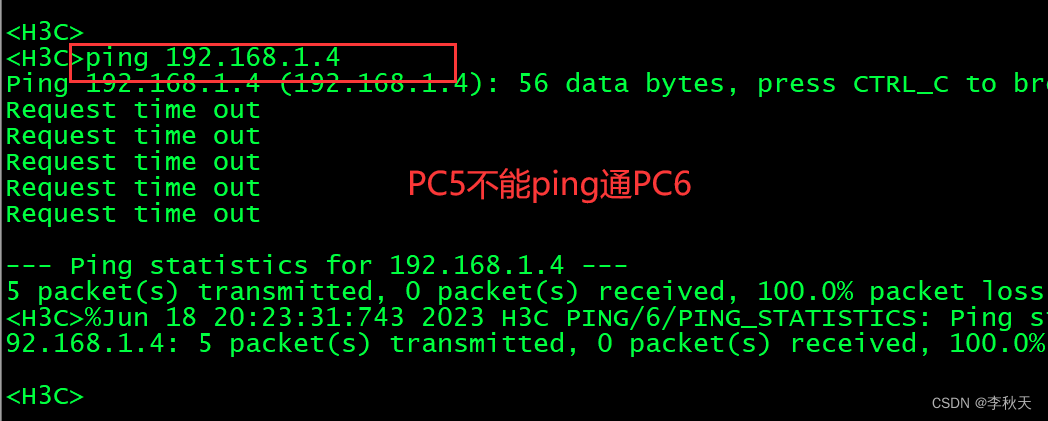
第5章 Redis的相关配置(redis.conf)
1)计量单位说明,大小写不敏感
# 1k => 1000 bytes
# 1kb => 1024 bytes
# 1m => 1000000 bytes
# 1mb => 1024*1024 bytes
# 1g => 1000000000 bytes
# 1gb => 1024*1024*1024 bytes
#
# units are case insensitive so 1GB 1Gb 1gB are all the same.
2)bind
默认情况bind=127.0.0.1只能接受本机的访问请求
不写的情况下,无限制接受任何ip地址的访问,产环境肯定要写你应用服务器的地址
如果开启了protected-mode,那么在没有设定bind ip且没有设密码的情况下,Redis只允许接受本机的请求
#bind 127.0.0.1
protected-mode no
3)port 服务端口号
port 6379
4)daemonize
是否为后台进程
daemonize yes
5)pidfile
存放pid文件的位置,每个实例会产生一个不同的pid文件
pidfile /var/run/redis_6379.pid
6)log file
日志文件存储位置
logfile “”
7)database
设定库的数量 默认16
databases 16
8)requirepass
设置密码
requirepass 123456
127.0.0.1:6379> set k1 v1
(error) NOAUTH Authentication required.
127.0.0.1:6379> auth "123456"
OK
127.0.0.1:6379> set k1 v1
OK
127.0.0.1:6379> get k1
"v1"
9)maxmemory
设置Redis可以使用的内存量。一 旦到达内存使用上限,Redis将会试图移除内部数据,移除规则可以通过maxmemory-policy来指定。如果Redis无法根据移除规则来移除内存中的数据,或者设置了“不允许移除”,
那么Redis则会针对那些需要申请内存的指令返回错误信息,比如SET、LPUSH等。
# maxmemory <bytes>
10)maxmemory-policy
移除策略
# maxmemory-policy noeviction
#volatile-lru:使用LRU算法移除key,只对设置了过期时间的键运算
#allkeys-lru:使用LRU算法移除key
#volatile-lfu :使用LFU策略移除key,只对设置了过期时间的键运算.
#allkeys-lfu :使用LFU策略移除key
#volatile-random:在过期集合中移除随机的key,只对设置了过期时间的键运算
#allkeys-random:移除随机的key
#volatile-ttl:移除那些TTL值最小的key,即那些最近要过期的key
#noeviction:不进行移除。针对写操作,只是返回错误信息
11)Maxmemory-samples
设置样本数量,LRU算法和最小TTL算法都并非是精确的算法,而是估算值,所以你可以设置样本的大小。一般设置3到7的数字,数值越小样本越不准确,但是性能消耗也越小。
# maxmemory-samples 5
第6章 Jedis
Jedis是Redis的Java客户端,可以通过Java代码的方式操作Redis
6.1 环境准备
1)添加依赖
redis.clients jedis 3.3.0 ## 6.2 基本测试 1)测试连通public class JedisDemo
{
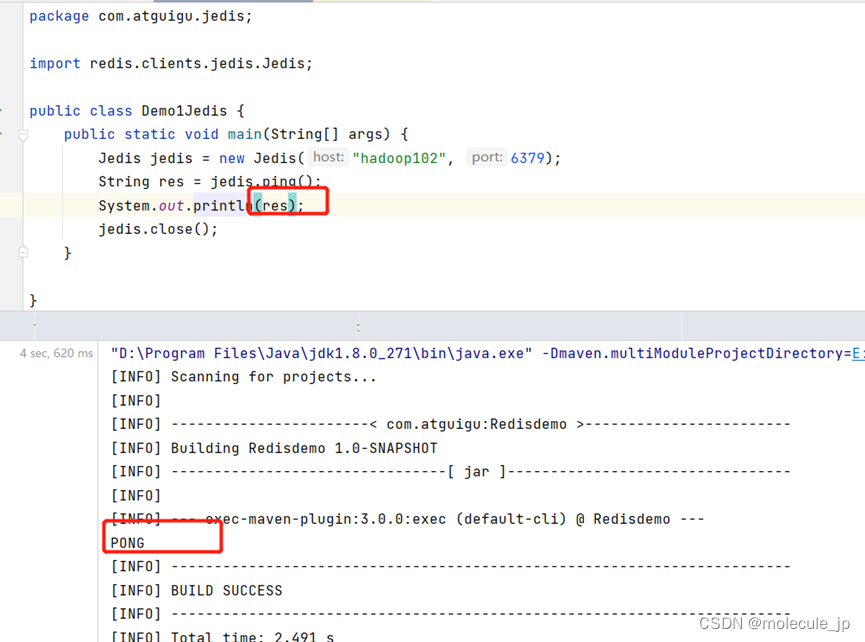
public static void main(String[] args) {
//创建一个客户端对象, 连接服务端
Jedis jedis = new Jedis("hadoop102", 6379);
//向服务端发送命令
String res = jedis.ping();
//如果是读操作,解析返回的结果
System.out.println(res);
//关闭客户端
jedis.close();
}
}
hadoop102开启服务
2)连接池
连接池主要用来节省每次连接redis服务带来的连接消耗,将连接好的实例反复利用
public class JedisPoolDemo
{
public static void main(String[] args) {
//创建一个存放客户端连接的池子
JedisPool jedisPool = new JedisPool("hadoop102", 6379);
//从池子中借一个连接
Jedis jedis = jedisPool.getResource();
//向服务端发送命令
String res = jedis.ping();
//如果是读操作,解析返回的结果
System.out.println(res);
//将连接还回池子
//如果连接是从池中借来的,自动还回池子,如果不是借的,是直接new的,那么就关闭
jedis.close();
}
}
第7章 Redis 持久化
7.1 两种方式
Redis提供了2个不同形式的持久化方式 RDB 和 AOF。
RDB为全量快照备份,会在备份时将内存中的所有数据持久化到磁盘的一个文件中。(适合数据量小,数据量大很消耗资源)
AOF为增量日志备份,会将所有写操作命令不但追加记录在一个日志文件中。
7.2 RDB(Redis Database)
7.2.1 是什么
在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot快照,它恢复时是在Redis服务启动时,将指定位置的快照文件直接读到内存里。
7.2.2 备份配置
RDB备份默认为自动开启,无需手动开启。当不使用时,只需要配置dbfilename后的值为空白即可。
1)RDB保存的文件
在redis.conf中配置文件名称,默认为dump.rdb
dbfilename dump.rdb
2)RDB文件的保存路径
默认为Redis启动时命令行所在的目录下,也可以修改, redis 服务命令在哪个路径下执行的就是保存到哪个路径的!
dir ./
7.2.3 RDB自动保存策略
# save <seconds> <changes>
# Will save the DB if both the given number of seconds and the given
# number of write operations against the DB occurred.
#
# In the example below the behaviour will be to save:
# after 900 sec (15 min) if at least 1 key changed
# after 300 sec (5 min) if at least 10 keys changed
# after 60 sec if at least 10000 keys changed
# Note: you can disable saving completely by commenting out all "save" lines.
save 900 1
save 300 10
save 60 10000
7.2.4 RDB手动保存
(1)save: 在执行时,server端会阻塞客户端的读写。全力备份。
(2)bgsave: 在执行时,server端不阻塞客户端的读写,一边备份一边服务,速度慢。
(3)shutdown时服务会立刻执行备份后再关闭
(4)flushall时会将清空后的数据备份
7.2.5 RDB其他配置
1)进行rdb保存时,将文件压缩
rdbcompression yes
2)文件校验
在存储快照后,还可以让Redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能
rdbchecksum yes
7.2.6 RDB优缺点
1)优点:
相比AOF,节省磁盘空间,恢复速度快。适合容灾恢复(从磁盘到云端恢复数据的一种方式)。
2)缺点:
虽然Redis在fork时使用了写时拷贝技术,但是如果数据庞大时还是比较消耗性能。
在备份周期在一定间隔时间做一次备份,所以如果Redis意外down掉的话,就会丢失最后一次快照后的所有修改。
7.3 AOF(Append Only File)
7.3.1 是什么
以日志(文本文件 不会保存额外的信息)的形式来记录每个写操作,将Redis执行过的所有写指令记录下来(读操作不记录),只许追加文件但不可以改写文件,Redis启动之初会读取该文件重新构建数据,换言之,Redis重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
7.3.2 开启AOF
1)AOF默认不开启,需要手动在配置文件中配置
appendonly yes
2)AOF文件
appendfilename “appendonly.aof”
3)AOF文件保存的位置,与RDB的路径一致
dir RDB的路径
7.3.3 AOF备份策略
# no: don't fsync, just let the OS flush the data when it wants. Faster.
# always: fsync after every write to the append only log. Slow, Safest.
# everysec: fsync only one time every second. Compromise.
appendfsync everysec
7.3.4 AOF文件损坏恢复
redis-check-aof --fix appendonly.aof
7.3.5 Rewrite
AOF采用文件追加方式,文件会越来越大为避免出现此种情况,新增了重写机制,当AOF文件的大小超过所设定的阈值时,Redis就会启动AOF文件的重写,只保留可以恢复数据的最小指令集.可以使用命令bgrewriteaof手动开始重写。
重写虽然可以节约大量磁盘空间,减少恢复时间。但是每次重写还是有一定的负担的,因此设定Redis要满足一定条件才会进行重写。
系统载入时或者上次重写完毕时,Redis会记录此时AOF大小,设为base_size,如果Redis的AOF当前大小>= base_size +base_size*100% (默认)且当前大小>=64mb(默认)的情况下,Redis会对AOF进行重写。
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
7.3.6 AOF的优缺点
1)优点:
(1)备份机制更稳健,丢失数据概率更低。默认只丢1秒的数据,极限情况只丢失最后一次操作的数据。
(2)可读的日志文本,通过操作AOF文件,可以处理误操作。
2)缺点:
(1)比起RDB占用更多的磁盘空间
(2)恢复备份速度要慢
(3)每次写都同步的话,有一定的性能压力
(4)存在个别bug,造成恢复不能
7.4 持久化的优先级
AOF的优先级大于RDB,如果同时开启了AOF和RDB,Redis服务启动时恢复数据以AOF为准.
7.5 RDB和AOF用哪个好
(1)官方推荐两个都启用。
(2)如果对数据不敏感,可以选单独用RDB
(3)不建议单独用 AOF,因为可能会出现Bug。
(4)如果只是做纯内存缓存,可以都不用
看场景:做缓存用,就可以不开启
如果要做数据库用,那么最好的情况都会丢失一条数据,要做数据库,就要允许有这种丢数据的风险!