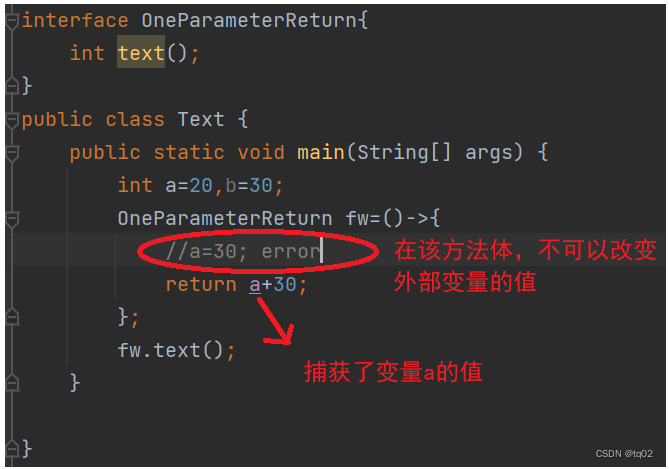
故障的分类

事务故障

系统故障

存储介质故障
只能通过故障来实现.
故障恢复
缓冲池策略

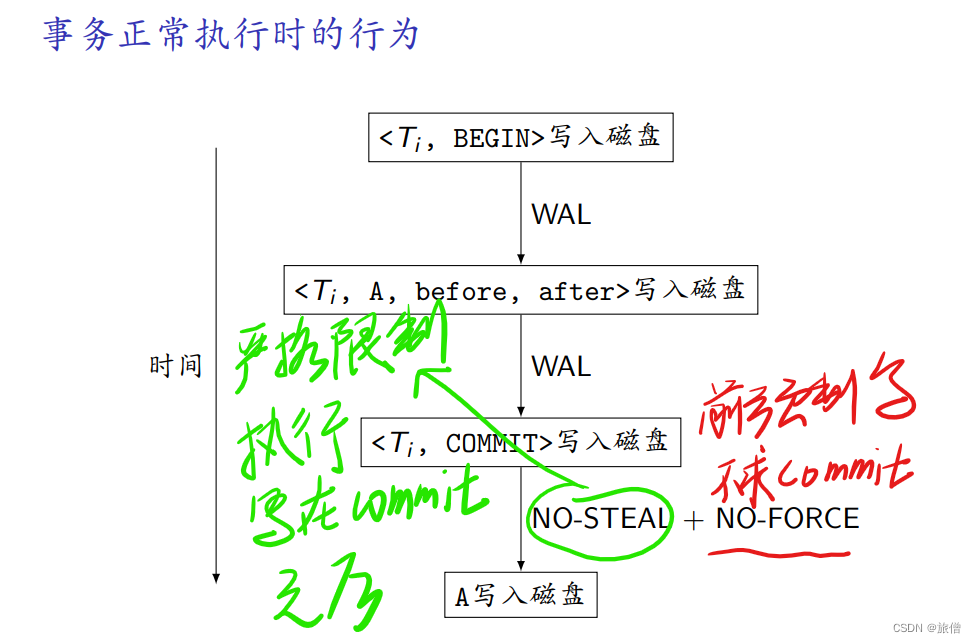
STEAL和FORCE策略:具体内容见课件。
为啥要使用steal和force两种策略 原因:如果不用steal策略 缓冲区就会有大量的脏页,如果使用not force策略 由于对同一个对象进行多次修改,如果每次都是强制写回的话消耗IO的次数比较多,不如只用一次最终的IO。
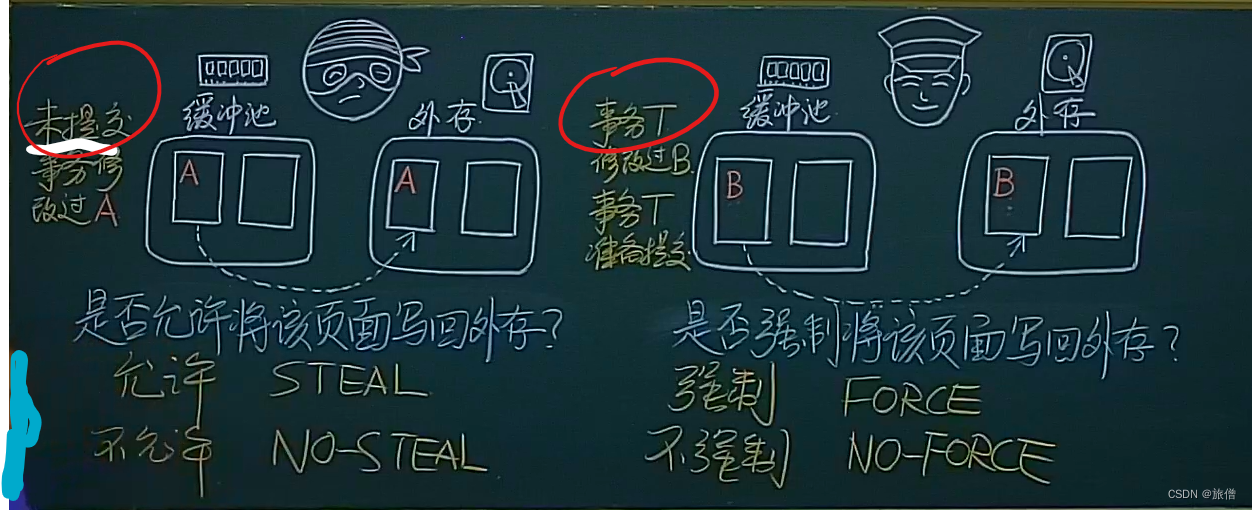
四种组合方式
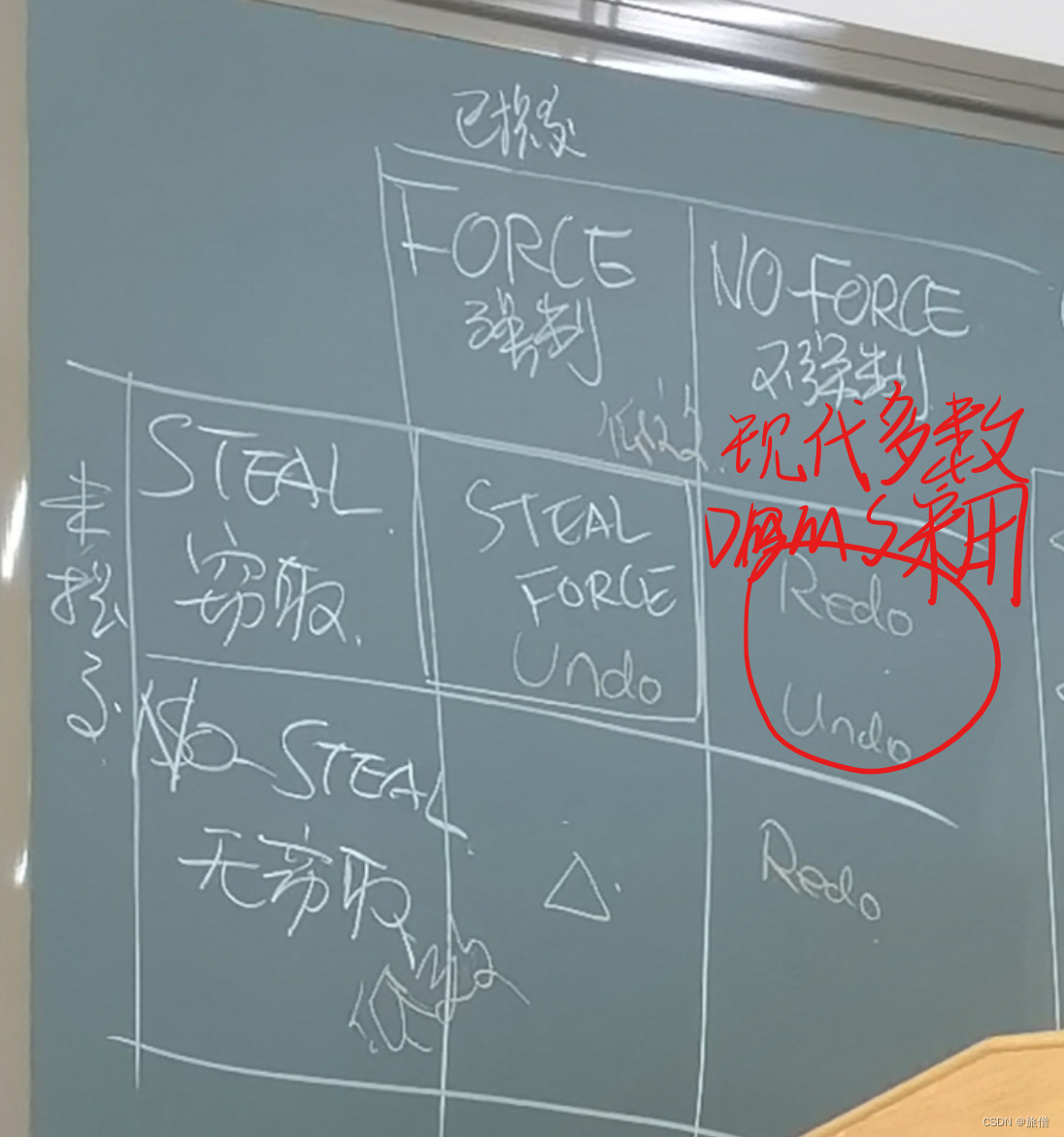
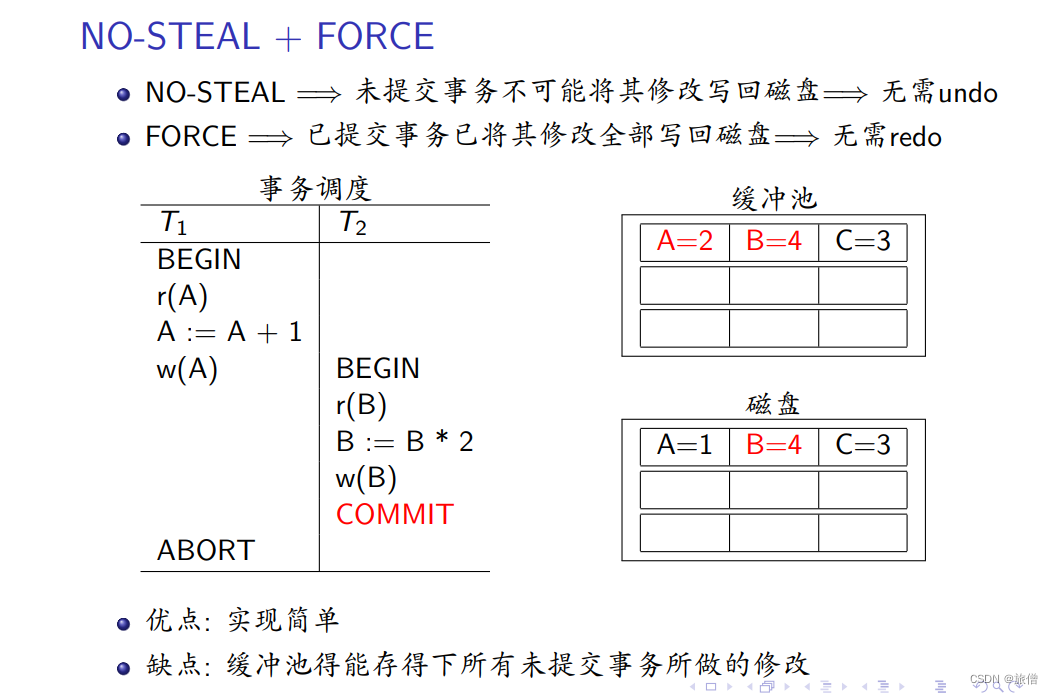
对于另外三种需要采用 预写式日志技术

日志
可以理解成计划、账单,在执行一个动作之前或者动作成功执行之后需要记录一下。
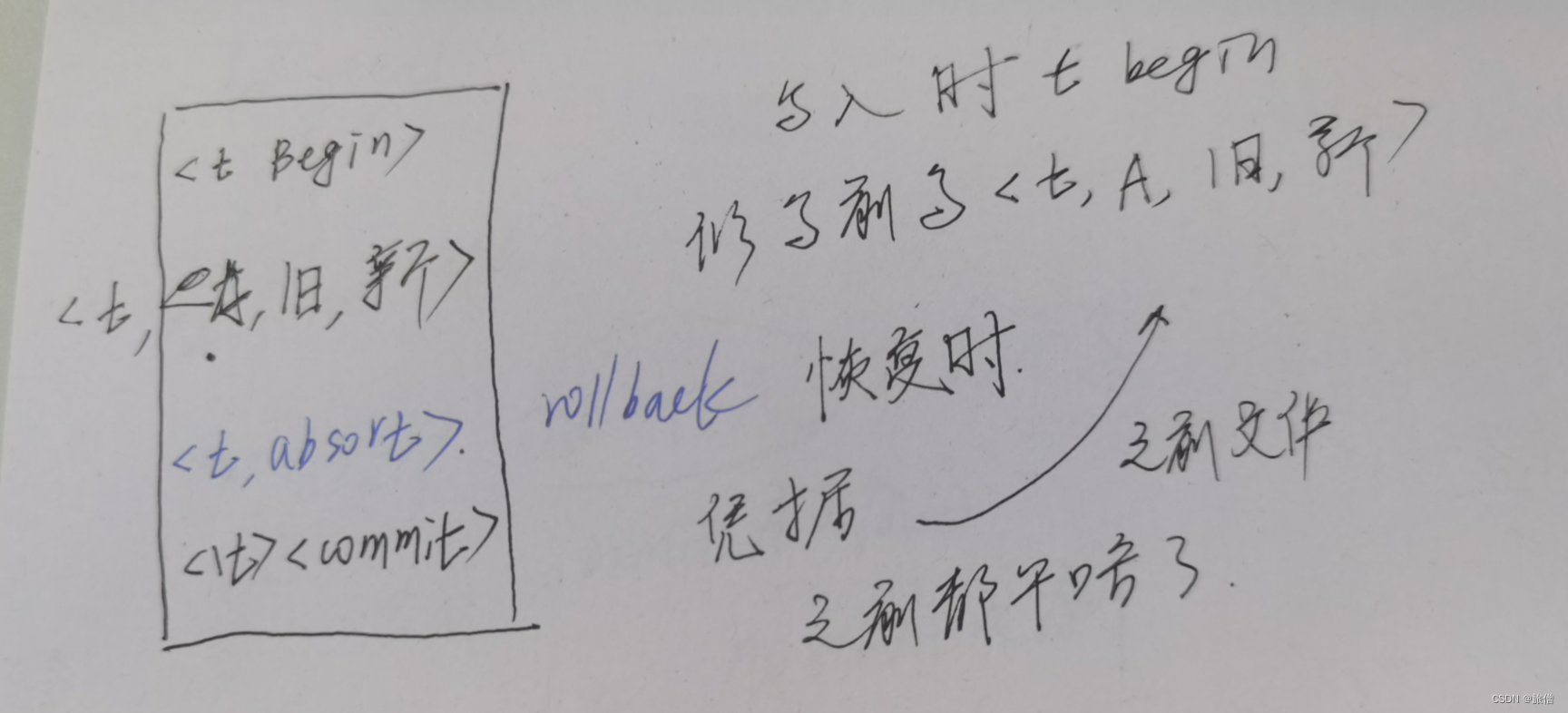


三种WAL协议


Undo logging
force进行强制写入,steal允许一边读一遍把脏页写入。 所以提交之后发生故障需不需要重做取决于force 发生故障 并且commit完毕 不需要恢复 因为他已经写完了。

执行顺序
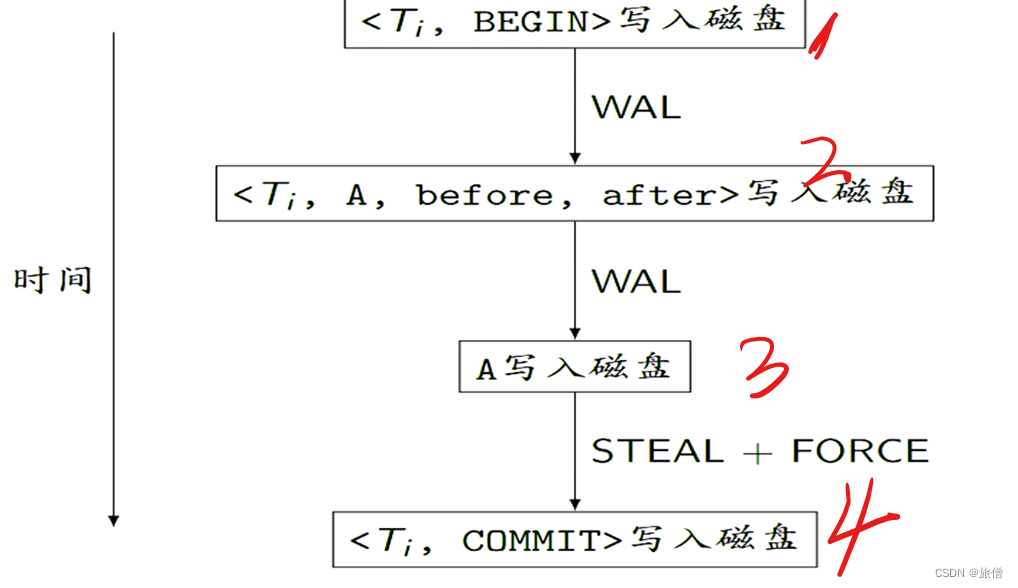
执行这种顺序的原因:

故障恢复 (分commit和非commit情况考虑)


如果在提交之前发生故障 需要undo


Redo logging



几种策略的对比
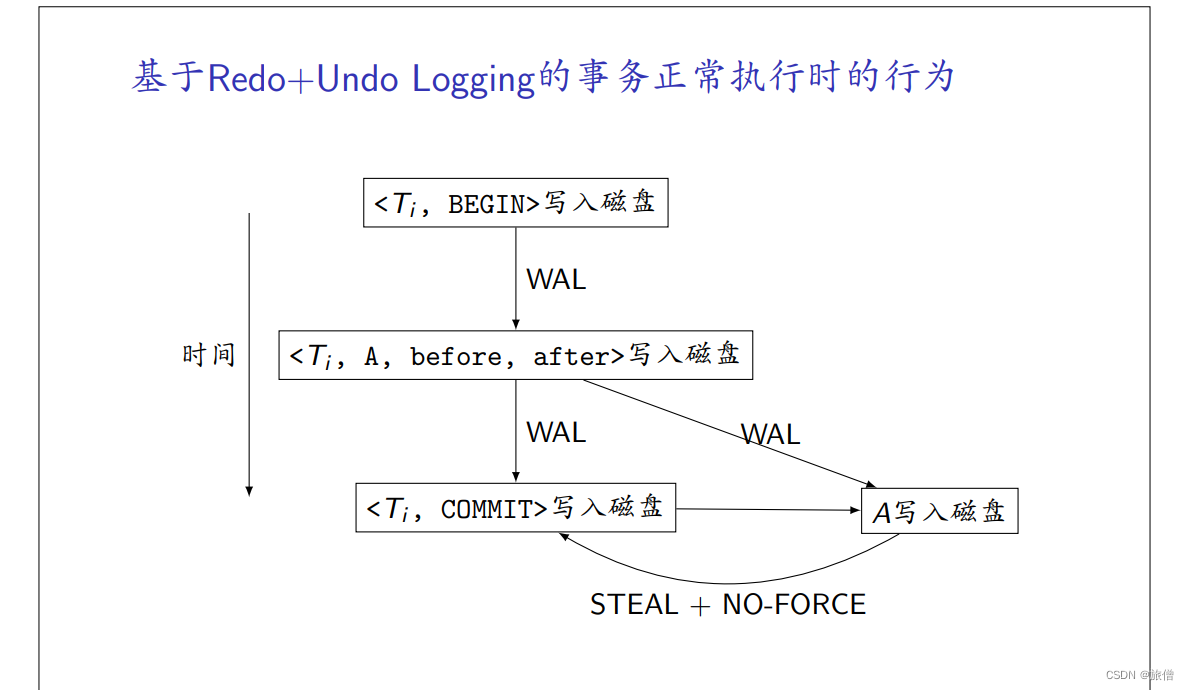
Redo&Undo logging








![[前端语法]js原型链有关的继承问题](https://img-blog.csdnimg.cn/82e7a5c121ea483fbfc6b74aea83fd16.png)