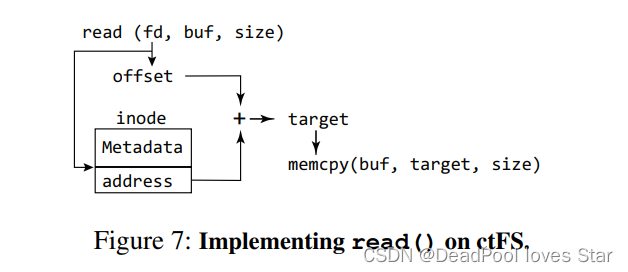
由于文件所占用空间是连续的虚拟地址空间,因此文件系统的读操作就变得非常简单,如下图所示,只需要根据offset计算虚拟地址,然后调用memcpy()将数据从NVM上拷贝数据至buf即可。
对于写操作,CtFS会先为单次写分配一个足够大的Partition,当文件大小增长超过该Partition时,CtFS会升级该Partition。升级的过程实际上就是虚拟地址空间迁移的过程,这时映射的物理数据理应保持不动。这里回顾一下,CtFS支持sync和strict模式,前者不保证数据一致性,后者保证。Partition的升级和数据一致性的保证都需要依赖psawp()进行,下面介绍二者:
-
Partition升级:当某次写入超过当前文件分配的
Partition P0时,CtFS会首先分配一个更大的Partition P1,然后调用pswap(P0, P1)完成虚拟地址空间的交换。Partition降级原理和升级类似; -
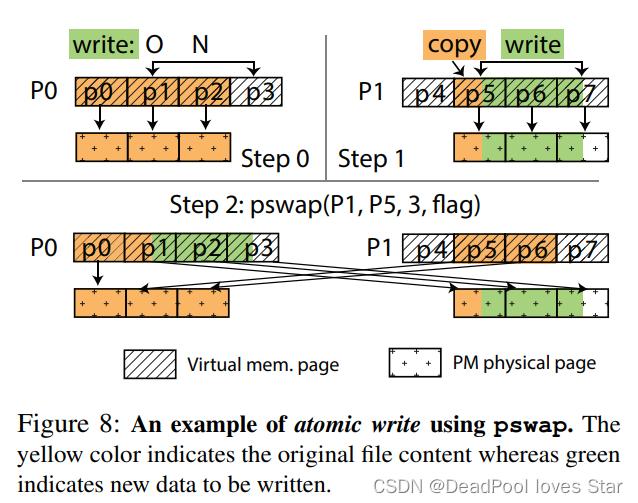
数据一致性:这里主要讨论的是数据覆盖写的情况。CtFS采用一种写后交换策略如下图Step 0所示,要从偏移为
O的地方写N个字节,N横跨了三个页面。由此,见Step 1,CtFS分配一个与P0等大的Partition P1,然后拷贝页面p1中未被覆盖的部分,并写入待写的部分。接着,CtFS对虚拟地址空间p1-p3与p5-p7做交换,交换完成后,见Step 2,P0对应的数据就是覆盖写之后的数据了。
3.5 其他优化
- 大页优化:
ctK会尽可能分配大页。这使得L3或L3往上的Partition都能够使用大页。然而,如果pswap()需要交换的空间非常小,那么大页就会先被拆解为4KB页面,这额外增加了pswap()的开销。CtFS默认启用大页优化。 - 追加写优化:在
strict模式下,CtFS避免写后交换的操作,而直接追加写数据,然后更新文件大小。 - 数据I/O优化:作者发现AVX512 NT 512-bit load/store (VMOVDQU和MOVNTDQ)性能最佳。
3.6 文件系统保护
这里需要说明的是,ctU的地址空间被嵌入在进程中,需要防止进程恶意修改文件系统空间。为此,CtFS使用Intel MPK进行用户态防护。即,ctK将所有NVM页面都标记为使用同一个MPK(CtFS称之为NONE)。每当ctU进行文件操作时,ctU将NONE MPK的权限设置为可读写,当完成操作后修改为不可访问。对于不同进程而言,由于MPK在每个核上都有,因此允许某些进程访问CtFS的页面,某些不能,从而起到保护隔离作用。
关于Intel MPK,可以参考[论文分享] Intra-Unikernel Isolation with Intel Memory Protection Keys (mstmoonshine.github.io),核心思想是将内存页面分组并给予权限。
这种保护措施无法避免恶意程序通过修改MPK来破坏文件系统。作者认为这使得CtFS的通用性受限,但可以部署在Data Center场景。
4. 评估(Evaluation)
4.1 微基准测试
4.1.1 追加写
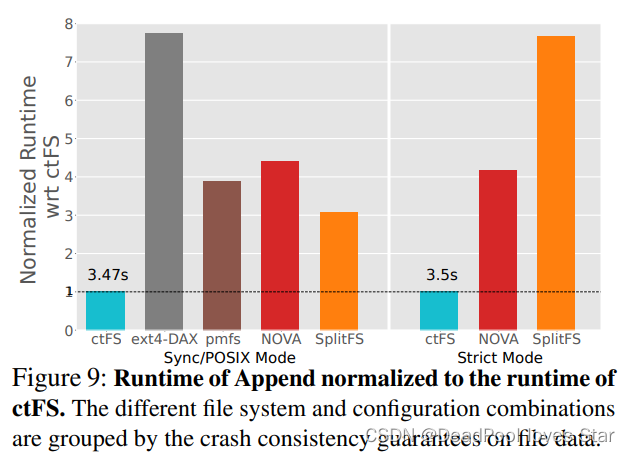
得益于MMU索引,CtFS在Append负载下大大超过其他文件系统,甚至超过基于Memory-Mapped的SplitFS。这是因为SplitFS还是受制于底层文件系统的索引开销。
4.1.2 其他负载
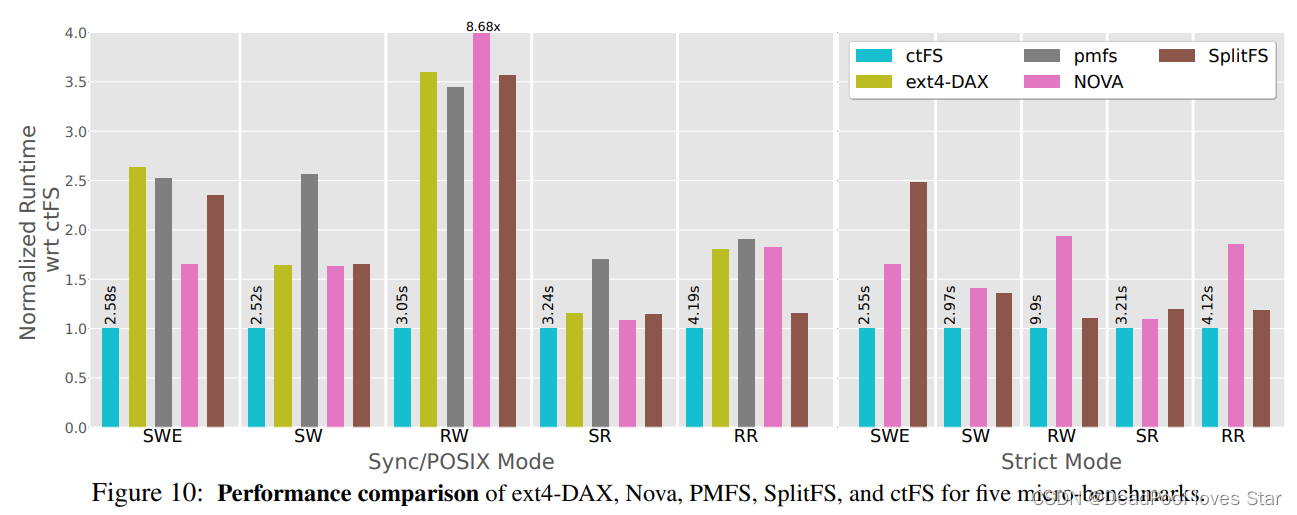
可以看到CtFS总是最优的,无论在sync模式下还是在strict模式下
4.1.3 大页优化分析
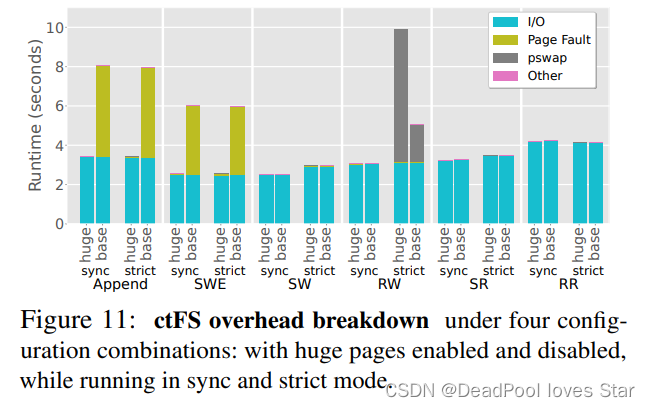
这里对CtFS的大页优化进行了对比。实验结果表明大页优化在Append和SWE负载下能够很好地减少Page Fault耗时,因为节省了PPT拷贝开销和页面分配开销(注意,这两个负载面向的都是空文件,而SW、RW、SR、RR面向的都是已经存在的文件,因此没有缺页)。
在strict模式的RW下,会触发大量pswap()。相比于使用基本页面,大页优化需要将页面拆分,因此耗时更长。
4.2 真实应用
主要在Level DB和Rocks DB上测试
- Level DB
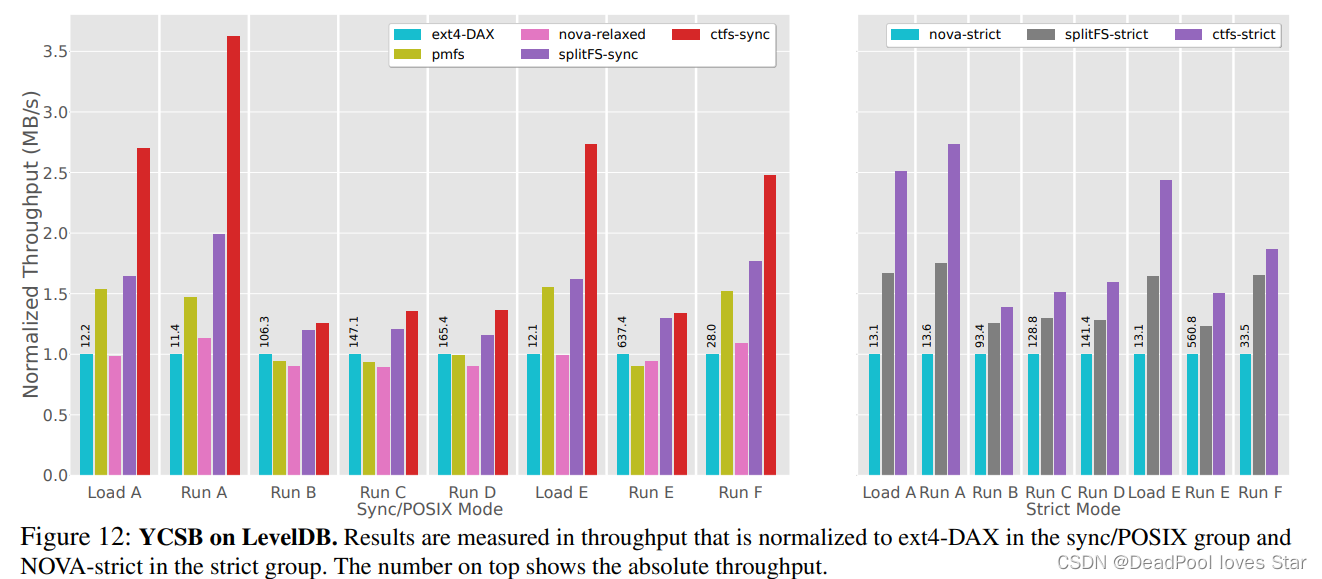
CtFS在Level DB上跑YCSB的结果非常不错。
-
Rocks DB
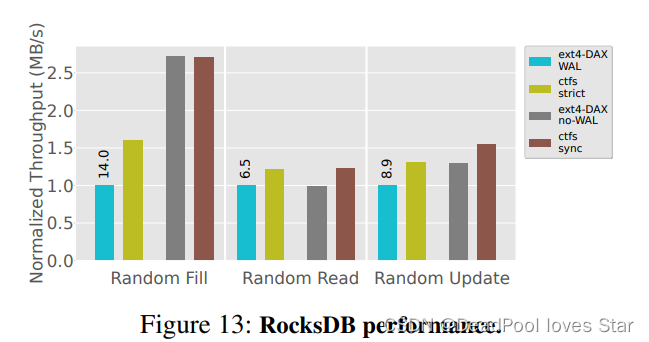
非常不错。
4.3 资源开销测试
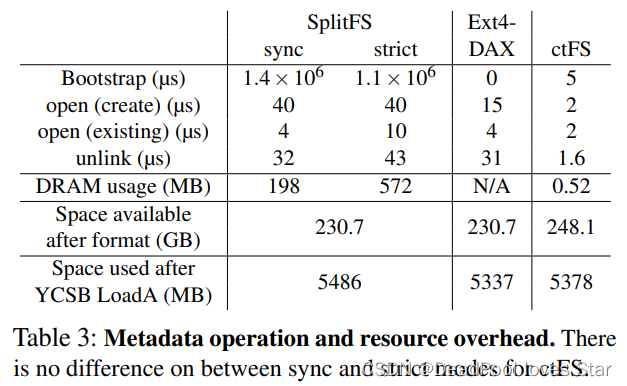
系统格式化后,CtFS的内存占用十分少。表格表明CtFS的各种操作(open()、unlink())时间较少,或许与其目录实现相关,需要研究代码才能清楚。
此外,CtFS在系统格式化后占用空间更少。元数据开销(跑完YCSB LoadA后的空间占用)与EXT4-DAX相似。
4.4 可拓展性
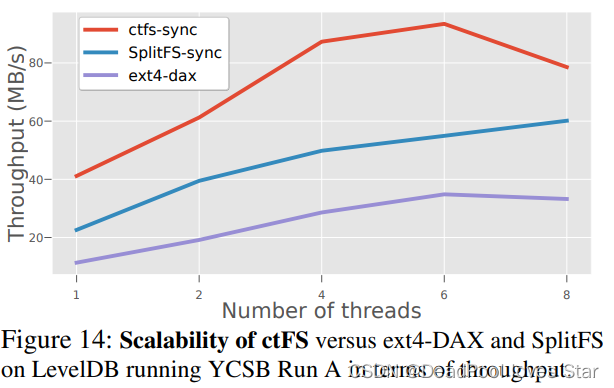
作者在8核机器上进行测试,测试表明峰值出现在线程数为6的时候。性能下降的原因应该与傲腾NVM的特性相关。OdinFS利用一些异步机制解决了这个问题,有时间可以研读一下:ODINFS: Scaling PM Performance with Opportunistic Delegation | USENIX
5. 总结
本文聚焦于索引开销问题,利用连续虚拟地址空间将索引开销offload至硬件MMU,从而大大减少索引开销。然而,如何分配虚拟地址空间以管理文件仍是一个待解决的挑战(虽然A New Design of In-Memory File System Based on File Virtual Address Framework | IEEE Journals & Magazine | IEEE Xplore好像已经解决了,而且看起来更高效),本文通过类似伙伴分配器的方法高效管理虚拟地址空间,并使用PPT完成页表映射。基于PPT,提出pswap()方法实现一致性操作以及文件大小增减操作。文章从问题、动机到解决方案、挑战到评估测试整套流程工整完整,值得学习。
需要说明的是虽然本文思路简单,然而实现起来并不简单。需要对操作系统内核、进程页表、大页映射等非常熟悉。相比SIMFS而言,该工作更优秀的地方在于其已经开源:robinlee09201/ctFS (github.com)。由于NVM的特性所致,未来NVM的技术发展必定和DRAM、Storage相融合,因此,该工作通过页表来高效访问NVM对于NVM研究者来说具有较高的参考价值。