源码下载链接:ppt.rar - 蓝奏云
PPT下载链接:https://pan.baidu.com/s/1HUAEe_-4IEV6ttOKC_VPuA?pwd=96px
提取码:96px
采集的参数
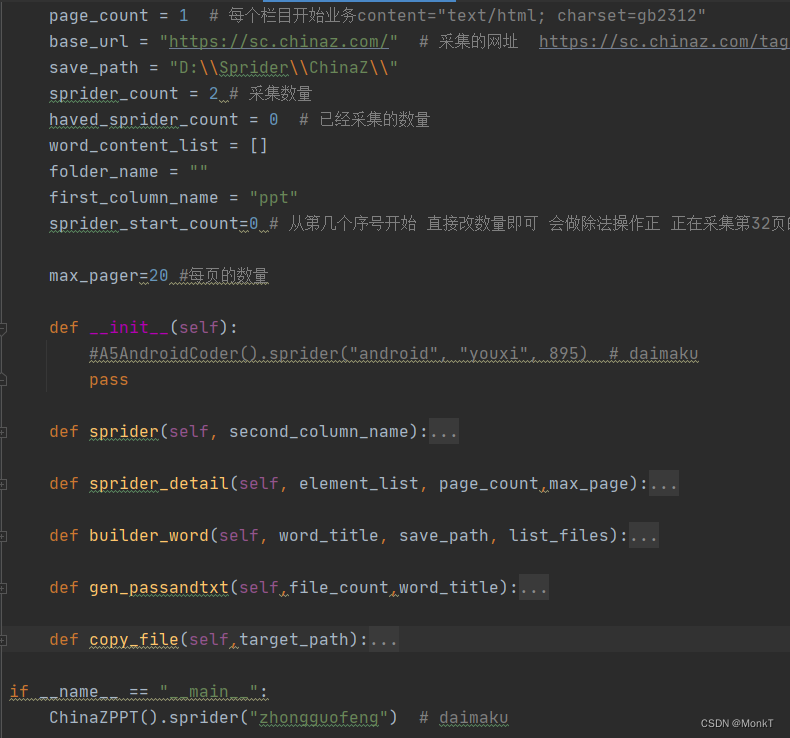
page_count = 1 # 每个栏目开始业务content="text/html; charset=gb2312"
base_url = "https://sc.chinaz.com/" # 采集的网址 https://sc.chinaz.com/tag_ppt/zhongguofeng.html
save_path = "D:\\Sprider\\ChinaZ\\"
sprider_count = 110 # 采集数量
haved_sprider_count = 0 # 已经采集的数量
word_content_list = []
folder_name = ""
first_column_name = "ppt"
sprider_start_count=800 # 从第几个序号开始 直接改数量即可 会做除法操作正 正在采集第32页的第16个资源 debug
max_pager=20 #每页的数量采集主体代码
def sprider(self, second_column_name):
"""
采集Coder代码
:return:
"""
if second_column_name == "zhongguofeng":
self.folder_name = "中国风"
self.first_column_name="tag_ppt"
elif second_column_name == "xiaoqingxin":
self.folder_name = "小清新"
self.first_column_name = "tag_ppt"
elif second_column_name == "kejian":
self.folder_name = "课件"
self.first_column_name = "ppt"
merchant = int(self.sprider_start_count) // int(self.max_pager) + 1
second_folder_name = str(self.sprider_count) + "个" + self.folder_name
self.save_path = self.save_path+ os.sep + "PPT" + os.sep + second_folder_name
BaseFrame().debug("开始采集ChinaZPPT...")
sprider_url = (self.base_url + "/" + self.first_column_name + "/" + second_column_name + ".html")
response = requests.get(sprider_url, timeout=10, headers=UserAgent().get_random_header(self.base_url))
response.encoding = 'UTF-8'
soup = BeautifulSoup(response.text, "html5lib")
#print(soup)
div_list = soup.find('div', attrs={"class": 'ppt-list'})
div_list =div_list.find_all('div', attrs={"class": 'item'})
#print(div_list)
laster_pager_url = soup.find('a', attrs={"class": 'nextpage'})
laster_pager_url = laster_pager_url.previous_sibling
#<a href="zhongguofeng_89.html"><b>89</b></a>
page_end_number = int(laster_pager_url.find('b').string)
#print(page_end_number)
self.page_count = merchant
while self.page_count <= int(page_end_number): # 翻完停止
try:
if self.page_count == 1:
self.sprider_detail(div_list,self.page_count,page_end_number)
else:
if self.haved_sprider_count == self.sprider_count:
BaseFrame().debug("采集到达数量采集停止...")
BaseFrame().debug("开始写文章...")
self.builder_word(self.folder_name, self.save_path, self.word_content_list)
BaseFrame().debug("文件编写完毕,请到对应的磁盘查看word文件和下载文件!")
break
#https://www.a5xiazai.com/android/youxi/qipaiyouxi/list_913_1.html
#https://www.a5xiazai.com/android/youxi/qipaiyouxi/list_913_2.html
#next_url = sprider_url + "/list_{0}_{1}.html".format(str(url_index), self.page_count)
# (self.base_url + "/" + first_column_name + "/" + second_column_name + "/"+three_column_name+"")
next_url =(self.base_url + "/" + self.first_column_name + "/" + second_column_name + "_{0}.html").format(self.page_count)
# (self.base_url + "/" + self.first_column_name + "/" + second_column_name + "")+"/list_{0}_{1}.html".format(str(self.url_index), self.page_count)
response = requests.get(next_url, timeout=10, headers=UserAgent().get_random_header(self.base_url))
response.encoding = 'UTF-8'
soup = BeautifulSoup(response.text, "html5lib")
div_list = soup.find('div', attrs={"class": 'ppt-list'})
div_list = div_list.find_all('div', attrs={"class": 'item'})
self.sprider_detail(div_list, self.page_count,page_end_number)
pass
except Exception as e:
print("sprider()执行过程出现错误" + str(e))
pass
self.page_count = self.page_count + 1 # 页码增加1
def sprider_detail(self, element_list, page_count,max_page):
try:
element_length = len(element_list)
self.sprider_start_index = int(self.sprider_start_count) % int(self.max_pager)
index = self.sprider_start_index
while index < element_length:
a=element_list[index]
if self.haved_sprider_count == self.sprider_count:
BaseFrame().debug("采集到达数量采集停止...")
break
index = index + 1
sprider_info = "正在采集第" + str(page_count) + "页的第" + str(index) + "个资源"
BaseFrame().debug(sprider_info)
title_image_obj = a.find('img', attrs={"class": 'lazy'})
url_A_obj=a.find('a', attrs={"class": 'name'})
next_url = self.base_url+url_A_obj.get("href")
coder_title = title_image_obj.get("alt")
response = requests.get(next_url, timeout=10, headers=UserAgent().get_random_header(self.base_url))
response.encoding = 'UTF-8'
soup = BeautifulSoup(response.text, "html5lib")
#print(next_url)
down_load_file_div = soup.find('div', attrs={"class": 'download-url'})
if down_load_file_div is None:
BaseFrame().debug("需要花钱无法下载因此跳过哦....")
continue
down_load_file_url = down_load_file_div.find('a').get("href")
#print(down_load_file_url)
image_obj = soup.find('div', attrs={"class": "one-img-box"}).find('img')
image_src = "https:"+ image_obj.get("data-original")
#print(image_src)
if (DownLoad(self.save_path).__down_load_file__(down_load_file_url, coder_title, self.folder_name)):
DownLoad(self.save_path).down_cover_image__(image_src, coder_title) # 资源的 封面
sprider_content = [coder_title,
self.save_path + os.sep + "image" + os.sep + coder_title + ".jpg"] # 采集成功的记录
self.word_content_list.append(sprider_content) # 增加到最终的数组
self.haved_sprider_count = self.haved_sprider_count + 1
BaseFrame().debug("已经采集完成第" + str(self.haved_sprider_count) + "个")
if (int(page_count) == int(max_page)):
self.builder_word(self.folder_name, self.save_path, self.word_content_list)
BaseFrame().debug("文件编写完毕,请到对应的磁盘查看word文件和下载文件!")
except Exception as e:
print("sprider_detail:" + str(e))
pass
采集的文件名
手绘风格乐器素材ppt背景图片
水粉手绘小清新花卉ppt背景图片
水彩手绘绿叶素材ppt背景图片
粉色儿童成长相册ppt背景图片
彩色手绘蔬菜食材ppt背景图片
水彩手绘开学季返校ppt背景图片
新的学期新的起点主题班会ppt模板
绿色渐变水彩风ppt背景模板
彩色卡通健康蔬果ppt图片背景
手绘拼贴画新冠防疫知识ppt背景图
手绘风介绍立秋节气ppt模板
儿童手绘致敬医学工作者ppt背景图片
手绘风幼儿园儿童节PPT课件
黑板手绘风备战高考PPT模板
小清新蓝绿植物文艺风ppt模板
期末家长会PPT模板
大学生职业规划书PPT模板
小学生秋游安全教育PPT模板
活动流程策划案例PPT模板
绿色手绘风叶子开学家长会PPT模板
小学教学工作汇报PPT模板
手绘风学业生涯规划书PPT模板
手绘策划方案答辩PPT模板
手绘绿植毕业生答辩PPT模板
手绘风卡通期中家长会PPT模板
转正述职报告PPT模板
大学生调研报告PPT模板
小清新财务总结报告PPT模板
美妆销售年初总结PPT模板
手绘风旅游旅行PPT模板
销售经理年终总结PPT模板
卡通手绘风2021庆典PPT模板
卡通儿童旅行相册PPT模板
手绘风圣诞节ppt背景
商务时尚企业PPT模板
秋天的图画ppt
小学语文ppt模板
卡通ppt背景图片
ppt模板免费下载
精美ppt模板免费下载
水彩手绘风感恩教师节ppt
手绘风快乐61儿童节PPT模板
文艺趣味手绘风商务总结PPT模板
手绘风医疗医药数据报告PPT模板
创意手绘风动态工作汇报PPT模板
手绘风可爱小班家长会PPT模板
创意手绘电商节活动策划PPT模板
手绘感恩节主题班会PPT模板
手绘清新教学课件PPT模板
绿色手绘花卉植物个人工作总结PPT模板
手绘卡通风端午节习俗PPT模板
手绘风唯美创意三八女神节PPT模板
日系风手绘美丽38女王节PPT模板
清新绿色手绘插画风艺术设计PPT模板
文艺小清新手绘插画风情人节PPT模板
创意粉笔手绘感恩教师节ppt模板
素雅文艺手绘插画师ppt模板
创意可爱手绘风童年回忆ppt模板
个性涂鸦色彩手绘风ppt模板
清新水彩手绘ppt模板
创意卡通铅笔手绘风ppt模板
卡通铅笔手绘大数据整理ppt模板
创意手绘卡通论文答辩ppt模板
创意手绘卡通ppt模板
灰色可爱卡通背景ppt模板
趣味简约手绘线稿ppt模板
创意趣味手绘涂鸦ppt模板下载
创意低碳环保ppt模板
创意彩色手绘论文答辩ppt模板
创意手绘涂鸦褶皱纸张背景ppt模板
创意趣味手绘ppt模板下载
精美彩绘ppt模板下载
水彩手绘说课ppt模板下载
创意手绘ppt卡通动画模板下载
个性创意手绘ppt模板下载
春天气息的ppt模板
化学说课ppt模板下载
玫瑰情人节ppt模板免费下载
手绘涂鸦PPT图表下载
师范类通用ppt模板下载
手绘沙滩海洋生物ppt模板
手绘绿色公园ppt模板下载
手绘梦幻樱花ppt模板下载
手绘女孩ppt模板下载
手绘女孩ppt模板下载
手绘爱心ppt模板下载
粉红女孩ppt模板下载
粉彩美女ppt模板下载












![[附源码]计算机毕业设计JAVA疫情背景下社区公共卫生服务系统](https://img-blog.csdnimg.cn/099cd5356c20469685e39021ae017784.png)