前言
上一篇博文我们介绍了Focal Loss,原理也比较简单,有不了解的小伙伴可以先跳转到之前的博文了解一下。Focal Loss介绍。这篇博文我们来看下Focal Loss的出处:Focal Loss for Dense Object Detection,这篇论文提出了RetainNet之后one-stage网络的受此超越了two-stage的网络。
一. RetainNet网路
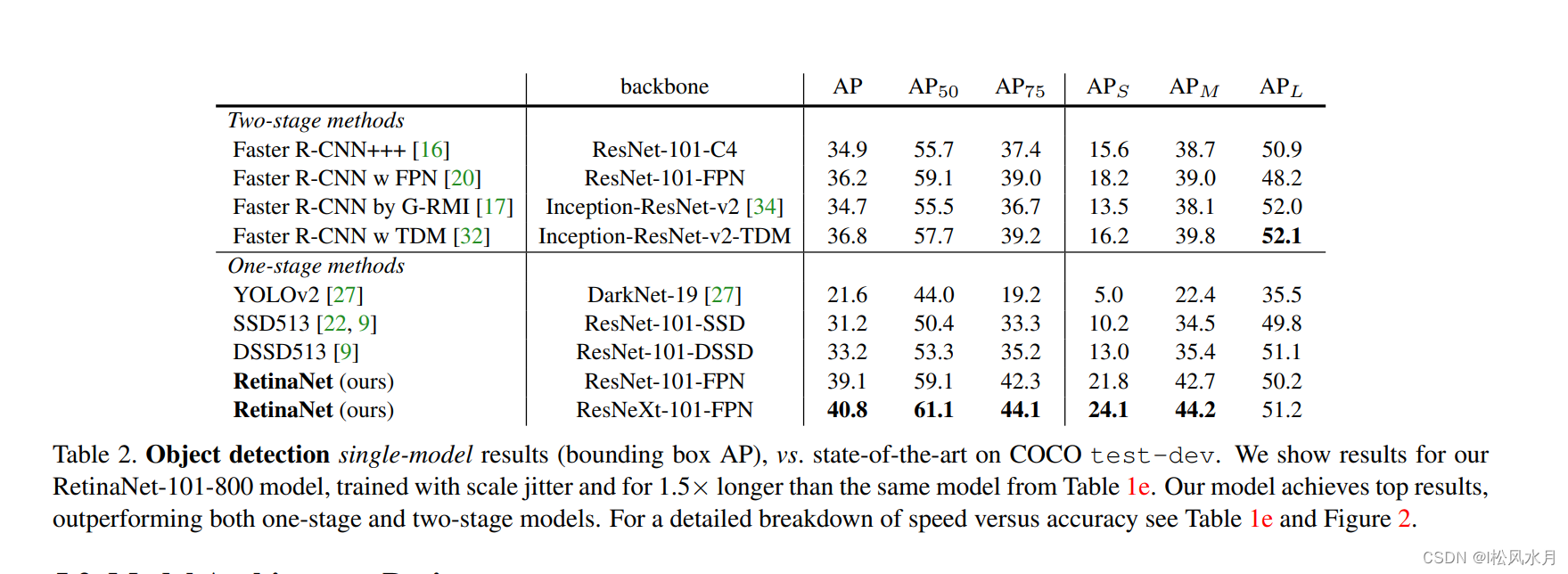
先来看下RetainNet的性能,可以看到远超Faster R-CNN网络。
我们再来看下RetainNet的网络结构:

可以看到RetainNet也采用了类似FPN的结构,主要有三个不同之处,关于FPN不了解的小伙伴可以跳转到我之前的博文(FPN网络介绍):
FPN会使用C2生成P2,RetainNet并没有使用C2生成P2。论文给的理由是C2会计算更多的计算资源。因为C2四低层特征,分辨率比较大。FPN中的P6是通过一个最大尺化下采样层进行一个下采样的,RetainNet是通过一个卷积层进行下采样的。FPN是从P2-P6,RetainNet是从P3-P7,P7是在P6的基础上通过一个激活函数ReLU,然后在通过一个卷积得到。
在FPN中,每个预测特征层都只是用了一个scale和三个ratios,RetainNet中每个预测特征层都是用了三个scale和三个ratios。RetainNet中的scale和ratios如下表:
| 层数 | stride | anchor_sizes | anchor_aspect_ratios | 生成的anchor个数,(乘以3是表示3种比例) |
|---|---|---|---|---|
| P2 | 4(2(^)2) | 32 | 0.5,1,2 | (1024//4)(^)2xx3=196608 |
| P3 | 8(2(^)3) | 64 | 0.5,1,2 | (1024//8)(^)2xx3=49152 |
| P4 | 16(2(^)4) | 128 | 0.5,1,2 | (1024//16)^^2xx3=12288 |
| P5 | 32(2(^)5) | 256 | 0.5,1,2 | (1024//32)(^)2xx3=3072 |
| P6 | 64(2(^)6) | 512 | 0.5,1,2 | (1024//64)(^)2xx3=768 |
再来看下RetainNet的预测器部分:
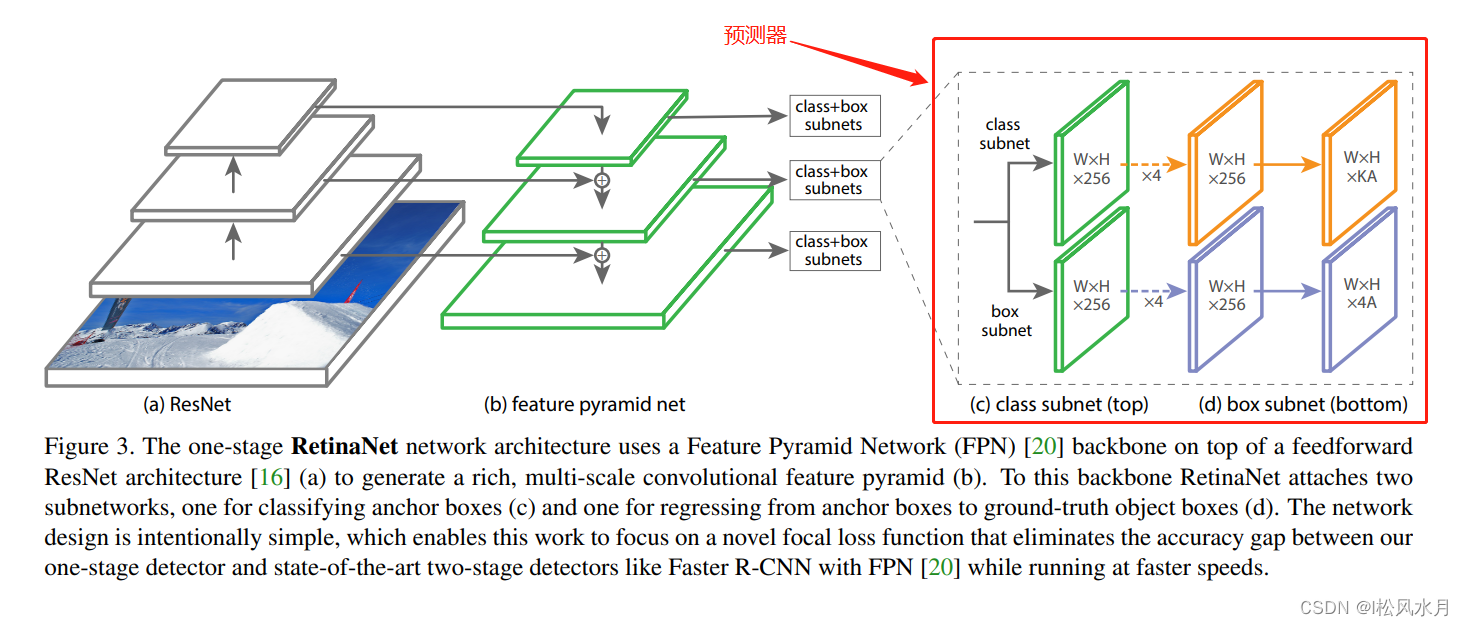
预测器分为两个分支,一个预测类别,一个是目标边界框回归参数。最后输出的K表示检测目标的类别个数(不含背景),A表示每个预测特征层上的anchor的个数。在FasterRCNN中是对于预测特在层上每一个anchor都会针对每个类别去生成 一组边界框回归参数,跟这里预测稍微有所不同,这里跟SSD是一样的,现在采样的基本上都是这种类别不可知的预测方式,能够减少网络训练参数。
二. 损失计算
首先我们会针对我们每一个anchor与我们事先标注好的gt进行一个匹配, 即计算iou,规则如下:
- 如果 i o u > = 0.5 iou>=0.5 iou>=0.5,标记为正样本
- i o u < = 0.4 iou<=0.4 iou<=0.4,标记为负样本
- i o u ∈ [ 0.4 , 0.5 ) iou \in[0.4, 0.5) iou∈[0.4,0.5),舍弃
总损失使用的还是分类损失和回归损失,如下所示:
Loss
=
1
N
P
O
S
∑
i
L
c
l
s
i
+
1
N
P
O
S
∑
j
L
r
e
g
j
\text { Loss } =\frac{1}{N_{P O S}} \sum_i L_{c l s}^i+\frac{1}{N_{P O S}} \sum_j L_{r e g}^j
Loss =NPOS1i∑Lclsi+NPOS1j∑Lregj
- L c l s L_{cls} Lcls:Sigmoid Focal Loss,上一篇博文我们介绍过了,不懂的小伙伴可以回到前面看看:Focal Loss介绍。
- L r e g L_{reg} Lreg:L1 Loss
- i i i:所有的正负样本
- j j j:所有的正样本
- N p o s N_{pos} Npos:正样本的个数
以上就是关于RetainNet网络的介绍,如有错误,敬请指正!