右值引用C++11
- 1.左值和右值
- 2.左值引用
- 3.右值引用
- 4.右值引用的性能优化空间
- 5.移动语义
- 6.值类别
- 7.将左值转化为右值
- 8.万能引用和引用折叠
- 9.完美转发
- 10.针对局部变量和右值引用的隐士类型转换
- 11.总结
今天看到谢丙堃老师的《现代C++语言核心特性解析》一书中关于右值引用的介绍,非常详细,再此分享一下,仅供学习使用。
1.左值和右值
左值和右值的概念早在C++98的时候就已经出现了,从最简单的字
面理解,无非是表达式等号左边的值为左值,而表达式右边的值为右
值,比如:
int x = 1;
int y = 3;
int z = x + y;
以上面的代码为例,x是左值,1是右值;y是左值,3是右值;z是
左值,x+y的结果是右值。用表达式等号左右的标准区分左值和右值虽
然在一些场景下确实能得到正确结果,但是还是过于简单,有些情况下
是无法准确区分左值和右值的,比如:
int a = 1;
int b = a;
按照表达式等号左右的区分方式,在第一行代码中a是左值,1是右
值;在第二行代码中b是左值,而a是右值。这里出现了矛盾,在第一行
代码中我们判断a是一个左值,它却在第二行变成了右值,很明显这不
是我们想要的结果,要准确地区分左值和右值还是应该理解其内在含
义。
在C++中所谓的左值一般是指一个指向特定内存的具有名称的值
(具名对象),它有一个相对稳定的内存地址,并且有一段较长的生命
周期。而右值则是不指向稳定内存地址的匿名值(不具名对象),它的
生命周期很短,通常是暂时性的。基于这一特征,我们可以用取地址
符&来判断左值和右值,能取到内存地址的值为左值,否则为右值。还
是以上面的代码为例,因为&a和&b都是符合语法规则的,所以a和b都
是左值,而&1在GCC中会给出“lvalue required as unary ‘&’ operand”错误
信息以提示程序员&运算符需要的是一个左值。
上面的代码在左右值的判断上比较简单,但是并非所有的情况都是
如此,下面这些情况左值和右值的判断可能是违反直觉的,例如:
int x = 1;
int get_val()
{
return x;
}
void set_val(int val)
{
x = val;
}
int main()
{
x++;
++x;
int y = get_val();
set_val(6);
}
在上面的代码中,x++和++x虽然都是自增操作,但是却分为不同
的左右值。其中x++是右值,因为在后置++操作中编译器首先会生成一
份x值的临时复制,然后才对x递增,最后返回临时复制内容。而++x则
不同,它是直接对x递增后马上返回其自身,所以++x是一个左值。如果
对它们实施取地址操作,就会发现++x的取地址操作可以编译成功,而
对x++取地址则会报错。但是从直觉上来说,&x++看起来更像是会编译
成功的一方:
int *p = &x++; // 编译失败
int *q = &++x; // 编译成功
接着来看上一份代码中的get_val函数,该函数返回了一个全局变
量x,虽然很明显变量x是一个左值,但是它经过函数返回以后变成了一
个右值。原因和x++类似,在函数返回的时候编译器并不会返回x本身,
而是返回x的临时复制,所以int * p = &get_val();也会编译失败。
对于set_val函数,该函数接受一个参数并且将参数的值赋值到x中。
在main函数中set_val(6);实参6是一个右值,但是进入函数之后形参
val却变成了一个左值,我们可以对val使用取地址符,并且不会引起
任何问题:
void set_val(int val)
{
int *p = &val;
x = val;
}
最后需要强调的是,通常字面量都是一个右值,除字符串字面量以
外:
int x = 1;
set_val(6);
auto p = &"hello world";
这一点非常容易被忽略,因为经验告诉我们上面的代码中前两行的
1和6都是右值,因为不存在&1和&6的语法,这会让我们想当然地认
为"hello world"也是一个右值,毕竟&"hello world"的语法也很少
看到。但是这段代码是可以编译成功的,其实原因仔细想来也很简单,
编译器会将字符串字面量存储到程序的数据段中,程序加载的时候也会
为其开辟内存空间,所以我们可以使用取地址符&来获取字符串字面量
的内存地址。
2.左值引用
左值引用是编程过程中的常用特性之一,它的出现让C++编程在一
定程度上脱离了危险的指针。当我们需要将一个对象作为参数传递给子
函数的时候,往往会使用左值引用,因为这样可以免去创建临时对象的
操作。非常量左值的引用对象很单纯,它们必须是一个左值。对于这一
点,常量左值引用的特性显得更加有趣,它除了能引用左值,还能够引
用右值,比如:
int &x1 = 7; // 编译错误
const int &x = 11; // 编译成功
在上面的代码中,第一行代码会编译报错,因为int&无法绑定一
个int类型的右值,但是第二行代码却可以编译成功。请注意,虽然在
结果上const int &x = 11和const int x = 11是一样的,但是从语
法上来说,前者是被引用了,所以语句结束后11的生命周期被延长,而
后者当语句结束后右值11应该被销毁。虽然常量左值引用可以引用右值
的这个特性在赋值表达式中看不出什么实用价值,但是在函数形参列表
中却有着巨大的作用。一个典型的例子就是复制构造函数和复制赋值运
算符函数,通常情况下我们实现的这两个函数的形参都是一个常量左值
引用,例如
class X {
public:
X() {}
X(const X&) {}
X& operator = (const X&) { return *this; }
};
X make_x()
{
return X();
}
int main()
{
X x1;
X x2(x1);
X x3(make_x());
x3 = make_x();
}
以上代码可以通过编译,但是如果这里将类X的复制构造函数和复
制赋值函数形参类型的常量性删除,则X x3(make_x());和x3 =
make_x();这两句代码会编译报错,因为非常量左值引用无法绑定
到make_x()产生的右值。常量左值引用可以绑定右值是一条非常棒的
特性,但是它也存在一个很大的缺点——常量性。一旦使用了常量左值
引用,就表示我们无法在函数内修改该对象的内容(强制类型转换除
外)。所以需要另外一个特性来帮助我们完成这项工作,它就是右值引
用。
3.右值引用
顾名思义,右值引用是一种引用右值且只能引用右值的方法。在语
法方面右值引用可以对比左值引用,在左值引用声明中,需要在类型后
添加&,而右值引用则是在类型后添加&&,例如:
int i = 0;
int &j = i; // 左值引用
int &&k = 11; // 右值引用
在上面的代码中,k是一个右值引用,如果试图用k引用变量i,则
会引起编译错误。右值引用的特点之一是可以延长右值的生命周期,这
个对于字面量11可能看不出效果,那么请看下面的例子:
# include <iostream>
class X {
public:
X() { std::cout << "X ctor" << std::endl; }
X(const X&x) { std::cout << "X copy ctor" << std::endl; }
~X() { std::cout << "X dtor" << std::endl; }
void show() { std::cout << "show X" << std::endl; }
};
X make_x()
{
X x1;
return x1;
}
int main()
{
X &&x2 = make_x();
x2.show();
}
在理解这段代码之前,让我们想一下如果将X &&x2 = make_x()
这句代码替换为X x2 = make_x()会发生几次构造。在没有进行任何
优化的情况下应该是3次构造,首先make_x函数中x1会默认构造一次,
然后return x1会使用复制构造产生临时对象,接着X x2 = make_x()
会使用复制构造将临时对象复制到x2,最后临时对象被销毁。
以上流程在使用了右值引用以后发生了微妙的变化,让我们编译运
行这段代码。请注意,用GCC编译以上代码需要加上命令行参数-fno-
elide-constructors用于关闭函数返回值优化(RVO)。因为GCC的
RVO优化会减少复制构造函数的调用,不利于语言特性实验:
X ctor
X copy ctor
X dtor
show X
X dtor
从运行结果可以看出上面的代码只发生了两次构造。第一次
是make_x函数中x1的默认构造,第二次是return x1引发的复制构
造。不同的是,由于x2是一个右值引用,引用的对象是函数make_x返
回的临时对象,因此该临时对象的生命周期得到延长,所以我们可以
在X &&x2 = make_x()语句结束后继续调用show函数而不会发生任何
问题。对性能敏感的读者应该注意到了,延长临时对象生命周期并不是
这里右值引用的最终目标,其真实目标应该是减少对象复制,提升程序
性能。
4.右值引用的性能优化空间
通过3的介绍我们知道了很多情况下右值都存储在临时对象
中,当右值被使用之后程序会马上销毁对象并释放内存。这个过程可能
会引发一个性能问题,例如:
#include <iostream>
class BigMemoryPool {
public:
static const int PoolSize = 4096;
BigMemoryPool() : pool_(new char[PoolSize]) {}
~BigMemoryPool()
{
if (pool_ != nullptr) {
delete[] pool_;
}
}
BigMemoryPool(const BigMemoryPool& other) : pool_(new char[PoolSize])
{
std::cout << "copy big memory pool." << std::endl;
memcpy(pool_, other.pool_, PoolSize);
}
private:
char *pool_;
};
BigMemoryPool get_pool(const BigMemoryPool& pool)
{
return pool;
}
BigMemoryPool make_pool()
{
BigMemoryPool pool;
return get_pool(pool);
}
int main()
{
BigMemoryPool my_pool = make_pool();
}
以上代码同样需要加上编译参数-fno-elide-constructors,编
译运行程序会在屏幕上输出字符串:
copy big memory pool.
copy big memory pool.
copy big memory pool.
可以看到BigMemoryPool my_pool = make_pool();调用了3次
复制构造函数。
1.get_pool返回的BigMemoryPool临时对象调用复制构造函数复
制了pool对象。
2.make_pool返回的BigMemoryPool临时对象调用复制构造函数
复制了get_pool返回的临时对象。
3.main函数中my_pool调用其复制构造函数复制make_pool返回
的临时对象。
该代码从正确性上看毫无问题,但是从运行性能的角度上看却还有
巨大的优化空间。在这里每发生一次复制构造都会复制整整4KB的数
据,如果数据量更大一些,比如4MB或者400MB,那么将对程序性能造
成很大影响。
5.移动语义
仔细分析4代码中3次复制构造函数的调用,不难发现第二次和
第三次的复制构造是影响性能的主要原因。在这个过程中都有临时对象
参与进来,而临时对象本身只是做数据的复制。如果有办法能将临时对
象的内存直接转移到my_pool对象中,不就能消除内存复制对性能的消
耗吗?好消息是在C++11标准中引入了移动语义,它可以帮助我们将临
时对象的内存移动到my_pool对象中,以避免内存数据的复制。让我们
简单修改一下BigMemoryPool类代码:
class BigMemoryPool {
public:
static const int PoolSize = 4096;
BigMemoryPool() : pool_(new char[PoolSize]) {}
~BigMemoryPool()
{
if (pool_ != nullptr) {
delete[] pool_;
}
}
BigMemoryPool(BigMemoryPool&& other)
{
std::cout << "move big memory pool." << std::endl;
pool_ = other.pool_;
other.pool_ = nullptr;
}
BigMemoryPool(const BigMemoryPool& other) : pool_(new char[PoolSize])
{
std::cout << "copy big memory pool." << std::endl;
memcpy(pool_, other.pool_, PoolSize);
}
private:
char *pool_;
};
在上面的代码中增加了一个类BigMemoryPool的构造函
数BigMemoryPool (BigMemoryPool&& other),它的形参是一个右
值引用类型,称为移动构造函数。这个名称很容易让人联想到复制构造
函数,那么就让我们先了解一下它们的区别。
从构造函数的名称和它们的参数可以很明显地发现其中的区别,对
于复制构造函数而言形参是一个左值引用,也就是说函数的实参必须是
一个具名的左值,在复制构造函数中往往进行的是深复制,即在不能破
坏实参对象的前提下复制目标对象。而移动构造函数恰恰相反,它接受
的是一个右值,其核心思想是通过转移实参对象的数据以达成构造目标
对象的目的,也就是说实参对象是会被修改的。
进一步来说类BigMemoryPool的移动构造函数,在函数中没有了复
制构造中的内存复制,取而代之的是简单的指针替换操作。它将实参对
象的pool_赋值到当前对象,然后置空实参对象以保证实参对象析构的
时候不会影响这片内存的生命周期。
编译运行这段代码,其输出结果如下:
copy big memory pool.
move big memory pool.
move big memory pool.
可以看到后面两次的构造函数变成了移动构造函数,因为这两次操
作中源对象都是右值(临时对象),对于右值编译器会优先选择使用移
动构造函数去构造目标对象。当移动构造函数不存在的时候才会退而求
其次地使用复制构造函数。在移动构造函数中使用了指针转移的方式构
造目标对象,所以整个程序的运行效率得到大幅提升。
为了验证效率的提升,我们可以将上面的代码重复运行 100 万次,
然后输出运行时间。请注意,在做实验前需要将构造函数中的打印输出
语句删除,否则会影响实验数据:
#include <chrono>
…
int main()
{
auto start = std::chrono::high_resolution_clock::now();
for (int i = 0; i < 1000000; i++) {
BigMemoryPool my_pool = make_pool();
}
auto end = std::chrono::high_resolution_clock::now();
std::chrono::duration<double> diff = end - start;
std::cout << "Time to call make_pool :" << diff.count() << " s" <<
std::endl;
}
以上代码在我的机器上运行结果是0.206474s,如果将移动构造函数
删除,运行结果是0.47077s,可见使用移动构造函数将性能提升了1倍
多。
除移动构造函数能实现移动语义以外,移动赋值运算符函数也能完
成移动操作,继续以BigMemoryPool为例,在这个类中添加移动赋值运
算符函数:`
class BigMemoryPool {
public:
…
BigMemoryPool& operator=(BigMemoryPool&& other)
{
std::cout << "move(operator=) big memory pool." << std::endl;
if (pool_ != nullptr) {
delete[] pool_;
}
pool_ = other.pool_;
other.pool_ = nullptr;
return *this;
}
private:
char *pool_;
};
int main()
{
BigMemoryPool my_pool;
my_pool = make_pool();
}
结果:
copy big memory pool.
move big memory pool.
move(operator=) big memory pool.
可以看到赋值操作my_pool = make_pool()调用了移动赋值运算
符函数,这里的规则和构造函数一样,即编译器对于赋值源对象是右值
的情况会优先调用移动赋值运算符函数,如果该函数不存在,则调用复
制赋值运算符函数。
最后有两点需要说明一下。
1.同复制构造函数一样,编译器在一些条件下会生成一份移动构
造函数,这些条件包括:没有任何的复制函数,包括复制构造函数和复
制赋值函数;没有任何的移动函数,包括移动构造函数和移动赋值函
数;也没有析构函数。虽然这些条件严苛得让人有些不太愉快,但是我
们也不必对生成的移动构造函数有太多期待,因为编译器生成的移动构
造函数和复制构造函数并没有什么区别。
2.虽然使用移动语义在性能上有很大收益,但是却也有一些风
险,这些风险来自异常。试想一下,在一个移动构造函数中,如果当一
个对象的资源移动到另一个对象时发生了异常,也就是说对象的一部分
发生了转移而另一部分没有,这就会造成源对象和目标对象都不完整的
情况发生,这种情况的后果是无法预测的。所以在编写移动语义的函数
时建议确保函数不会抛出异常,与此同时,如果无法保证移动构造函数
不会抛出异常,可以使用noexcept说明符限制该函数。这样当函数抛
出异常的时候,程序不会再继续执行而是调用std::terminate中止执
行以免造成其他不良影响。
6.值类别
到目前为止一切都非常容易理解,其中一个原因是我在前面的内容
中隐藏了一个概念。但是在进一步探讨右值引用之前,我们必须先掌握
这个概念——值类别。值类别是C++11标准中新引入的概念,具体来说
它是表达式的一种属性,该属性将表达式分为3个类别,它们分别是左
值(lvalue)、纯右值(prvalue)和将亡值(xvalue),如图6-1所示。
从前面的内容中我们知道早在C++98的时候,已经有了一些关于左值和
右值的概念了,只不过当时这些概念对于C++程序编写并不重要。但是
由于C++11中右值引用的出现,值类别被赋予了全新的含义。可惜的
是,在C++11标准中并没能够清晰地定义它们,比如在C++11的标准文
档中,左值的概念只有一句话:“指定一个函数或一个对象”,这样的描
述显然是不清晰的。这种糟糕的情况一直延续到C++17标准的推出才得
到解决。所以现在是时候让我们重新认识这些概念了。
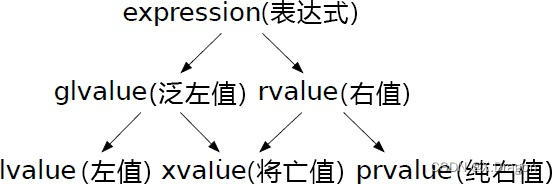
表达式首先被分为了泛左值(glvalue)和右值(rvalue),其中泛左
值被进一步划分为左值和将亡值,右值又被划分为将亡值和纯右值。理
解这些概念的关键在于泛左值、纯右值和将亡值。
1.所谓泛左值是指一个通过评估能够确定对象、位域或函数的标
识的表达式。简单来说,它确定了对象或者函数的标识(具名对象)。
2.而纯右值是指一个通过评估能够用于初始化对象和位域,或者
能够计算运算符操作数的值的表达式。
3.将亡值属于泛左值的一种,它表示资源可以被重用的对象和位
域,通常这是因为它们接近其生命周期的末尾,另外也可能是经过右值
引用的转换产生的。
剩下的两种类别就很容易理解了,其中左值是指非将亡值的泛左
值,而右值则包含了纯右值和将亡值。再次强调,值类别都是表达式的
属性,所以我们常说的左值和右值实际上指的是表达式,不过为了描述
方便我们常常会忽略它。
是不是感觉有点晕。相信我,当我第一次看到这些概念的时候也是
这个反应。不过好在我们对传统左值和右值的概念已经了然于心了,现
在只需要做道连线题就能弄清楚它们的概念。实际上,这里的左值
(lvalue)就是我们上文中描述的C++98的左值,而这里的纯右值
(prvalue)则对应上文中描述的C++98的右值。最后我们惊喜地发现,
现在只需要弄清楚将亡值(xvalue)到底是如何产生的就可以了。
从本质上说产生将亡值的途径有两种,第一种是使用类型转换将泛
左值转换为该类型的右值引用。比如:
static_cast<BigMemoryPool&&>(my_pool)
第二种在C++17标准中引入,我们称它为临时量实质化,指的是纯
右值转换到临时对象的过程。每当纯右值出现在一个需要泛左值的地方
时,临时量实质化都会发生,也就是说都会创建一个临时对象并且使用
纯右值对其进行初始化,这也符合纯右值的概念,而这里的临时对象就
是一个将亡值。
struct X {
int a;
};
int main()
{
int b = X().a;
}
在上面的代码中,S()是一个纯右值,访问其成员变量a却需要一个
泛左值,所以这里会发生一次临时量实质化,将S()转换为将亡值,最
后再访问其成员变量a。还有一点需要说明,在C++17标准之前临时变
量是纯右值,只有转换为右值引用的类型才是将亡值。
在本节之后的内容中,依然会以左值和右值这样的术语为主。但是
读者应该清楚,这里的左值是C++17中的左值(lvalue),右值是C++17
中的纯右值(prvalue)和将亡值(xvalue)。对于将亡值(xvalue),
读者实际上只需要知道它是泛左值和右值交集即可,后面的内容也不会
重点强调它,所以不会影响到读者对后续内容的理解。
7.将左值转化为右值
在3提到过右值引用只能绑定一个右值,如果尝试绑定,左值
会导致编译错误:
int i = 0;
int &&k = i; // 编译失败
不过,如果想完成将右值引用绑定到左值这个“壮举”还是有办法
的。在C++11标准中可以在不创建临时值的情况下显式地将左值通过
static_cast转换为将亡值,通过值类别的内容我们知道将亡值属于右
值,所以可以被右值引用绑定。值得注意的是,由于转换的并不是右
值,因此它依然有着和转换之前相同的生命周期和内存地址,例如:
int i = 0;
int &&k = static_cast<int&&>(i); // 编译成功
读者在这里应该会有疑问,既然这个转换既不改变生命周期也不改
变内存地址,那它有什么存在的意义呢?实际上它的最大作用是让左值
使用移动语义,还是以BigMemoryPool为例:
BigMemoryPool my_pool1;
BigMemoryPool my_pool2 = my_pool1;
BigMemoryPool my_pool3 = static_cast<BigMemoryPool &&>(my_pool1);
在这段代码中,my_pool1是一个BigMemoryPool类型的对象,也
是一个左值,所以用它去构造my_pool2的时候调用的是复制构造函
数。为了让编译器调用移动构造函数构造my_pool3,这里使用了
static_cast<BigMemoryPool &&>(my_ pool1)将my_pool1强制转
换为右值(也是将亡值,为了叙述思路的连贯性后面不再强调)。由于
调用了移动构造函数,my_pool1失去了自己的内存数据,后面的代码
也不能对my_pool1进行操作了。
现在问题又来了,这样单纯地将一个左值数据转换到另外一个左值
似乎并没有什么意义。在这个例子中的确如此,这样的转换不仅没有意
义,而且如果有程序员在移动构造之后的代码中再次使用my_pool1还
会引发未定义的行为。正确的使用场景是在一个右值被转换为左值后需
要再次转换为右值,最典型的例子是一个右值作为实参传递到函数中。
我们在讨论左值和右值的时候曾经提到过,无论一个函数的实参是左值
还是右值,其形参都是一个左值,即使这个形参看上去是一个右值引
用,例如:
void move_pool(BigMemoryPool &&pool)
{
std::cout << "call move_pool" << std::endl;
BigMemoryPool my_pool(pool);
}
int main()
{
move_pool(make_pool());
}
结果:
copy big memory pool.
move big memory pool.
call move_pool
copy big memory pool.
在上面的代码中,move_pool函数的实参是make_pool函数返回的临
时对象,也是一个右值,move_pool的形参是一个右值引用,但是在使
用形参pool构造my_pool的时候还是会调用复制构造函数而非移动构造
函数。为了让my_pool调用移动构造函数进行构造,需要将形参pool强
制转换为右值:
void move_pool(BigMemoryPool &&pool)
{
std::cout << "call move_pool" << std::endl;
BigMemoryPool my_pool(static_cast<BigMemoryPool&&>(pool));
}
请注意,在这个场景下强制转换为右值就没有任何问题了,因为
move_pool函数的实参是make_pool返回的临时对象,当函数调用结束后
临时对象就会被销毁,所以转移其内存数据不会存在任何问题。
在C++11的标准库中还提供了一个函数模板std::move帮助我们将左
值转换为右值,这个函数内部也是用static_cast做类型转换。只不过由于
它是使用模板实现的函数,因此会根据传参类型自动推导返回类型,省
去了指定转换类型的代码。另一方面从移动语义上来说,使用std::move
函数的描述更加准确。所以建议读者使用std::move将左值转换为右值而
非自己使用static_cast转换,例如:
void move_pool(BigMemoryPool &&pool)
{
std::cout << "call move_pool" << std::endl;
BigMemoryPool my_pool(std::move(pool));
}
8.万能引用和引用折叠
2提到过常量左值引用既可以引用左值又可以引用右值,是一
个几乎万能的引用,但可惜的是由于其常量性,导致它的使用范围受到
一些限制。其实在C++11中确实存在着一个被称为“万能”的引用,它看
似是一个右值引用,但其实有着很大区别,请看下面的代码:
void foo(int &&i) {} // i为右值引用
template<class T>
void bar(T &&t) {} // t为万能引用
int get_val() { return 5; }
int &&x = get_val(); // x为右值引用
auto &&y = get_val(); // y为万能引用
在上面的代码中,函数foo的形参i和变量x是右值引用,而函数模
板的形参t和变量y则是万能引用。我们知道右值引用只能绑定一个右
值,但是万能引用既可以绑定左值也可以绑定右值,甚至const和
volatile的值都可以绑定,例如:
int i = 42;
const int j = 11;
bar(i);
bar(j);
bar(get_val());
auto &&x = i;
auto &&y = j;
auto &&z = get_val();
看到这里读者应该已经发现了其中的奥秘。所谓的万能引用是因为
发生了类型推导,在T&&和auto&&的初始化过程中都会发生类型的推
导,如果已经有一个确定的类型,比如int &&,则是右值引用。在这
个推导过程中,初始化的源对象如果是一个左值,则目标对象会推导出
左值引用;反之如果源对象是一个右值,则会推导出右值引用,不过无
论如何都会是一个引用类型。
万能引用能如此灵活地引用对象,实际上是因为在C++11中添加了
一套引用叠加推导的规则——引用折叠。在这套规则中规定了在不同的
引用类型互相作用的情况下应该如何推导出最终类型,如表6-1所示。
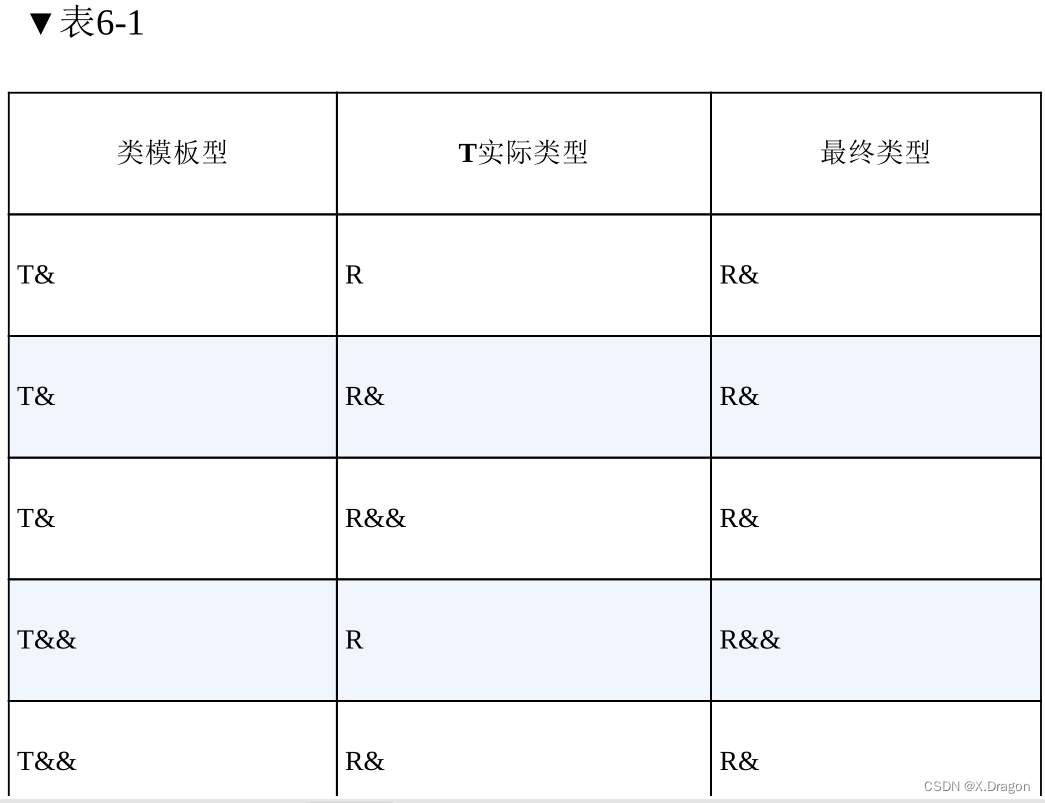

上面的表格显示了引用折叠的推导规则,可以看出在整个推导过程
中,只要有左值引用参与进来,最后推导的结果就是一个左值引用。只
有实际类型是一个非引用类型或者右值引用类型时,最后推导出来的才
是一个右值引用。那么这个规则是如何在万能引用中体现的呢?让我们
以函数模板bar为例看一下具体的推导过程。
在bar(i);中i是一个左值,所以T的推导类型结果是int&,根据引
用折叠规则int& &&的最终推导类型为int&,于是bar函数的形参是一
个左值引用。而在bar(get_val());中get_val返回的是一个右值,所
以T的推导类型为非引用类型int,于是最终的推导类型是int&&,bar
函数的形参成为一个右值引用。
值得一提的是,万能引用的形式必须是T&&或者auto&&,也就是说
它们必须在初始化的时候被直接推导出来,如果在推导中出现中间过
程,则不是一个万能引用,例如:
#include <vector>
template<class T>
void foo(std::vector<T> &&t) {}
int main()
{
std::vector<int> v{ 1,2,3 };
foo(v); // 编译错误
}
在上面的代码中,foo(v)无法编译通过,因为foo的形参t并不是
一个万能引用,而是一个右值引用。因为foo的形参类型
是std::vector&&而不是T&&,所以编译器无法将其看作一个万能
引用处理。
9.完美转发
8节介绍了万能引用的语法和推导规则,但没有提到它的用途。
现在是时候讨论这个问题了,万能引用最典型的用途被称为完美转发。
在介绍完美转发之前,我们先看一个常规的转发函数模板:
#include <iostream>
#include <string>
template<class T>
void show_type(T t)
{
std::cout << typeid(t).name() << std::endl;
}
template<class T>
void normal_forwarding(T t)
{
show_type(t);
}
int main()
{
std::string s = "hello world";
normal_forwarding(s);
}
在上面的代码中,函数normal_forwarding是一个常规的转发函
数模板,它可以完成字符串的转发任务。但是它的效率却令人堪忧。因
为normal_forwarding按值转发,也就是说std::string在转发过程
中会额外发生一次临时对象的复制。其中一个解决办法是将void
normal_forwarding(T t)替换为void normal_ forwarding(T
&t),这样就能避免临时对象的复制。不过这样会带来另外一个问题,
如果传递过来的是一个右值,则该代码无法通过编译,例如:
std::string get_string()
{
return "hi world";
}
normal_forwarding(get_string()); // 编译失败
当然,我们还可以将void normal_forwarding(T &t)替换
为void normal_forwarding (const T &t)来解决这个问题,因为
常量左值引用是可以引用右值的。但是我们也知道,虽然常量左值引用
在这个场景下可以“完美”地转发字符串,但是如果在后续的函数中需要
修改该字符串,则会编译错误。所以这些方法都不能称得上是完美转
发。
万能引用的出现改变了这个尴尬的局面。上文提到过,对于万能引
用的形参来说,如果实参是给左值,则形参被推导为左值引用;反之如
果实参是一个右值,则形参被推导为右值引用,所以下面的代码无论传
递的是左值还是右值都可以被转发,而且不会发生多余的临时复制:
#include <iostream>
#include <string>
template<class T>
void show_type(T t)
{
std::cout << typeid(t).name() << std::endl;
}
template<class T>
void perfect_forwarding(T &&t)
{
show_type(static_cast<T&&>(t));
}
std::string get_string()
{
return "hi world";
}
int main()
{
std::string s = "hello world";
perfect_forwarding(s);
perfect_forwarding(get_string());
}
如果已经理解了引用折叠规则,那么上面的代码就很容易理解了。
唯一可能需要注意的是show_type(static_cast<T&&>(t));中的类型
转换,之所以这里需要用到类型转换,是因为作为形参的t是左值。为
了让转发将左右值的属性也带到目标函数中,这里需要进行类型转换。
当实参是一个左值时,T被推导为std::string&,于
是static_cast<T&&>被推导为static_cast<std:: string&>,传递
到show_type函数时继续保持着左值引用的属性;当实参是一个右值
时,T被推导为std::string,于是static_cast <T&&>被推导
为static_caststd::string&&,所以传递到show_type函数时保
持了右值引用的属性。
和移动语义的情况一样,显式使用static_cast类型转换进行转发
不是一个便捷的方法。在C++11的标准库中提供了一个std::forward
函数模板,在函数内部也是使用static_cast进行类型转换,只不过使
用std::forward转发语义会表达得更加清晰,std::forward函数模板
的使用方法也很简单:
template<class T>
void perfect_forwarding(T &&t)
{
show_type(std::forward<T>(t));
}
请注意std::move和std::forward的区别,其中std::move一定
会将实参转换为一个右值引用,并且使用std::move不需要指定模板实
参,模板实参是由函数调用推导出来的。而std::forward会根据左值
和右值的实际情况进行转发,在使用的时候需要指定模板实参。
10.针对局部变量和右值引用的隐士类型转换
在对旧程序代码升级新编译环境之后,我们可能会发现程序运行的
效率提高了,这里的原因一定少不了新标准的编译器在某些情况下将隐
式复制修改为隐式移动。虽然这些是编译器“偷偷”完成的,但是我们不
能因为运行效率提高就忽略其中的缘由,所以接下来我们要弄清楚这些
隐式移动是怎么发生的:
#include <iostream>
struct X {
X() = default;
X(const X&) = default;
X(X&&) {
std::cout << "move ctor";
}
};
X f(X x) {
return x;
}
int main() {
X r = f(X{});
}
这段代码很容易理解,函数f直接返回调用者传进来的实参x,
在main函数中使用r接收f函数的返回值。关键问题是,这个赋值操作
究竟是如何进行的。从代码上看,将r赋值为x应该是一个复制,对于旧
时的标准这是没错的。但是对于支持移动语义的新标准,这个地方会隐
式地采用移动构造函数来完成数据的交换。编译运行以上代码最终会显
示move ctor字符串。
除此之外,对于局部变量也有相似的规则,只不过大多数时候编译
器会采用更加高效的返回值优化代替移动操作,这里我们稍微修改一点
f函数:
X f() {
X x;
return x;
}
int main() {
X r = f();
}
请注意,编译以上代码的时候需要使用-fno-elide-
constructors选项用于关闭返回值优化。然后运行编译好的程序,会
发现X r = f();同样调用的是移动构造函数。
在C++20标准中,隐式移动操作针对右值引用和throw的情况进行
了扩展,例如:
#include <iostream>
#include <string>
struct X {
X() = default;
X(const X&) = default;
X(X&&) {
std::cout << "move";
}
};
X f(X &&x) {
return x;
}
int main() {
X r = f(X{});
}
以上代码使用C++20之前的标准编译是不会调用任何移动构造函数
的。原因前面也解释过,因为函数f的形参x是一个左值,对于左值要调
用复制构造函数。要实现移动语义,需要将return x;修改为return
std::move(x);。显然这里是有优化空间的,C++20标准规定在这种情
况下可以隐式采用移动语义完成赋值。具体规则如下。
可隐式移动的对象必须是一个非易失或一个右值引用的非易失自动
存储对象,在以下情况下可以使用移动代替复制。
1.return或者co_return语句中的返回对象是函数或者lambda表
达式中的对象或形参。
2.throw语句中抛出的对象是函数或try代码块中的对象。
实际上throw调用移动构造的情况和return差不多,我们只需要将
上面的代码稍作修改即可:
void f() {
X x;
throw x;
}
int main() {
try {
f();
}
catch (…) {
}
}
可以看到函数f不再有返回值,它通过throw抛出x,main函数
用try-catch捕获f抛出的x。这个捕获调用的就是移动构造函数。
11.总结
右值引用是C++11标准提出的一个非常重要的概念,它的出现不仅
完善了C++的语法,改善了C++在数据转移时的执行效率,同时还增强
了C++模板的能力。如果要在C++11提出的所有特性中选择一个对
C++影响最深远的特性,我会毫不犹豫地选择右值引用。
随着C++引入右值引用以及与之相关的移动语义和完美转发,
C++的语义变得更加丰富和合理,与此同时它的性能也有了更大的优化
空间。对于这些优化空间,C++委员会已经对标准库进行了优化,比如
常用的容器vector、list和map等均已支持移动构造函数和移动赋值运
算符函数。另外,如make_pair、make_tuple以及make_shared等也
都使用完美转发以提高程序的性能。对于我们而言,也应该灵活运用右
值引用,避免在程序里出现无谓的复制,提高程序的运行效率。
本文来自谢丙堃老师的《现代C++语言核心特性解析》一书,书中还介绍了大量C++语言核心特性,非常推荐大家去读一读,本文仅供学习使用,如有侵权,联系删帖。