MPU(Memory Protection Unit)是ARM处理器中的一个特性,它提供了内存保护和访问控制的功能,通常用于实现操作系统的内存隔离和保护。比如我们可以设置所有的RAM为不可执行,这样就可以避免代码注入攻击。最近做项目过程中,使用的几个Cortex核都用到了MPU,我发现MPU不仅仅起到一个内存保护的作用,它还和Cache有关,还能加快外接存储设备的访问速度。所以这篇文章就来详细地介绍一下MPU。
文章目录
- 1 MPU特点
- 2 内存类型
- 3 内存属性
- 4 I.MX RT1170的MPU配置例子
这里以Cortex-M7系列内核为例对MPU进行介绍,实际上Cortex-M核在MPU方面基本上都一样,除了Cortex-M33,它取消了子区域和可重叠的特性,因为它能自定义每个区域大小,更加灵活。
1 MPU特点
MPU允许一个进程访问16个内存或外设区域(0~15),每个区域的位置和大小(必须是2^n,且大于32字节)是可配置的。
- 每一个区域都可以进一步被划分为最多8个子区域,每个子区域的大小至少为32字节,这是由缓存行长度决定的
- 除了16个区域外,还有一个编号为-1的默认区域,它的优先级是最低的
- 这些区域可以重叠,也可以嵌套。区域15的优先级最高,区域0的优先级最低,这决定了区域重叠的行为。
来看一个例子:
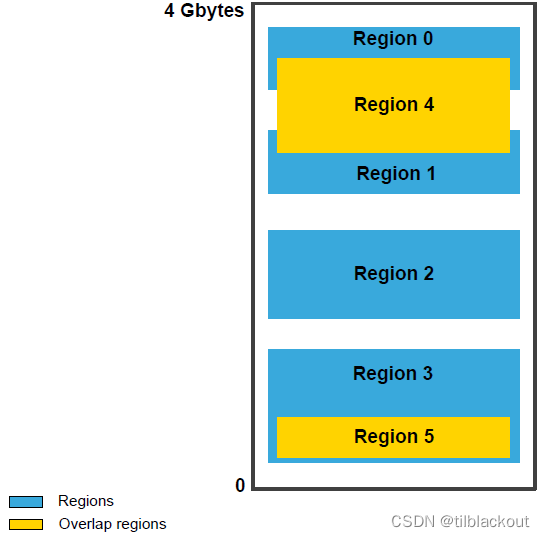
上图显示了一个包含六个区域的示例。区域4与区域0和1重叠,区域5包含于区域3。由于优先级按升序排列,重叠区域(橙色)具有优先级。因此,如果区域0是可写的,而区域4是不可写的,那么位于0和4之间重叠的地址是不可写的。
- MPU对于指令和数据的访问权限并没有做区分,而是使用相同的区域来控制对数据和指令的访问。
- MPU还能定义其它内存属性,如一个区域的可缓存性,这些属性都会传递给系统的Cache单元或内存控制器。
- ARM架构支持两级Cache:内部Cache(
L1-Cache)和外部Cache(L2-Cache)。其中L1缓存位于处理器核心附近,距离处理器最近,提供最快的访问速度。L2缓存位于L1缓存之外,相对于处理器来说较远,但仍然比主存更快,提供较大的容量。
- ARM架构支持两级Cache:内部Cache(
2 内存类型
一般有三种常见的内存类型:
1、Normal Memory:允许CPU以高效的方式对字节、半字和字进行加载和存储操作(编译器不知道内存区域类型)。对于普通内存区域,加载和存储的顺序不一定按照程序中列出的顺序执行。
2、Device Memory:加载和存储操作严格按照顺序执行,以确保寄存器按照正确的顺序进行设置。
3、Strongly Ordered Memory:一切操作都严格按照程序中列出的顺序执行,CPU会等待加载/存储指令执行完成后才执行程序流中的下一条指令。这会导致性能下降。
3 内存属性
MPU的区域属性和大小寄存器MPU_RASR(Region Attribute and Size Register)用来设置所有内存属性,寄存器各个字段的功能如下表所示:
| bits | Name | Description |
|---|---|---|
| 28 | XN | Execute never |
| 26:24 | AP | Data access permission field (RO, RW, or No access) |
| 21:19 | TEX | Type extension field |
| 18 | S | Shareable |
| 17 | C | Cacheable |
| 16 | B | Bufferable |
| 15:8 | SRD | Subregion disabled. 1 = disabled, 0 = enabled |
| 5:1 | SIZE | the size of the MPU protection region |
(1)XN:控制代码的执行。当XN=1时,访问对应的内存区域将产生MemManage Fault。
(2)AP:控制内存区域的访问权限,如下表所示
| AP[2:0] | Privileged permissions | Unprivileged permissions | Description |
|---|---|---|---|
| 000 | No access | No access | All accesses generate a permission fault |
| 001 | RW | No access | Access from a privileged software only |
| 010 | RW | RO | Written by an unprivileged software generates a permission fault |
| 011 | RW | RW | Full access |
| 100 | Unpredictable | Unpredictable | Reserved |
| 101 | RO | No access | Read by a privileged software only |
| 110 | RO | RO | Read only, by privileged or unprivileged software |
| 111 | RO | RO | Read only, by privileged or unprivileged software |
(3)S:指示内存区域是否可共享。如果一个区域是可共享的,那么多个总线主控可以同时访问它,并且系统会提供数据同步机制。然而,如果一个区域是不可共享的,则需要软件来控制多个总线访问数据的一致性。
- 对于有的芯片来说,不支持硬件层的数据同步机制,
S就用来指示该区域是否为non-cacheable
(4)TEX,C,B:这三个字段定义内存区域的缓存属性,并能在一定程度上确定其可共享性(S字段)
| TEX | C | B | Memory type | Description | Shareable |
|---|---|---|---|---|---|
| 000 | 0 | 0 | Strongly ordered | Strongly ordered | Yes |
| 000 | 0 | 1 | Device | Shared device | Yes |
| 000 | 1 | 0 | Normal | Write through, no write allocate | S bit |
| 000 | 1 | 1 | Normal | Write-back, no write allocate | S bit |
| 001 | 0 | 0 | Normal | Non-cacheable | S bit |
| 001 | 0 | 1 | Reserved | Reserved | Reserved |
| 001 | 1 | 0 | Undefined | Undefined | Undefined |
| 001 | 1 | 1 | Normal | Write-back, write and read allocate | S bit |
| 010 | 0 | 0 | Device | Non-shareable device | No |
| 010 | 0 | 1 | Reserved | Reserved | Reserved |
Bufferable和Cacheable的不同?Bufferable主要关注内存访问的读写效率,用于预取数据或者根据其缓冲策略决定何时将数据写回内存。而Cacheable属性则主要关注数据的访问速度,允许处理器将数据存储在高速缓存中以加快访问。Write through with no write allocate:在命中(缓存中存在所需数据)时,将数据写入缓存和主存。在未命中时,它只更新主存中的块,而写入缓存。Write-back with no write allocate:当处理器执行写操作时,如果数据已经在缓存中,则只更新缓存中的数据,而不立即写回主存。只有在需要替换缓存中的数据时,才将最新的数据写回主存。Write-back with write and read allocate:当处理器执行写操作时,如果数据已经在缓存中,则更新缓存中的数据并写到主存。当处理器执行读操作时,数据在缓存中不存在,它会将整个块从主存读取到缓存中
(5)SRD:标志特定子区域的启用或禁用状态。如果禁用了某个子区域,那么在该子区域范围内的访问将会被其他启用的区域所重叠覆盖。如果没有其他启用的区域与禁用的子区域重叠,则MPU会产生一个错误,表示该访问是非法的或不允许的。
Cortex-M7注意事项:
(1)TCM(Tightly Coupled Memories,紧耦合内存)始终被视为不可缓存、不共享的普通内存,而不管MPU为TCM中的内存区域定义了什么样的内存类型属性。
(2)speculative prefetch
预取是处理器的一种优化技术,用于提前从主存中将数据加载到处理器的缓存中,以便在需要时可以更快地访问。然而,由于处理器无法事先准确地知道哪些数据将被实际使用,预取操作有时可能会带来不必要的开销。这会对一些对多次访问敏感的存储器或设备产生影响,如FIFO、LCD控制器等。同时,它可能会占用其它主设备的带宽,如LCD、DMA。
为了避免不必要的预取带来的性能损失,Cortex-M7处理器引入了constraint speculative prefetch的约束。这意味着在某些情况下,处理器会对预取操作进行限制,而不会执行预取操作,比如通过MPU的内存属性将内存类型改为Device Memory或Strongly Ordered Memory。
4 I.MX RT1170的MPU配置例子
对于I.MX RT1170的Cortex-M7核来说来说,我们可以采用以下宏定义ARM_MPU_RBAR和ARM_MPU_RASR配置一个MPU区域:
* \param Region The region to be configured, number 0 to 15.
* \param BaseAddress The base address for the region.
MPU->RBAR = ARM_MPU_RBAR(Region, BaseAddress);
* \param DisableExec Instruction access disable bit, 1= disable instruction fetches.
* \param AccessPermission Data access permissions, allows you to configure read/write access for User and Privileged mode.
* \param TypeExtField Type extension field, allows you to configure memory access type, for example strongly ordered, peripheral.
* \param IsShareable Region is shareable between multiple bus masters.
* \param IsCacheable Region is cacheable, i.e. its value may be kept in cache.
* \param IsBufferable Region is bufferable, i.e. using write-back caching. Cacheable but non-bufferable regions use write-through policy.
* \param SubRegionDisable Sub-region disable field.
* \param Size Region size of the region to be configured, for example 4K, 8K.
MPU->RASR = ARM_MPU_RASR((DisableExec, AccessPermission, TypeExtField, IsShareable, IsCacheable, IsBufferable, SubRegionDisable, Size));
RT1170中默认的MPU配置篇幅很长,我也省略了一部分,因为有的内存的配置是一样的。另外对于Cache相关段的初始化我也省略了,这个在后续我会写一篇关于ICache和DCache的文章进行分析。如下所示为RT1170中默认的MPU配置代码:
- 区域的基地址必须对齐到区域大小的整数倍
/* Region 0 setting: Instruction access disabled, No data access permission. */
MPU->RBAR = ARM_MPU_RBAR(0, 0x00000000U);
MPU->RASR = ARM_MPU_RASR(1, ARM_MPU_AP_NONE, 0, 0, 0, 0, 0, ARM_MPU_REGION_SIZE_4GB);
/* Region 1 setting: Memory with Device type, not shareable, non-cacheable. */
MPU->RBAR = ARM_MPU_RBAR(1, 0x80000000U);
MPU->RASR = ARM_MPU_RASR(0, ARM_MPU_AP_FULL, 2, 0, 0, 0, 0, ARM_MPU_REGION_SIZE_512MB);
/* Region 3 setting: Memory with Device type, not shareable, non-cacheable. */
MPU->RBAR = ARM_MPU_RBAR(3, 0x00000000U);
MPU->RASR = ARM_MPU_RASR(0, ARM_MPU_AP_FULL, 2, 0, 0, 0, 0, ARM_MPU_REGION_SIZE_1GB);
/* Region 4 setting: Memory with Normal type, not shareable, outer/inner write back */
MPU->RBAR = ARM_MPU_RBAR(4, 0x00000000U);
MPU->RASR = ARM_MPU_RASR(0, ARM_MPU_AP_FULL, 0, 0, 1, 1, 0, ARM_MPU_REGION_SIZE_256KB);
/* Region 8 setting: Memory with Normal type, not shareable, outer/inner write back. */
MPU->RBAR = ARM_MPU_RBAR(8, 0x30000000U);
MPU->RASR = ARM_MPU_RASR(0, ARM_MPU_AP_RO, 0, 0, 1, 1, 0, ARM_MPU_REGION_SIZE_16MB);
(1)Region 0:将芯片的整个地址映射,即32位寻址的地址最大范围4G,默认赋值为不可执行和不可访问。这是因为MPU的配置是可以被高优先级的配置所覆盖的,所以这样做的意义是给之后没有配置的内存区域默认赋一个权限
(2)Region 1:这是SDRAM的映射地址,这里将其定义为Device Memory,即non-shareable。表示取消CPU对这段内存预取功能。
(3)Region 3:将0x00000000~0x40000000的内存置为Device Memory,和Region 0一样,也是设定一个默认值
(4)Region 4:这是系统的ITCM的地址,设置Memory类型为Normal Memory。这里设置为non-shareable、cacheable和bufferable,表示使用缓存中的数据,仅当缓存数据被换出时才写入内存中
(5)Region 8:这是NOR Flash的映射地址,和Region 4的配置基本相同,只不过对于NOR Flash来说,使用FlexSPI映射的话,这段内存是只读的。如果需要写NOR Flash则需要调用FlexSPI的xfer函数产生相关的写时序
- 还有配置
AIPS寄存器映射的内存,这里也省略了,实际上也是配置成Device Momory。