Transformer目录
- Transformer介绍
- Seq2seq结构
- Encoder结构
- Decoder结构
- Autoregressive Decoder(AT):
- Encoder和Decoder对比和联系
- Cross attention:
- Non-autoregressive Decoder(NAT):
- 训练Seq2seq Model的Tips
- Copy Mechanism
- Guided Attention
- Beam Search
- 评估标准
- 训练VS测试 出现的问题:
Transformer介绍
Transformer就是一个sequence-to-sequence(Seq2seq)的module
- 第三种:Seq2seq任务:输入 N N N 输出 N ′ N' N′(由机器自己决定输出的个数)
- 例如:语音辨识(一段声音变为文字)、机器翻译任务(文字变为其他语言文字)、语音翻译(一段语音翻译为其他语言文字)
语音辨识:输入声音,输出中文 就是语言辨识。(例如谷歌的pixel4,使用
N
N
N to
N
N
N 的神经网络,使用RNN transducer)
语音合成:输入中文,输出声音就是语音合成。 (音标—>语音 (使用seq2seq model))
Seq2seq在NLP有很多应用,很多问题可以看成QA:
很多问题也可以使用Seq2seq硬解,例如文法剖析(Grammar as Foreign Language(14年文章)),例如Muti-label Classification(多标签分类,机器自己决定多少个class)、目标检测等。
Seq2seq结构
Seq2seq 结构会分为俩块:Encoder、Decoder
input一个sequence由Encoder负责处理,将处理好的结果丢到Decoder决定输出什么样的sequence(起源:14年9月提出用于翻译(Sequence to Sequence Learning with Neural Networks) )
Encoder结构
Encoder:给一排向量输出另外一排向量。(CNN、RNN、Self-attention都可以做到)
注:在 Transformer 的
Encoder中用的就是Self-attention。
Encoder中会分为很多个Block,每一个Block都是给一排向量输出另外一排向量(每一个Block是好几个 layer 在处理)
Block中是:给一排向量先做Self-attention,再做FC,再输出另外一排向量。

在原来 Transformer 中
Block更为复杂:
给一排向量先做Self-attention,再加上input(a+b)(称为residual),再做 Layer normalization(计算输入向量的mean和standard deviation,做normalize),再做FC(也做residual),再做 Layer normalization,再输出。


Add&Norm :意思就是加上residual + Layer norm
注:Bert 中也会再用到,Bert 其实就是
Transformer中的Encoder
注:原始的
transformer架构并不一定是最好的,做Layer normalization再做residual更换顺序。(文章On Layer Normalization in the Transformer Architecture、PowerNorm:Rethinking Batch Normalization in Transformers)。
下图(a)是原始的transformer架构,(b)是更换顺序的架构

Decoder结构
Decoder有俩种:Autoregressive Decoder(AT)、Non-autoregressive (NAT)
Autoregressive Decoder(AT):
使用语音辨识做例子(输入一段声音,输出文字)
Encoder:输入一段声音向量,输入另外一排向量 ——> Decoder 产生语音辨识的结果。
Decoder流程:
BEGIN或者BOS(begin of seqence)(special token)(one-hot编码) ——>(softmax)中文每一个字对应一个数值(也包括END)——>例如输出“机”字概率最高输出“机”字—— >
把“机”做Decoder新的 input(one-hot 编码)和BEGIN——>输出“器”——>BEGIN、"机"、"器"做 input —— > 输出"学"——>…

Decoder 看到的输入其实是它在前一个时间点自己的输出。Decoder 需自己决定输出sequence的长度。



(其中"机"会被变成 one-hot 的向量"机"是 1 其他都是 0 ,Decoder输出是一个几率的分布,会让这二者越接近越好,所以会计算Ground truth和distribution的cross entropy越小越好)
注:每一次
Decoder在产生一个中文字的时候,其实就是做了一次分类的问题。Decoder的输入就是sequence正确的答案,也称为Teacher Forcing。

Encoder和Decoder对比和联系

transformer Decoder中的Block:
Masked Muti-Head attention——> Add&Norm ——>
(Cross attention是 Encoder 和 Decoder 之间的桥梁)两个输入来自 Encoder,Decoder 提供一个输入——>Muti-Head attention——>Add&Norm——>Feed Forward——>Add&Norm
注:其中
Masked Muti-Head attention指:
之前 Self-sattention 产生 b 1 b^1 b1 是考虑了 a 1 a^1 a1 ~ a 4 a^4 a4 ,现在只能考虑左边的,例如 b 1 b^1 b1 能考虑 a 1 a^1 a1 , b 2 b^2 b2只能考虑 a 1 a^1 a1, a 2 a^2 a2

Cross attention:


Cross attention中:
q
q
q来自 Decoder ,
k
k
k 和
v
v
v 来自 Encoder。
Cross attention一开始来自 Seq2seq 模型(文章 Listen,attend and spell做语音辨识ICASS2016),那时候的 Encoder 和 Decoder 都还是使用LSTM,但是Cross attention已经有了,Cross attention比先Self-attention早诞生。
在原始 Transformer 中: Encoder 和 Decoder 都有很多层, Decoder 无论哪一层都是拿 Encoder 的最后一层的输出。
但是也有很多不同Cross attention的方式:
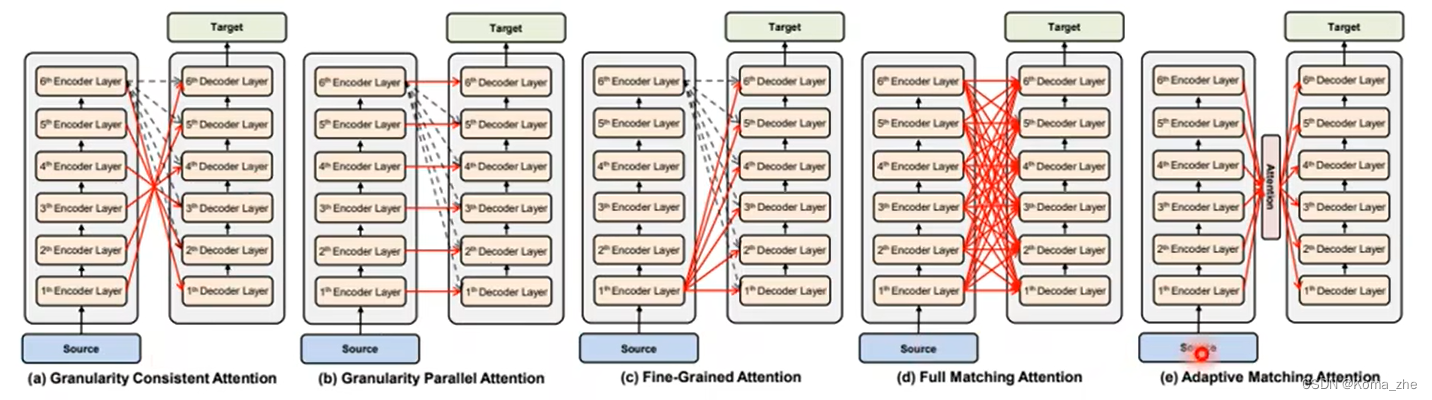
Non-autoregressive Decoder(NAT):
Autoregressive Decoder(AT)、Non-autoregressive Decoder (NAT)区别:
NAT是一个步骤产生一整个句子。
Non-autoregressive (NAT)把一堆一排的BEGIN 的Token都丢给它,让它产生一排Token就结束了(一个步骤完成句子的生成)。

NAT如何解决输出的长度:
一种解决方法:用另外一个 Classifier 由 Encoder 的输出来预测一个 Decoder 需输出的长度——>多少个BEGIN
另外一种解决方法:或者输入很多BEIGIN,在输出的时候定一个END,右边的舍弃。
NAT是由 Transformer 以后有 Self-attention 的 Decoder 以后才有的,以前是LSTM或者RNN就算给一排BEGIN也无法同时产生全部的输出,需一个一个产生。
语音合成现在都可以使用Seq2seq的模型来做,Tacotron是AT的 Decoder ,FastSpeech是NAT的 Decoder。
NAT的Performance往往都不如AT的 Decoder (Muti-Modality问题)
训练Seq2seq Model的Tips
训练 Sequence To Sequence Model(不局限 Transformer )的Tips:
Copy Mechanism
之前讨论中都要求 Decoder 自己产生输出,对很多任务来说 Decoder 可能没有必要自己创造输出,而是从输出复制一些(例如对话机器人、摘要)
注:最早有从输入复制东西能力的模型:
Pointer Network后来有变形的Copy Network(文章Incorporating Copyting Mechanism in Sequence-to-Sequence Learning)
Guided Attention
Seq2seq可能会犯低级的错误,例如漏字了(例如语音辨识,语音合成TTS)
要求机器去 Guide 领导这个 attention 的过程,要求在做 attention 的时候有固定的方式
解决方法方法例如:Monotonic Attention、Location-aware attention

Beam Search
每次 Decoder 输出那个分数最高的 Token ,找分数最高的字 称为 Greedy Decoding ,但是可能不是最好的。
Beam Search为了找一个 Approximate,找一个估测的 Solution。(可能不是特别精准的 Solution )
注:有时候对 Decoder 来说,
Beam Search不一定就是好的(文章The Curious Case of Neural Text Degeneration),没有找出分数最高的路反而结果可能好(跟任务本身特性有关,答案明确的任务例如 语音辨识Beam Search比较有帮助,需要创造力例如TTS语音合成比较差)

评估标准
BLEU score: Decoder 产生一个完整句子后,再跟正确答案一整句做比较。
在训练的时候我们是使用 minmize cross entropy,但是不一定可以 maximize BLEU score。
所以在验证集中应该使用BLEU score。
能否训练就使用
BLEU score?
答:在训练过程使用BLEU score乘负号作为 loss 不太能实现,因为BLEU score不能微分,BLEU score本身复杂,每一个中文字计算cross entropy才能做
训练VS测试 出现的问题:
测试的时候 Decoder 看到自己的输出,所以可能会看到错误的输出,例如“机”“气”(一步错,步步错),训练的时候看到是完全正确的,例如“机”“器”。
不一致的现象称为Exposure bias。

解决方法:给 Decoder 的输入加入错误的东西,不要都是正确的(技术:Schedule Sampling(2015年提出,在LSTM就已经有,文章Original Scheduled Sampling、Scheduled Sampling for Transformer、Paraller Scheduled Sampling),但是会伤害 Transformer 平行化的能力)。






![[附源码]Python计算机毕业设计SSM金牛社区疫情防控系统(程序+LW)](https://img-blog.csdnimg.cn/417db15b077449b8b45f4073bfec11b4.png)
![[附源码]JAVA毕业设计老年人健康饮食管理系统(系统+LW)](https://img-blog.csdnimg.cn/47bec3a52da948c0b5e07b9a18165cf7.png)
![[附源码]计算机毕业设计车源后台管理系统](https://img-blog.csdnimg.cn/107c4e4b04f84972b751d7ef35584073.png)