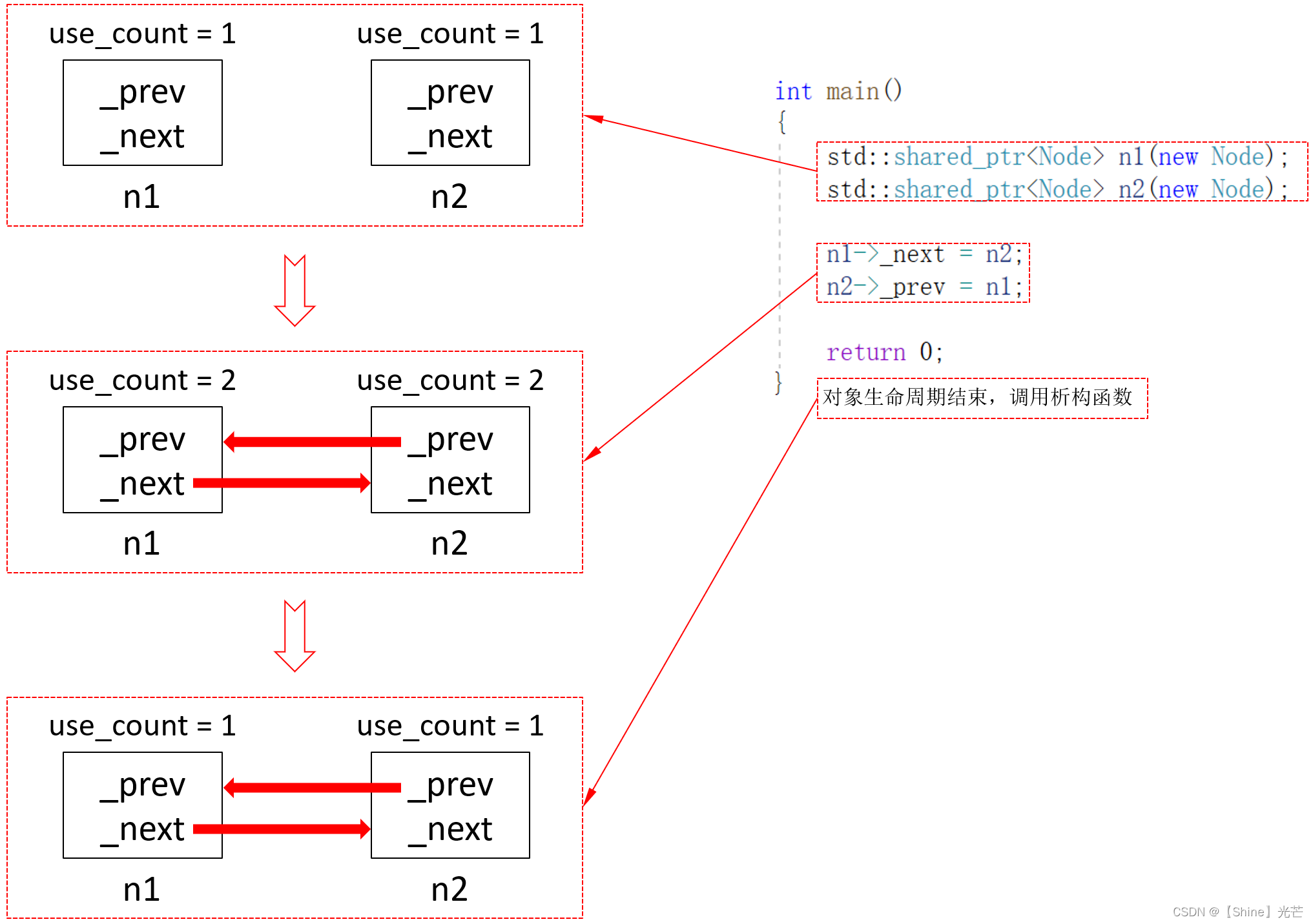
手写汉字、手写数字、手写字母识别模型都已经做过很多了,但是手写甲骨文识别这个应该都是很少有听说过的吧,今天也是看到这个数据集就想着基于这批手写甲骨文数据集开发构建识别模型,首先来看下效果图:

接下来看下对应使用的数据集:

共包含40个不同类别对象。
因为甲骨文的表示过于困难这里都是以编号的形式表示的,简单看几个类别,如下所示:
【0117】

【0105】

【0121】

【0129】

【0137】

【0141】

这里对这40个类别数量进行统计可视化如下所示:
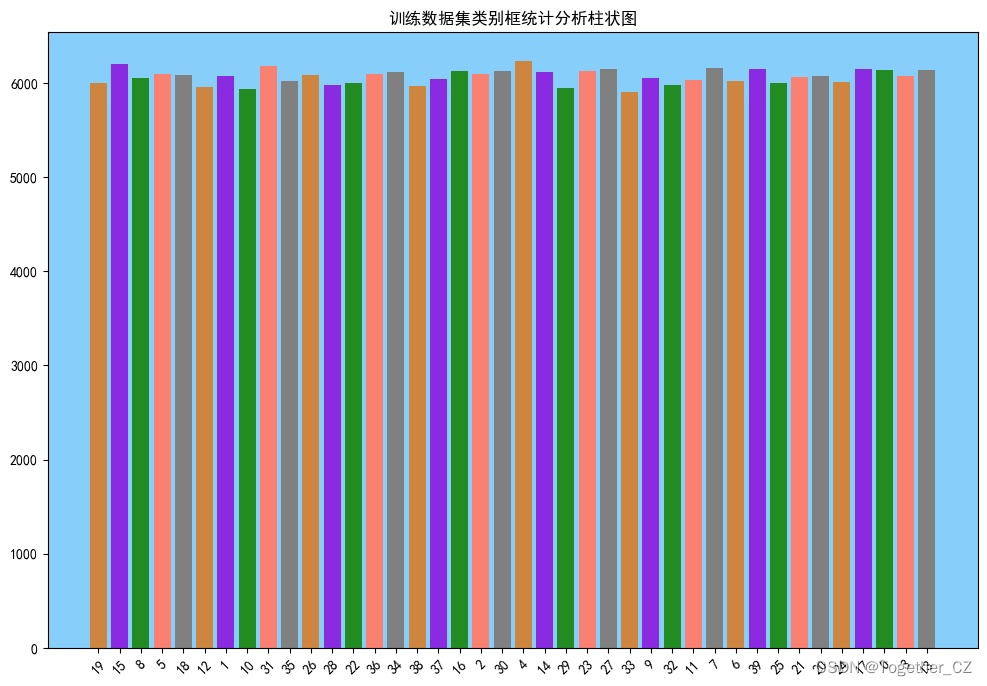
可以看到不同类别的数据集是相对均衡的。
本文的项目开发完全是基于《基于轻量级卷积神经网络模型实践Fruits360果蔬识别》构建的,这里对技术模型就不再赘述了,感兴趣的话可以自行移步阅读下即可。
本文模型参数结构详情如下:

感兴趣的话可以对照搭建复现一下,还是很基础的。
接下来看下损失值曲线:
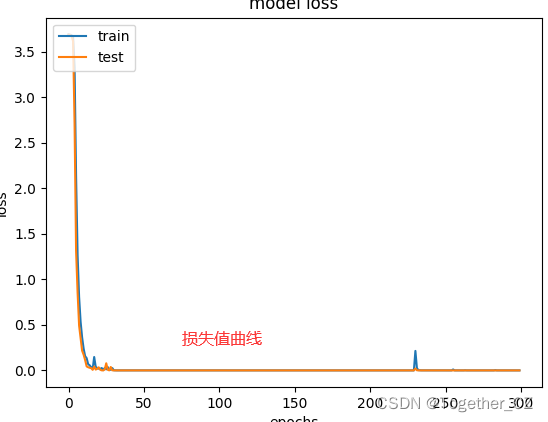
准确率曲线如下:
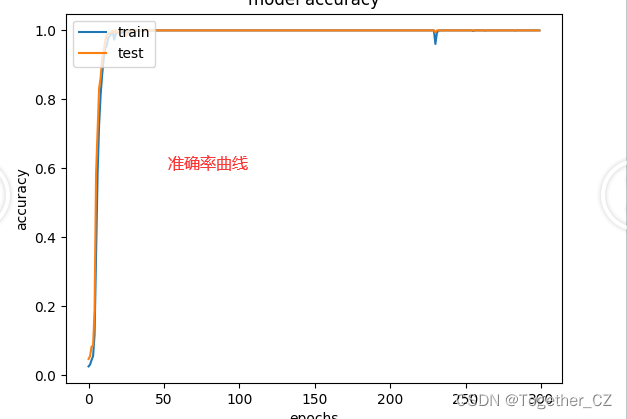
在前文水果识别系统的可视化界面基础上,进一步开发优化集成进来了更多的功能实现了可视化系统界面如下所示:
【数据可视化】

【模型训练】
【模型评估测试】

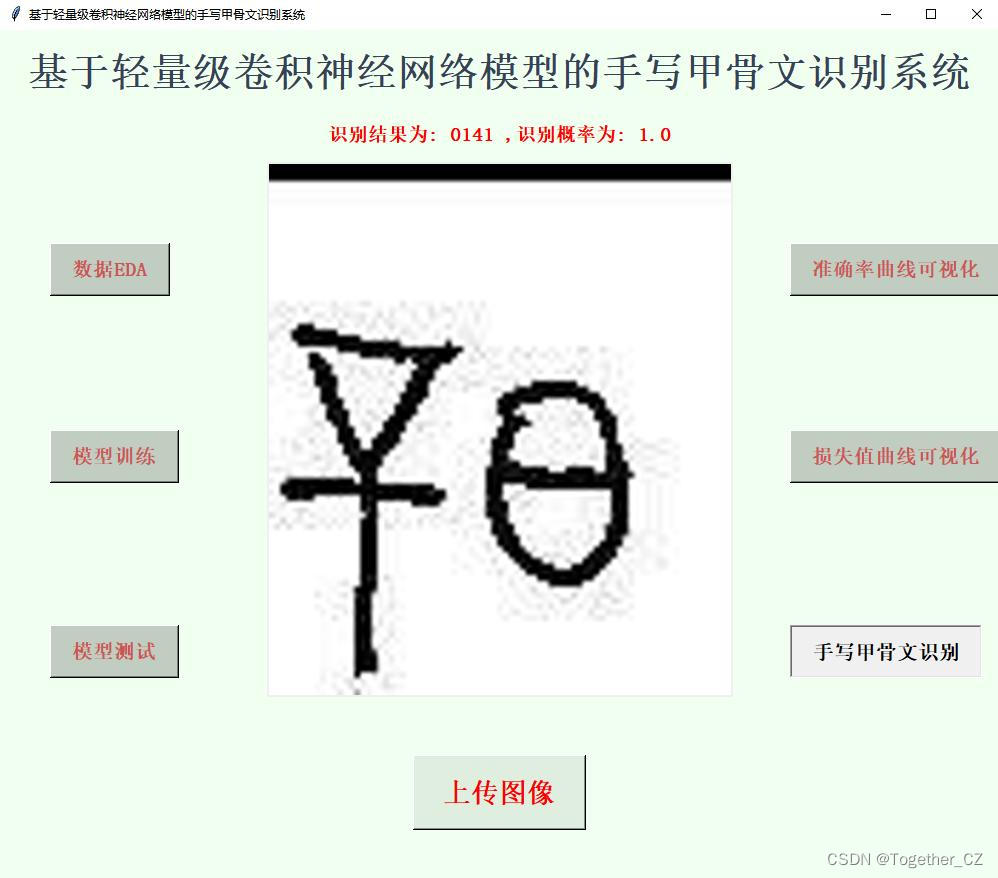
【实例推理】






![[数据结构 -- C语言] 堆实现Top-K问题,原来王者荣耀的排名是这样实现的,又涨知识了](https://img-blog.csdnimg.cn/img_convert/ea814162208d07fe293fb52b324d167a.png)