基本概述
Redis是一个键值型(Key-Value Pair)的数据库,可以根据键实现快速的增删改查。而键与值的映射关系正是通过Dict来实现的。
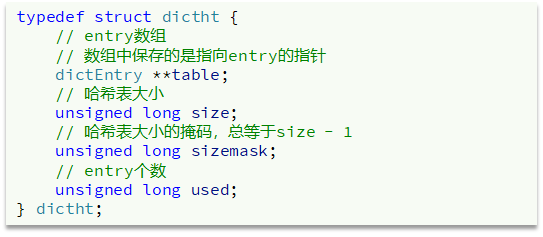
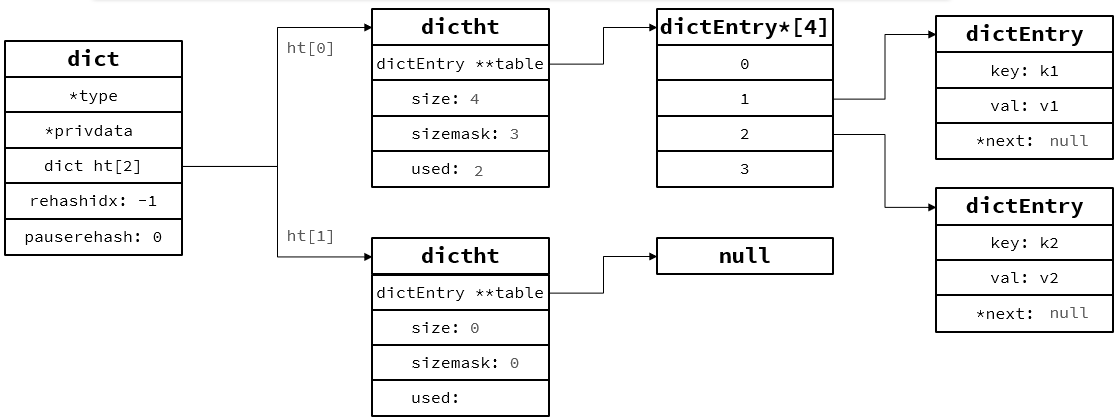
Dict由三部分组成,分别是:哈希表(DictHashTable)、哈希节点(DictEntry)、字典(Dict)
哈希表:
哈希节点:

size大小只能是 2^n
sizemark一定要是 2^n - 1,才会有如下效果
与sizemark与运算实际上与 size求余效果一样(hash运算)
向Dict添加键值对时,Redis首先
根据key计算出hash值(h),然后利用 h & sizemask来计算元素应该存储到数组中的哪个索引位置。
例如:存储k1=v1,假设k1的哈希值h = 1,则1 & 3 = 1,因此k1 = v1要存储到数组角标1位置。

(size默认大小是4)
假设k2哈希值也是1,相同hash值节点,拉链法(加在队首)

字典:

Dict的扩容
Dict中的HashTable就是数组结合单向链表的实现,当集合中元素较多时,必然导致哈希冲突增多,链表过长,则查询效率会大大降低。
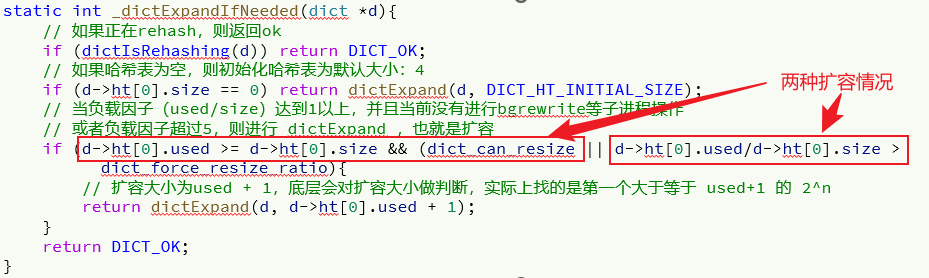
Dict在每次新增键值对时都会检查负载因子(LoadFactor = used/size) ,满足以下两种情况时会触发哈希表扩容:
- 哈希表的 LoadFactor >= 1,并且服务器没有执行 BGSAVE 或者 BGREWRITEAOF 等后台进程(消耗CPU,负载因子不是很大,可以忍忍);
- 哈希表的 LoadFactor > 5(负载因此过大,忍无可忍);
Dict的收缩
Dict除了扩容以外,每次删除元素时,也会对负载因子做检查,当LoadFactor < 0.1 时,会做哈希表收缩:


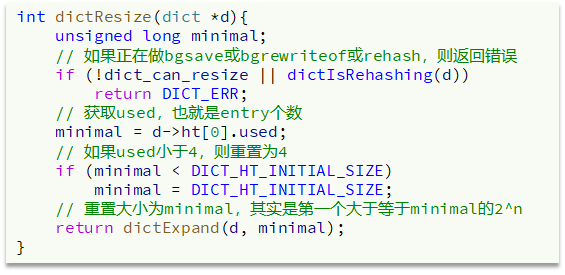
Dict的rehash
不管是扩容还是收缩,必定会创建新的哈希表,导致哈希表的size和sizemask变化,而key的查询与sizemask有关。因此必须对哈希表中的每一个key重新计算索引,插入新的哈希表,这个过程称为rehash。
过程是这样的:
① 计算新hash表的realeSize,值取决于当前要做的是扩容还是收缩:
- 如果是扩容,则新size为第一个大于等于dict.ht[0].used + 1的2^n
- 如果是收缩,则新size为第一个大于等于dict.ht[0].used的2^n (不得小于4)
② 按照新的realeSize申请内存空间,创建dictht,并赋值给dict.ht[1]
③ 设置dict.rehashidx = 0,标示开始rehash
④ 将dict.ht[0]中的每一个dictEntry都rehash到dict.ht[1]
⑤ 将dict.ht[1]赋值给dict.ht[0],给dict.ht[1]初始化为空哈希表,释放原来的dict.ht[0]的内存
无论是扩容还是收缩,都会调用dictExpand(),最终调用_dictExpand()
/* Expand or create the hash table,
* when malloc_failed is non-NULL, it'll avoid panic if malloc fails (in which case it'll be set to 1).
* Returns DICT_OK if expand was performed, and DICT_ERR if skipped. */
int _dictExpand(dict *d, unsigned long size, int* malloc_failed)
{
if (malloc_failed) *malloc_failed = 0;
// 如果正在rehash,或者dict节点个数大于扩展数量,直接返回错误
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
// 创建一个新的哈希表
dictht n; /* the new hash table */
unsigned long realsize = _dictNextPower(size); // 计算出满足条件的 2^n 扩展个数
// 健壮性判断
if (realsize < size || realsize * sizeof(dictEntry*) < realsize)
return DICT_ERR;
if (realsize == d->ht[0].size) return DICT_ERR;
// 新哈希表赋值
n.size = realsize;
n.sizemask = realsize-1;
if (malloc_failed) {
n.table = ztrycalloc(realsize*sizeof(dictEntry*));
*malloc_failed = n.table == NULL;
if (*malloc_failed)
return DICT_ERR;
} else
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys. */
// 第一次初始化,无需rehash,直接初始化第一个哈希表,直接结束
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
/* Prepare a second hash table for incremental rehashing */
// 不是第一次初始化,准备第二个rehash所需的哈希表
d->ht[1] = n;
// 置为0,标识开始rehash
d->rehashidx = 0;
return DICT_OK;
}
实际上,redis的rehash流程不是逐个节点都rehash到dict.ht[1],假设节点个数成千上万这个过程是比较耗时的,不是特别高效
Dict的渐进式rehash
Dict的rehash并不是一次性完成的。试想,如果Dict中包含数百万的entry,要在一次rehash完成,极有可能导致主线程阻塞。因此Dict的rehash是分多次、渐进式的完成,因此称为渐进式rehash。
实际完整流程如下:
① 计算新hash表的size,值取决于当前要做的是扩容还是收缩:
- 如果是扩容,则新size为第一个大于等于dict.ht[0].used + 1的2^n
- 如果是收缩,则新size为第一个大于等于dict.ht[0].used的2^n (不得小于4)
② 按照新的size申请内存空间,创建dictht,并赋值给dict.ht[1]
③ 设置dict.rehashidx = 0,标示开始rehash
④ 将dict.ht[0]中的每一个dictEntry都rehash到dict.ht[1]
④每次执行新增、查询、修改、删除操作时,都检查一下dict.rehashidx是否大于-1,如果是则将dict.ht[0].table[rehashidx]的entry链表rehash到dict.ht[1],并且将rehashidx++。直至dict.ht[0]的所有数据都rehash到dict.ht[1]
⑤ 将dict.ht[1]赋值给dict.ht[0],给dict.ht[1]初始化为空哈希表,释放原来的dict.ht[0]的内存【每次操作(增删改查),rehash只操作数组一个角标上的元素,直至所有元素迁移完成,重置两个dictht】
⑥ 将rehashidx赋值为-1,代表rehash结束
⑦ 在rehash过程中,新增操作,则直接写入ht[1],查询、修改和删除则会在dict.ht[0]和dict.ht[1]依次查找并执行。这样可以确保ht[0]的数据只减不增,随着rehash最终为空
小结
Dict的结构:
- 类似java的HashTable,底层是
数组加链表来解决哈希冲突 Dict包含两个哈希表,ht[0]平常用,ht[1]用来rehash
Dict的伸缩:
- 当
LoadFactor大于5或者LoadFactor大于1并且没有子进程任务时,Dict扩容 - 当
LoadFactor小于0.1并且哈希表大小大于初始值4时,Dict收缩 - 扩容大小为第一个大于等于used + 1的2^n
- 收缩大小为第一个大于等于used 的2^n
- Dict采用
渐进式rehash,每次访问Dict时执行一次rehash,直至所有元素rehash完毕 rehash时ht[0]只减不增,新增操作只在ht[1]执行,其它操作在两个哈希表