SQL常用语句总结
mysql -u root -p
mysql会提示你输入密码,输入安装配置MySQL服务时设置的密码即可。
输入如下命令生成样例数据库:
CREATE DATABASE university;
USE university;
SOURCE <DLL.sql文件路径>;
SOURCE <InsertStatements.sql文件路径>;
好了,现在让我们开始温习SQL语句吧。
数据库
- 查看现有数据库
SHOW DATABASES;
2. 新建数据库
CREATE DATABASE <数据库名>;
3. 选择数据库
USE <数据库名>;
4. 从.sql文件引入SQL语句
SOURCE <.sql文件路径>;
5. 删除数据库
DROP DATABASE <数据库名>;
表
6. 查看当前数据库中的表
SHOW TABLES;
- 创建新表
CREATE TABLE <表名> (
<列名1> <列类型1>,
<列名2> <列类型2>,
<列名3> <列类型3>,
PRIMARY KEY (<列名1>),
FOREIGN KEY (<列名2>) REFERENCES <表名2>(<列名2>)
);
主键(PRIMARY KEY)用来标识一条记录(一行),所以每条记录的主键值必须是唯一的。主键可以定义在多列上,这称为联合主键(composite primary key)。
如果我们把表视作具有某种结构的数组(例如,C语言中的struct),那么外键(FOREIGN KEY)可以视作指针。
例子:
CREATE TABLE instructor (
ID CHAR(5),
name VARCHAR(20) NOT NULL,
dept_name VARCHAR(20),
salary NUMERIC(8,2),
PRIMARY KEY (ID),
FOREIGN KEY (dept_name) REFERENCES department(dept_name));
在上面的例子中,我们创建了一个教员(instructor)表,该表的主键是ID,外键是教员所在的部门名称(dept_name),关联部门(department)表。此外,教员表还包括姓名(name)、薪水(salary)。其中,姓名有约束NOT NULL,表示姓名这一项不能为空。
- 概述表中的列
使用如下语句查看表中的列的基本信息:
DESCRIBE <表名>;
下图显示了一些例子:
- 在表中插入新纪录
INSERT INTO <表名> (<列名1>, <列名2>, <列名3>, …)
VALUES (<值1>, <值2>, <值3>, …);
也可以省略列名(依序在所有列上插入新值):
INSERT INTO <表名>
VALUES (<值1>, <值2>, <值3>, …);
10. 在表中更新记录
UPDATE <表名>
SET <列名1> = <值1>, <列名2> = <值2>, …
WHERE <条件>;
11. 清空表
DELETE FROM <表名>;
12. 删除表
DROP TABLE <表名>;
查询
13. SELECT
SELECT语句可以从表中选择数据:
SELECT <列名1>, <列名2>, …
FROM <表名>;
以下语句选择所有内容:
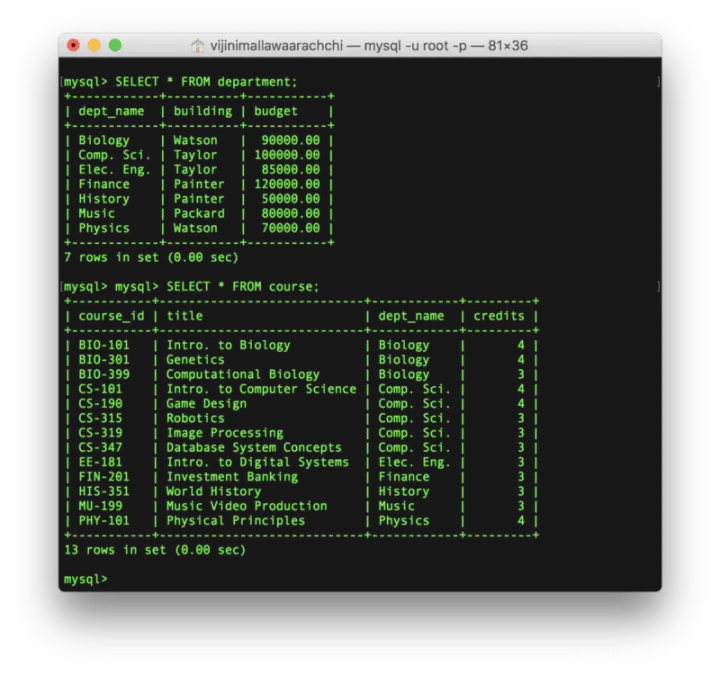
SELECT * FROM <表名>;
选中department表和course表中的所有内容
14. SELECT DISTINCT
SELECT DISTINCT过滤掉了重复的值:
SELECT DISTINCT <列名1>, <列名2>, …
FROM <表名>;
- WHERE
我们之前在更新记录时已经用到了WHERE关键字,用来指明条件。这里我们稍微详细一点地介绍下WHERE。
WHERE的条件通常是:
比较文本(text)
比较数字(numbers)
AND、OR、NOT等逻辑运算
让我们来看一些例子:
SELECT * FROM course WHERE dept_name=‘Comp. Sci.’;
SELECT * FROM course WHERE credits>3;
SELECT * FROM course WHERE dept_name=‘Comp. Sci.’ AND credits>3;
- GROUP BY
GROUP BY语句可以分组结果,常用于COUNT、MAX、MIN、SUM、AVG等聚合函数(aggregate functions)。
SELECT <列名1>, <列名2>, …
FROM <表名>
GROUP BY <列名>;
让我们来看一个例子,列出每个部门的课程数量:
SELECT COUNT(course_id), dept_name
FROM course
GROUP BY dept_name;
- HAVING
乍看起来,HAVING和WHERE很像:
SELECT <列名1>, <列名2>, …
FROM <表名>
GROUP BY <列名x>
HAVING <条件>;
那么,HAVING和WHERE有什么不同呢?让我们先来看一个例子,列出开了不止一门课程的部门开设的课程数:
SELECT COUNT(course_id), dept_name
FROM course
GROUP BY dept_name
HAVING COUNT(course_id)>1;
这里HAVING不能换成WHERE,因为WHERE直接针对行操作,且在GROUP BY之前运行(即先通过WHERE筛选行,之后再将筛选出的行通过GROUP BY分组)。假设SQL中不存在HAVING语句,那么我们只能先新建一张表,将COUNT(course_id)作为新表的列,然后在新表上再通过WHERE进行筛选(当然,实际上SQL提供了派生表、CTE等机制,并不用真的手工建新表)。
- ORDER BY
ORDER BY可以对结果进行排序,在没有明确指定ASC(升序)或DESC(降序)的情况下,默认按升序排列。
SELECT <列名1>, <列名2>, …
FROM <表名>
ORDER BY <列名1>, <列名2>, …, ASC|DESC;
例子:
SELECT * FROM course ORDER BY credits;
SELECT * FROM course ORDER BY credits DESC;
- BETWEEN
BETWEEN语句用于指定区间。
SELECT <列名1>, <列名2>, …
FROM <表名>
WHERE <列名x> BETWEEN <值1> AND <值2>;
其中“值”可能是数字,文本,乃至日期等。
例如,列出薪资在50000和100000之间的教员:
SELECT * FROM instructor
WHERE salary BETWEEN 50000 AND 100000;
- LIKE
LIKE用于匹配文本中的特定模式。
SELECT <列名1>, <列名2>, …
FROM <表名>
WHERE <列名x> LIKE <模式>;
模式中可以使用以下两个通配符:
% (零个、一个或多个字符)
_ (单个字符)
例子:列出课程名中包含“to”的课程,以及课程ID以“CS-”开头的课程。
SELECT * FROM course WHERE title LIKE ‘%to%’;
SELECT * FROM course WHERE course_id LIKE ‘CS-___’;
- IN
IN语句表示值属于某个集合。
SELECT <列名1>, <列名2>, …
FROM <表名>
WHERE <列名n> IN (<值1>, <值2>, …);
例子:列出计算机科学、物理、电子工程部门的学生。
SELECT * FROM student
WHERE dept_name IN (‘Comp. Sci.’, ‘Physics’, ‘Elec. Eng.’);
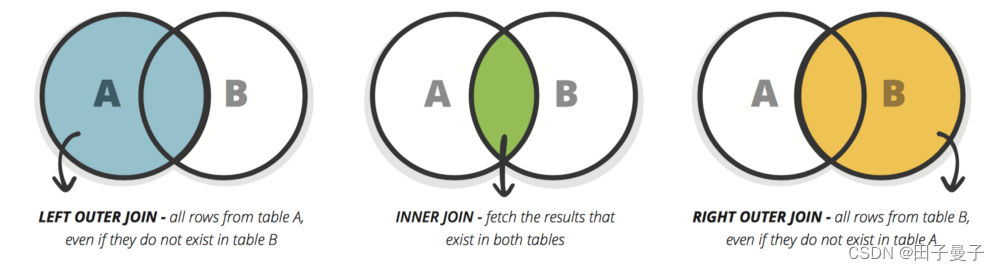
- JOIN
JOIN用来组合两张以上表中的值。下图展示了JOIN的三种类型:
图片来源:zeroturnaround.com
SELECT <列名1>, <列名2>, …
FROM <表名1>
JOIN <表名2>
ON <表名1.列名x> = <表名2.列名x>
让我们来看三个例子,分别对应三种JOIN的类型。
第一个例子,列出课程时包含开设课程的部门详情:
SELECT * FROM course
JOIN department
ON course.dept_name=department.dept_name;
第二个例子,列出所有具有前置课程的课程的详情:
SELECT prereq.course_id, title, dept_name, credits, prereq_id
FROM prereq
LEFT OUTER JOIN course
ON prereq.course_id=course.course_id;
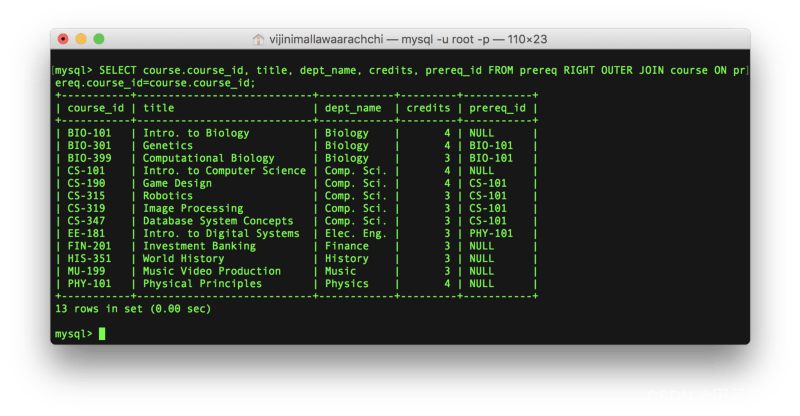
最后一个例子,列出所有课程的详情,不管是否具有前置课程:
SELECT course.course_id, title, dept_name, credits, prereq_id
FROM prereq
RIGHT OUTER JOIN course
ON prereq.course_id=course.course_id;
- 视图
视图(view)是虚拟的SQL表。它包含行和列,和一般的SQL表格很类似。视图总是显示数据库中的最新数据。
CREATE VIEW
创建视图:
CREATE VIEW <视图名> AS
SELECT <列名1>, <列名2>, …
FROM <表名>
WHERE <条件>;
DROP VIEW
删除视图:
DROP VIEW <视图名>;
例如,创建3学分的课程视图:
CREATE VIEW my_view AS
SELECT * FROM course
WHERE credits=3;
- 聚合函数
我们之前已经提到聚合函数,这里列出最常用的一些聚合函数:
COUNT(列名) 返回行数
SUM(列名) 返回指定列的值之和
AVG(列名) 返回指定列的平均值
MIN(列名) 返回指定列的最小值
MAX(列名) 返回指定列的最大值
25. 嵌套子查询
在SQL请求中,可以嵌套SELECT-FROM-WHERE表达式,称为嵌套子查询(nested subqueries)。
例如,查找2009年秋、2010年春都开的课程:
SQL常用语句总结
SQL常用语句总结
论智
论智
352 人赞同了该文章
作者:Vijini Mallawaarachchi
编译:weakish
【编者按】由于大量数据保存在关系数据库中,因此数据科学家难免要和SQL打交道。当然,面试的时候也常常考察SQL。Moratuwa大学生物信息学研究员Vijini Mallawaarachchi总结了常用的SQL语句用法,可供参考和温习。
本文总结了常用的SQL语句,尤其适合在面试前复习你的SQL知识。你可以尝试文中的例子,温习下你很久以前在数据库系统课程上学到的知识。
配置样例数据库
为了演示每个命令的用法,我们将使用一个样例数据库。生成该数据库的脚本可以从Google网盘下载:
DLL.sql: https://drive.google.com/file/d/0B_oq3-doZhC-ME1lUlR3a3pYRU0/view
InsertStatements.sql: https://drive.google.com/file/d/0B_oq3-doZhC-TV9ud1JubkVDaXM/view
如不便访问Google网盘,可以在论智公众号(ID: jqr_AI)留言sql recap获取。
下载文件后,输入以下命令进入MySQL控制台(假设你已经装好了MySQL或MariaDB)。
mysql -u root -p
mysql会提示你输入密码,输入安装配置MySQL服务时设置的密码即可。
输入如下命令生成样例数据库:
CREATE DATABASE university;
USE university;
SOURCE <DLL.sql文件路径>;
SOURCE <InsertStatements.sql文件路径>;
好了,现在让我们开始温习SQL语句吧。
数据库
- 查看现有数据库
SHOW DATABASES;
2. 新建数据库
CREATE DATABASE <数据库名>;
3. 选择数据库
USE <数据库名>;
4. 从.sql文件引入SQL语句
SOURCE <.sql文件路径>;
5. 删除数据库
DROP DATABASE <数据库名>;
表
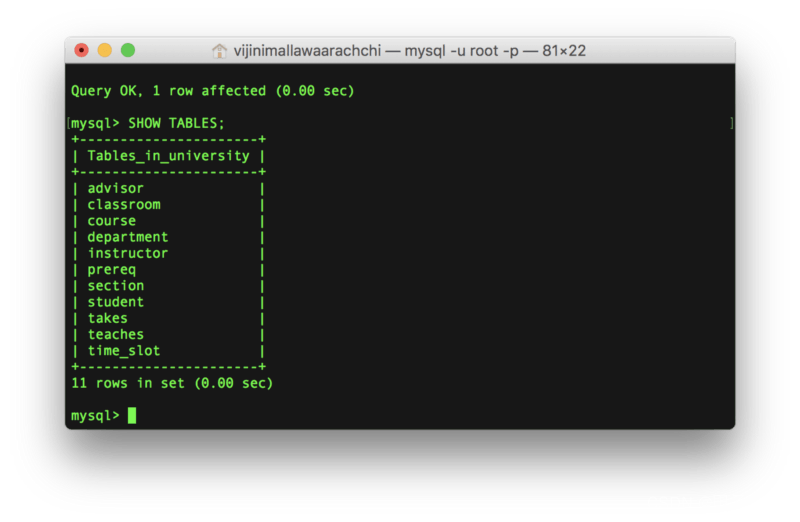
6. 查看当前数据库中的表
SHOW TABLES;
- 创建新表
CREATE TABLE <表名> (
<列名1> <列类型1>,
<列名2> <列类型2>,
<列名3> <列类型3>,
PRIMARY KEY (<列名1>),
FOREIGN KEY (<列名2>) REFERENCES <表名2>(<列名2>)
);
主键(PRIMARY KEY)用来标识一条记录(一行),所以每条记录的主键值必须是唯一的。主键可以定义在多列上,这称为联合主键(composite primary key)。
如果我们把表视作具有某种结构的数组(例如,C语言中的struct),那么外键(FOREIGN KEY)可以视作指针。
例子:
CREATE TABLE instructor (
ID CHAR(5),
name VARCHAR(20) NOT NULL,
dept_name VARCHAR(20),
salary NUMERIC(8,2),
PRIMARY KEY (ID),
FOREIGN KEY (dept_name) REFERENCES department(dept_name));
在上面的例子中,我们创建了一个教员(instructor)表,该表的主键是ID,外键是教员所在的部门名称(dept_name),关联部门(department)表。此外,教员表还包括姓名(name)、薪水(salary)。其中,姓名有约束NOT NULL,表示姓名这一项不能为空。
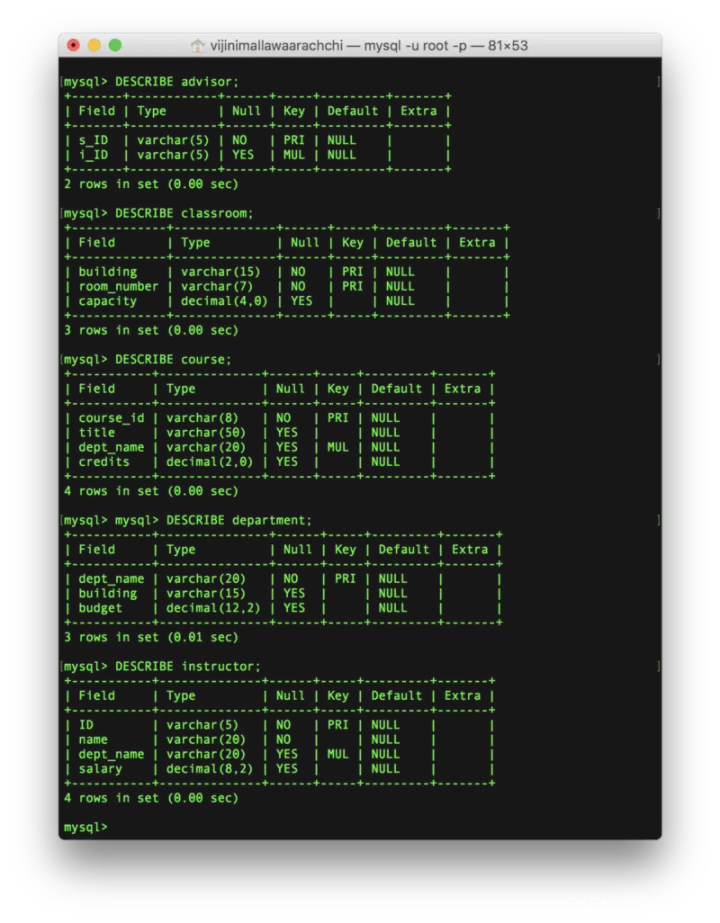
- 概述表中的列
使用如下语句查看表中的列的基本信息:
DESCRIBE <表名>;
下图显示了一些例子:
- 在表中插入新纪录
INSERT INTO <表名> (<列名1>, <列名2>, <列名3>, …)
VALUES (<值1>, <值2>, <值3>, …);
也可以省略列名(依序在所有列上插入新值):
INSERT INTO <表名>
VALUES (<值1>, <值2>, <值3>, …);
10. 在表中更新记录
UPDATE <表名>
SET <列名1> = <值1>, <列名2> = <值2>, …
WHERE <条件>;
11. 清空表
DELETE FROM <表名>;
12. 删除表
DROP TABLE <表名>;
查询
13. SELECT
SELECT语句可以从表中选择数据:
SELECT <列名1>, <列名2>, …
FROM <表名>;
以下语句选择所有内容:
SELECT * FROM <表名>;
- SELECT DISTINCT
SELECT DISTINCT过滤掉了重复的值:
SELECT DISTINCT <列名1>, <列名2>, …
FROM <表名>;

- WHERE
我们之前在更新记录时已经用到了WHERE关键字,用来指明条件。这里我们稍微详细一点地介绍下WHERE。
WHERE的条件通常是:
比较文本(text)
比较数字(numbers)
AND、OR、NOT等逻辑运算
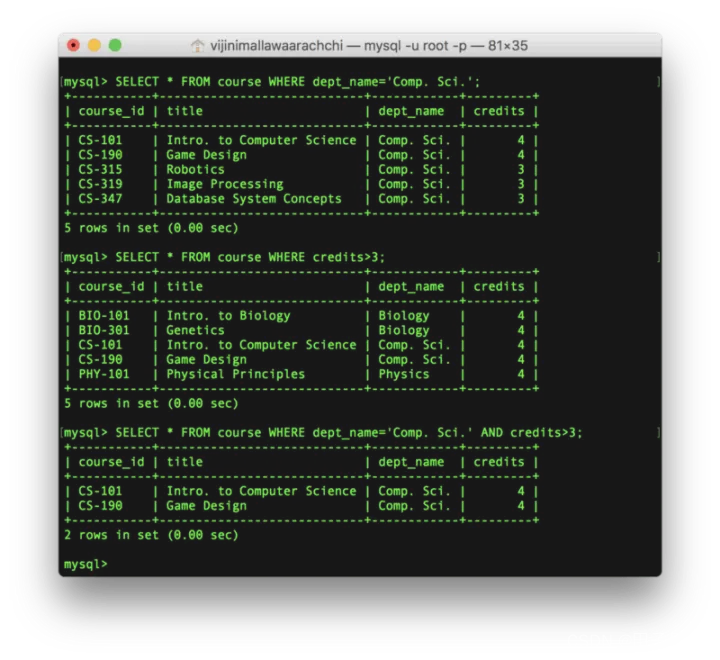
让我们来看一些例子:
SELECT * FROM course WHERE dept_name=‘Comp. Sci.’;
SELECT * FROM course WHERE credits>3;
SELECT * FROM course WHERE dept_name=‘Comp. Sci.’ AND credits>3;
- GROUP BY
GROUP BY语句可以分组结果,常用于COUNT、MAX、MIN、SUM、AVG等聚合函数(aggregate functions)。
SELECT <列名1>, <列名2>, …
FROM <表名>
GROUP BY <列名>;
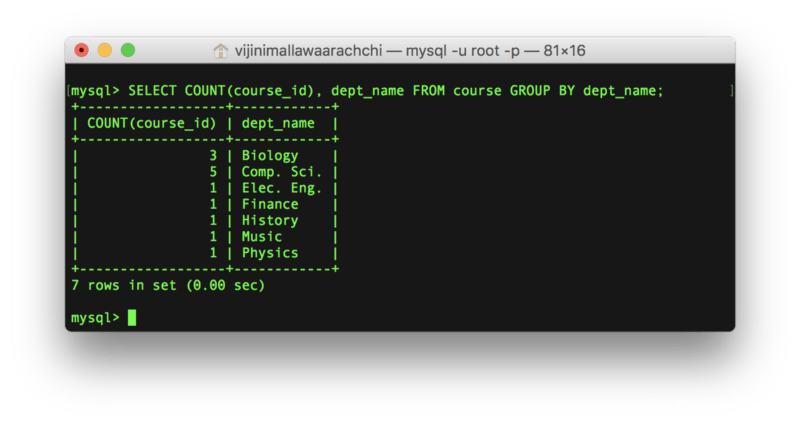
让我们来看一个例子,列出每个部门的课程数量:
SELECT COUNT(course_id), dept_name
FROM course
GROUP BY dept_name;
- HAVING
乍看起来,HAVING和WHERE很像:
SELECT <列名1>, <列名2>, …
FROM <表名>
GROUP BY <列名x>
HAVING <条件>;
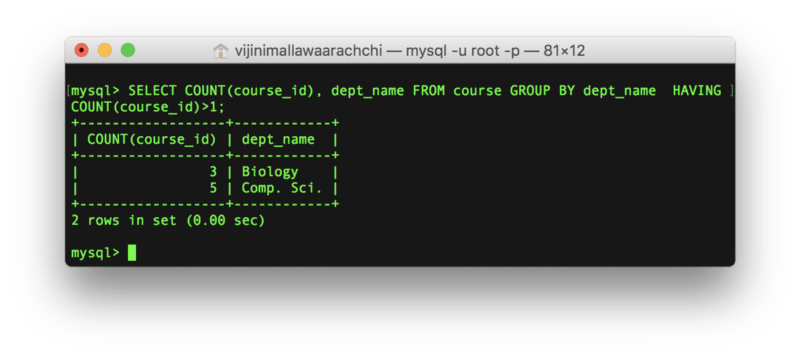
那么,HAVING和WHERE有什么不同呢?让我们先来看一个例子,列出开了不止一门课程的部门开设的课程数:
SELECT COUNT(course_id), dept_name
FROM course
GROUP BY dept_name
HAVING COUNT(course_id)>1;
这里HAVING不能换成WHERE,因为WHERE直接针对行操作,且在GROUP BY之前运行(即先通过WHERE筛选行,之后再将筛选出的行通过GROUP BY分组)。假设SQL中不存在HAVING语句,那么我们只能先新建一张表,将COUNT(course_id)作为新表的列,然后在新表上再通过WHERE进行筛选(当然,实际上SQL提供了派生表、CTE等机制,并不用真的手工建新表)。
- ORDER BY
ORDER BY可以对结果进行排序,在没有明确指定ASC(升序)或DESC(降序)的情况下,默认按升序排列。
SELECT <列名1>, <列名2>, …
FROM <表名>
ORDER BY <列名1>, <列名2>, …, ASC|DESC;
例子:
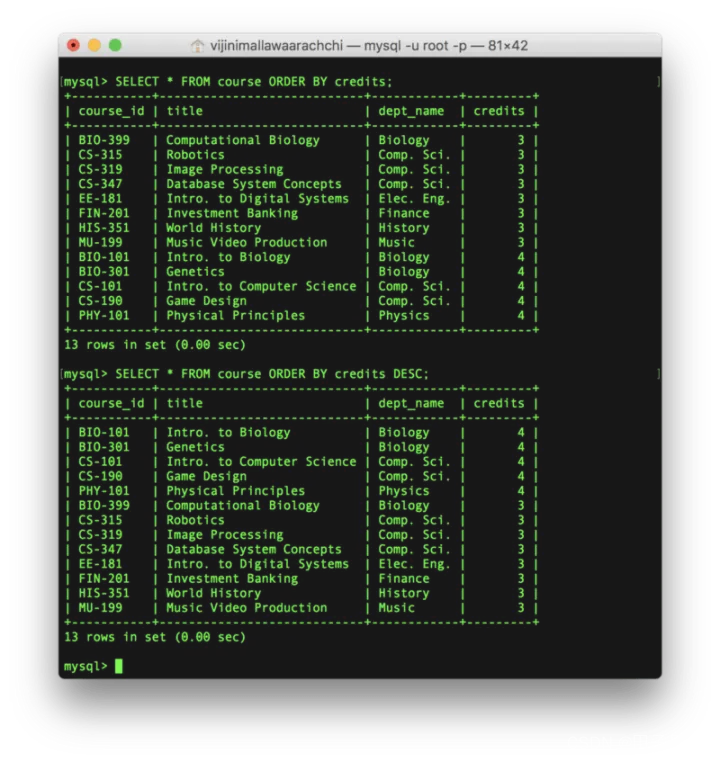
SELECT * FROM course ORDER BY credits;
SELECT * FROM course ORDER BY credits DESC;
- BETWEEN
BETWEEN语句用于指定区间。
SELECT <列名1>, <列名2>, …
FROM <表名>
WHERE <列名x> BETWEEN <值1> AND <值2>;
其中“值”可能是数字,文本,乃至日期等。
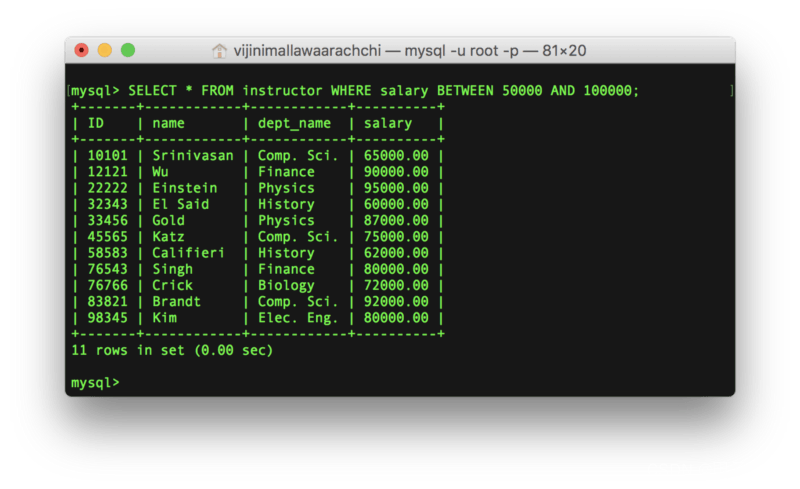
例如,列出薪资在50000和100000之间的教员:
SELECT * FROM instructor
WHERE salary BETWEEN 50000 AND 100000;
- LIKE
LIKE用于匹配文本中的特定模式。
SELECT <列名1>, <列名2>, …
FROM <表名>
WHERE <列名x> LIKE <模式>;
模式中可以使用以下两个通配符:
% (零个、一个或多个字符)
_ (单个字符)
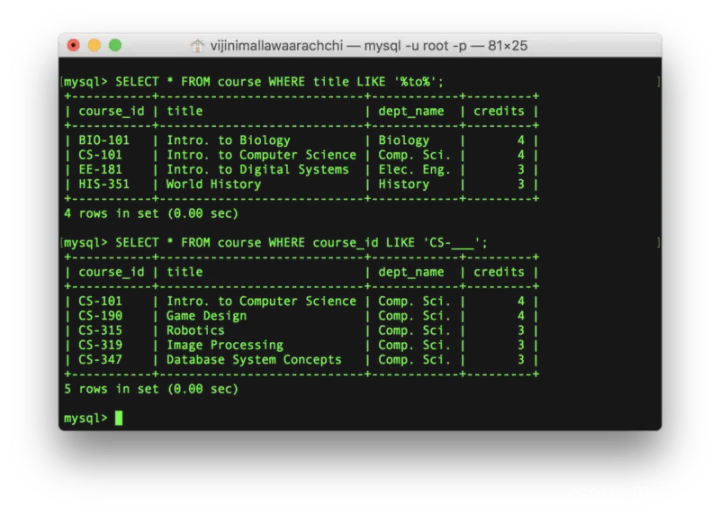
例子:列出课程名中包含“to”的课程,以及课程ID以“CS-”开头的课程。
SELECT * FROM course WHERE title LIKE ‘%to%’;
SELECT * FROM course WHERE course_id LIKE ‘CS-___’;
- IN
IN语句表示值属于某个集合。
SELECT <列名1>, <列名2>, …
FROM <表名>
WHERE <列名n> IN (<值1>, <值2>, …);
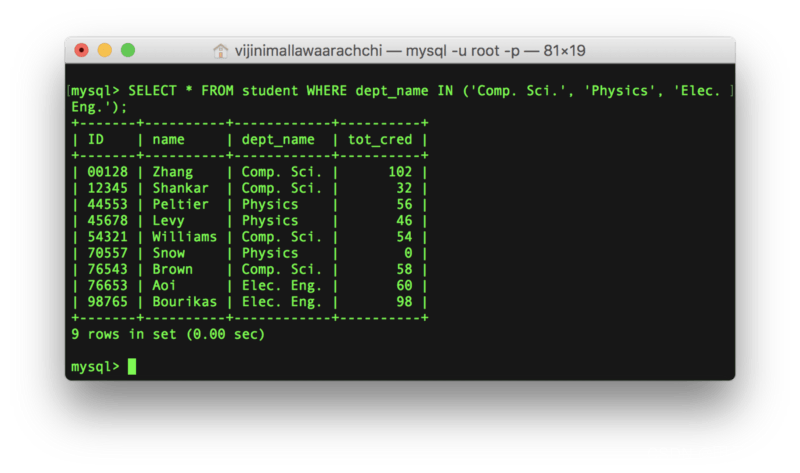
例子:列出计算机科学、物理、电子工程部门的学生。
SELECT * FROM student
WHERE dept_name IN (‘Comp. Sci.’, ‘Physics’, ‘Elec. Eng.’);
- JOIN
JOIN用来组合两张以上表中的值。下图展示了JOIN的三种类型:
SELECT <列名1>, <列名2>, …
FROM <表名1>
JOIN <表名2>
ON <表名1.列名x> = <表名2.列名x>
让我们来看三个例子,分别对应三种JOIN的类型。
第一个例子,列出课程时包含开设课程的部门详情:
SELECT * FROM course
JOIN department
ON course.dept_name=department.dept_name;

第二个例子,列出所有具有前置课程的课程的详情:
SELECT prereq.course_id, title, dept_name, credits, prereq_id
FROM prereq
LEFT OUTER JOIN course
ON prereq.course_id=course.course_id;
最后一个例子,列出所有课程的详情,不管是否具有前置课程:
SELECT course.course_id, title, dept_name, credits, prereq_id
FROM prereq
RIGHT OUTER JOIN course
ON prereq.course_id=course.course_id;
- 视图
视图(view)是虚拟的SQL表。它包含行和列,和一般的SQL表格很类似。视图总是显示数据库中的最新数据。
CREATE VIEW
创建视图:
CREATE VIEW <视图名> AS
SELECT <列名1>, <列名2>, …
FROM <表名>
WHERE <条件>;
DROP VIEW
删除视图:
DROP VIEW <视图名>;
例如,创建3学分的课程视图:
CREATE VIEW my_view AS
SELECT * FROM course
WHERE credits=3;

- 聚合函数
我们之前已经提到聚合函数,这里列出最常用的一些聚合函数:
COUNT(列名) 返回行数
SUM(列名) 返回指定列的值之和
AVG(列名) 返回指定列的平均值
MIN(列名) 返回指定列的最小值
MAX(列名) 返回指定列的最大值
25. 嵌套子查询
在SQL请求中,可以嵌套SELECT-FROM-WHERE表达式,称为嵌套子查询(nested subqueries)。
例如,查找2009年秋、2010年春都开的课程:
SELECT DISTINCT course_id
FROM section
WHERE semester = ‘Fall’ AND year= 2009 AND course_id IN (
SELECT course_id
FROM section
WHERE semester = ‘Spring’ AND year= 2010
);





![[附源码]JAVA毕业设计农产品的物流信息服务平台(系统+LW)](https://img-blog.csdnimg.cn/e55ce54cd8554e9d92ccdb59127adb37.png)

![[附源码]计算机毕业设计社区生活废品回收APPSpringboot程序](https://img-blog.csdnimg.cn/9d32129672704204aa07472b1e1baa94.png)