最近做的很多工作都是跟手写性质的数据集有关的,比如:手写汉字、手写甲骨文、手写数字、手写字母等等,今天主要做的实践是对藏文中的手写数字进行识别分析,在我之前的博文中有很多相关的实践分析,感兴趣的话可以自行移步阅读即可。
《基于轻量级目标检测模型实现手写汉字检测识别计数》
《python开发构建基于机器学习模型的手写数字识别系统》
《Yolov3目标检测实战【实现图像中随机出现手写数字的检测】》
《Python 手写数字识别实战分享》
《超轻量级目标检测模型Yolo-FastestV2基于自建数据集【手写汉字检测】构建模型训练、推理完整流程超详细教程》
《python开发构建轻量级卷积神经网络模型实现手写甲骨文识别系统》
《python基于yolov7开发构建手写甲骨文检测识别系统》
《紧接上文,基于轻量级yolov5s模型开发构建手写甲骨文检测识别系统》
首先看下效果图:
接下来看下数据集:
共包含0-9共10个不同的数字图像,藏文跟我们常规的阿拉伯数字是不同的简单看下实例。
【0】

【1】

【2】

【3】

【4】

【5】

【6】

【7】

【8】

【9】

本文所用模型详细信息如下:

非常的轻量级,整体不足5MB,但是识别效果确实非常不错的。
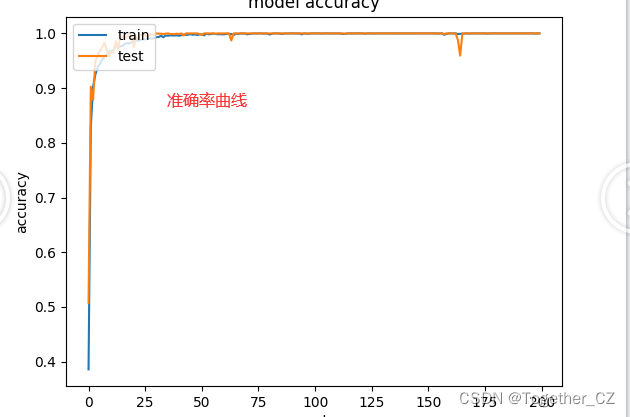
默认训练200次epoch,准确率曲线如下所示:
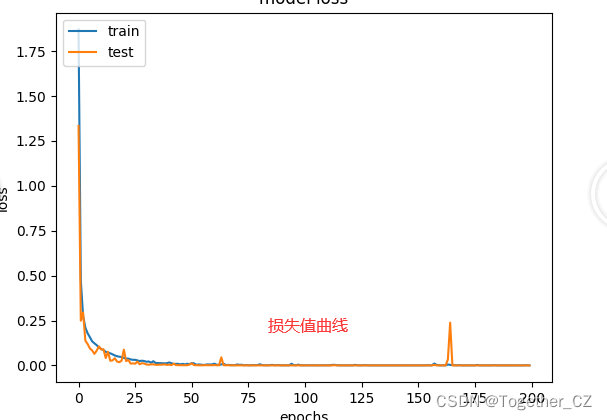
损失值曲线如下所示:
可视化推理实例如下所示:

基于GradCAM实现了热力图计算可视化如下:

感兴趣的话都可以自己实践搭建计算一下。




![[IJCAI 2022] 基于个性化掩码的实用安全联合推荐](https://img-blog.csdnimg.cn/3a159b16f8ba495bb436b74fa2a3b364.png)