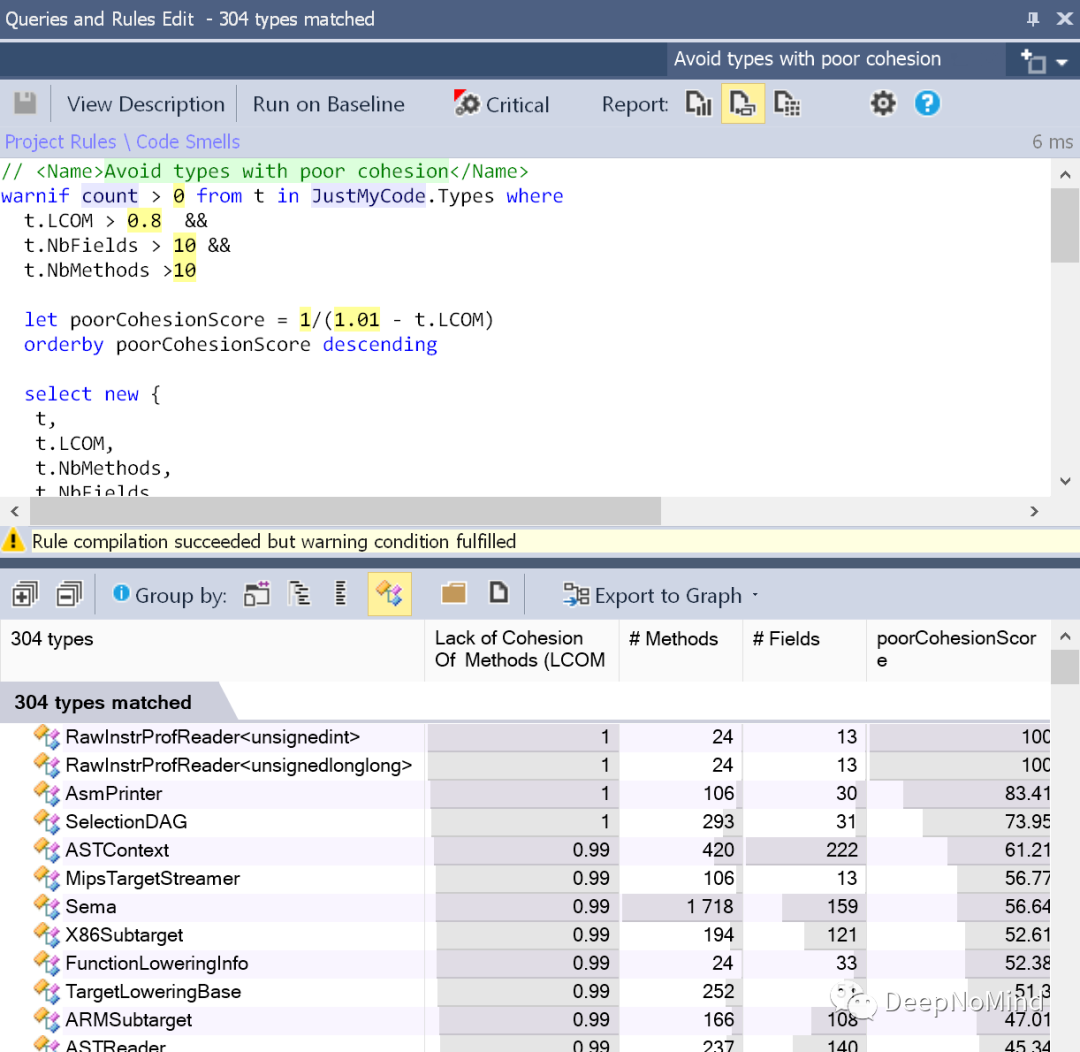
数据库
- 我电脑上的数据库登录指令:mysql -uroot -p123456
- 常用指令:show databases、user 数据库名、show tables。
创建项目
创建完项目后,要及时检查maven仓库的配置,jdk的配置,项目的编码,如下图。



配置项目的pom依赖和aplication文件,在启动类中加入lombok的slf4j注解,就可以使用log.info()方法在控制台输出信息了,方便调试。
映射静态资源
- 问题:如果静态资源直接放入resource目录之下,而不是放在static或者templates目录下面,则项目启动后,浏览器无法直接访问到静态资源。
- 解决方法,编写WebMvcConfig配置文件,文件所在目录以及内容如下所示。

package com.example.reggie_take_out;
import lombok.extern.slf4j.Slf4j;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@Slf4j
@SpringBootApplication
public class ReggieTakeOutApplication {
public static void main(String[] args) {
SpringApplication.run(ReggieTakeOutApplication.class, args);
log.info("项目启动成功。。。");
}
}
用户登录退出和拦截器功能的实现
用户登录功能
@PostMapping("/login")
public R<Employee> login(HttpServletRequest request, @RequestBody Employee employee){
//1、将页面提交的密码password进行md5加密处理
String password = employee.getPassword();
password = DigestUtils.md5DigestAsHex(password.getBytes());
//2、根据页面提交的用户名username查询数据库
LambdaQueryWrapper<Employee> queryWrapper = new LambdaQueryWrapper<>();
//参数中,第一个参数是属性的引用,用于指定要匹配的属性。第二个参数是属性值,表示要匹配的值。
queryWrapper.eq(Employee::getUsername, employee.getUsername());
Employee emp = employeeService.getOne(queryWrapper);
//3、如果没有查询到则返回登灵失败结果
if(emp == null){
return R.error("登陆失败");
}
//4、密码比对,如果不一致则返回登录失败结果
if(!emp.getPassword().equals(password)){
return R.error("密码错误");
}
//5、查看员工状态,如果为已禁用状态,则返回员工已禁用结果
if(emp.getStatus() == 0){
return R.error("账号已禁用");
}
//6、登录成功,将员工id存入Session并返回登录成功结果
request.getSession().setAttribute("employee", emp.getId());
return R.success(emp);
}用户退出
@PostMapping("/logout")
public R<String> logout(HttpServletRequest request){
//清理session中保存的员工ID
request.getSession().removeAttribute("employee");
return R.success("退出成功");
}拦截器
拦截器和过滤器各自适用的场景
拦截器通常在业务处理层面进行操作,它们更接近业务逻辑,可以对请求进行细粒度的控制和处理。例如,权限验证是一个常见的业务处理需求,拦截器可以拦截请求并检查用户的权限,以确保只有具有访问权限的用户可以执行相应的操作。另外,日志记录也是拦截器常见的应用场景,通过拦截请求和响应,可以记录请求的细节和响应的结果,方便问题的排查和系统的监控。
过滤器则更多地关注于请求和响应的处理和过滤。它们通常在请求的前后进行操作,用于对请求和响应进行过滤、修改或转换。请求过滤是过滤器的常见应用场景,可以用于对请求进行预处理、验证和过滤,例如检查请求的来源、请求的参数等。同时,过滤器还可以对请求和响应的编码进行转换,以确保请求和响应的正确编码格式。
综上所述,拦截器和过滤器在不同的层面和目的上有所不同,拦截器更偏向于业务处理和控制,而过滤器更专注于对请求和响应的处理和过滤。
//注意在启动类中添加注解 @ServletComponentScan
@WebFilter(filterName = "loginCheckFilter", urlPatterns = "/*")
@Slf4j
public class LoginCheckFilter implements Filter {
public static final AntPathMatcher PATH_MATCHER = new AntPathMatcher();
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
HttpServletRequest request = (HttpServletRequest)servletRequest;
HttpServletResponse response = (HttpServletResponse)servletResponse;
log.info("拦截到请求:{}",request.getRequestURI());
// 1、获取本次请求的URI
String requestURI = request.getRequestURI();
//不需要检查的请求路径
String[] urls = new String[]{
"/employee/login",
"/employee/logout",
"/backend/**",
"/front/**"
};
// 2、判断本次请求是否需要处理
boolean check = check(urls, requestURI);
// 3、如果不需要处理,则直接放行
if(check == true){
filterChain.doFilter(request, response);
return;
}
// 4、判断登录状态,如果已登录,则直接放行
if(request.getSession().getAttribute("employee") != null){
filterChain.doFilter(request, response);
return;
}
// 5、如果未登录则返回未登录结果,通过输出流的方式向客户端页面响应数据
response.getWriter().write(JSON.toJSONString(R.error("NOTLOGIN")));
return;
}
/**
* 路径匹配,检查本次请求是否需要放行
* @param urls
* @param requestURI
* @return
*/
public boolean check(String[] urls, String requestURI){
for(String url:urls){
if(PATH_MATCHER.match(url, requestURI) == true ){
return true;
}
}
return false;
}
}
由于dofilter的返回类型为void,所以不能通过return R.error("错误信息")向客户端返回信息,可使用response对象向客户端返回信息:
response.getWriter().write(JSON.toJSONString(R.error("NOTLOGIN")));新增员工功能
@PostMapping
public R<String> save(HttpServletRequest request, @RequestBody Employee employee){
log.info("新增员工,员工信息:{}", employee.toString());
employee.setPassword(DigestUtils.md5DigestAsHex("123456".getBytes()));
employee.setCreateTime(LocalDateTime.now());
employee.setUpdateTime(LocalDateTime.now());
//获取当前登录用户ID
Long empId =(Long) request.getSession().getAttribute("employee");
employee.setCreateUser(empId);
employee.setUpdateUser(empId);
employeeService.save(employee);
return R.success("新增员工成功");
}员工查询
@GetMapping("/page")
public R<Page> page(int page, int pageSize, String name){
log.info("分页查询{} {} {}", page, pageSize, name);
//构造分页构造器
Page pageInfo = new Page(page, pageSize);
//构造条件构造器
LambdaQueryWrapper<Employee> queryWrapper = new LambdaQueryWrapper();
//添加过滤条件
if(name != null){
queryWrapper.like(Employee::getName, name);
}
//添加排序条件
queryWrapper.orderByDesc(Employee::getUpdateTime);
//执行查询
employeeService.page(pageInfo, queryWrapper);
return R.success(pageInfo);
}需要注意的是,如果没有配置 MyBatis Plus 的分页插件,意味着分页功能将不会启用。 那么调用 employeeService.page(pageInfo, queryWrapper) 方法时,将无法进行分页查询, 而是会返回所有符合条件的结果,而不是按照指定的分页参数进行分页查询。
启用和禁用员工
/**
* 根据id修改员工信息
* @param employee
* @return
*/
@PutMapping
public R<String> updata(HttpServletRequest request, @RequestBody Employee employee){
log.info(employee.toString());
long empid = (long)request.getSession().getAttribute("employee");
employee.setUpdateUser(empid);
employee.setUpdateTime(LocalDateTime.now());
employeeService.updateById(employee);
return R.success("员工信息修改成功");
}注意,ID为long类型,有19位,页面中js处理long型数字只能精确到前16位,所以最终通过ajax请求提交给服务端的时候id发生了变化。
解决办法是,将返回给客户端的数据转换为JSON格式,具体做法是在WebMvcConfig配置文件中添加扩展mvc框架的消息转换器,如下所示。
/**
* 扩展mvc框架的消息转换器
* @param converters
*/
@Override
protected void extendMessageConverters(List<HttpMessageConverter<?>> converters) {
MappingJackson2HttpMessageConverter messageConverter = new MappingJackson2HttpMessageConverter();
//设置对象转换器 底层使用Jackson将Java对象转为json
messageConverter.setObjectMapper(new JacksonObjectMapper());
//将上面的消息转换器对象追加到mvc框架的转换器集合中
converters.add(0, messageConverter);
super.extendMessageConverters(converters);
}
公共字段的填充
- 在实体类的相应字段上加入如下的注解。
//在插入时生效
@TableField(fill = FieldFill.INSERT)
private LocalDateTime createTime;
//在插入和更新时生效
@TableField(fill = FieldFill.INSERT_UPDATE)
private LocalDateTime updateTime;- 在MyMetaObjecthandler类中无法获得HttpSession对象,我们用TreadLocal来解决该问题,他是JDK中提供的一个类。


- 如下为代码实现。
- 首先构建基于ThreadLocal封装工具类,用户保存和获取当前登录用户id
package com.example.reggie_take_out.common; /** * 基于ThreadLocal封装工具类,用户保存和获取当前登录用户id */ public class BaseContext { private static ThreadLocal<Long> threadLocal = new ThreadLocal<>(); public static void setCurrentId(Long id){ threadLocal.set(id); } public static Long getCurrenId(){ return threadLocal.get(); } } - 从filter中将用户id存入threadLocal提供的存储空间当中
// 4、判断登录状态,如果已登录,则直接放行
if(request.getSession().getAttribute("employee") != null){
//将用户id存入threadLocal提供的存储空间当中
BaseContext.setCurrentId((Long)request.getSession().getAttribute("employee"));
filterChain.doFilter(request, response);
return;
}- 在MyMetaObjecthandler类中获取用户ID
/** * 更新操作自动填充 * @param metaObject */ @Override public void updateFill(MetaObject metaObject) { log.info("公共字段自动填充[update]"); log.info((metaObject.toString())); metaObject.setValue("updateTime", LocalDateTime.now()); metaObject.setValue("updateUser", BaseContext.getCurrenId()); }
代码开发的结构

删除分类
删除分类时要注意,判断被删除的分类是否关联了菜品或者套餐,因此就不能在CategoryController直接使用categoryService.removeById( id )对分类进行删除。
在CategoryService接口中定义remove方法,实现关联删除的逻辑业务判断,在CategoryServiceImpl中具体的实现方法如下。
@Service
public class CategoryServiceImpl extends ServiceImpl<CategoryMapper, Category> implements CategoryService {
@Autowired
private DishService dishService;
@Autowired
private SetmealService setmealService;
/**
* 根据id进行删除,删除之前要做判断
* @param id
*/
@Override
public void remove(Long id) {
//查询当前分类是否关联菜品,如果已经关联,抛出一个业务异常
LambdaQueryWrapper<Dish> dishLambdaQueryWrapper = new LambdaQueryWrapper<>();
dishLambdaQueryWrapper.eq(Dish::getCategoryId, id);
int count1 = dishService.count(dishLambdaQueryWrapper);
if(count1 >0) {
throw new CustomException("当前分类下关联了菜品,不能删除");
}
//查询当前分类是否关联套餐,如果已经关联,抛出一个业务异常
LambdaQueryWrapper<Setmeal> setmealLambdaQueryWrapper = new LambdaQueryWrapper<>();
setmealLambdaQueryWrapper.eq(Setmeal::getCategoryId, id);
int count2 = setmealService.count(setmealLambdaQueryWrapper);
if(count2 >0) {
throw new CustomException("当前分类下关联了套餐,不能删除");
}
//正常删除业务
super.removeById(id);
}
}自定义异常类的代码如下。
/**
* 自定义业务异常类
*/
public class CustomException extends RuntimeException {
public CustomException(String message){
super(message);
}
}
全局异常处理器的代码如下。
/**
* 异常处理方法
* @return
*/
@ExceptionHandler(CustomException.class)
public R<String> exceptionHandler(CustomException ex){
log.error(ex.getMessage());
return R.error(ex.getMessage());
}文件上传
/**
* 文件上传
* @param file
* @return
*/
@PostMapping("/upload")
public R<String> upLoad(MultipartFile file){
//file是一个临时文件,需要转存到指定位置,否则本次请求完成后临时文件会被删除
log.info(file.toString());
//原始文件名
String originalFilename = file.getOriginalFilename();
String suffix = originalFilename.substring(originalFilename.lastIndexOf("."));
//使用UUID重新生成文件名,防止文件名称重复造成覆盖
String filename = UUID.randomUUID().toString() + suffix;
//创建一个目录对象
File dir = new File(basePath);
if(!dir.exists()){
dir.mkdir();
}
//将临时文件转存到指定位置
try {
file.transferTo(new File(basePath+filename));
} catch (IOException e) {
e.printStackTrace();
}
return R.success(filename);
}文件下载
/**
* 文件下载
* @param name
* @param response
*/
@GetMapping("/download")
public void download(String name, HttpServletResponse response){
//输入流,通过输入流读取文件内容
try {
FileInputStream fileInputStream = new FileInputStream(basePath + name);
//输出流,通过输出流将文件写回浏览器,在浏览器展示图片
ServletOutputStream outputStream = response.getOutputStream();
response.setContentType("/image/jpeg");
//用于存储文件内容的缓冲区。
int len = 0;
byte[] bytes = new byte[1024];
//输入流中读取文件内容,并将其写入输出流,直到文件的所有内容都被读取完毕。
while( (len = fileInputStream.read(bytes)) != -1){
//这行代码将缓冲区中的内容写入输出流,并通过flush()方法将数据刷新到浏览器。
outputStream.write(bytes, 0, len);
outputStream.flush();
}
//关闭资源
outputStream.close();
fileInputStream.close();
} catch (Exception e) {
e.printStackTrace();
}
}新增菜品
新增菜品,同时插入菜品对应的口味数据,需要操作两张表:dish,dish_flavor。
因此在DishService接口中自定义方法void saveWithFlavor(DishDto dishDto),用于新增菜品,同时插入菜品对应的口味数据。DishServiceImpl实现类中的代码如下。
@Service
@Slf4j
public class DishServiceImpl extends ServiceImpl<DishMapper, Dish> implements DishService {
@Autowired
private DishFlavorService dishFlavorService;
/**
* 新增菜品,同时保存相应的口味数据
* @param dishDto
*/
@Override
@Transactional
public void saveWithFlavor(DishDto dishDto) {
//this.save(dishDto) 将调用 DishServiceImpl 类中的 save 方法,将 dishDto 对象保存到数据库中。
this.save(dishDto);
Long id = dishDto.getId();//菜品id
//菜品口味
List<DishFlavor> flavors = dishDto.getFlavors();
//赋值菜品口味的相应id
flavors = flavors.stream().map((item) -> {
item.setDishId(id);
return item;
}).collect(Collectors.toList());
dishFlavorService.saveBatch(flavors);
}
}注意,saveWithFlavor方法中操作了两张表,因此需要方法上加入@Transactional注解,并且在启动类中加上@EnableTransactionManagement 注解。
菜品展示
问题:页面展示需要分类的名称,但dish表中只有分类的id,因此总体思路是将dish表中的分类id取出来,用分类id在分类表中查询分类名称。
具体步骤:
- 使用DTO(Data Transfer Object)数据传输对象,用于在不同层之间传输数据。DTO结构如下。
@Data public class DishDto extends Dish { private List<DishFlavor> flavors = new ArrayList<>(); private String categoryName; private Integer copies; }DTO继承自Dish类,并且DTO的categoryName属性可用于前端分类名称的展示。