文章目录
- 李宏毅老师讲Transformer
- Encoder
- Decoder
- Decoder整体逻辑
- non-autoregressive
- Decoder中的Cross Attention
- 训练Seq2seq的一些Tips
老师讲的超级棒,激动哭了:
视频链接:台大李宏毅21年机器学习课程 self-attention和transformer
李宏毅老师讲Transformer
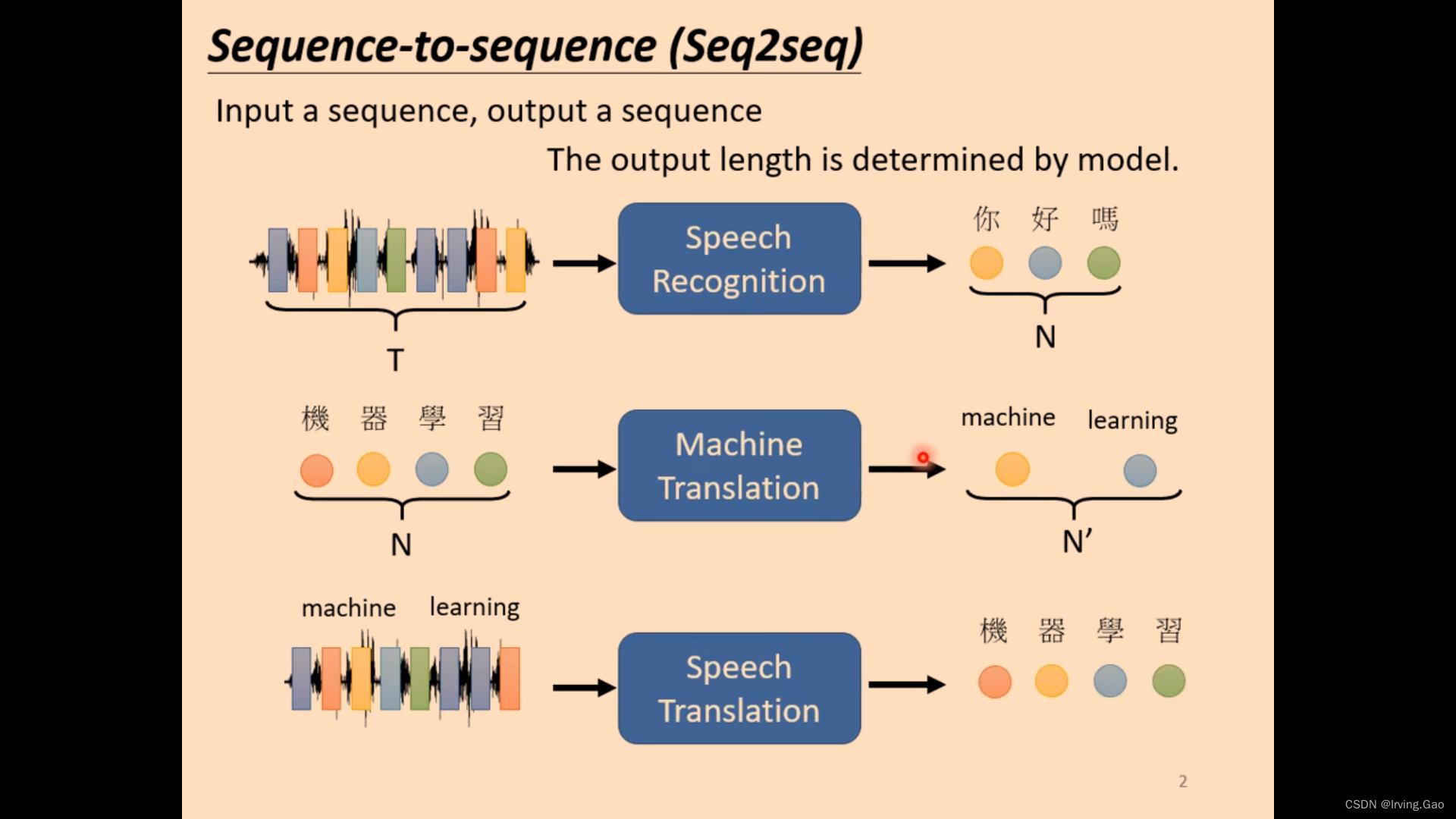
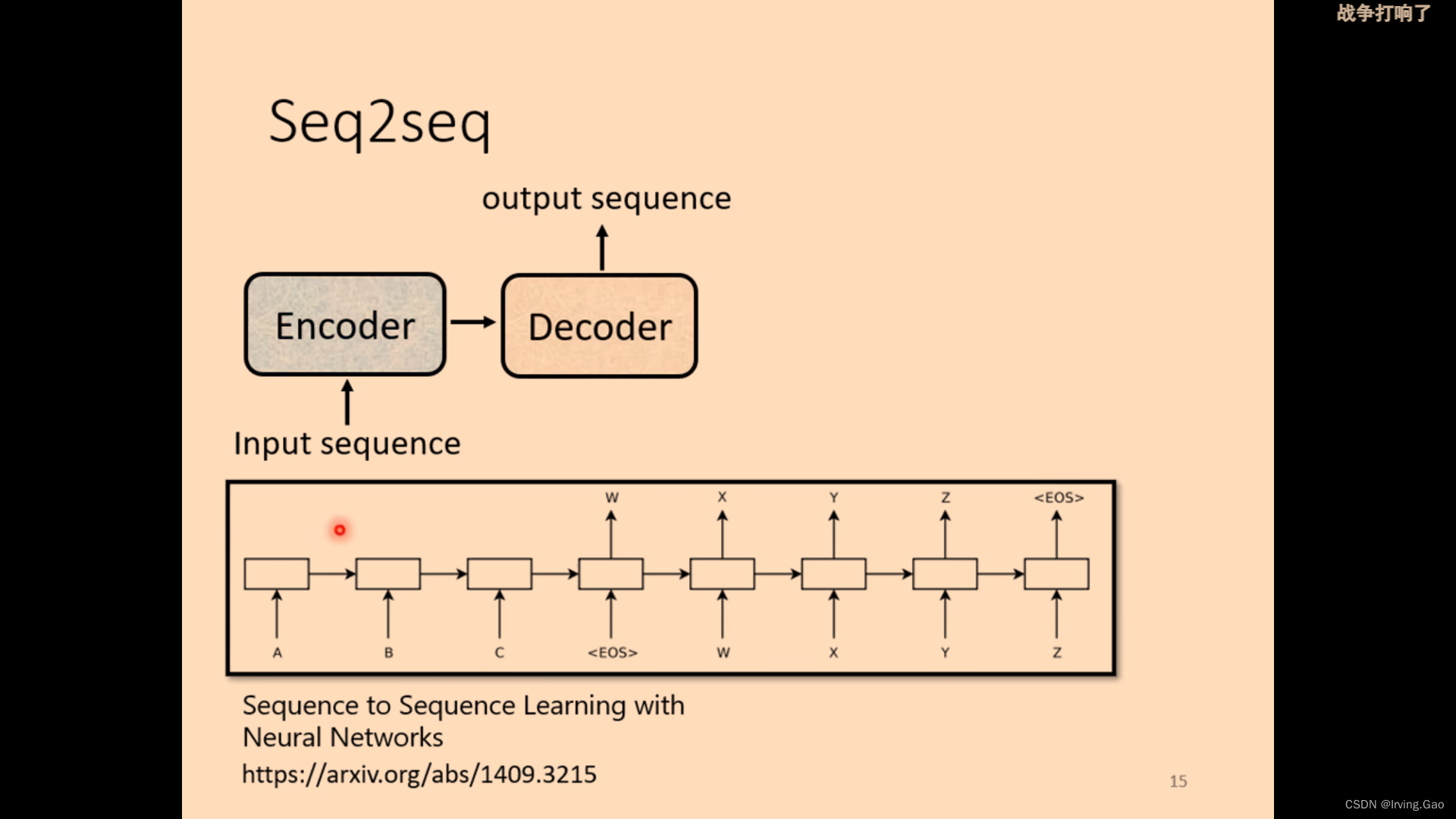
- Transformer本质就是Seq2seq问题:
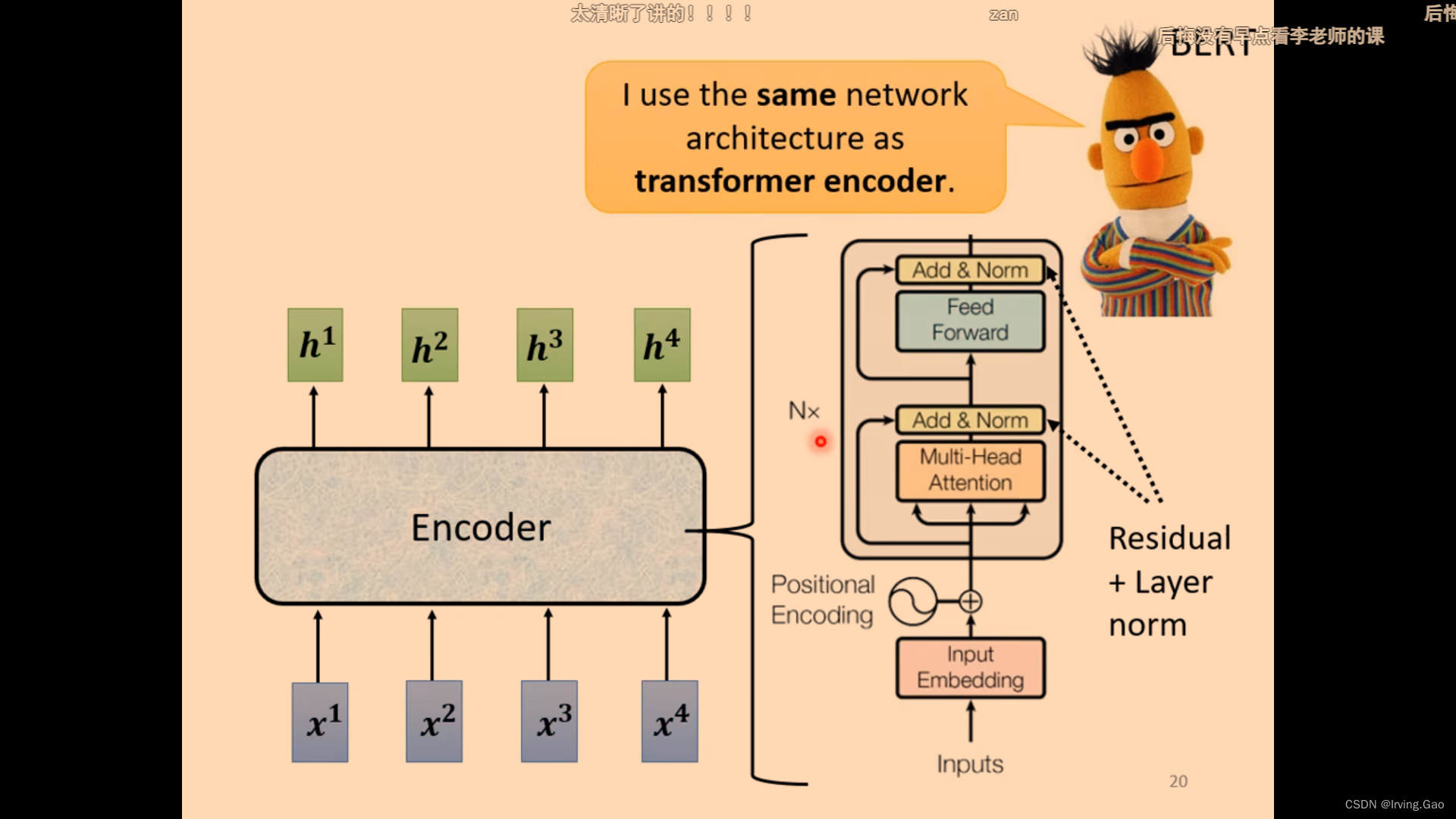
Encoder
- 作用:输入一系列向量,输出同样长度的一系列向量,将向量编码到一种机器空间。
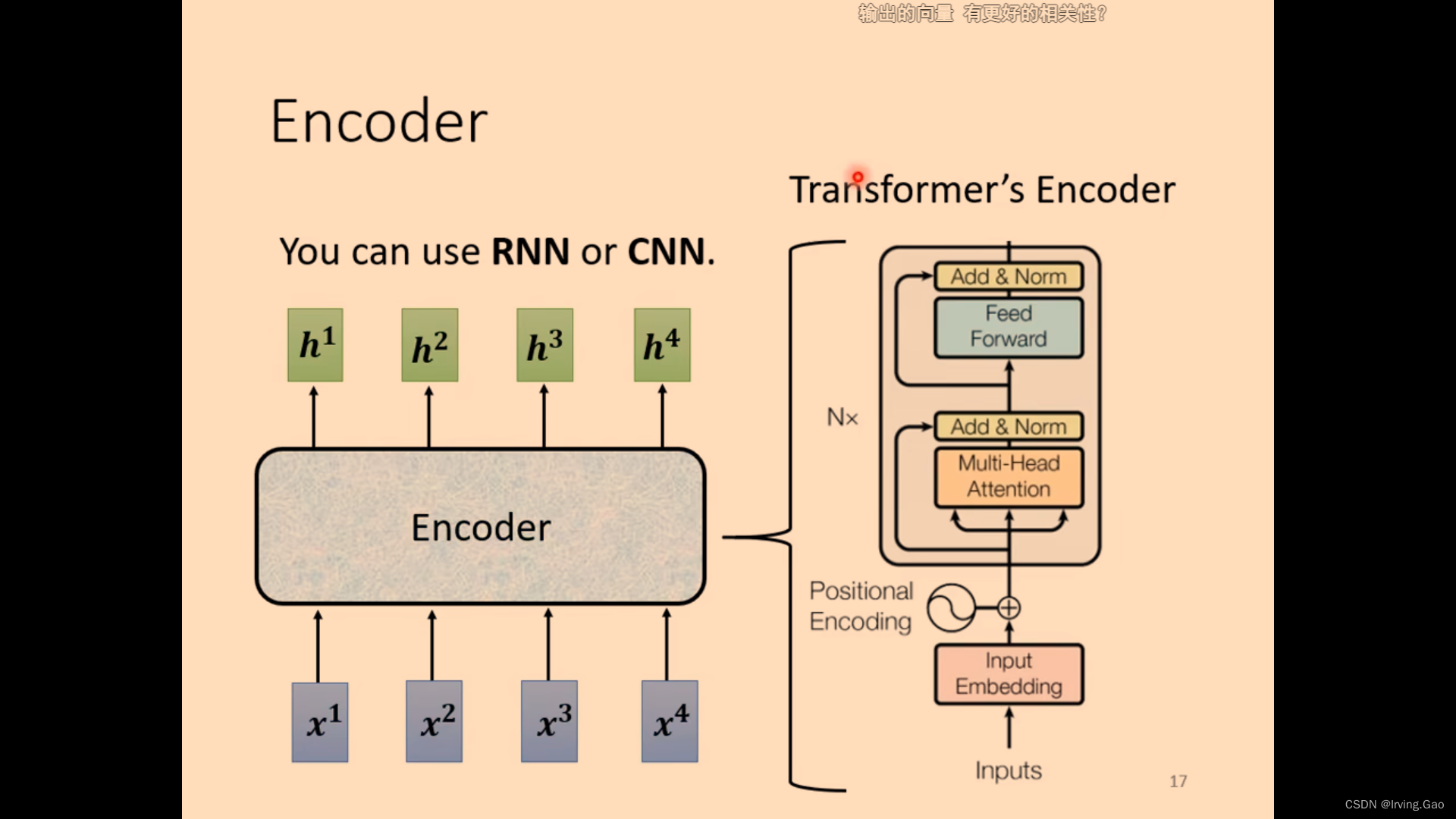
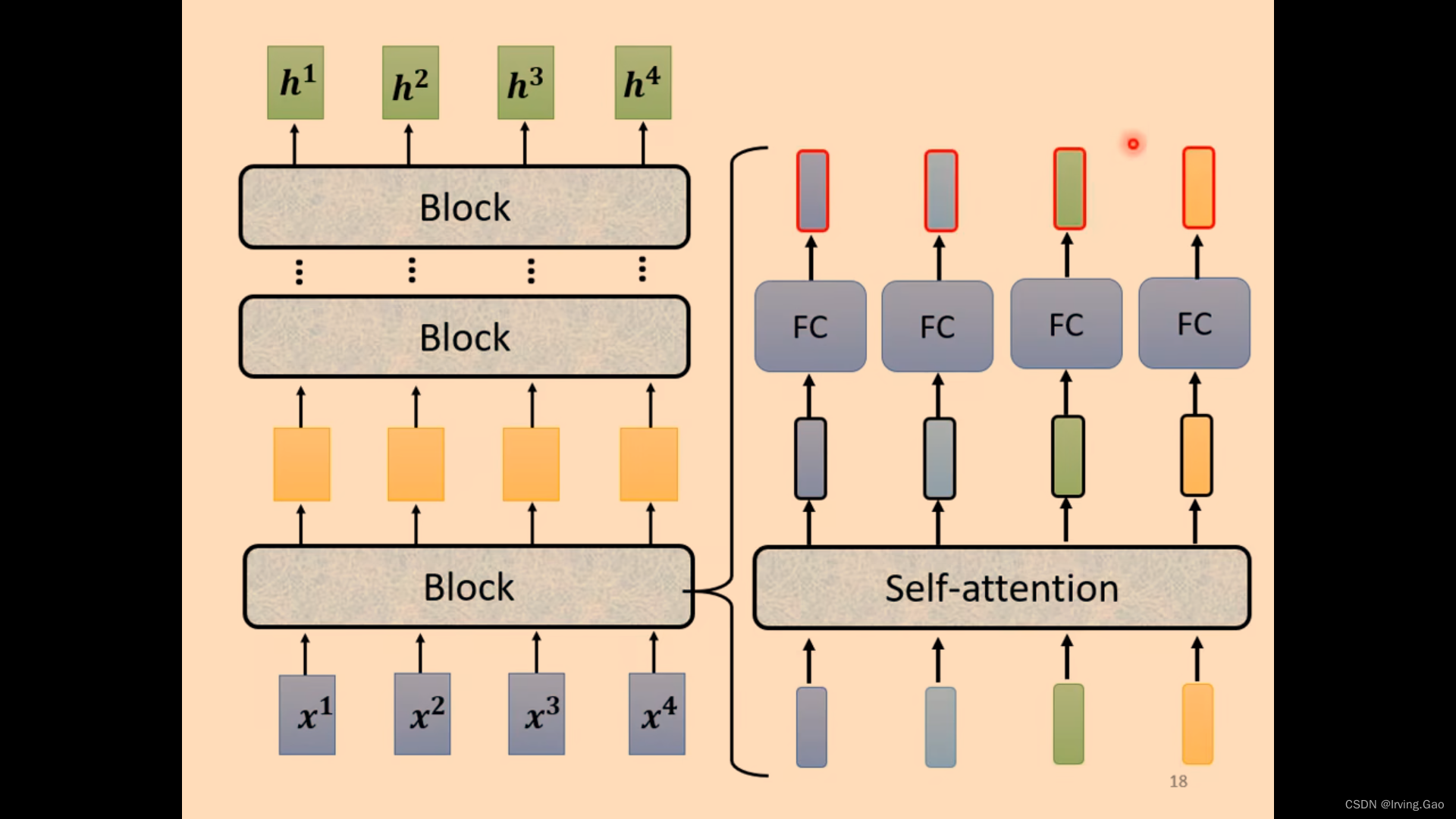
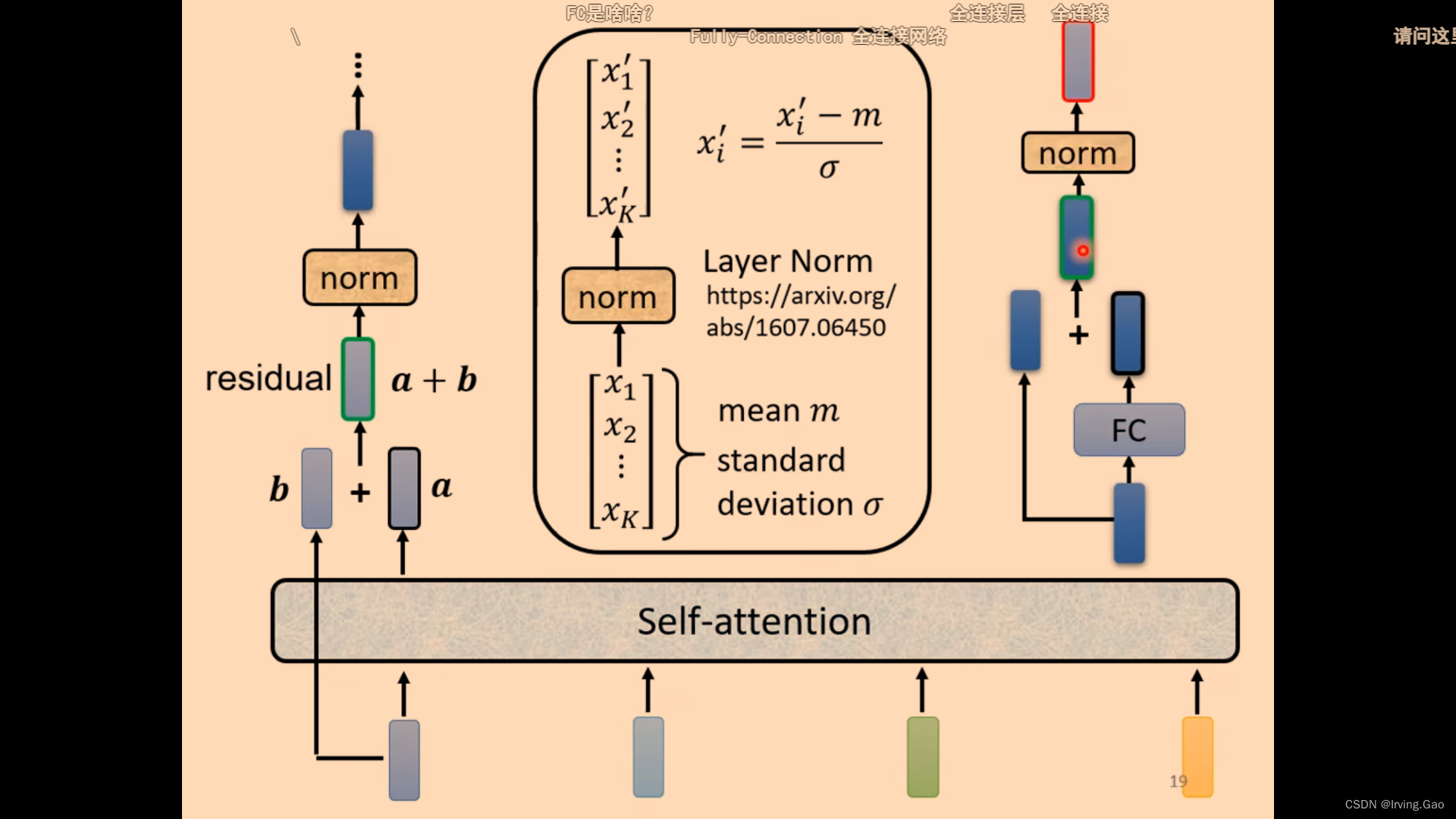
- 每一个模块都是Residual的设计;
- norm:求平均值和标准差,计算归一化。
Decoder
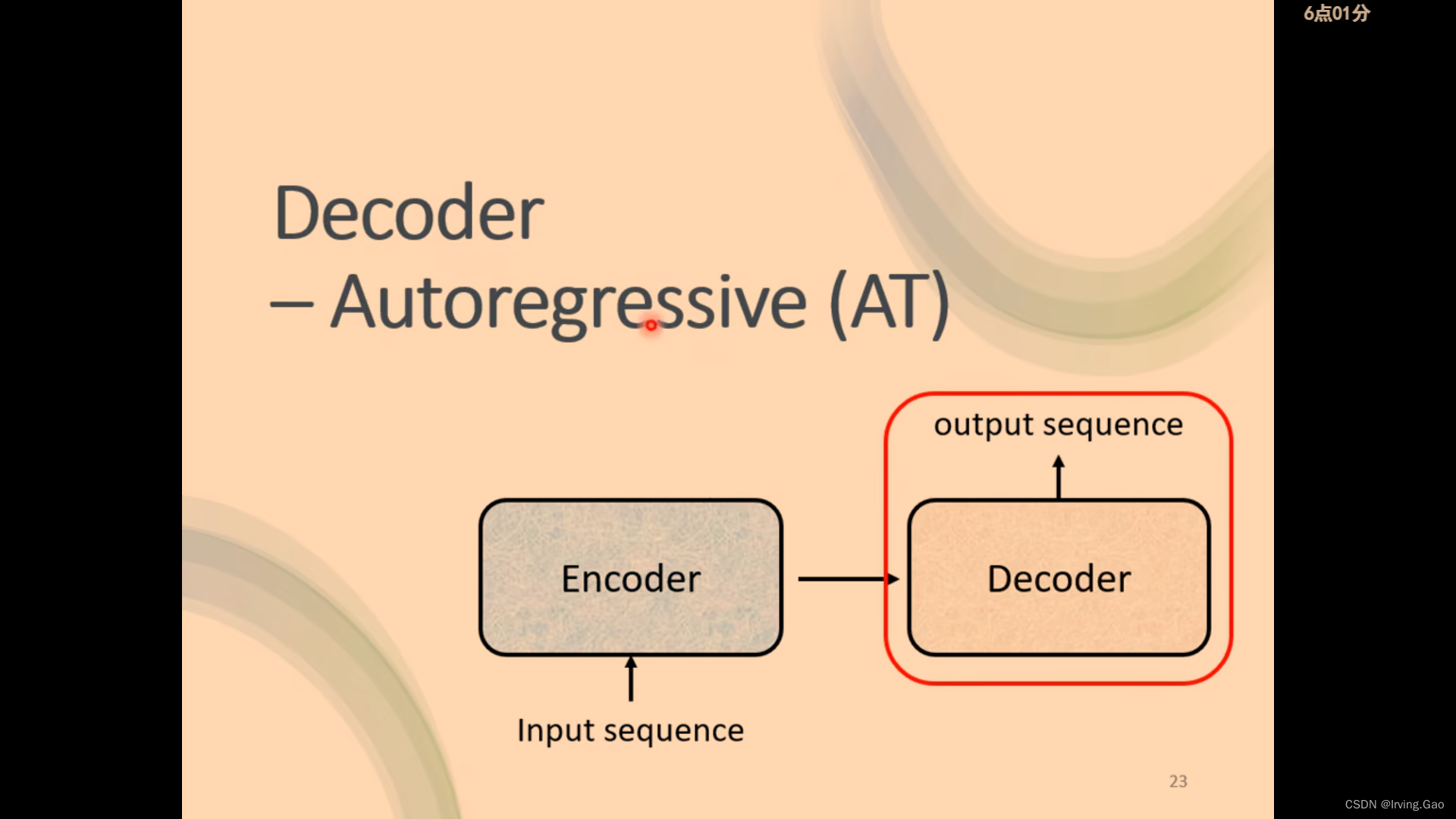
Decoder整体逻辑
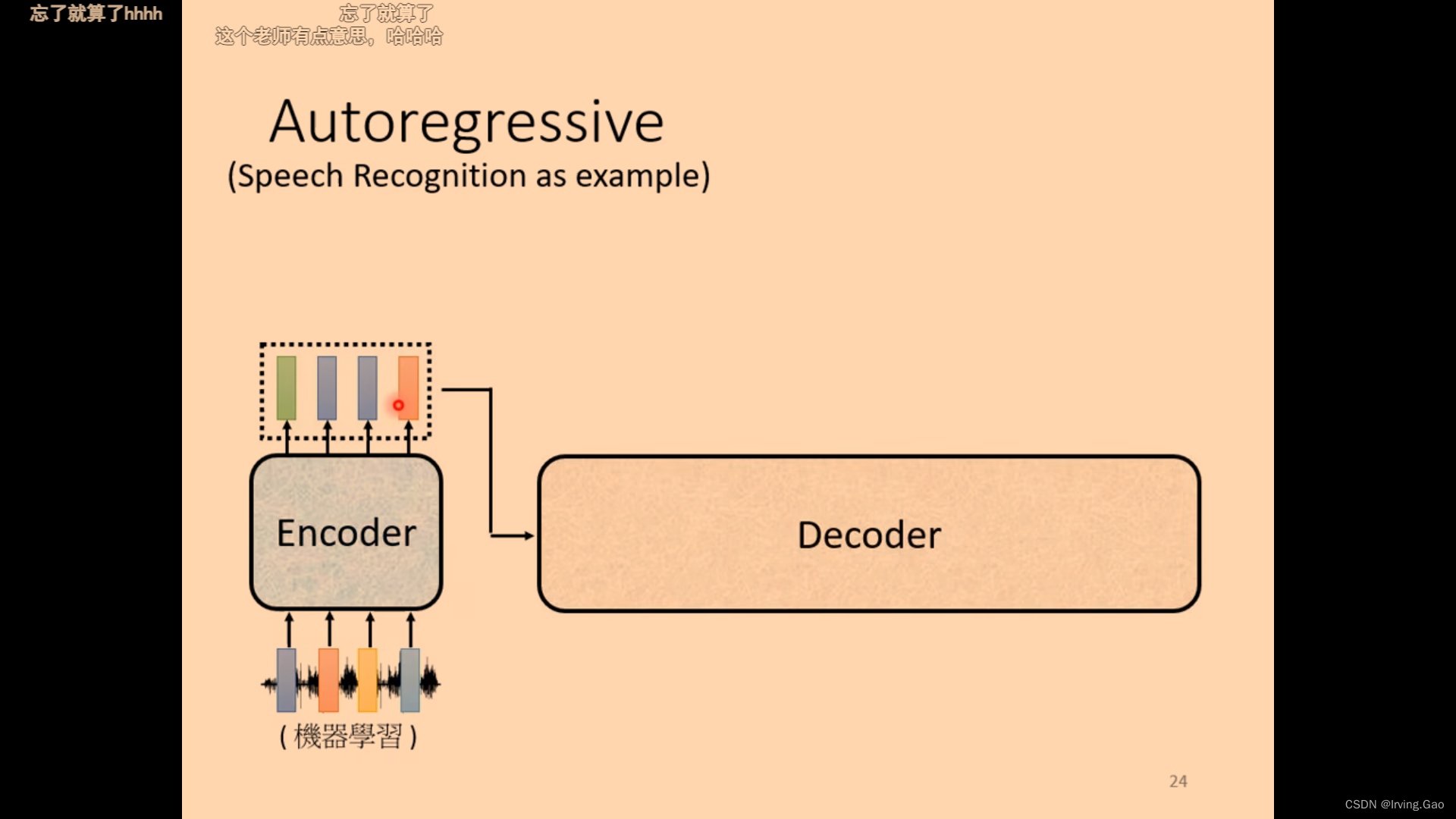
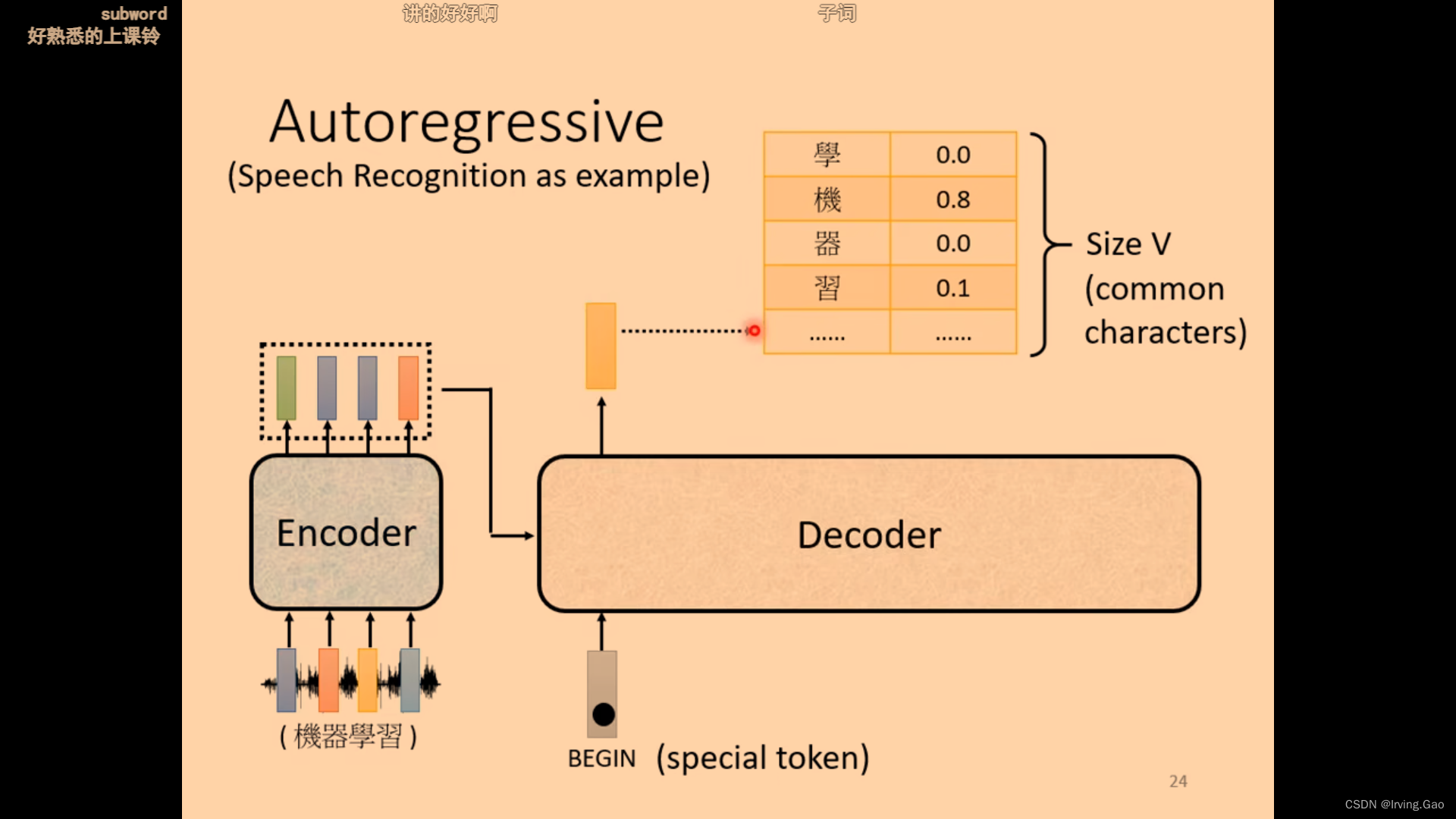
- 有一个初始vector:
BOS,在Decoder可能输出的向量前加一个即可; - 输出的向量vector:是对你所有可能结果(如果是英文翻译中文,则是中文词料库所有词)的softmax后分数最高的对应的vector;
- 然后以此类推。
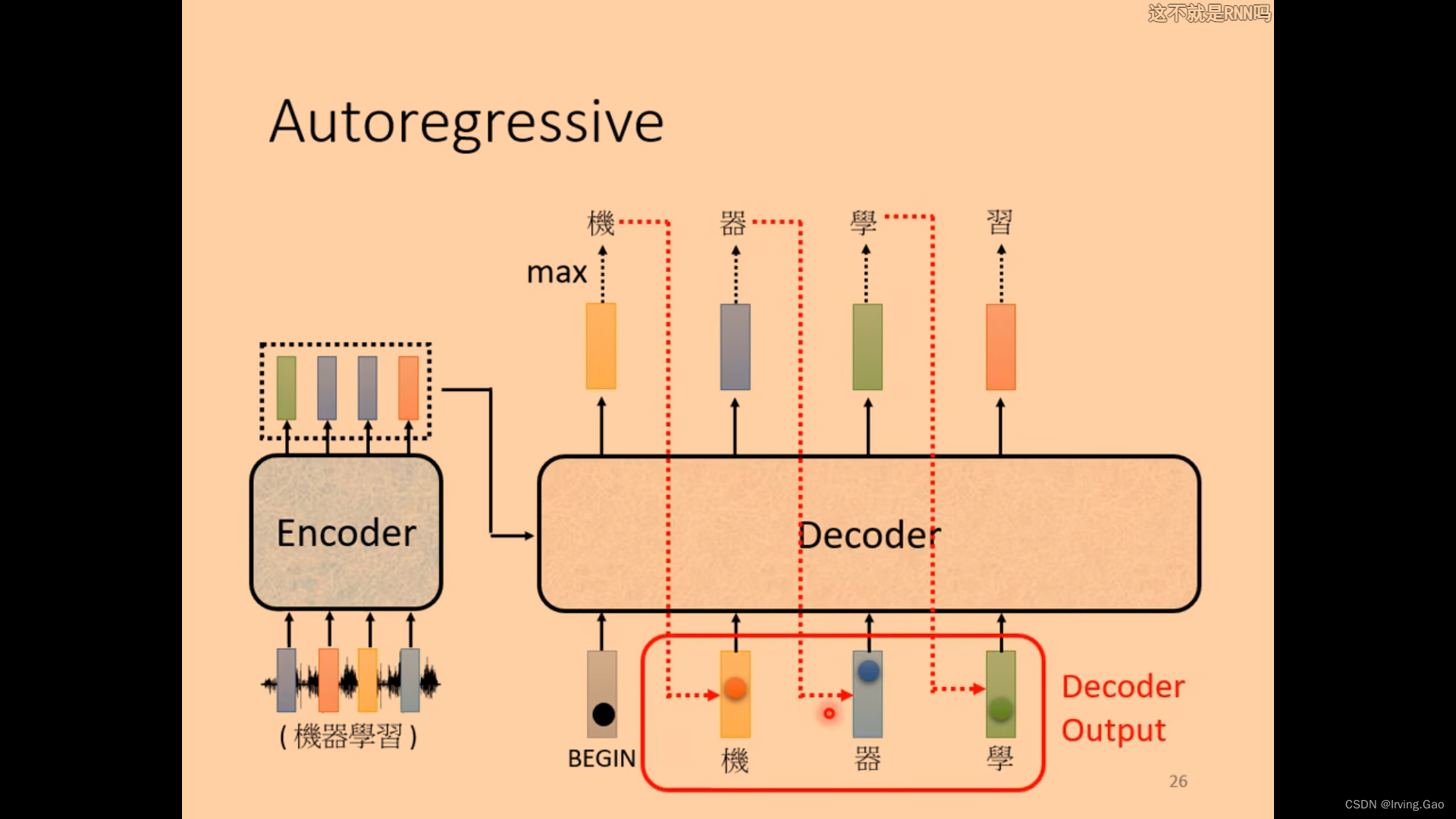
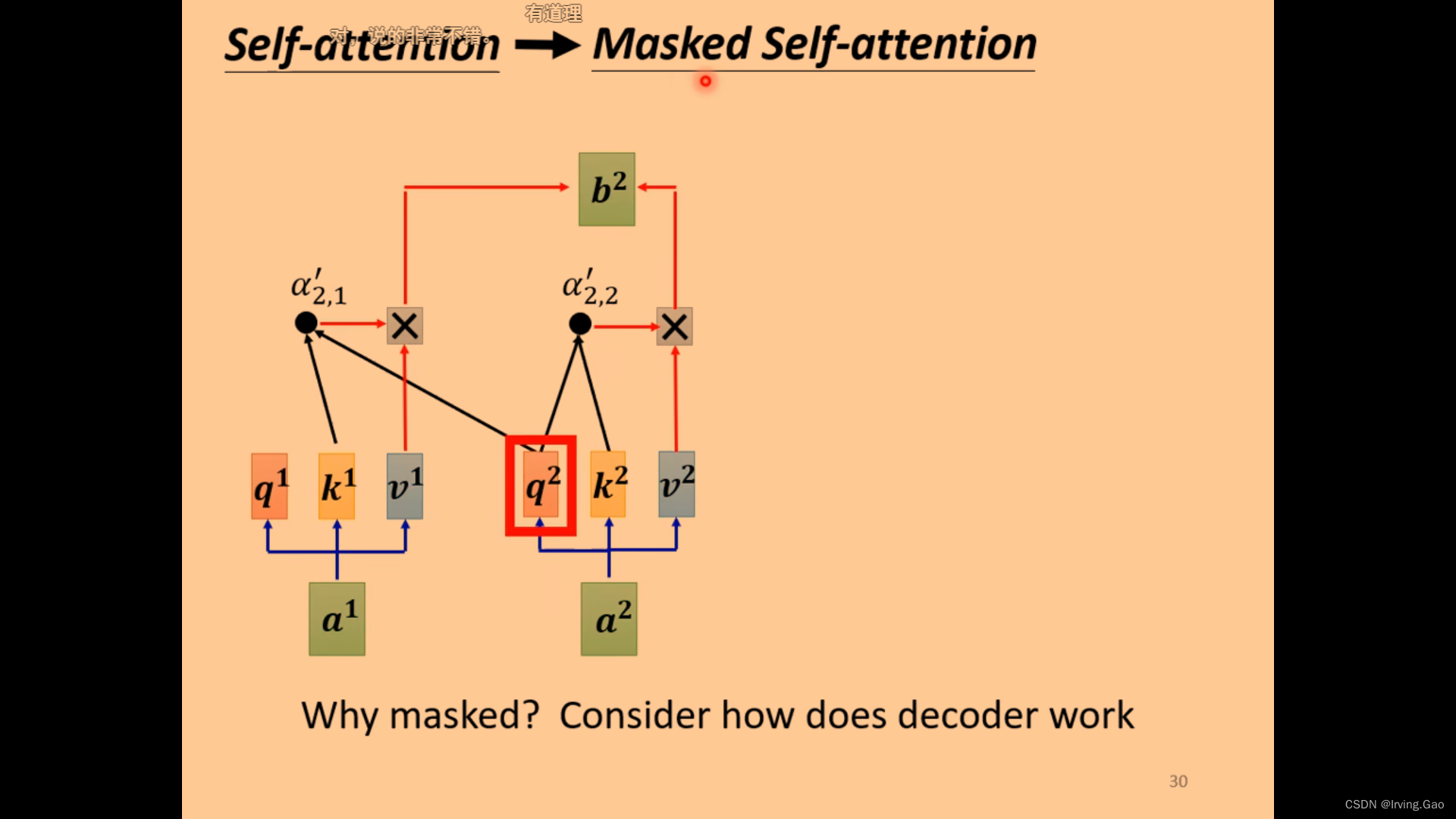
- 在Decoder的
Masked Self Attention中,每一次输出的vector只和前边已生成的vector进行交互,不能包括还未生成的vector;
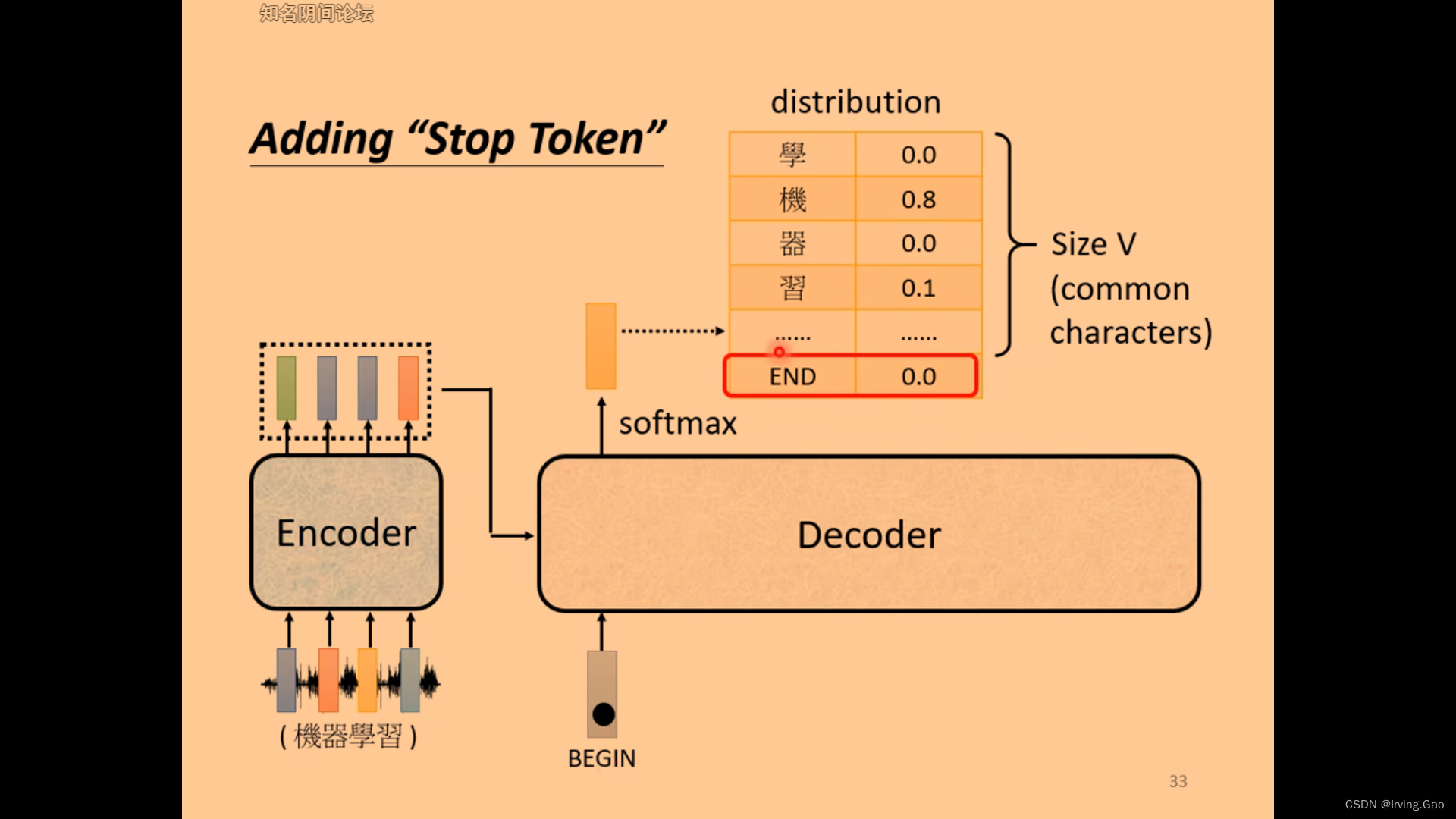
- 通过预测END符号来表示sequence的结束;

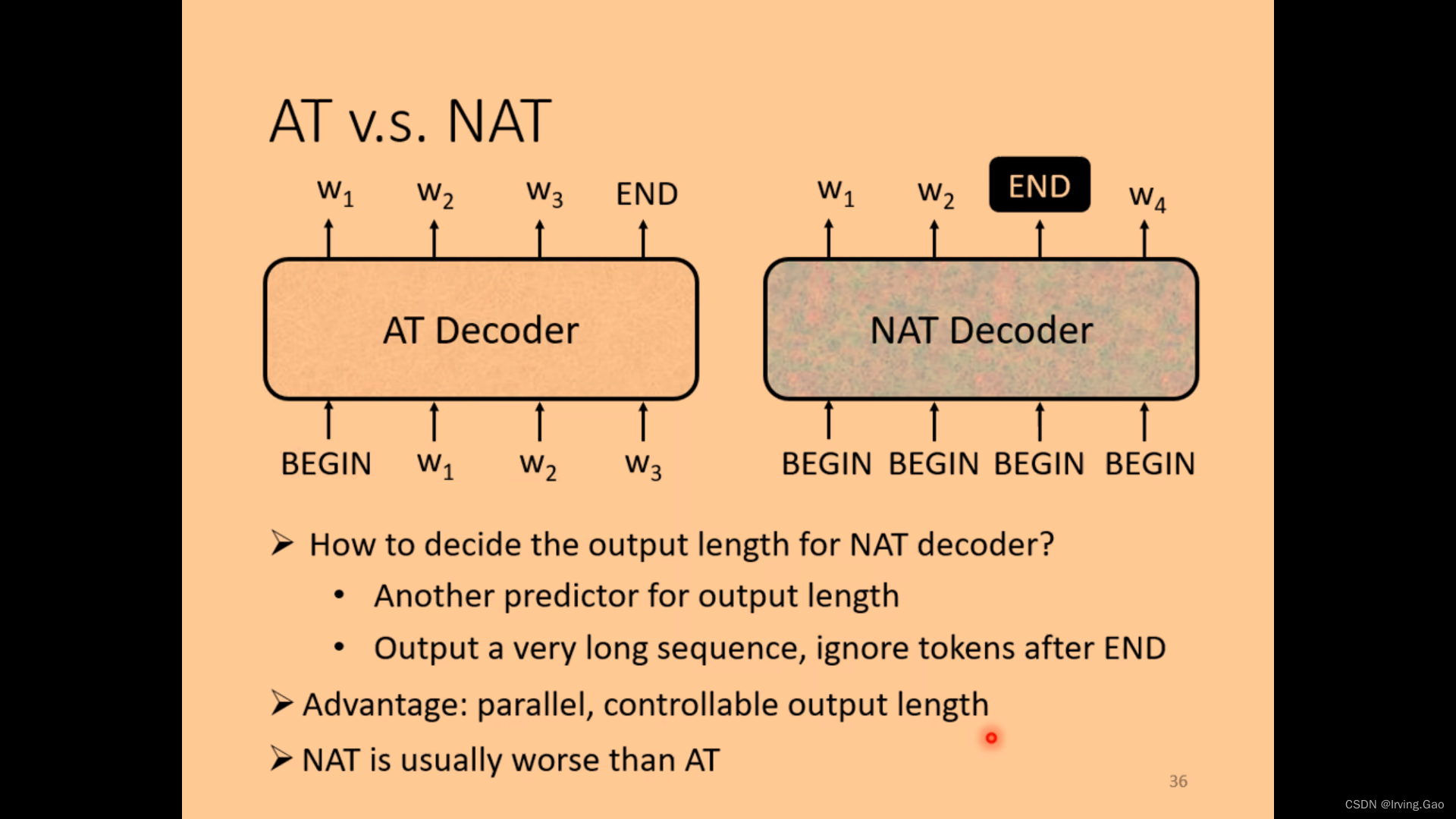
non-autoregressive
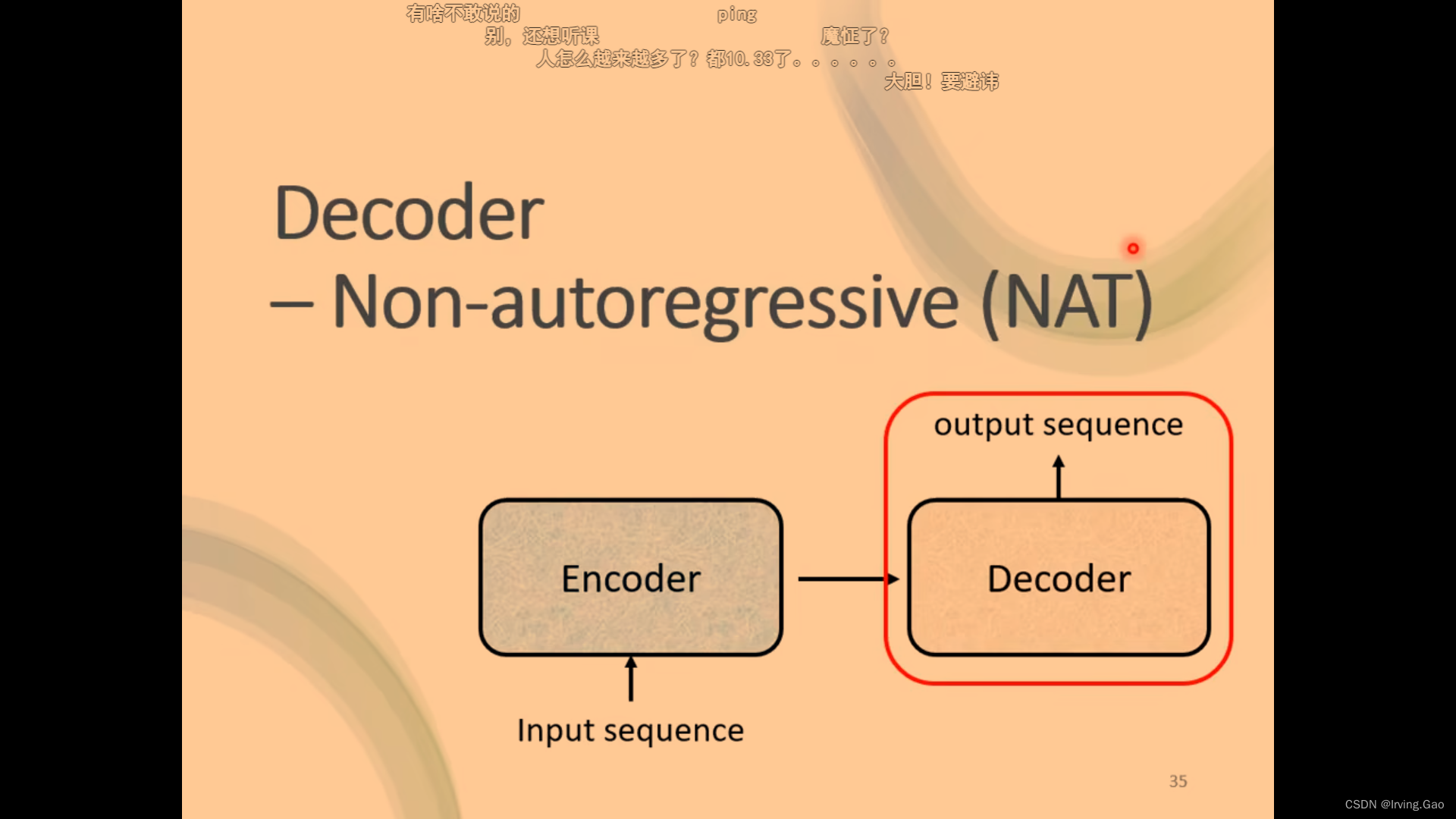
- 优势:并行化,可控制输出长度;
- 用self attention也可以得到;
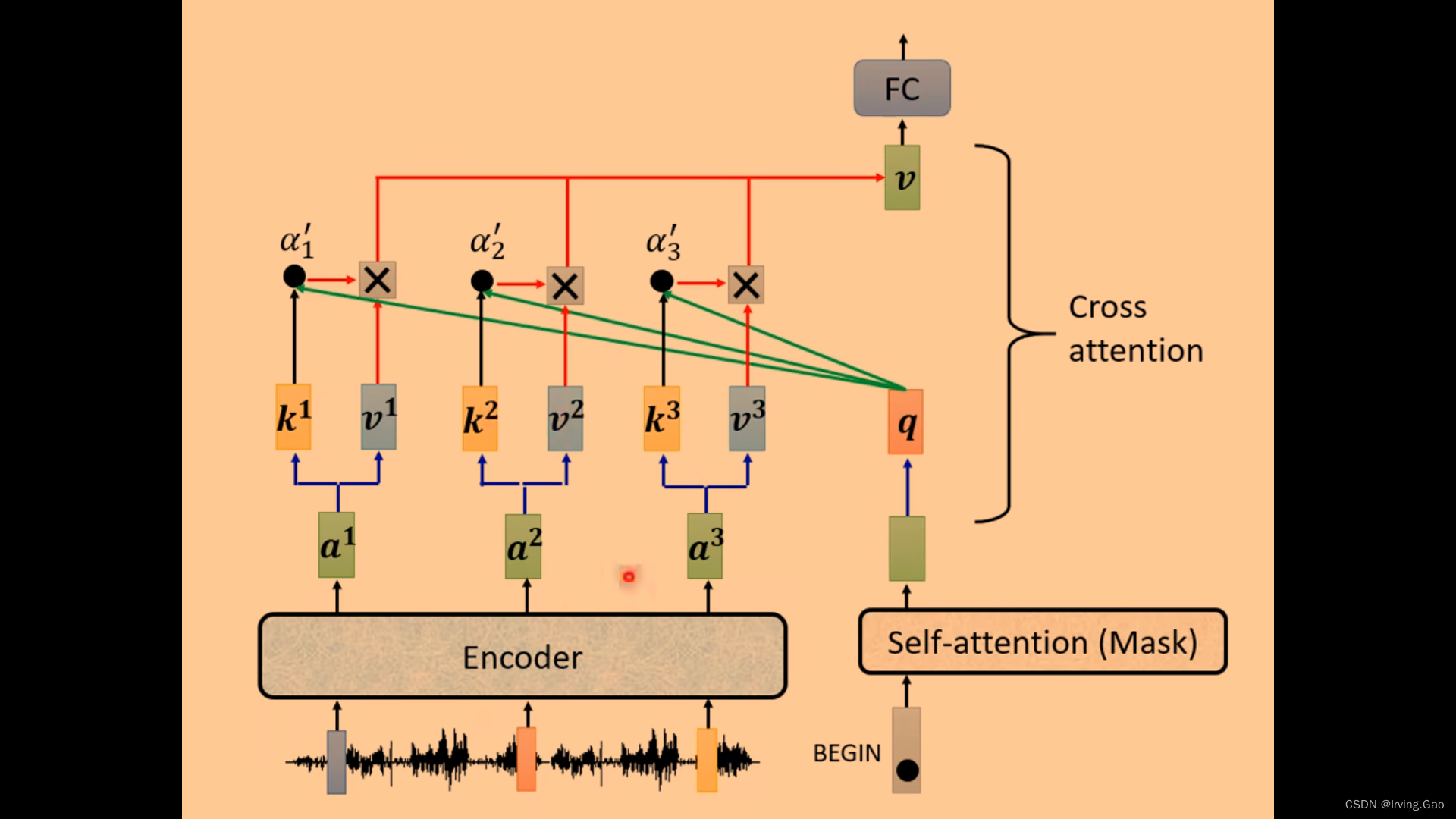
Decoder中的Cross Attention
- 通过Cross Entropy计算loss;
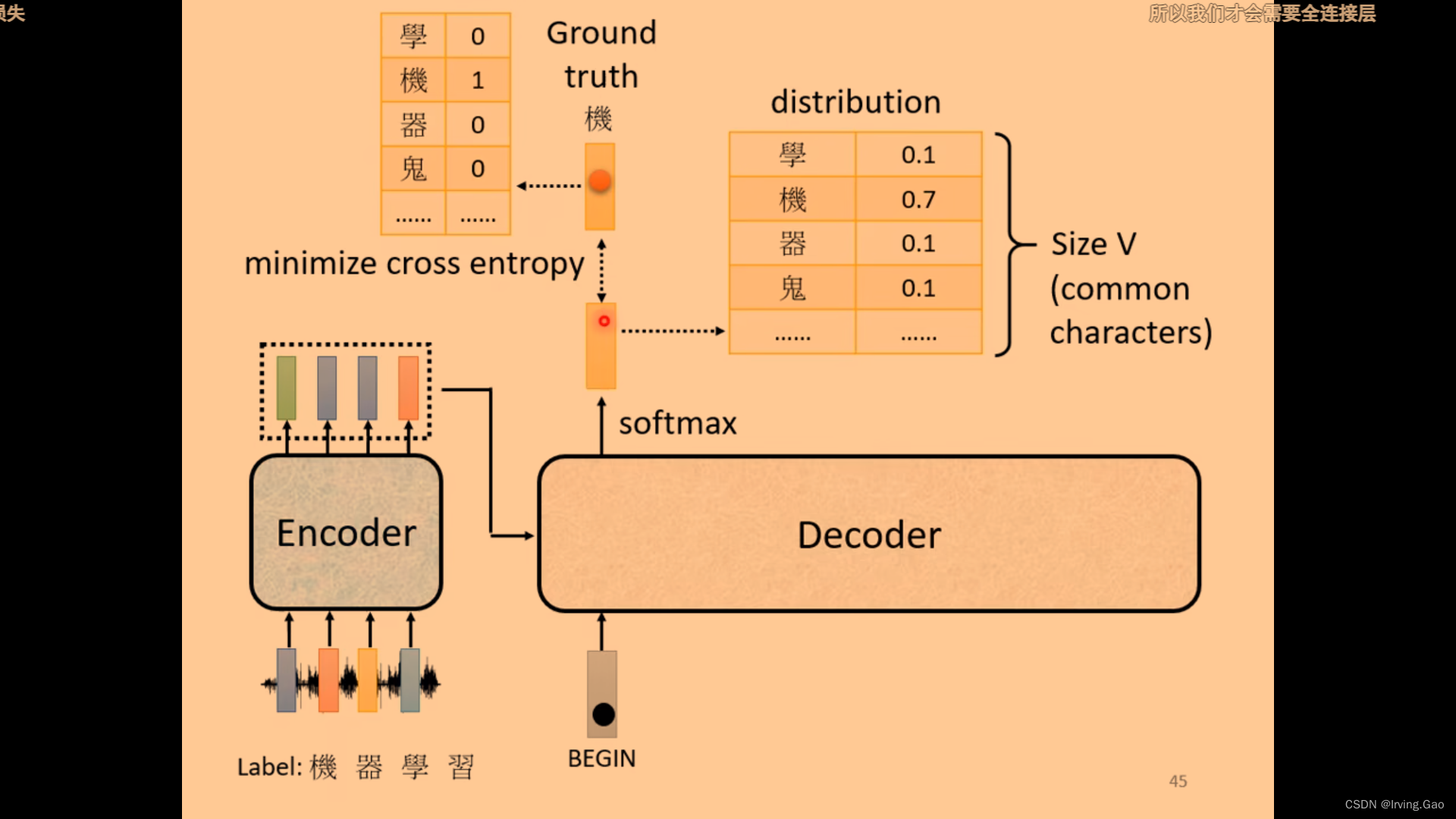
- 训练时会给deocder输入正确答案;
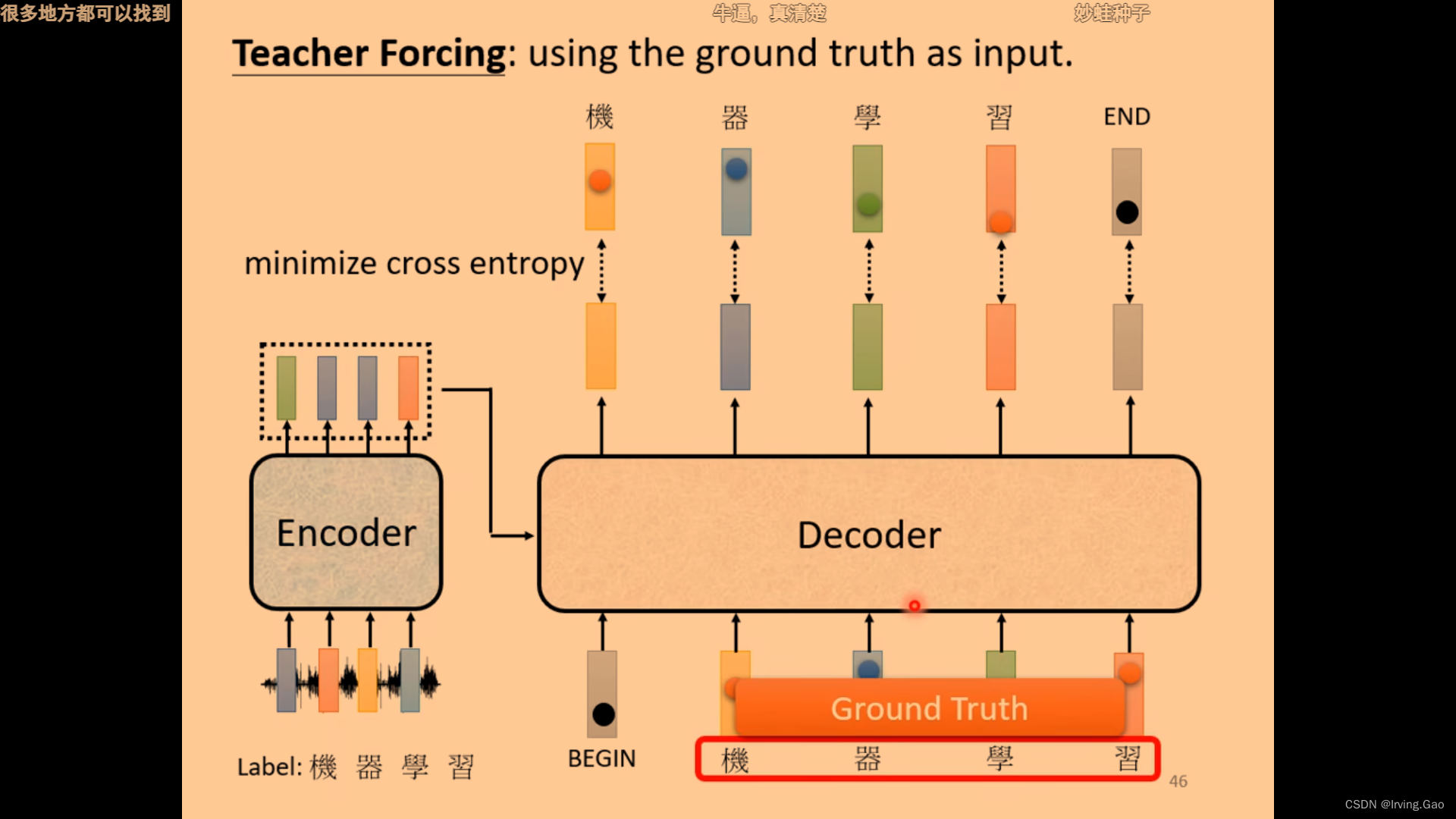
训练Seq2seq的一些Tips
- 训练时给Decoder加入一些错误的GT。









![[附源码]JAVA毕业设计商店管理系统(系统+LW)](https://img-blog.csdnimg.cn/ba5d80ad14594762a31e6751003f0042.png)