NLP学习笔记四-word embeding
word embeding就是一块重头戏了,因为这里做完,我们的数据处理部分也基本上收尾了。
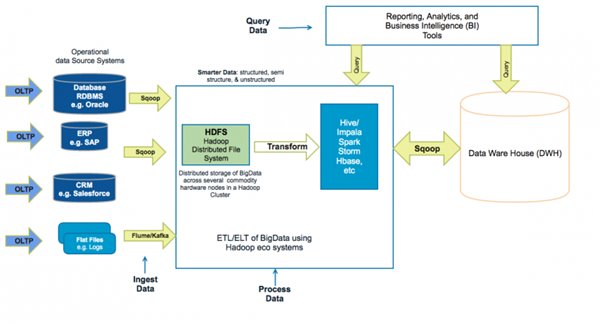
下面我们附上一张图:

如上图,word embeding实在我们one-hot word之后才可以进行的,每一步处理技术都是环环相扣的,那么one-hot word之后,每个单词会被表征成一个1xN的向量,这个1xN的向量只有一个元素为1,其他全为0。
p
t
p^t
pt矩阵是需要学习的参数矩阵,可以看出,其实
p
t
p^t
pt矩阵的每一列就是我们最终的词嵌入向量。这个矩阵可以真正的将单词和单词之间的相关性进行一定程度上的反映,得到的词嵌入向量才有价值。
下面就是一张图:
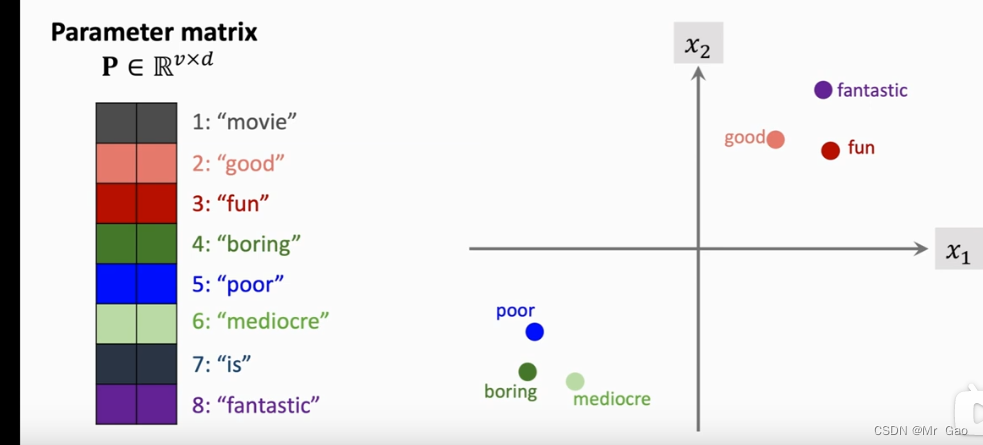
p
t
p^t
pt矩阵并不是一个简单的矩阵,每一列向量代码一个词向量,同时如果映射到多维空间,应可以表设计相应的单词关系。
这一部分很重要哈,基本上所有跟语言有关的模型都是需要这个操作。









![[分布式锁]:Redis与Redisson](https://img-blog.csdnimg.cn/17b703c27da24ec494a59fa352320f31.png)