C++11新特性第二篇重点
文章目录
- 上一篇的补充
- 一、可变参数模板
- 二、lambda函数
- 总结
前言
上一篇我们重点讲解了右值引用+移动语义,关于移动构造和移动赋值还有一些需要补充的知识:
一、较为简单的新特性
1.delete关键字
当我们不想让一个类的拷贝构造函数去拷贝,那么我们可以在后面加上delete关键字,如下:
class Person
{
public:
Person(const char* name = "", int age = 0)
:_name(name)
, _age(age)
{}
Person(const Person& s) = delete;
private:
string _name;
int _age;
};
int main()
{
Person p1;
Person p2(p1);
return 0;
}我们将Person类中拷贝构造函数加上delete后,我们发现不能再使用拷贝构造了,如下图:

2.final关键字
final关键字的作用是修饰一个类,让一个类不能被继承。final也可以修饰一个成员函数,可以让这个成员函数不能被重写。
3.override关键字
override可以强制检查派生类的虚函数是否完成重写,如果没有完成重写就报错。(纯虚函数可以强制子类完成重写)
4.可变参数列表
template <class ...Args>
void ShowList(Args... args)
{
cout << sizeof...(args) << endl;
}
int main()
{
ShowList();
ShowList(" ", 11, "hello", 12);
return 0;
}上面是一个可变参数包,第一个参数包的参数为0,第二个参数包的参数为4,一个空格字符串,一个数字11,一个hello字符串,一个数字12,我们sizeof打印的时候一定是...在括号外面,实际上...就代表参数包,下面我们看看运行结果是否正确:

那么如果解析这个可变参数包呢?解析参数包的意思就是拿到参数包的内容,比如第二个参数包的4个参数。这里我们给出两种方法:
第一种:递归方式
void ShowList()
{
cout << endl;
}
template <class T, class ...Args>
void ShowList(const T& val, Args... args)
{
/*cout << sizeof...(args) << endl;*/
cout << val << " ";
ShowList(args...);
}
int main()
{
ShowList();
ShowList(" ", 11, "hello", 12);
return 0;
}注意:递归传参数包的时候后面必须加上...
第二个方法:
template <class T>
void PrintArg(T t)
{
cout << t << " ";
}
template <class ...Args>
void ShowList(Args... args)
{
int arr[] = { (PrintArg(args),0)... };
cout << endl;
}
int main()
{
ShowList(1, 'A', "hello", 54);
return 0;
}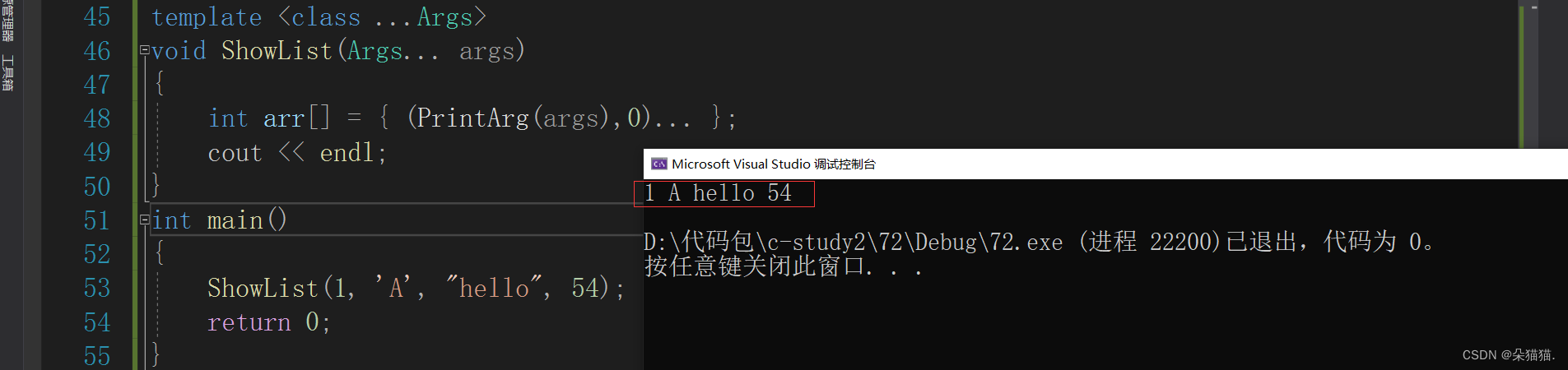
上面arr数组中存放的参数包至于这个数组多大看参数包有多少个参数,...一定要放在括号外面这样编译器才能推出来参数,其中PrintArg用的逗号表达式是因为最后的结果必须是0,如果我们不用PrintArg的返回值的话,我们可以修改一下代码:
template <class T>
int PrintArg(T t)
{
cout << t << " ";
return 0;
}
template <class ...Args>
void ShowList(Args... args)
{
int arr[] = { PrintArg(args)... };
cout << endl;
}
int main()
{
ShowList(1, 'A', "hello", 54);
return 0;
}将...写在括号外面的意思是:每次生成一个PrintArg函数,具体要生成多少个要看这个参数包有多少个参数。
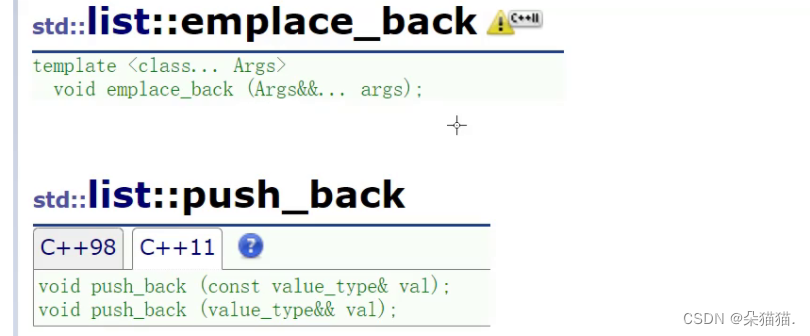
不知道大家还记不记得STL容器中的emplace系列,这个系列就是用参数包做的:
实际上这个参数包就是C语言中的可变参数列表变化而来的。

下面我们看看参数包对应的emplace系列的使用:
int main()
{
list<sxy::string> mylist;
sxy::string s1("hello");
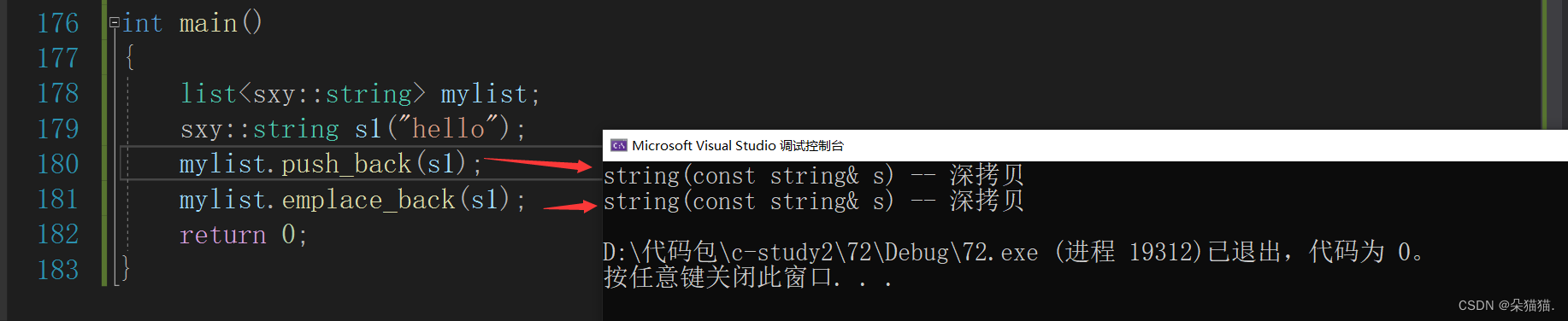
mylist.push_back(s1);
mylist.emplace_back(s1);
return 0;
}我们先看看emplace系列和普通的push_back有什么不同,可以看到emplace系列用了可变参数包,这里用了万能引用,也就是左值引用和右值引用都可以使用,下面我们运行起来看看区别:
运行后我们发现并没有什么区别,我们再试试右值:
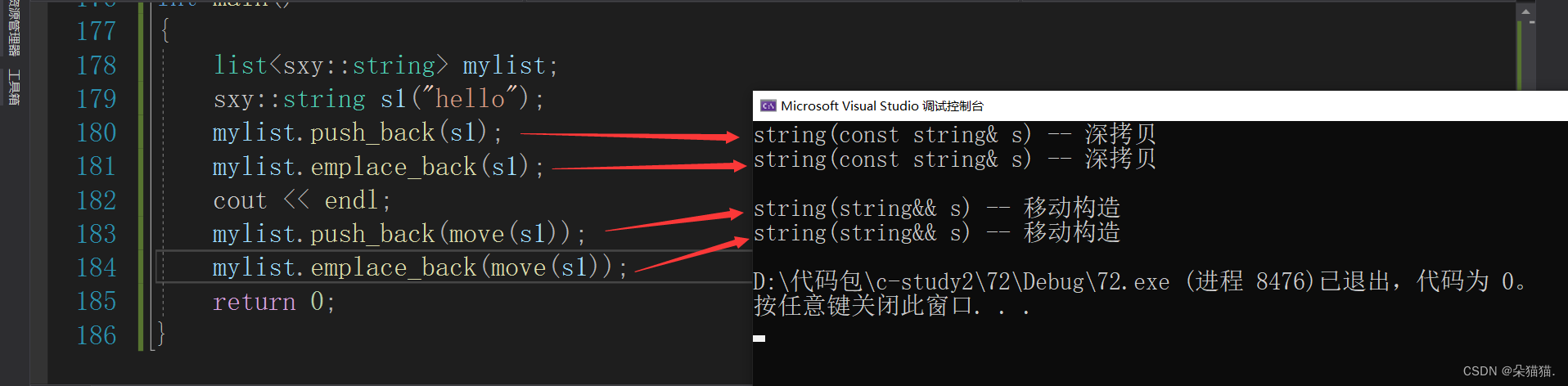
那么emplace系列真正的区别点在哪里呢?下面我们看看匿名对象当右值:
int main()
{
list<sxy::string> mylist;
//有区别
mylist.push_back("3333");
mylist.emplace_back("3333");
return 0;
}
我们可以看到,push_back在插入右值的时候,是构造+移动构造,而emplace版本只需要一个构造,为什么会这样呢?因为我们传的const cahr*类型,这个编译器推参数包的时候直接推导为char*类型,而我们string类本来就有char*类型的直接构造,所以emplace比普通版本的插入效率高!
总结:emplace系列对于深拷贝的类效果不大,因为这里的参数包没有多大效果。对于Date类这种emplace就起了效果,参数包可以直接调用其构造函数。
二、lambda表达式
首先我们学习一下语法:
上面的语法大家先了解一下,下面我们用例子来讲解lambda表达式中有哪些该注意的事项:
struct Goods
{
string _name;
double _price;
int _evaluate;
Goods(const char* str, double price, int evaluate)
:_name(str)
, _price(price)
, _evaluate(evaluate)
{}
};
struct ComparePriceLess
{
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._price < gr._price;
}
};
struct ComparePriceGreater
{
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._price > gr._price;
}
};
int main()
{
vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2,
3 }, { "菠萝", 1.5, 4 } };
sort(v.begin(), v.end(), ComparePriceLess());
sort(v.begin(), v.end(), ComparePriceGreater());
}以前我们对于这种自定义的类进行比较的时候都需要去单独写一个仿函数或者函数指针等,虽然能解决排序的问题但是相对较麻烦,下面我们用lambda表达式比较一下:
int main()
{
vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2,
3 }, { "菠萝", 1.5, 4 } };
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2)->bool
{
return g1._price < g2._price;
});
for (auto& e : v)
{
cout << e._name << " : " << e._evaluate << " : " << e._price << endl;
}
cout << "---------------------------------------" << endl;
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2)->bool
{
return g1._name < g2._name;
});
for (auto& e : v)
{
cout << e._name << " : " << e._evaluate << " : " << e._price << endl;
}
}
我们可以看到lambda表达式对于这样的情况处理起来简直太方便了,具体的语法我们下面进行讲解:

上图中我们可以详细的看到lambda的每个部分,注意函数体内的;和语句结尾的;。就以上面的表达式为例,首先我们的返回值类型是可以省略的,如下图:

使用起来也很简单,可以用lambda对象,也可以直接用对象名: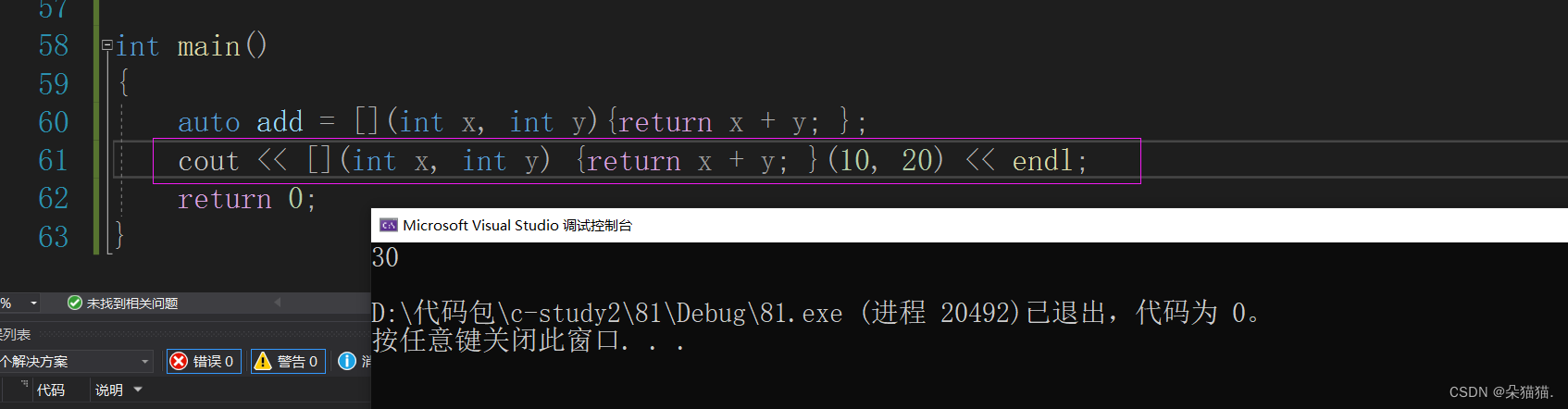

注意:lambda表达式中有两个位置是一定不可以省略的,第一个是捕捉列表[],第二个是函数体{}.
下面我们讲讲捕捉列表的作用:
比如我们现在要实现一个交换的函数:
int main()
{
int x = 10, y = 20;
auto swap = [](int x, int y)
{
int tmp = x;
x = y;
y = tmp;
};
swap(x, y);
cout << x << ":" << y << endl;
return 0;
}
这里为什么没有交换成功呢?因为我们lambda表达式中的参数是传值的,函数体内交换的是x和y的临时拷贝,所以我们应该用传引用:

这次我们看到成功了,下面我们在用用捕捉列表,捕捉列表可以捕捉我们当前作用域的值:

捕捉后我们发现不能修改,这是因为lambda捕捉列表为了防止有人直接修改作用域的值,所以捕捉过来的值不允许修改,那么如何修改呢?我们需要在后面加上mutable,这个的含义是异变:
int main()
{
int x = 10, y = 20;
auto swap = [x, y]()mutable
{
int tmp = x;
x = y;
y = tmp;
};
swap();
cout << x << ":" << y << endl;
return 0;
}
我们发现捕捉后还是不能成功交换啊,这是因为默认的捕捉是传值捕捉,我们需要在捕捉变量前面加上&符号,这样就是引用捕捉了:

下面我们两个特殊的用法:
全部引用捕捉:

全部传值捕捉:
 混合捕捉:
混合捕捉:

上面捕捉列表的意思是:x使用传值捕捉,其他全是引用捕捉。
下面我们用一下线程来演示lambda表达式的魅力:(不知道线程相关知识的可以看我linux线程的文章)
#include <thread>
void func(int n)
{
for (int i = 0; i < n; i++)
{
cout << i << " ";
}
cout << endl;
}
int main()
{
thread t1(func, 10);
thread t2(func, 5);
t1.join();
t2.join();
return 0;
}以上是传统写法,我们让两个线程去执行func函数打印,下面是结果:
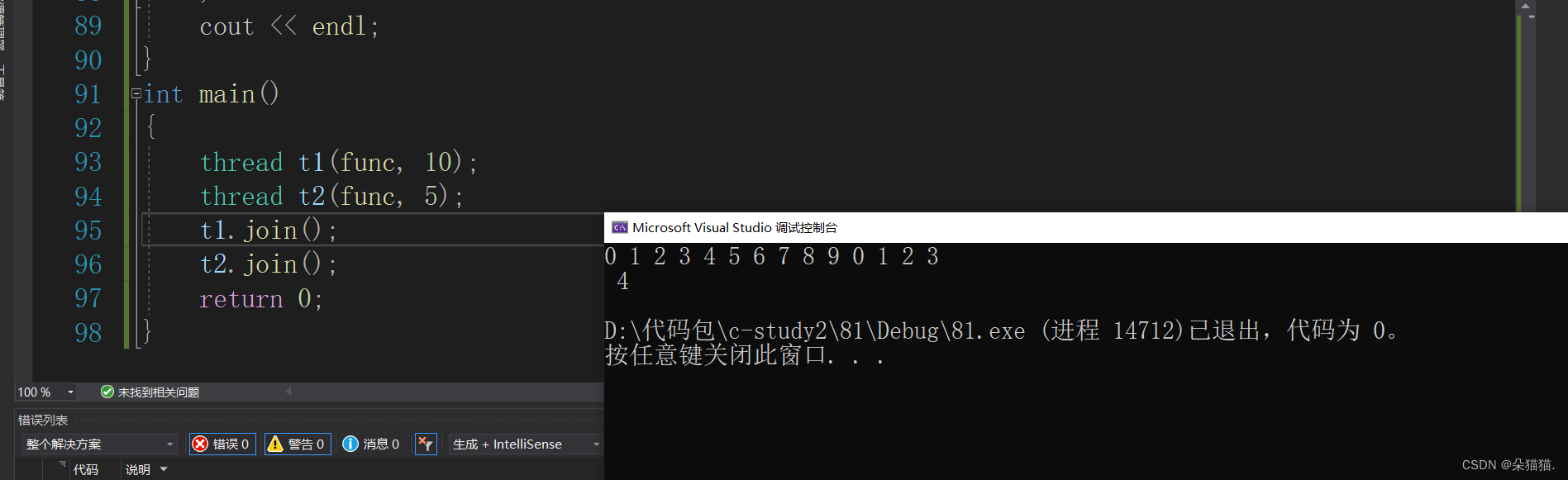
出现上面结果的原因不难解释,因为我们的线程是并发访问的,所以这个函数是很有可能被两个线程同时进入的,这就导致换行出现问题。下面我们用lambda表达式来写上面的代码:
int main()
{
int n = 10;
thread t1([n]()
{
for (int i = 0; i < n; i++)
{
cout << i << " ";
}
cout << endl;
});
thread t2([n]()
{
for (int i = 0; i < n; i++)
{
cout << i << " ";
}
cout << endl;
});
t1.join();
t2.join();
return 0;
}
以上就是lambda表达式的所有内容了,后面我们讲解c++11线程的时候也会大量的用到lambda表达式。
总结
函数对象和lambda表达式:
class Rate
{
public:
Rate(double rate): _rate(rate)
{}
double operator()(double money, int year)
{ return money * _rate * year;}
private:
double _rate;
};
int main()
{
// 函数对象
double rate = 0.49;
Rate r1(rate);
r1(10000, 2);
// lamber
auto r2 = [=](double monty, int year)->double{return monty*rate*year;
};
r2(10000, 2);
return 0;
}在上述代码中,我们运行起来查看汇编代码看lambda的底层是什么:
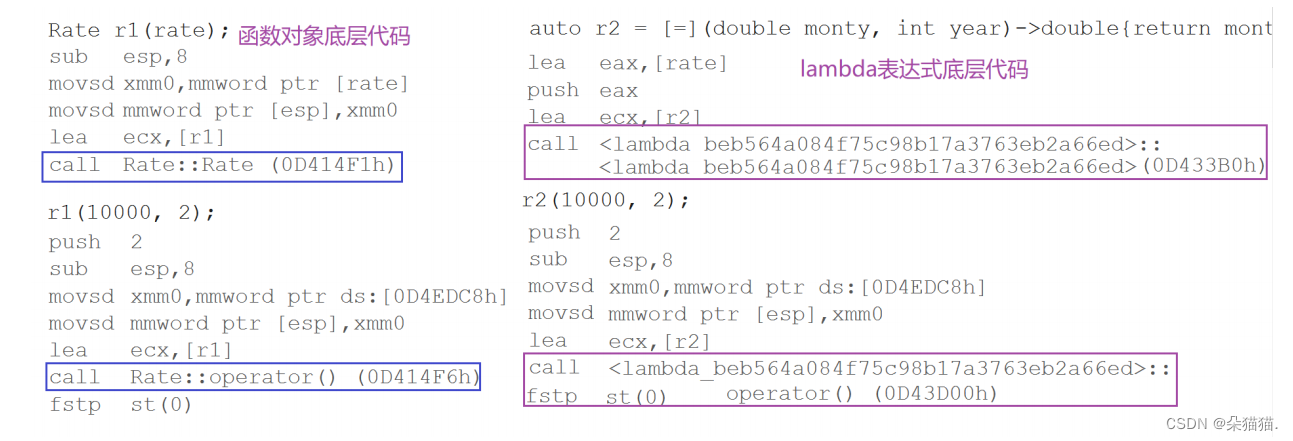
实际在底层编译器对于lambda表达式的处理方式,完全就是按照函数对象的方式处理的,即:如