预聚合是 OLAP 系统中常用的一种优化手段,在通过在加载数据时就进行部分聚合计算,生成聚合后的中间表或视图,从而在查询时直接使用这些预先计算好的聚合结果,提高查询性能,实现这种预聚合方法大多都使用物化视图来实现。
Clickhouse 社区实现的 Projection 功能类似于物化视图,原始的概念来源于 Vertica,在原始表数据加载时,根据聚合 SQL 定义的表达式,计算写入数据的聚合数据与原始数据同步写入存储。在数据查询的过程中,如果查询 SQL 通过匹配分析可以通过聚合数据计算得到,直接查询聚合数据减少计算开销,大幅提升查询性能。
Clickhouse Projection 是针对物化视图现有问题,在查询匹配,数据一致性上扩展了使用场景:
- 支持 normal projection,按照不同列进行数据重排,对于不同条件快速过滤数据
- 支持 aggregate projection, 使用聚合查询在源表上直接定义出预聚合模型
- 查询分析能根据查询代价,自动选择最优 Projection 进行查询优化,无需改写查询
- projeciton 数据存储于原始 part 目录下,在任一时刻针对任一数据变换操作均提供一致性保证
- 维护简单,不需另外定义新表,在原始表添加 projection 属性
ByteHouse 是火山引擎基于 ClickHouse 研发的一款分析型数据库产品,是同时支持实时和离线导入的自助数据分析平台,能够对 PB 级海量数据进行高效分析。具备真实时分析、存储-计算分离、多级资源隔离、云上全托管服务四大特点,为了更好的兼容社区的 projection 功能,扩展 projection 使用场景,ByteHouse 对 Projection 进行了匹配场景和架构上进行了优化。在 ByteHouse 商业客户性能测试 projection 的性能测试,在 1.2 亿条的实际生产数据集中进行测试,查询并发能力提升 10~20 倍,下面从 projeciton 在优化器查询改写和基于 ByteHouse 框架改进两个方面谈一谈目前的优化工作。
Projection 使用
为了提高 ByteHouse 对社区有很好的兼容性,ByteHouse 保留了原有语法的支持,projection 操作分为创建,删除,物化,删除数据几个操作。为了便于理解后面的优化使用行为分析系统例子作为分析的对象。
语法
-- 新增projection定义
ALTER TABLE [db].table ADD PROJECTION name ( SELECT <COLUMN LIST EXPR> [GROUP BY] [ORDER BY] )
-- 删除projection定义并且删除projection数据
ALTER TABLE [db].table DROP PROJECTION name
-- 物化原表的某个partition数据
ALTER TABLE [db.]table MATERIALIZE PROJECTION name IN PARTITION partition_name
-- 删除projection数据但不删除projection定义
ALTER TABLE [db.]table CLEAR PROJECTION name IN PARTITION partition_name
实例
CREATE DATABASE IF NOT EXISTS tea_data;
创建原始数据表
CREATE TABLE tea_data.events(
app_id UInt32,
user_id UInt64,
event_type UInt64,
cost UInt64,
action_duration UInt64,
display_time UInt64,
event_date Date
) ENGINE = CnchMergeTree PARTITION BY toDate(event_date)
ORDER BY
(app_id, user_id, event_type);
创建projection前写入2023-05-28分区测试数据
INSERT INTO tea_data.events
SELECT
number / 100,
number % 10,
number % 3357,
number % 166,
number % 5,
number % 40,
'2023-05-28 05:11:55'
FROM system.numbers LIMIT 100000;
创建聚合projection
ALTER TABLE tea_data.events ADD PROJECTION agg_sum_proj_1
(
SELECT
app_id,
user_id,
event_date,
sum(action_duration)
GROUP BY app_id,
user_id, event_date
);
创建projection后写入2023-05-29分区测试数据
INSERT INTO tea_data.events
SELECT
number / 100,
number % 10,
number % 3357,
number % 166,
number % 5,
number % 40,
'2023-05-29 05:11:55'
FROM system.numbers LIMIT 100000;
Note:CnchMergeTree是Bytehouse特有的引擎
Query Optimizer 扩展 Projection 改写
Bytehouse 优化器
ByteHouse 优化器为业界目前唯一的 ClickHouse 优化器方案。ByteHouse 优化器的能力简单总结如下:
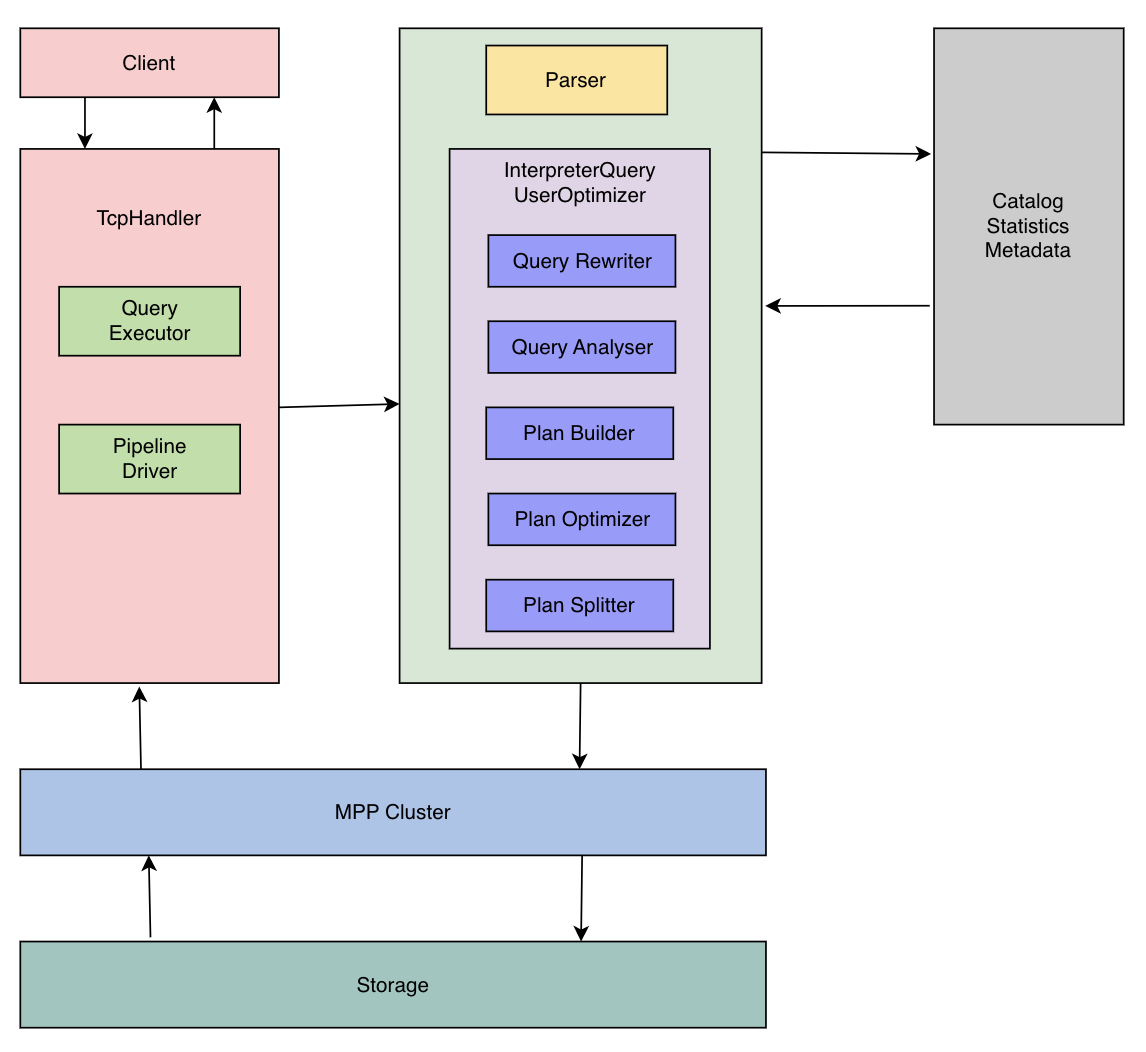
- RBO:支持:列裁剪、分区裁剪、表达式简化、子查询解关联、谓词下推、冗余算子消除、Outer-JOIN 转 INNER-JOIN、算子下推存储、分布式算子拆分等常见的启发式优化能力。
- CBO:基于 Cascade 搜索框架,实现了高效的 Join 枚举算法,以及基于 Histogram 的代价估算,对 10 表全连接级别规模的 Join Reorder 问题,能够全量枚举并寻求最优解,同时针对大于 10 表规模的 Join Reorder 支持启发式枚举并寻求最优解。CBO 支持基于规则扩展搜索空间,除了常见的 Join Reorder 问题以外,还支持 Outer-Join/Join Reorder,Magic Set Placement 等相关优化能力。
- 分布式计划优化:面向分布式 MPP 数据库,生成分布式查询计划,并且和 CBO 结合在一起。相对业界主流实现:分为两个阶段,首先寻求最优的单机版计划,然后将其分布式化。我们的方案则是将这两个阶段融合在一起,在整个 CBO 寻求最优解的过程中,会结合分布式计划的诉求,从代价的角度选择最优的分布式计划。对于 Join/Aggregate 的还支持 Partition 属性展开。
- 高阶优化能力:实现了 Dynamic Filter pushdown、单表物化视图改写、基于代价的 CTE (公共表达式共享)。
借助 bytehouse 优化器强大的能力,针对 projection 原有实现的几点局限性做了优化,下面我们先来看一下社区在 projection 改写的具体实现。
社区 Projection
改写实现在非优化器执行模式下,对原始表的聚合查询可通过 aggregate projection 加速,即读取 projection 中的预聚合数据而不是原始数据。计算支持了 normal partition 和 projection partition 的混合查询,如果一个 partition 的 projection 还没物化,可以使用原始数据进行计算。
具体改写执行逻辑:
- 计划阶段
- 将原查询计划和已有 projection 进行匹配筛选能满足查询要求的 projection candidates;
- 基于最小的 mark 读取数选择最优的 projection candidate;
- 对原查询计划中的 ActionDAG 进行改写和折叠,之后用于 projection part 数据的后续计算;
- 将当前数据处理阶段提升到 WithMergeableState;
- 执行阶段
- MergeTreeDataSelectExecutor 会将 aggregate 之前的计算进行拆分:对于 normal part,使用原查询计划进行计算;对于 projection part,使用改写后 ActionDAG 构造 QueryPipeline;
- 将两份数据合并,用于 aggregate 之后的计算。
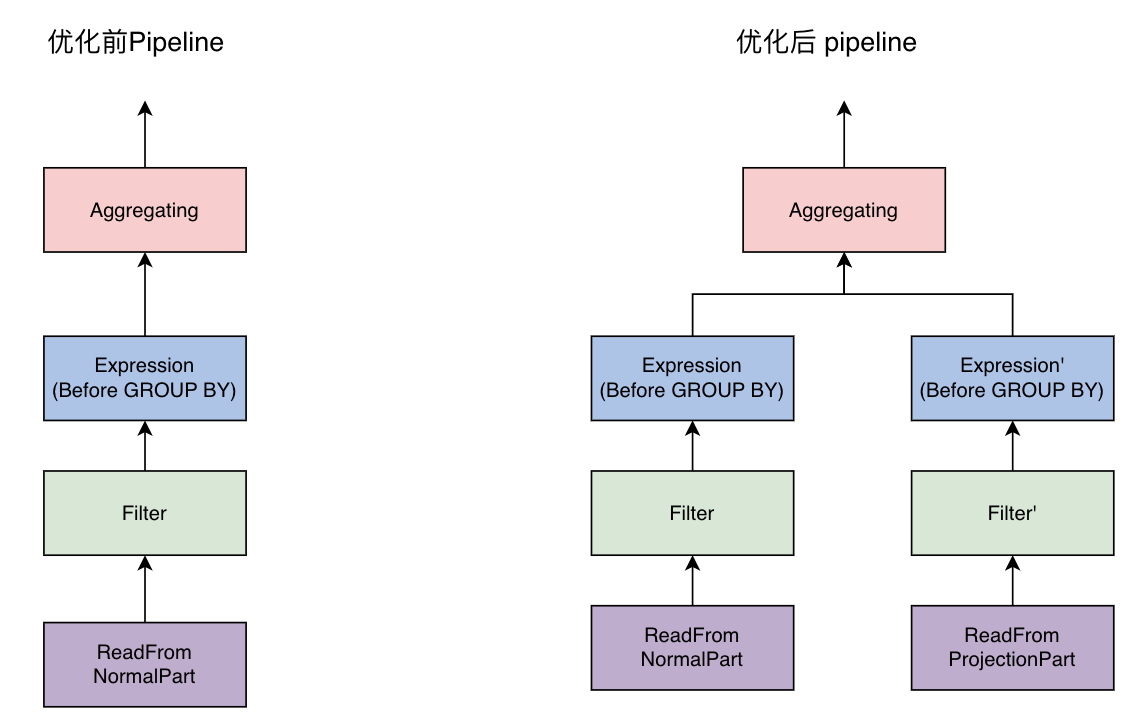
Bytehouse 优化器改写实现
优化器会将查询切分为不同的 plan segment 分发到 worker 节点并行执行,segment 之间通过 exchange 交换数据,在 plan segment 内部根据 query plan 构建 pipeline 执行,以下面简单聚合查询为例,说明优化器如何匹配 projection。
Q1:
SELECT
app_id,
user_id,
sum(action_duration)
FROM tea_data.eventsWHERE event_date = '2023-05-29'
GROUP BY
app_id,
user_id
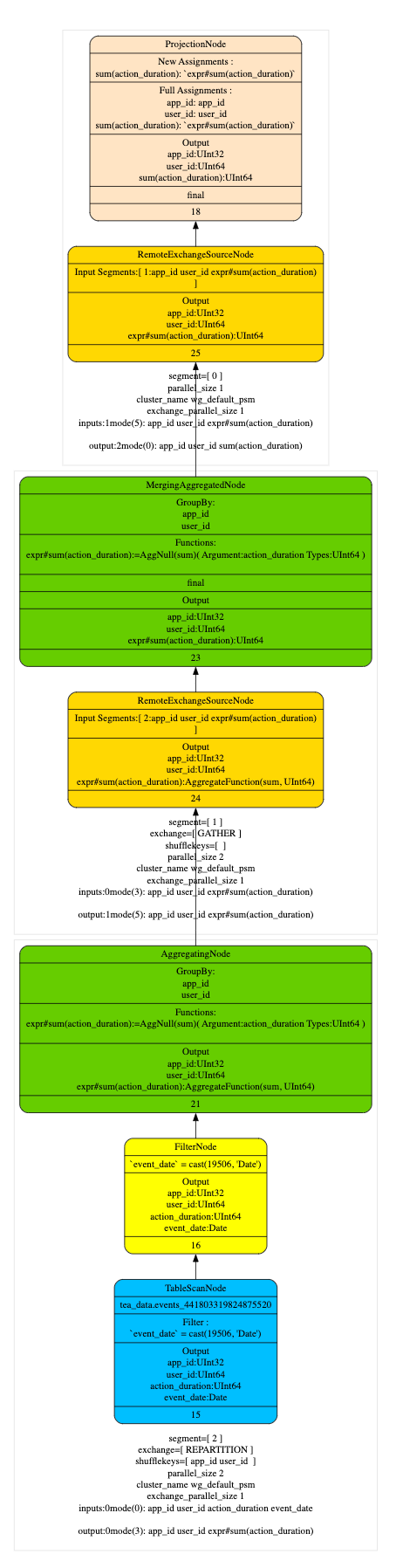
在执行计划阶段优化器尽量的将 TableScan 上层的 Partial Aggregation Step,Projection 和 Filter 下推到 TableScan 中,在将 plan segment 发送到 worker 节点后,在根据查询代价选择合适 projection 进行匹配改写,从下面的执行计划上看,命中 projection 会在 table scan 中直接读取 AggregateFunction(sum, UInt64)的 state 数据,相比于没有命中 projection 的执行计划减少了 AggregaingNode 的聚合运算。
- Q1 查询计划(optimizer_projection_support=0)
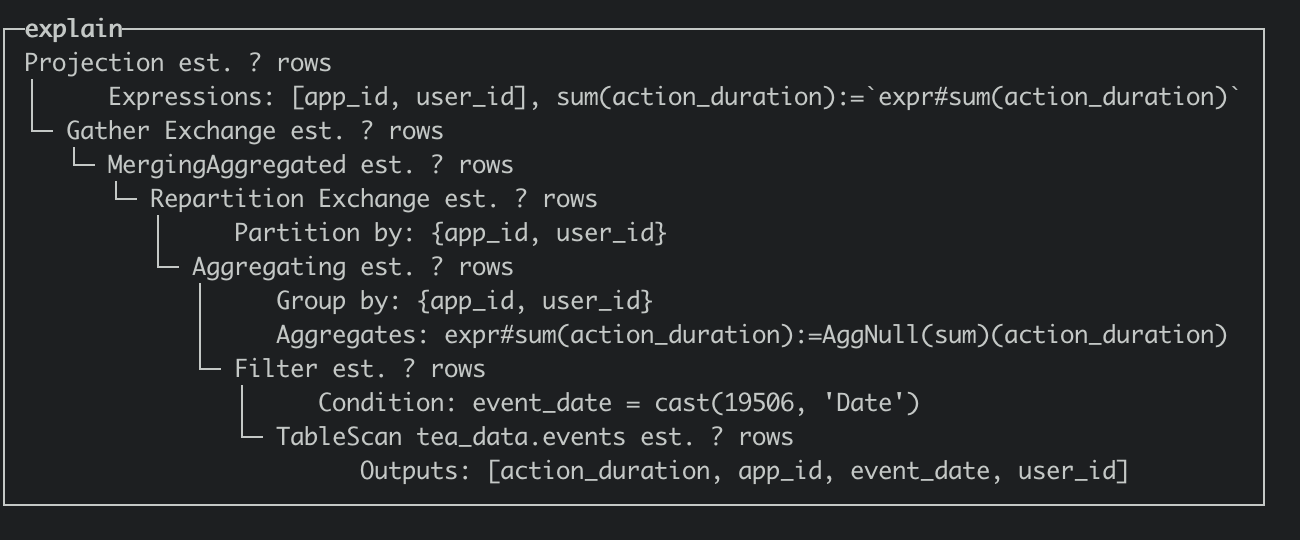
- Q1 查询计划(optimizer_projection_support=1)
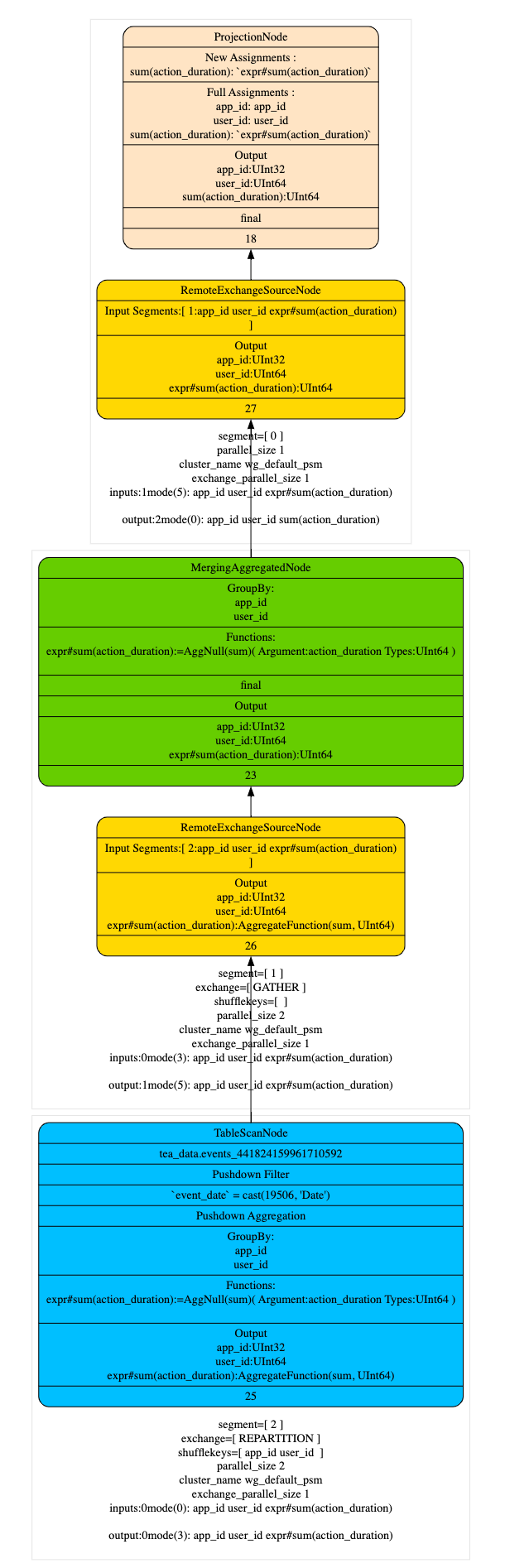
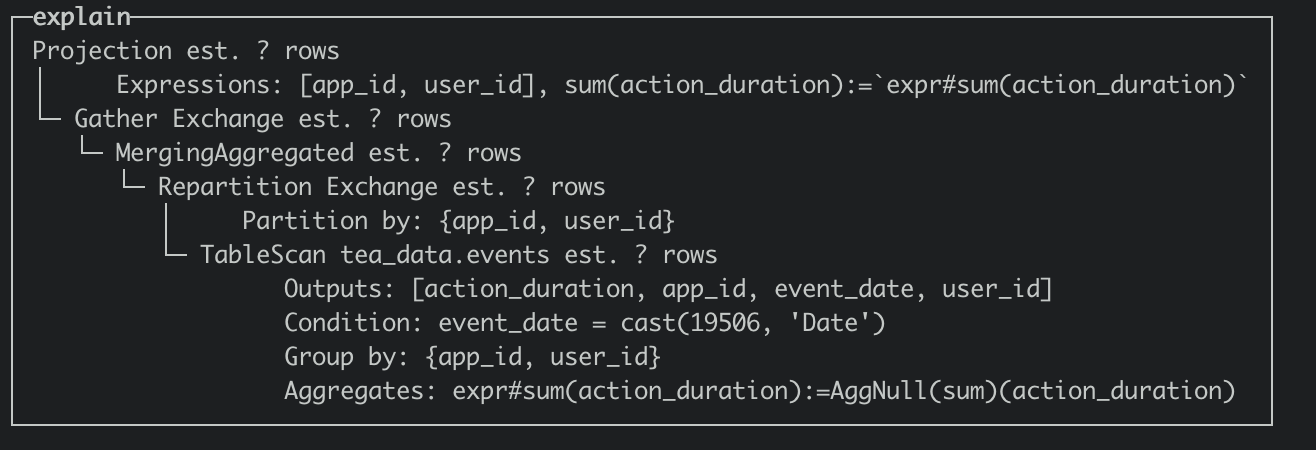
混合读取 Projection
Projection 在创建之后不支持更新 schema,只能创建新的 projection,但是在一些对于 projection schema 变更需求频繁业务场景下,需要同一个查询既能够读取旧 projection 也能读取新 projection,所以在匹配时需要从 partition 维度进行匹配而不是从 projection 定义的维度进行匹配,混合读取不同 projection 的数据,这样会使查询更加灵活,更好的适应业务场景,下面举个具体的实例:
创建新的projection
ALTER TABLE tea_data.events ADD PROJECTION agg_sum_proj_2
(
SELECT
app_id,
sum(action_duration),
sum(cost)
GROUP BY app_id
);
写入2023-05-30的数据
INSERT INTO tea_data.events
SELECT
number / 10,
number % 100,
number % 23,
number % 3434,
number % 23,
number % 55,
'2023-05-30 04:12:43'
FROM system.numbers LIMIT 100000;
执行查询
Q2:
SELECT
app_id,
sum(action_duration)
FROM tea_data.events
WHERE event_date >= '2023-05-28'
GROUP BY app_id
- Q2 执行计划
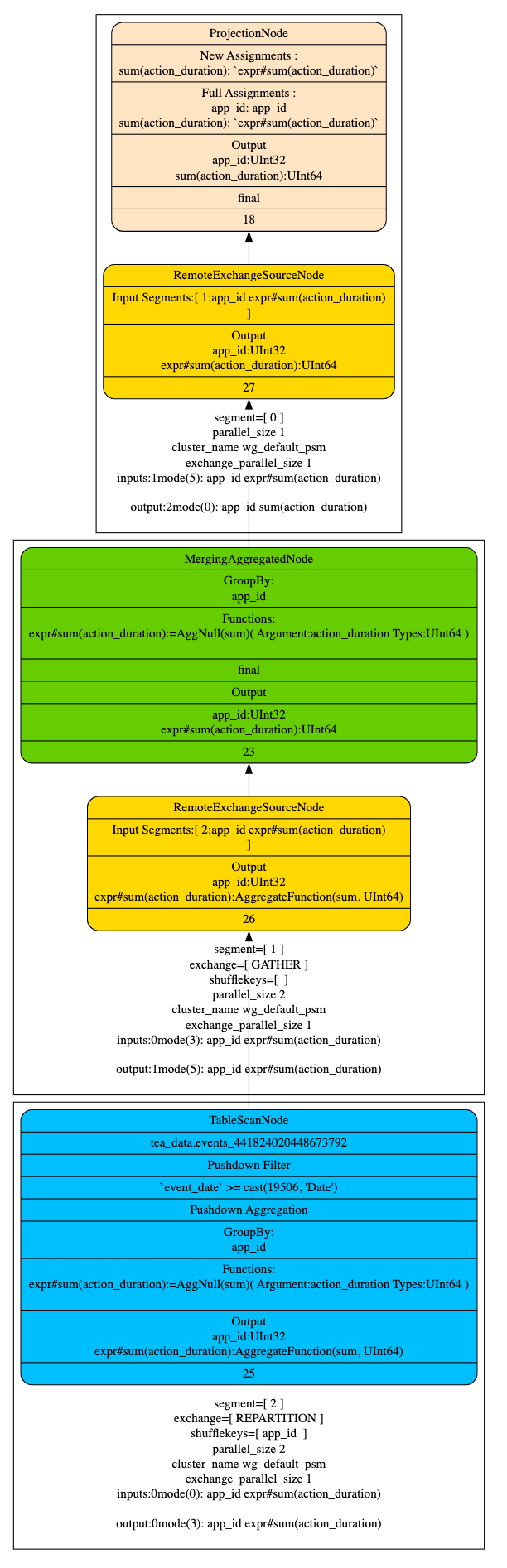
- 按照 partition 来匹配 projection
查询过滤条件 WHERE event_date >= ‘2023-05-28’ 会读取是三个分区的数据, 并且 agg_sum_proj_1, agg_sum_proj_2 都满足 Q2 的查询条件,所以 table scan 会读取 2023-05-28 的原始数据,2023-05-29 会读取 agg_sum_proj_1 的数据,2023-05-30 由于 agg_sum_proj_2 相对于 agg_sum_proj_1 的数据聚合度更高,读取代价较小,选择读取 agg_sum_proj_2 的数据,混合读取不同 projection 的数据。
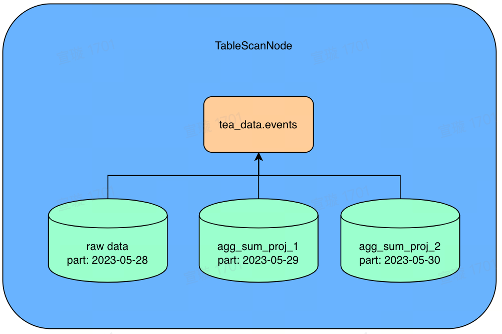
原始表 Schema 更新
当对原始表添加新字段(维度或指标 ),对应 projection 不包含这些字段,这时候为了利用 projection 一般情况下需要删除 projection 重新做物化,比较浪费资源,如果优化器匹配算法能正确处理不存在缺省字段,并使用缺省值参与计算就可以解决这个问题。
ALTER TABLE tea_data.events ADD COLUMN device_id String after event_type;
ALTER TABLE tea_data.events ADD COLUMN stay_time UInt64 after device_id;
执行查询
Q3:
SELECT
app_id,
device_id,
sum(action_duration),
max(stay_time)
FROM tea_data.events
WHERE event_date >= '2023-05-28'
GROUP BY app_id,device_id
- Q3 执行计划
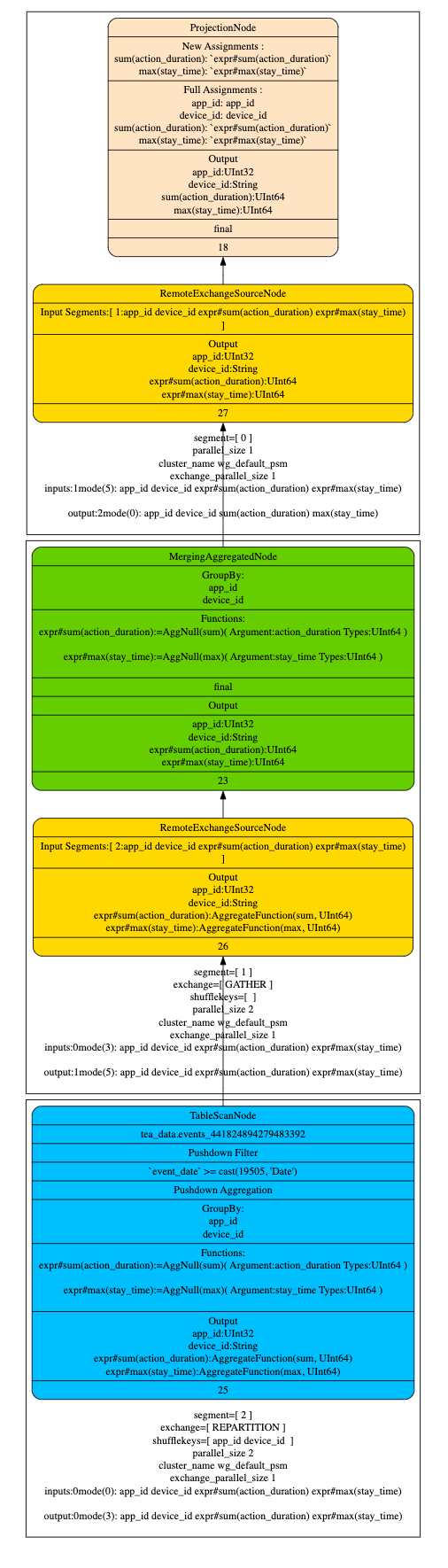
- 默认值参与计算
从查询计划可以看出,即使 agg_sum_proj_1 和 agg_sum_proj_2 并不包含新增的维度字段 device_id,指标字段 stay_time, 仍然可以命中原始的 partiton 的 projection,并且使用默认值来参与计算,这样可以利用旧的 projection 进行查询加速。
Bytehouse Projection 实现
Projection 是按照 Bytehouse 的存算分离架构进行设计的,Projecton 数据由分布式存储统一进行管理,而针对 projection 的查询和计算则在无状态的计算节点上进行。相比于社区版,Bytehouse Projection 实现了以下优势:
- 对于 Projection 数据的存储节点和计算节点可以独立扩展,即可以根据不同业务对于 Projection 的使用需求,增加存储或者计算节点。
- 当进行 Projection 查询时,可以根据不同 Projection 的数据查询量来分配计算节点的资源,从而实现资源的隔离和优化,提高查询效率。
- Projection 的元数据存储十分轻量,在业务数据急剧变化的时候,计算节点可以做到业务无感知扩缩容,无需额外的 Projection 数据迁移。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OXCQGex3-1686027117180)(/img/bVc8ev0)]
Projection 数据存储
在 Bytehouse 中,多个 projections 数据与 data 数据存储在一个共享存储文件中。文件的外部数据对 projections 内部的内容没有感知,相当于一个黑盒。当需要读取某个 projection 时,通过 checksums 里面存储的 projection 指针,定位到特定 projection 位置,完成 projection 数据解析与加载。
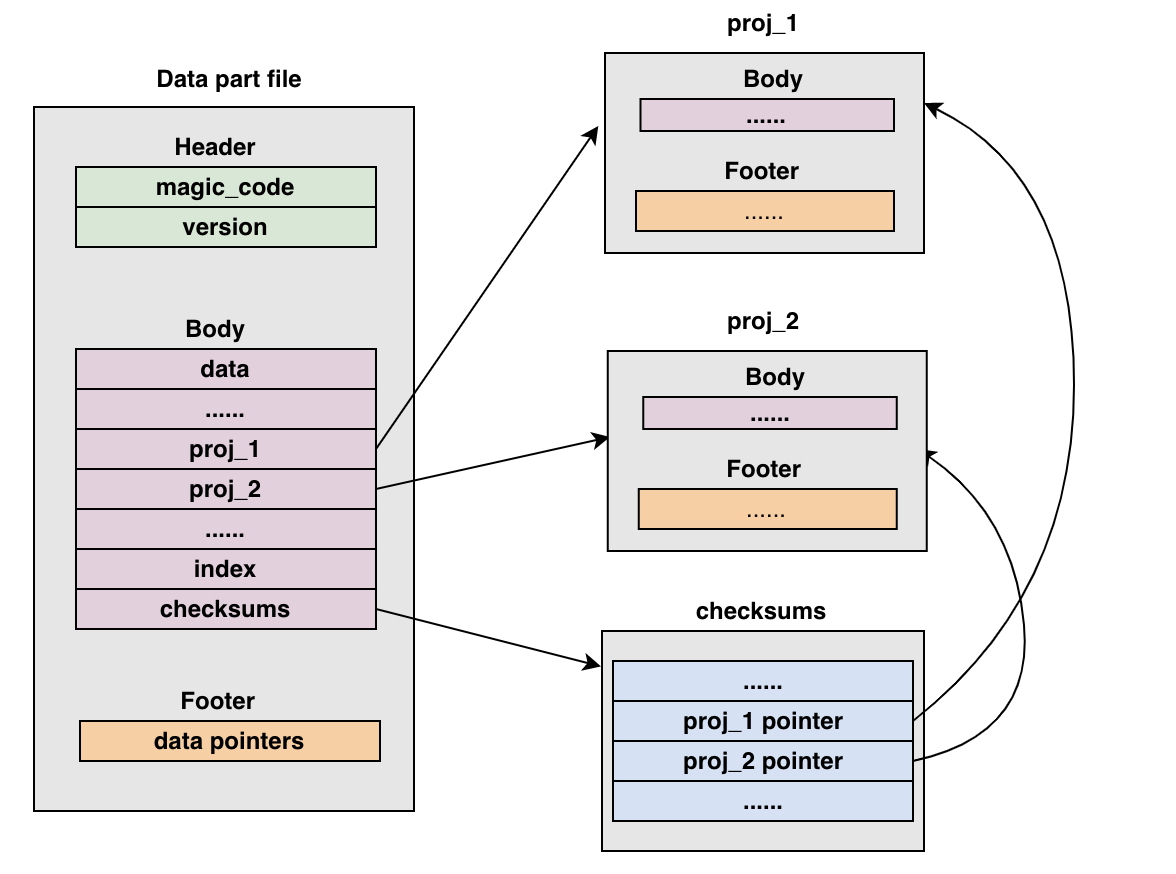
Write 操作
Projection 写入分为两部分,先在本地做数据写入,产生 part 文件存储在 worker 节点本地,然后通过 dumpAndCommitCnchParts 将数据 dump 到远程共享存储。
- 写入本地
通过 writeTempPart()将 block 写入本地,当写完原始 part 后,循环通过方法 addProjectionPart()将每一个 projection 写入 part 文件夹,并添加到 new_part 中进行管理。 - dump 到远程存储
dumpCnchParts()的时候,按照上述的存储格式,写入完原始 part 中的 bin 和 mark 数据后,循环将每一个 projection 文件夹中的数据写入到共享存储文件中,并记录位置和大小到 checksums,如下:
写入 header
写入 data
写入 projections
写入 Primary index
写入 Checksums
写入 Metainfo
写入 Unique Key Index
写入 data footger
Merge 操作
随着时间的推移,针对同一个 partition 会存在越来越多的 parts,而 parts 越多查询过滤时的代价就会越大。因此,Bytehouse 在后台进程中会 merge 同一个 partition 的 parts 组成更大的 part,从而减少 part 的数量提高查询的效率。
- 对于每一个要 merge 的 part
对于 part 中的每一列,缓存对应的 segments 到本地
创建 MergeTreeReaderStreamWithSegmentCache,通过远程文件 buffer 或者本地 segments 的 buffer 初始化 - 通过 MergingSortedTransform 或 AggregatingSortedTransform 等将 sources 融合成 PipelineExecutingBlockInputStream
- 创建 MergedBlockOutputStream
- 对于 projection,进行如下操作
- 建立每一个 projection 的读取流,本地缓存 buffer 或者远程文件 buffer
- 原始表 merge 过程,对 parts 中的 projections 进行 merge
- 通过 dumper 将新的完整 part 存储到远端
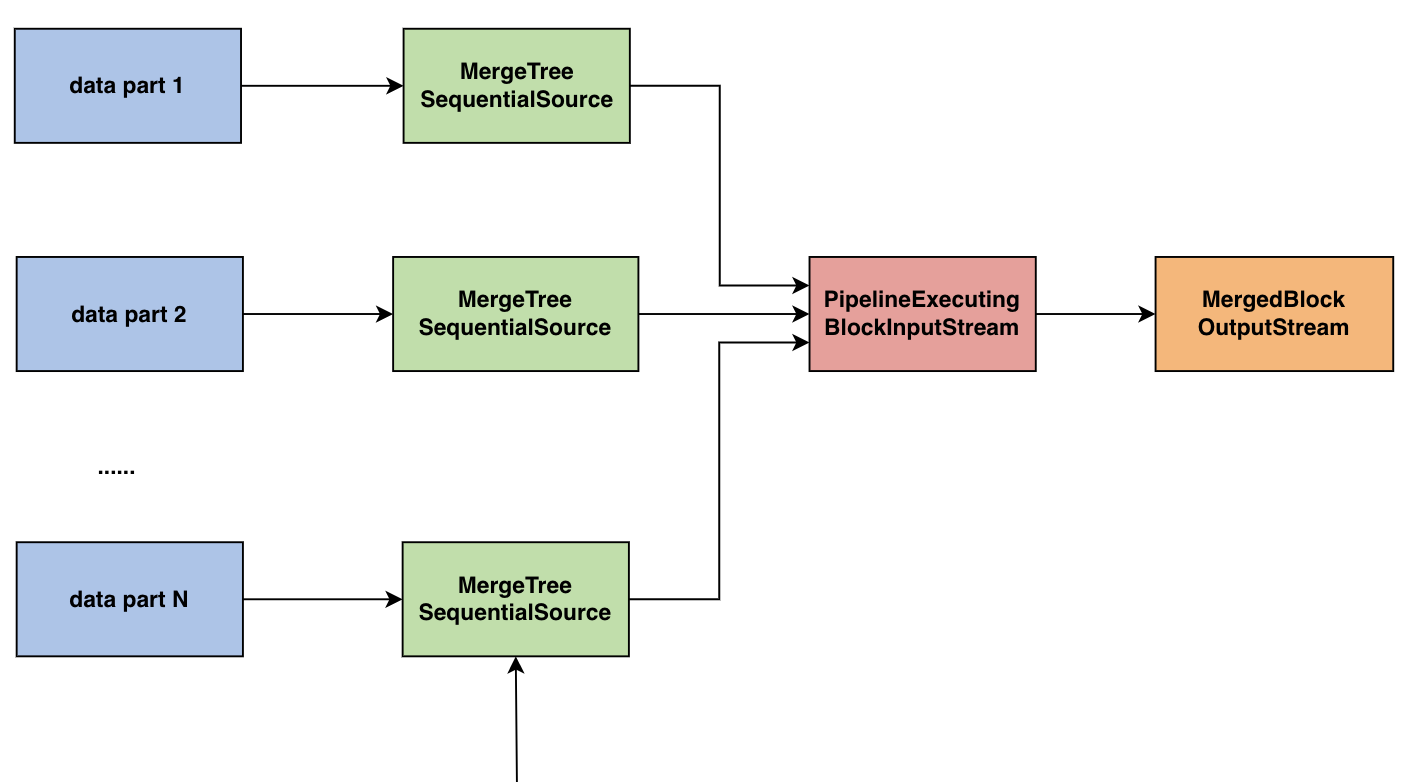
Mutate 操作
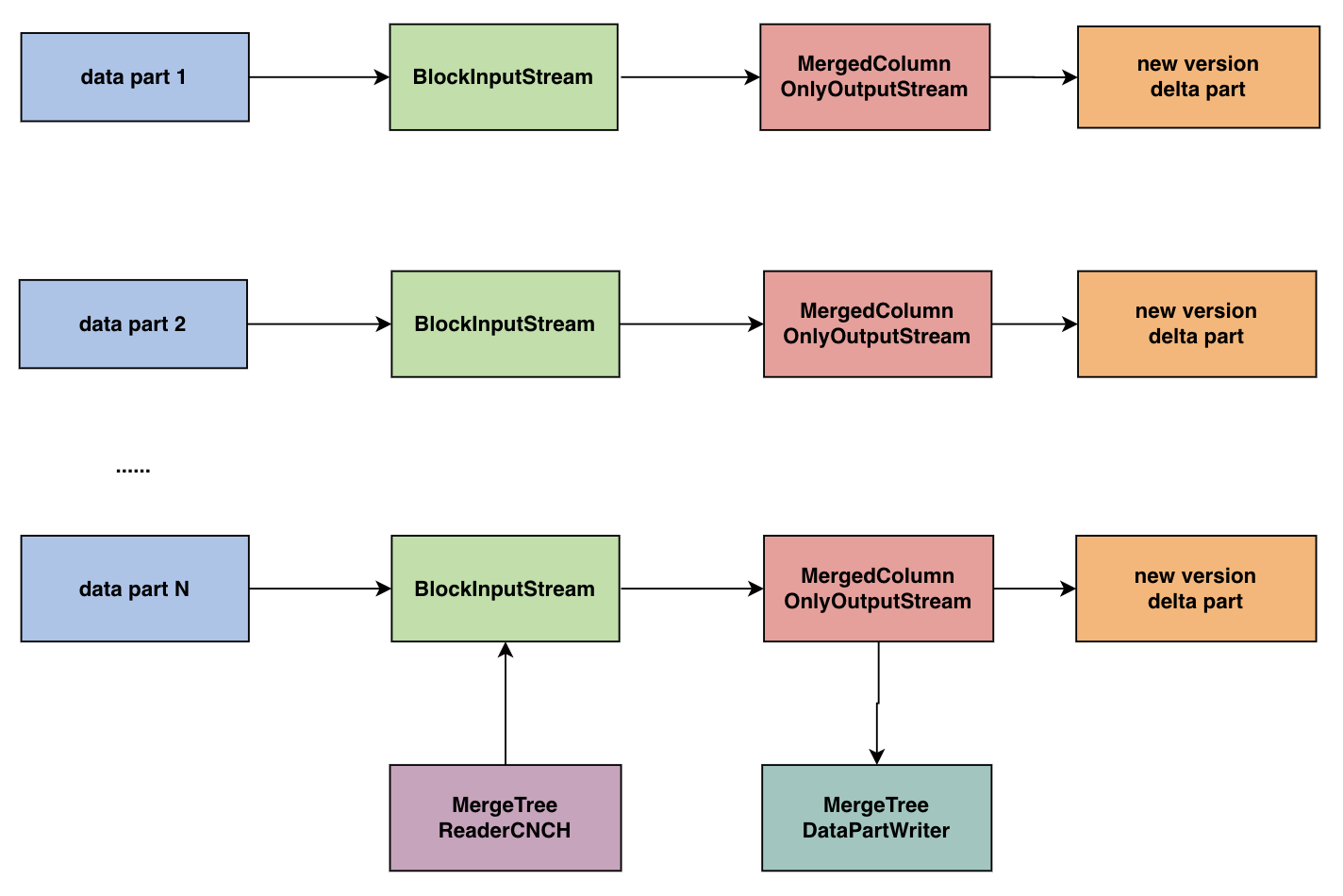
Bytehouse 采用 MVCC 的方式,针对 mutate 涉及的列,新增一个 delta part 版本存储此次 mutate 涉及到的列。相应地,我们在 mutate 的时候,构造 projection 的 mutate 操作的 inputstream,将 mutate 后的 projection 和原始表数据一起写到同一个 delta part 中。
- 在 MutationsInterpreter 里面,通过 InterpreterSelectQuery(mutation_ast)获取 BlockInputStream
- projection 通过 block 和 InterpreterSelectQuery(projection.ast)重新构建
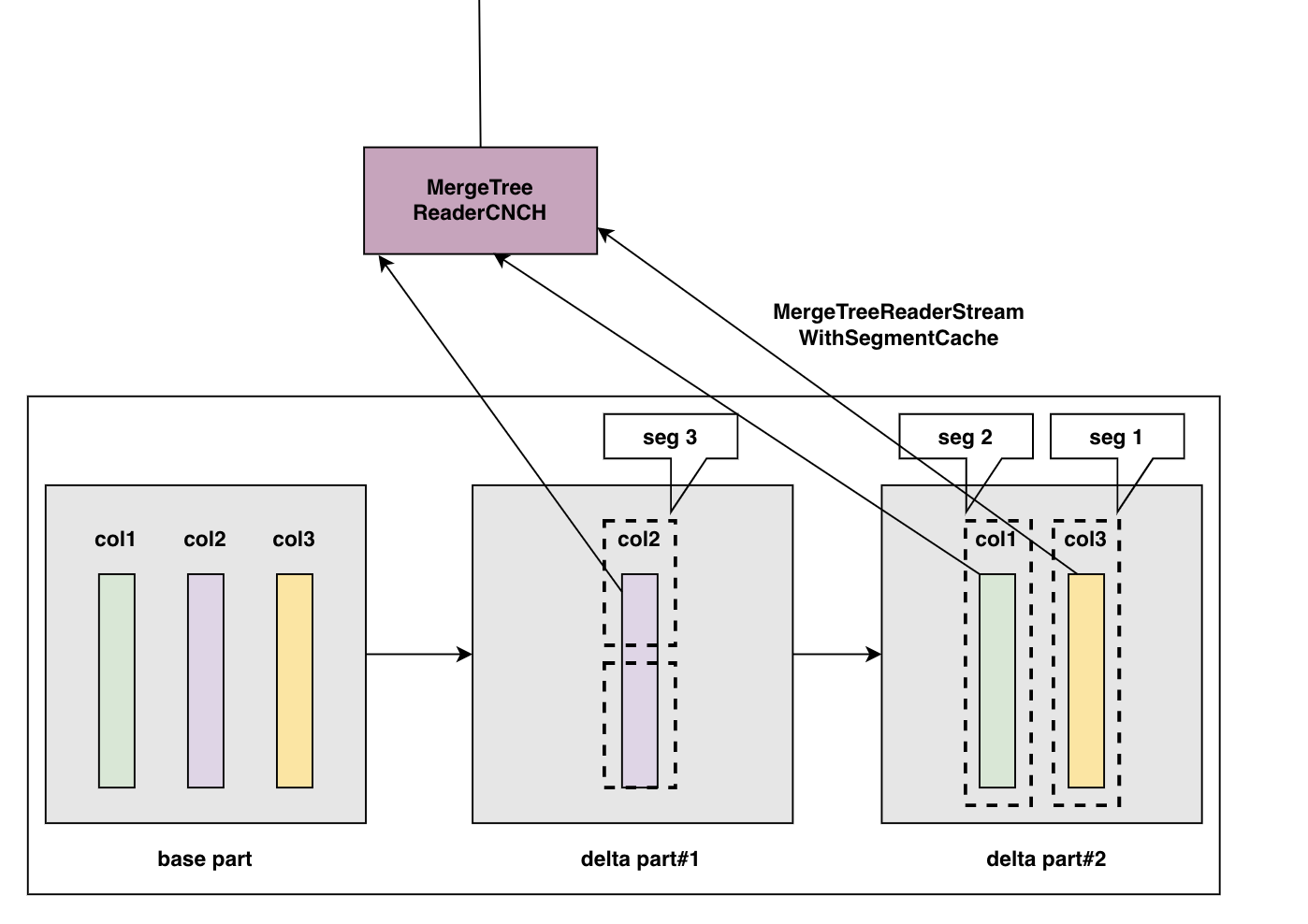
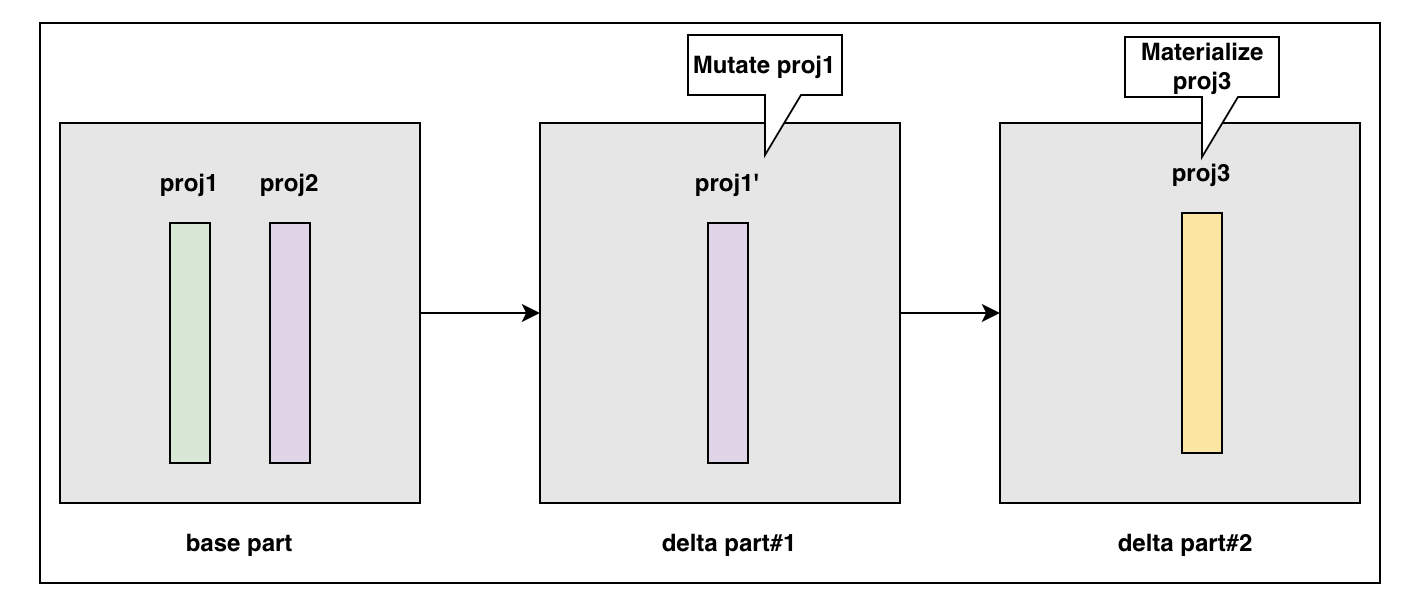
Materialize 物化操作
如下图所示,根据 Bytehouse 的 part 管理方式,针对 mutate 操作或新增物化操作,我们为 part 生成新的 delta part,在下图 part 中,它所管理的三个 projections 由 base part 中的 proj2,delta part#1 中的 proj1’,以及 delta part#2 中的 proj3 共同构成。当 parts 加载完成后,delta part#2 会存储 base part 中的 proj2 的指针和 delta part#1 中的 proj1’指针,以及自身的 proj3 指针,对上层提供统一的访问服务。
Worker 端磁盘缓存
目前,CNCH 中针对不同数据设计了不同的缓存类型
- DiskCacheSegment:管理 bin 和 mark 数据
- ChecksumsDiskCacheSegment:管理 checksums 数据
- PrimaryIndexDiskCacheSegment:管理主键索引数据BitMapIndexDiskCacheSegment:管理 bitmap 索引数据
针对 Projection 中的数据,分别通过上述的 DiskCache,ChecksumsDiskCache 和 PrimaryIndexDiskCache 对 bin,mark,checksums 以及索引进行缓存。
另外,为了加快 Projection 数据的加载过程,我们新增了 MetaInfoDiskCacheSegment 用于缓存 Projection 相关的元数据信息。
实际案例分析
某真实用户场景的数据集,我们利用它对 Projection 性能进行了测试。
该数据集约 1.2 亿条,包含 projection 约 240G 大小,测试机器 80CPU(s) / 376G Mem,配置如下:
- SET allow_experimental_projection_optimization = 1
- use_uncompressed_cache = true
- max_threads = 1
- log_level = error
- 开启 Projection 查询并发度 80,关闭 Projection 查询并发度为 30
测试结果
开启 Projection 后,针对 1.2 亿条的数据集,查询性能提升 10~20 倍。

表结构
CREATE TABLE user.trades(
`type` UInt8,
`status` UInt64,
`block_hash` String,
`sequence_number` UInt64,
`block_timestamp` DateTime,
`transaction_hash` String,
`transaction_index` UInt32,
`from_address` String,
`to_address` String,
`value` String,
`input` String,
`nonce` UInt64,
`contract_address` String,
`gas` UInt64,
`gas_price` UInt64,
`gas_used` UInt64,
`effective_gas_price` UInt64,
`cumulative_gas_used` UInt64,
`max_fee_per_gas` UInt64,
`max_priority_fee_per_gas` UInt64,
`r` String,
`s` String,
`v` UInt64,
`logs_count` UInt32,
PROJECTION tx_from_address_hit
(
SELECT *
ORDER BY from_address
),
PROJECTION tx_to_address_hit (
SELECT *
ORDER BY to_address
),
PROJECTION tx_sequence_number_hit (
SELECT *
ORDER BY sequence_number
),
PROJECTION tx_transaction_hash_hit (
SELECT *
ORDER BY transaction_hash
)
)
ENGINE=CnchMergeTree()
PRIMARY KEY (transaction_hash, from_address, to_address)
ORDER BY (transaction_hash, from_address, to_address)
PARTITION BY toDate(toStartOfMonth(`block_timestamp`));
开启Projection
Q1
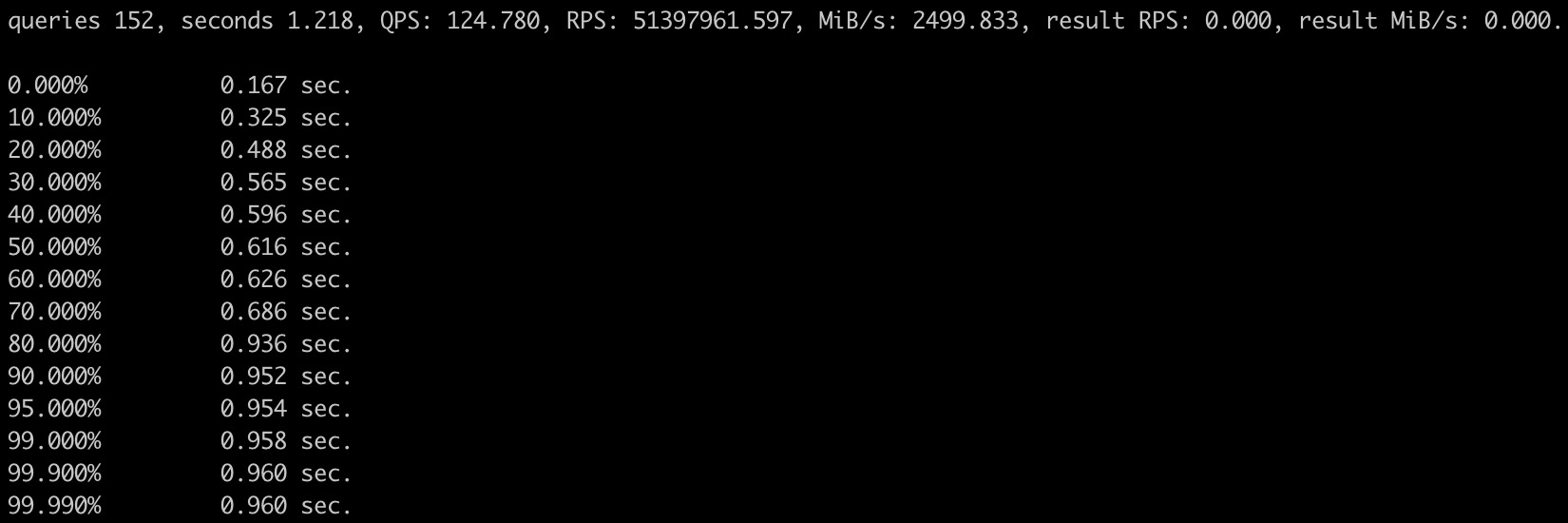
WITH tx AS ( SELECT * FROM user.trades WHERE from_address = '0x9686cd65a0e998699faf938879fb' ORDER BY sequence_number DESC,transaction_index DESC UNION ALL SELECT * FROM user.trades WHERE to_address = '0x9686cd65a0e998699faf938879fb' ORDER BY sequence_number DESC, transaction_index DESC ) SELECT * FROM tx LIMIT 100;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xZ0YQjwV-1686027117184)(/img/bVc8ewb)]
Q2
with tx as (select sequence_number, transaction_index, transaction_hash, input from user.trades where from_address = '0xdb03b11f5666d0e51934b43bd' order by sequence_number desc,transaction_index desc UNION ALL select sequence_number, transaction_index, transaction_hash, input from user.trades where to_address = '0xdb03b11f5666d0e51934b43bd' order by sequence_number desc, transaction_index desc) select sequence_number, transaction_hash, substring(input,1,8) as func_sign from tx order by sequence_number desc, transaction_index desc limit 100 settings max_threads = 1, allow_experimental_projection_optimization = 1, use_uncompressed_cache = true;
关闭 Projection
Q1
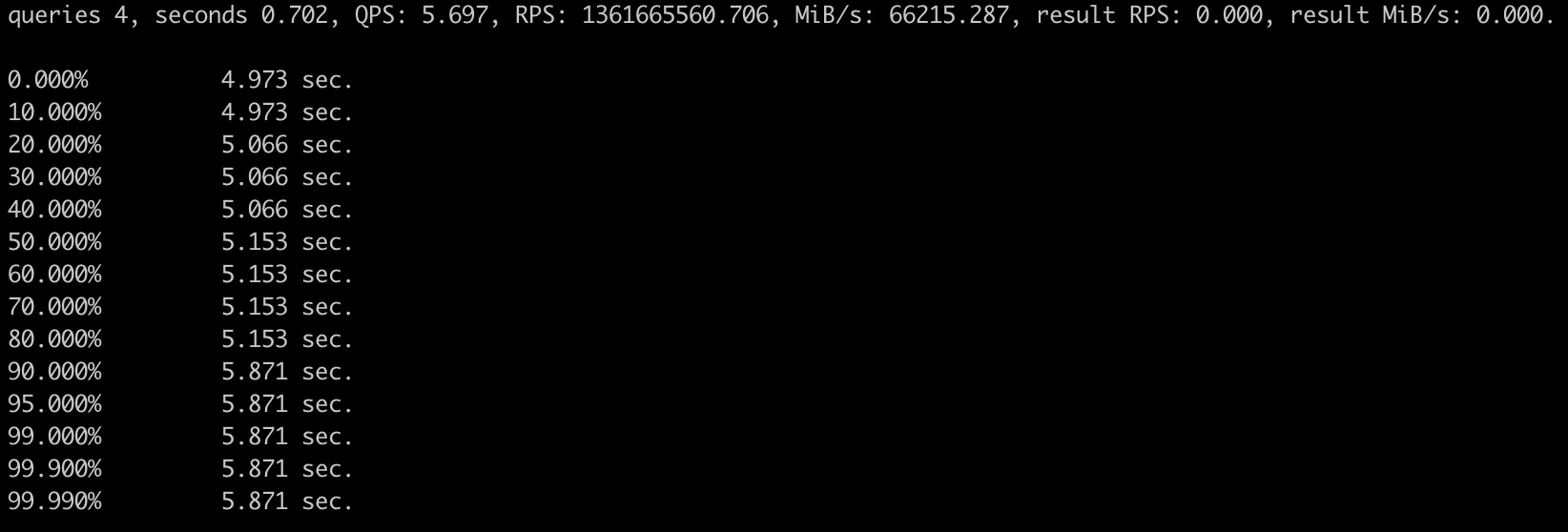
Q2