文章目录
- 正则表达式
- 一.正则表达式
- 1.含义
- 2.通配符
- 2.1通配符含义作用
- 2.2常见的通配符
- 3.元字符(字符匹配)
- 4.表示次数
- 5.位置锚定
- 6.分组或其他
- 二.扩展正则表达式
- 1.表示次数
- 2.举例
正则表达式
一.正则表达式
1.含义
(1)是一种特殊字符及文本字符所编写的模式,针对文本文件的内容
(2)主要用来匹配字符串(命令结果,文本内容)
2.通配符
2.1通配符含义作用
通配符只用于匹配文件名、目录名等,不能用于匹配文件内容。(而且是已存在的文件或者目录)
2.2常见的通配符
(1)*:通配符,匹配任意一个或多个字符
ls *.txt

(2)?:通配符,只能匹配任意一个字符
ls ?.txt

(3)[ ] 通配符,匹配list中任意单个字符
ls [a-z].txt

3.元字符(字符匹配)
| 常用元字符 |
|---|
| . 匹配任意单个字符,可以是一个汉字 |
| () 使用转义符,只表示() |
| [] 匹配指定范围内的任意单个字符 |
| [^] 匹配指定范围外的任意单个字符(取反) |
| [[:space:]]:匹配空格 |
示例:
ls /opt/ | grep "[^A-Z]"——————————不要大写字符的文本内容
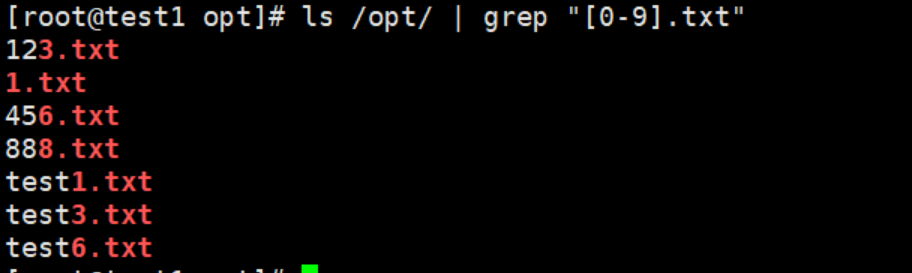
ls /opt/ | grep "[0-9].txt"—————————取含有0-9字符的txt文件名
ls /opt/ | grep "[a-zA-Z]"——————————匹配大小写英文字符
ls /opt/ | grep "[a-z0-9]"——————————同时匹配字符和数字
ls /opt/ | grep "[zj]"——————————————匹配zj任意的两个字符
4.表示次数
| 常用的表示 |
|---|
| * #匹配前面的字符任意次,包括0次,贪婪模式:尽可能长的匹配 |
| .* #任意长度的任意字符,不包括0次,也就是匹配所有 |
| ? #匹配其前面的字符出现0次或1次,即:可有可无 |
| + #匹配其前面的字符出现最少1次,即:肯定有且 >=1 次 |
| {n} #匹配前面的字符=n次 |
| {m,n} #匹配前面的字符至少m次,至多n次 |
| {,n} #匹配前面的字符至多n次,<=n |
| {n,} #匹配前面的字符至少n次 |
示例:
echo google | grep 'go\{2\}gle'———————代表前面的o连续出现2次
echo gooooooogle | grep 'go\{2,\}gle'———————代表前面的o出现2次以上
echo goooogle | grep 'go\{2,5\}gle'——————代表前面的o出现2次以上5次以下
echo golgole | grep “\(go\)\{1\}”————————不连续的go

ifconfig ens33 | grep -o "[0-9]\+\.[0-9]\+\.[0-9]\+\.[0-9]\+"————————————匹配IP地址过滤出所有结果

echo 54456567@qq.com | grep "[0-9]\+@qq\.[a-z]\+"————匹配邮箱号

5.位置锚定
| 常用 |
|---|
| ^ #行首错定,用于模式的最左侧 |
| $ #行尾错定,用于模式的最右侧 |
| ^root$ #用于模式匹配整行 (单独一行 只有root ) |
| ~$ #空行 |
| 1*$ #空白行 |
\<或 \b #词首错定,用于单词模式的左侧(连续的数字,字母,下划线都算单词内部)
\>或\b #词尾错定,用于单词模式的石侧
\<root\> #匹配敷个单词
cat /etc/fstab | grep -v "#" |grep -v "^$"————过滤出文字不包含#号行的

单词模式
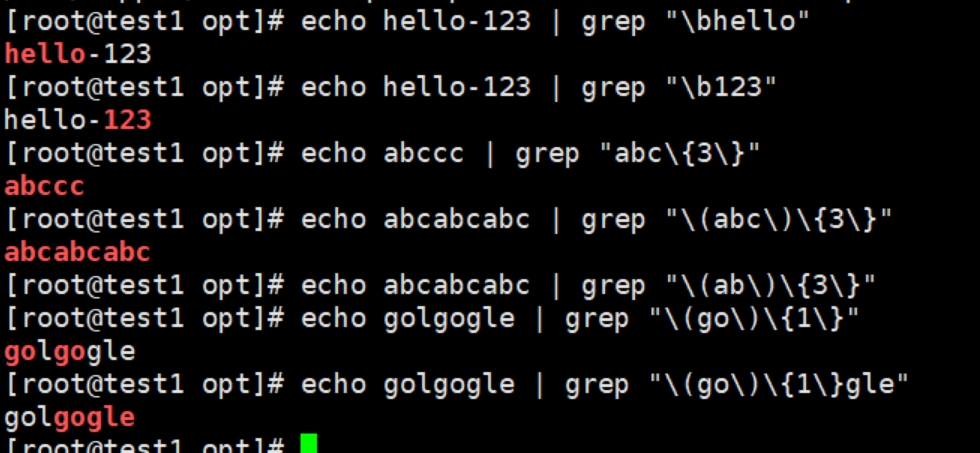
echo hello-123 | grep "\bhello"
echo hello-123 | grep "\b123"

6.分组或其他
分组:()将多个字符捆绑在一起,当作一个整体处理
或者:\|
echo hello-123 | grep "\bhello"
echo hello-123 | grep "\b123"
echo abccc | grep "abc\{3\}"
echo abcabcabc | grep "\(abc\)\{3\}"
echo golgogle | grep "\(go\)\{1\}"
echo golgogle | grep "\(go\)\{1\}gle"
二.扩展正则表达式
grep -E或者egrep
1.表示次数
| 字符 |
|---|
| * #匹配前面字符任意次 |
| ? #0或1次 |
| + #1次或多次 |
| {n} # 匹配n次 |
| {m,n} #至少m,至多n次 |
| {,n} #匹配前面的字符至多n次,<=n,n可以为0 |
| {n , } #匹配前面的字符至少n次,<-n,n可以为0 |
2.举例
将ifconfig ens33 的地址显示出来
ifconfig ens33 | grep -E -o "[0-9]+\.[0-9]+\.[0-9]+\.[0-9]+"

将文本中的的区号展示出来
cat 888.txt | grep -E "[0-9]{,4}-[0-9]{,8}"

将电话号码展示(11位)
cat dhhm.txt | grep -E "[0-9]{,11}"

将不同的地址展示
cat kz.txt | grep -E "[0-9a-zA-Z]+@[0-9a-z]+\.[a-z]{,3}"
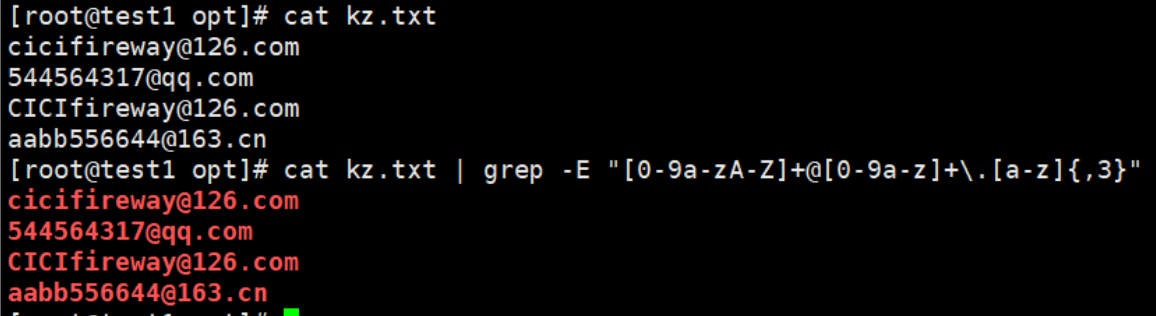
不同类型的区号展示
cat lz.txt | grep -E "(\([0-9]+\)|[0-9]+)[ -]?[0-9]+[ -]?[0-9]+"

[:space:] ↩︎