介绍
受到我最近给出的StackOverflow答案的启发,我决定是时候写一篇关于使用JPA和Hibernate时查询分页的文章了。
在本文中,您将了解如何使用查询分页来限制 JDBC大小并避免获取不必要的数据。ResultSet
如何在#Hibernate中使用查询分页来限制 JDBC 结果集的大小并避免获取不必要的数据。@vlad_mihalceahttps://t.co/fkd8ne1mYjpic.twitter.com/Ca78OhlIP1
— Java (@java) 2018 年 10 月 12 日
域模型
现在,假设我们在应用程序中定义了以下实体类:PostPostComment
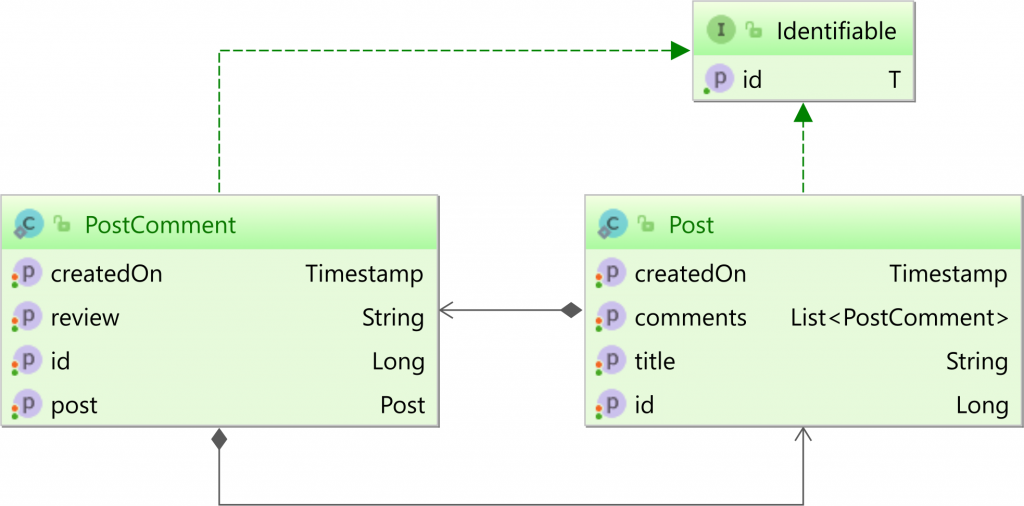
类是父实体,而子实体是子实体,因为它与实体有关联。两个实体都实现了提供用于访问基础实体标识符的协定的接口。PostPostComment@ManyToOnePostIdentifiable
接下来,我们将在数据库中保存以下内容和实体:PostPostComment
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
LocalDateTime timestamp = LocalDateTime.of(
2018, 10, 9, 12, 0, 0, 0
);
int commentsSize = 5;
LongStream.range(1, 50).forEach(postId -> {
Post post = new Post();
post.setId(postId);
post.setTitle(
String.format("Post nr. %d", postId)
);
post.setCreatedOn(
Timestamp.valueOf(
timestamp.plusMinutes(postId)
)
);
LongStream.range(1, commentsSize + 1).forEach(commentOffset -> {
long commentId = ((postId - 1) * commentsSize) + commentOffset;
PostComment comment = new PostComment();
comment.setId(commentId);
comment.setReview(
String.format("Comment nr. %d", comment.getId())
);
comment.setCreatedOn(
Timestamp.valueOf(
timestamp.plusMinutes(commentId)
)
);
post.addComment(comment);
});
entityManager.persist(post);
});
|
限制结果集大小
为了限制基础查询大小,JPA接口提供了setMaxResults方法。ResultSetQuery
因此,在执行以下 JPQL 查询时:
|
1
2
3
4
5
6
7
8
9
10
11
|
List<Post> posts = entityManager
.createQuery(
"select p " +
"from Post p " +
"order by p.createdOn ")
.setMaxResults(10)
.getResultList();
assertEquals(10, posts.size());
assertEquals("Post nr. 1", posts.get(0).getTitle());
assertEquals("Post nr. 10", posts.get(9).getTitle());
|
Hibernate在PostgreSQL上生成以下SQL语句:
|
1
2
3
4
5
6
|
SELECT p.id AS id1_0_,
p.created_on AS created_2_0_,
p.title AS title3_0_
FROM post p
ORDER BY p.created_on
LIMIT 10
|
在 SQL Server 2012(或更高版本)上,Hibernate 将执行以下 SQL 查询:
|
1
2
3
4
5
6
|
SELECT p.id AS id1_0_,
p.created_on AS created_2_0_,
p.title AS title3_0_
FROM post p
ORDER BY p.created_on
OFFSET 0 ROWS FETCH NEXT 10 ROWS ONLY
|
因此,SQL 分页查询适用于基础数据库引擎功能。
使用查询分页时,使用 of 是强制性的,因为 SQL 不保证任何特定的顺序,除非我们通过子句提供一个。
ORDER BYORDER BY
使用偏移来定位结果集
如果上一个查询是给定分页查询的第一页的典型查询,则导航下一页需要将结果集定位在最后一页结束的位置。为此,JPA接口提供了setFirstResult方法。Query
|
1
2
3
4
5
6
7
8
9
10
11
12
|
List<Post> posts = entityManager
.createQuery(
"select p " +
"from Post p " +
"order by p.createdOn ")
.setFirstResult(10)
.setMaxResults(10)
.getResultList();
assertEquals(10, posts.size());
assertEquals("Post nr. 11", posts.get(0).getTitle());
assertEquals("Post nr. 20", posts.get(9).getTitle());
|
在 PostgreSQL 上运行之前的 JPQL 查询时,Hibernate 执行以下 SQL SELECT 语句:
|
1
2
3
4
5
6
7
|
SELECT p.id AS id1_0_,
p.created_on AS created_2_0_,
p.title AS title3_0_
FROM post p
ORDER BY p.created_on
LIMIT 10
OFFSET 10
|
在 SQL Server 2012(或更高版本)上,Hibernate 将生成以下 SQL 查询:
|
1
2
3
4
5
6
|
SELECT p.id AS id1_0_,
p.created_on AS created_2_0_,
p.title AS title3_0_
FROM post p
ORDER BY p.created_on
OFFSET 10 ROWS FETCH NEXT 10 ROWS ONLY
|
DTO投影查询
JPA 查询分页不限于仅返回实体的实体查询。您也可以将其用于DTO投影。
假设我们有以下DTO:PostCommentSummary
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
public class PostCommentSummary {
private Number id;
private String title;
private String review;
public PostCommentSummary(
Number id,
String title,
String review) {
this.id = id;
this.title = title;
this.review = review;
}
public PostCommentSummary() {}
//Getters omitted for brevity
}
|
运行以下 DTO 投影查询时:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
List<PostCommentSummary> summaries = entityManager
.createQuery(
"select new " +
" com.vladmihalcea.book.hpjp.hibernate.fetching.PostCommentSummary( " +
" p.id, p.title, c.review " +
" ) " +
"from PostComment c " +
"join c.post p " +
"order by c.createdOn")
.setMaxResults(10)
.getResultList();
assertEquals(10, summaries.size());
assertEquals("Post nr. 1", summaries.get(0).getTitle());
assertEquals("Comment nr. 1", summaries.get(0).getReview());
assertEquals("Post nr. 2", summaries.get(9).getTitle());
assertEquals("Comment nr. 10", summaries.get(9).getReview());
|
Hibernate将分页子句附加到底层SQL查询:
|
1
2
3
4
5
6
7
|
SELECT p.id AS col_0_0_,
p.title AS col_1_0_,
c.review AS col_2_0_
FROM post_comment c
INNER JOIN post p ON c.post_id=p.id
ORDER BY c.created_on
LIMIT 10
|
有关使用 JPA 和 Hibernate 进行 DTO 投影的更多详细信息,请查看本文。
本机 SQL 查询
JPA 查询分页不限于实体查询,例如 JPQL 或条件 API。您也可以将其用于本机 SQL 查询。
|
1
2
3
4
5
6
7
8
9
10
11
12
|
List<Tuple> posts = entityManager
.createNativeQuery(
"select p.id as id, p.title as title " +
"from post p " +
"order by p.created_on", Tuple.class)
.setFirstResult(10)
.setMaxResults(10)
.getResultList();
assertEquals(10, posts.size());
assertEquals("Post nr. 11", posts.get(0).get("title"));
assertEquals("Post nr. 20", posts.get(9).get("title"));
|
运行上述 SQL 查询时,Hibernate 会附加特定于 DB 的分页子句:
|
1
2
3
4
5
6
|
SELECT p.id AS id,
p.title AS title
FROM post p
ORDER BY p.created_on
LIMIT 10
OFFSET 10
|
加入抓取和分页
但是,如果我们尝试在实体查询中使用子句,同时也使用 JPA 分页:JOIN FETCH
|
1
2
3
4
5
6
7
8
9
|
List<Post> posts = entityManager.createQuery(
"select p " +
"from Post p " +
"left join fetch p.comments " +
"order by p.createdOn", Post.class)
.setMaxResults(10)
.getResultList();
assertEquals(10, posts.size());
|
休眠将发出以下警告消息:
|
1
|
HHH000104: firstResult/maxResults specified with collection fetch; applying in memory!
|
并且执行的 SQL 查询将缺少分页子句:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
SELECT p.id AS id1_0_0_,
c.id AS id1_1_1_,
p.created_on AS created_2_0_0_,
p.title AS title3_0_0_,
c.created_on AS created_2_1_1_,
c.post_id AS post_id4_1_1_,
c.review AS review3_1_1_,
c.post_id AS post_id4_1_0__,
c.id AS id1_1_0__
FROM post p
LEFT OUTER JOIN post_comment c ON p.id=c.post_id
ORDER BY p.created_on
|
这是因为 Hibernate 希望完全获取实体及其集合,如子句所示,而 SQL 级分页可能会截断可能使父实体在集合中具有较少元素。JOIN FETCHResultSetPostcomments
警告的问题在于Hibernate将获取andentities的乘积,并且由于结果集的大小,查询响应时间将很长。HHH000104PostPostComment
为了解决此限制,您必须使用窗口函数查询:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
List<Post> posts = entityManager
.createNativeQuery(
"select * " +
"from ( " +
" select *, dense_rank() OVER (ORDER BY post_id) rank " +
" from ( " +
" select p.*, pc.* " +
" from post p " +
" left join post_comment pc on p.id = pc.post_id " +
" order by p.created_on " +
" ) p_pc " +
") p_pc_r " +
"where p_pc_r.rank <= :rank", Post.class)
.setParameter("rank", 10)
.unwrap(NativeQuery.class)
.addEntity("p", Post.class)
.addEntity("pc", PostComment.class)
.setResultTransformer(DistinctPostResultTransformer.INSTANCE)
.getResultList();
|
有关使用窗口函数修复问题及其代码的更多详细信息,请查看本文。
HHH000104DistinctPostResultTransformer
为什么不改用查询流式处理?
JPA 2.2 添加了该方法,您可能认为它是分页的有效替代方案。但是,流结果不会向查询计划程序提供结果集大小,因此可能会选择次优的执行计划。因此,在获取少量数据时,使用分页比流式传输更有效。getResultStreamQuery
有关为什么分页比流式传输更有效的更多详细信息,请查看本文。
键集分页
Markus Winand撰写了《SQL Performance Explained》一书,他提倡使用Keyset分页而不是Offset。尽管偏移分页是 SQL 标准功能,但有两个原因让您更喜欢密钥集分页:
- 性能(索引必须扫描到偏移量,而对于键集分页,我们可以直接转到按谓词和过滤条件匹配顺序的第一个索引条目)
- 正确性(如果在两者之间添加元素,偏移分页将无法提供一致的读取)
即使 Hibernate 不支持键集分页,您也可以使用本机 SQL 查询来实现此目的。
结论
获取所需数量的数据是数据访问性能方面最重要的技巧之一。提取数据时,分页允许您控制结果集大小,以便即使基础数据集随时间增长,性能也保持稳定。
虽然键集分页为大型结果集提供了更好的性能,但如果您可以使用正确的过滤谓词缩小扫描的数据集,则偏移分页的性能将相当好。为了获得一致的读取,您必须确保扫描的数据集始终以这样一种方式进行排序,即新条目附加到集的末尾,而不是混合在旧条目之间。



![[附源码]Python计算机毕业设计Django汽车租赁管理系统](https://img-blog.csdnimg.cn/0331c370a7234ab093e85295dae75ce2.png)