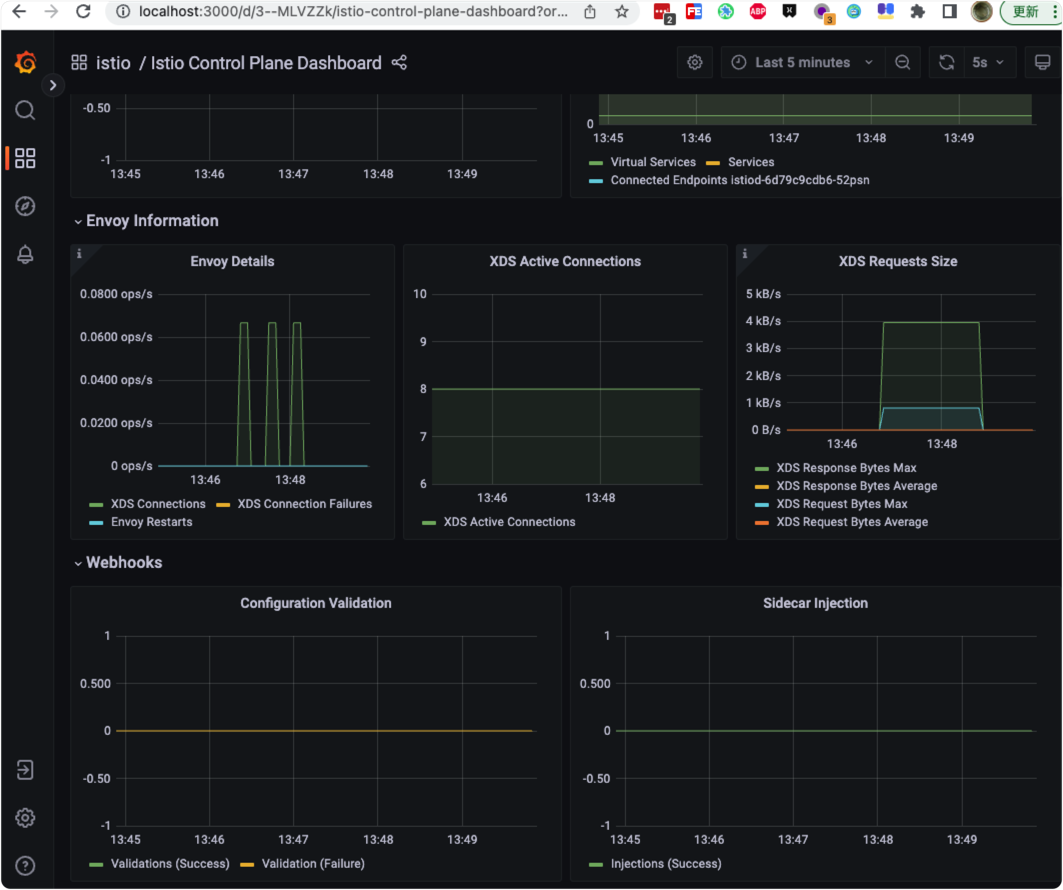
目录
一、Create
1.insert
2.更新
3.替换
二、Retrieve(查找)
1.select
2.where
3. 结果排序
4. 筛选分页结果
三、Update
四、Delete
1.删除数据
2.截断表
五、聚合函数
1.count:
2.avg
3.sum
4.max
5.min
六、Group by
一、Create
1.insert
INSERT [INTO] table_name [(column [, column] ...)] VALUES (value_list) [, (value_list)] ... value_list: value, [, value] ...
[ ]里的内容可以省略。
实例:
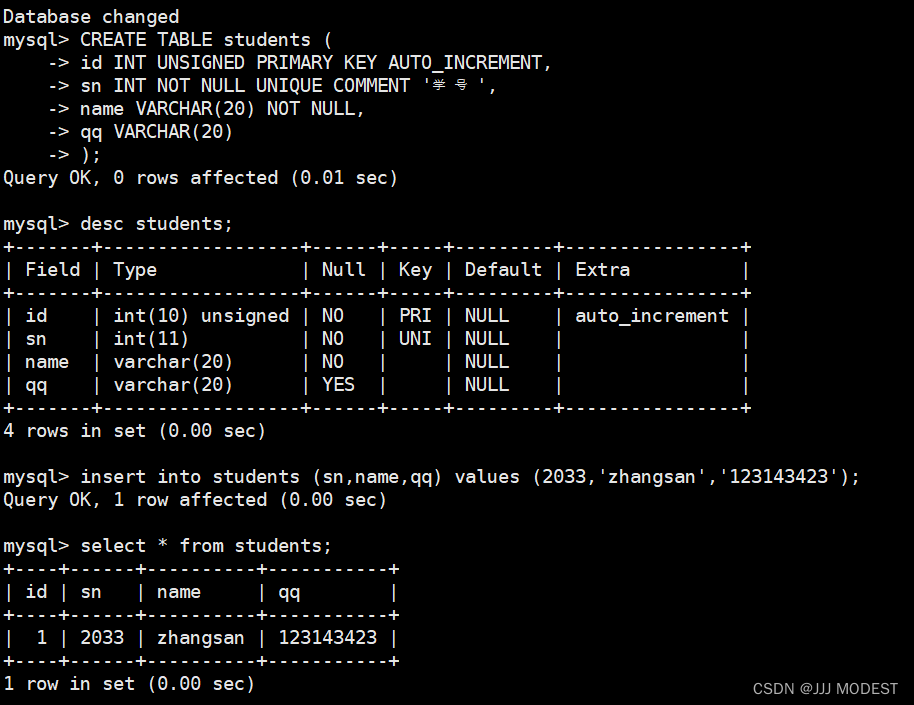
至于id为什么没有插入,因为在创建时该列设为自增长。

当不指明插入哪一列时,默认是全列插入,所以value必须一一对应,不能省略。
全列插入:

2.更新
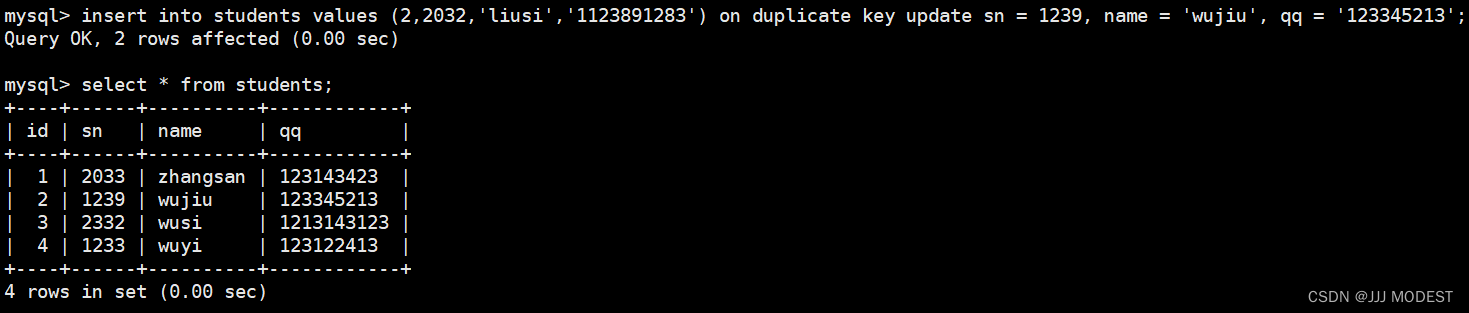
这由于主键或者唯一键对应的值已经存在而导致插入失败。![]()
此时我们可以选择性的进行同步更新操作。
INSERT ... ON DUPLICATE KEY UPDATE column = value [, column = value] ...
3.替换
主键 或者 唯一键 没有冲突,则直接插入;
主键 或者 唯一键 如果冲突,则删除后再插入
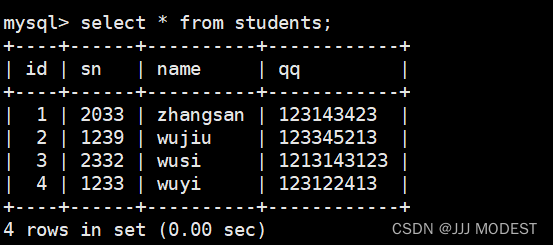
插入当前会冲突的数据。
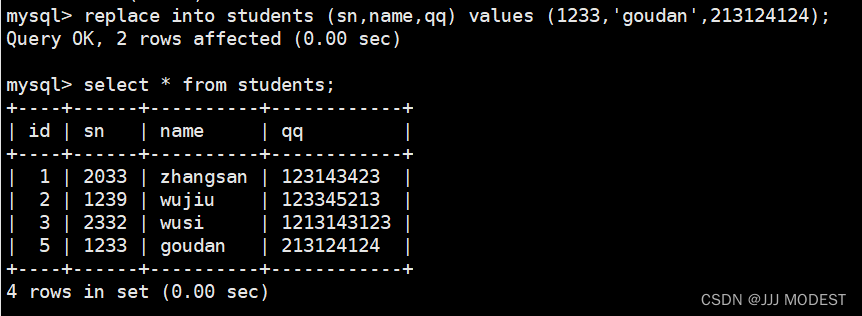
我们会发现当前冲突的数据已经被替换。
一般的场景中用到的最多的是insert与repalce。
二、Retrieve(查找)
1.select
在MySQL中查找语句使用的最多的就是select。
SELECT [DISTINCT] {* | {column [, column] ...}
[FROM table_name] [WHERE ...]
[ORDER BY column [ASC | DESC], ...]
LIMIT ...
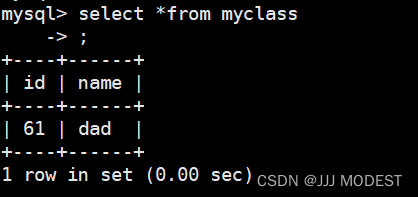

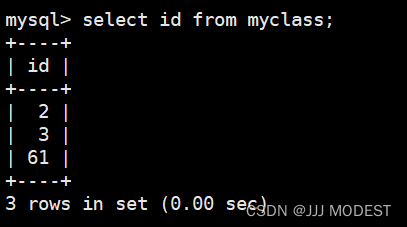
同样, select后面还可以跟表达式。
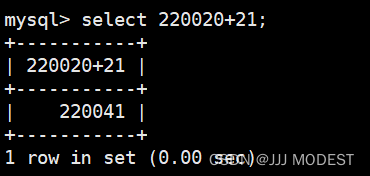
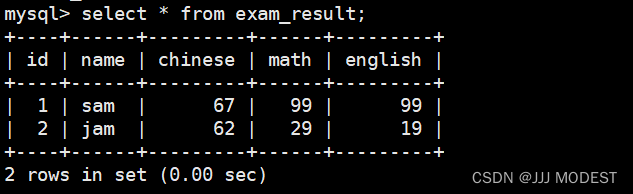

同样,select还支持去重查找。
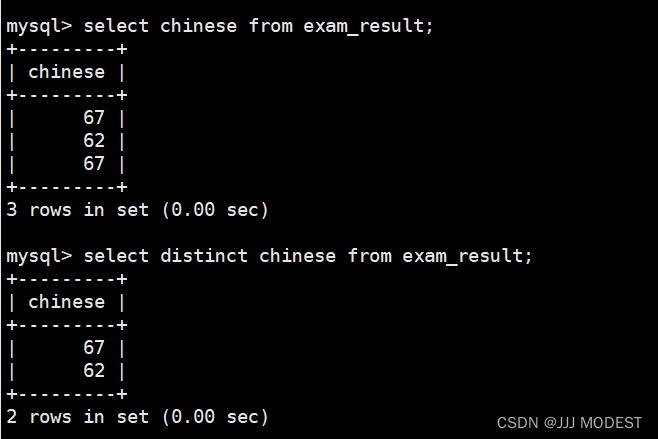
selcet : 支持全列查找或者列查找
支持表达式
支持对列重命名
支持去重
2.where

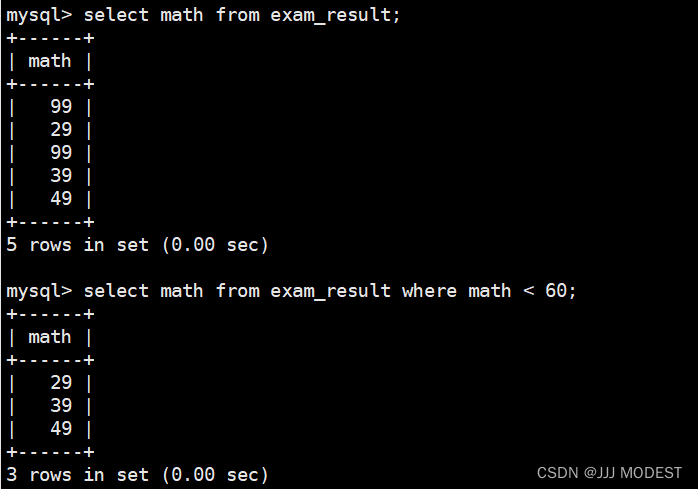
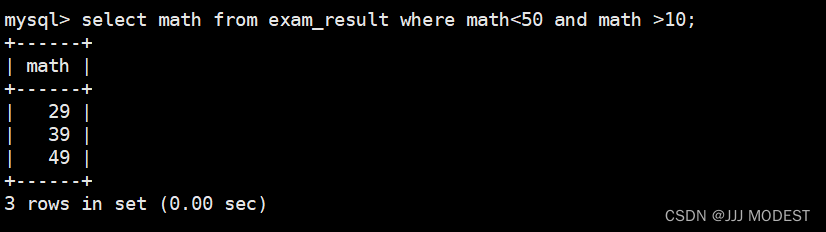
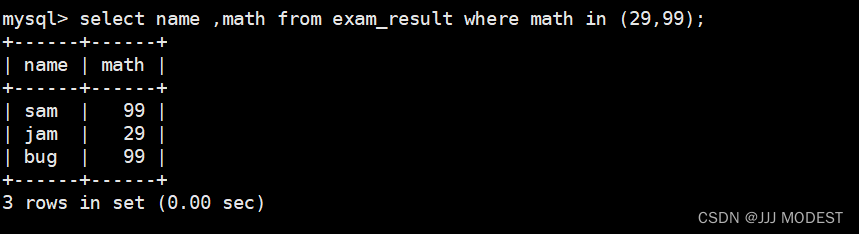
我们判断下这条语句的执行顺序。
![]()
首先肯定是从哪个表查询,所以是from...
其次是条件是什么,所以是where...
再然后是挑选展示那一列,所以是select...

3. 结果排序
-- ASC 为升序(从小到大) -- DESC 为降序(从大到小) -- 默认为 ASC
SELECT ... FROM table_name [WHERE ...] ORDER BY column [ASC|DESC], [...];
数学成绩按照升序排序:
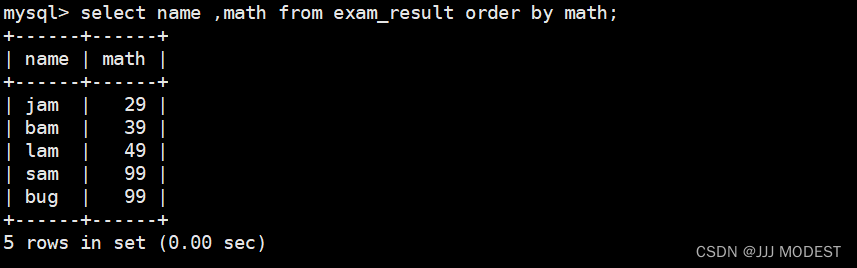
数学成绩按照降序排序:

数学降序,语文升序,英语降序:

排序,基本是在select的最后才做的,尽管他的sql语句写在比较靠后的位置。
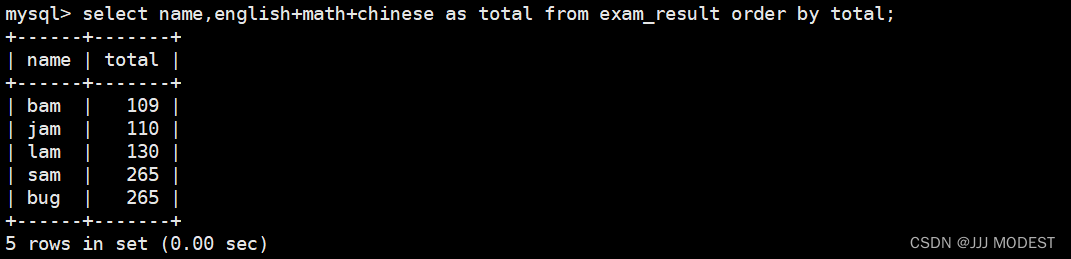
所以这样的语句可以执行,order by语句是最后执行的,前面的语句已经执行过english+math+chinese as total,所以这里的total就是english+math+chinese。
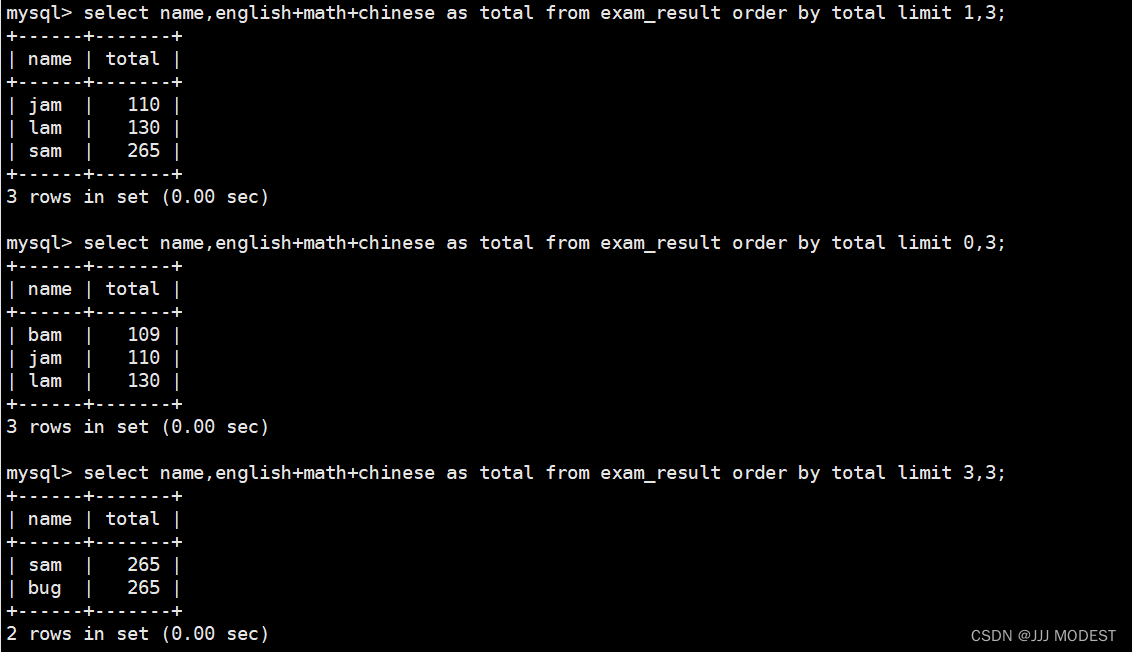
总分升序只显示前三行:
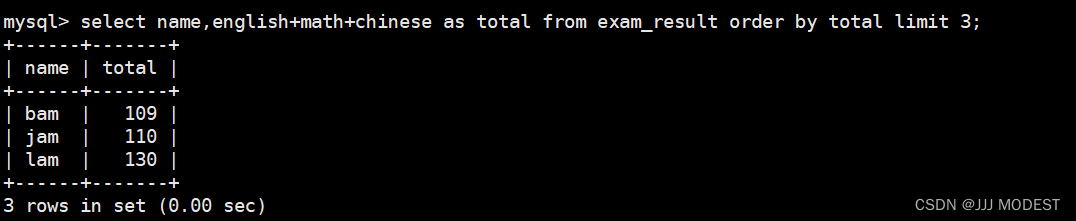
4. 筛选分页结果
-- 起始下标为 0
-- 从 0 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;
-- 从 s 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n;
-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;
三、Update
UPDATE table_name SET column = expr [, column = expr ...] [WHERE ...] [ORDER BY ...] [LIMIT ...]
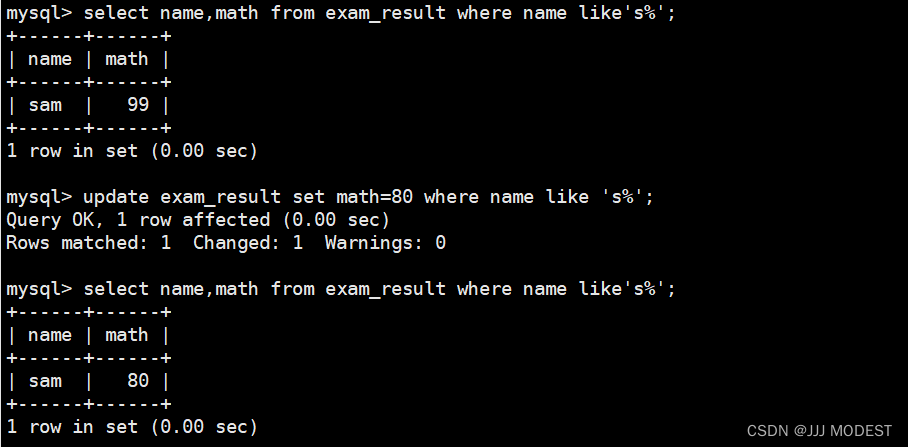
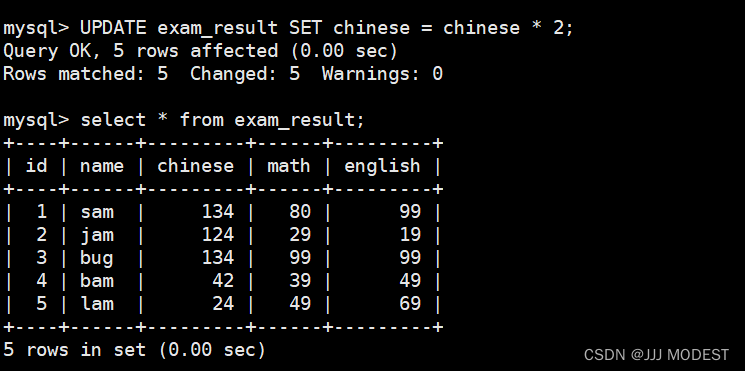
将语文成绩翻倍
四、Delete
1.删除数据
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]
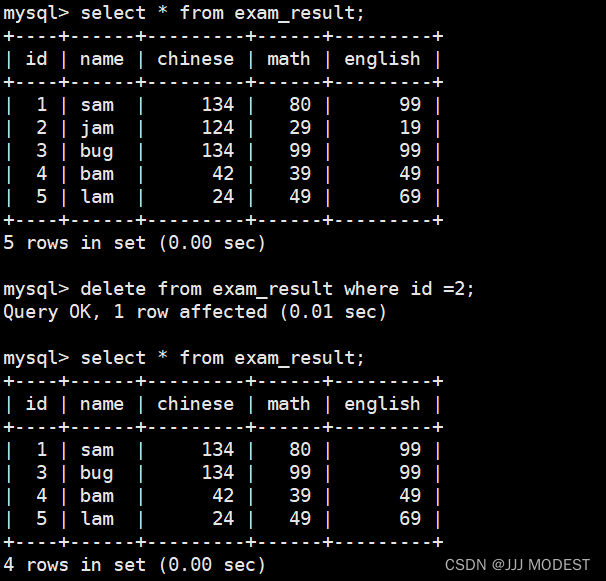
删除整张表:

2.截断表
TRUNCATE [TABLE] table_name
这个语句最重要的是会重置auto_increment项.

五、聚合函数
AVG()
SUM()
MAX()
MIN()
COUNT()
1.count:
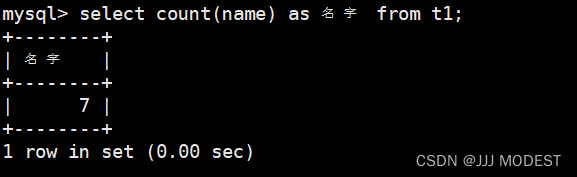
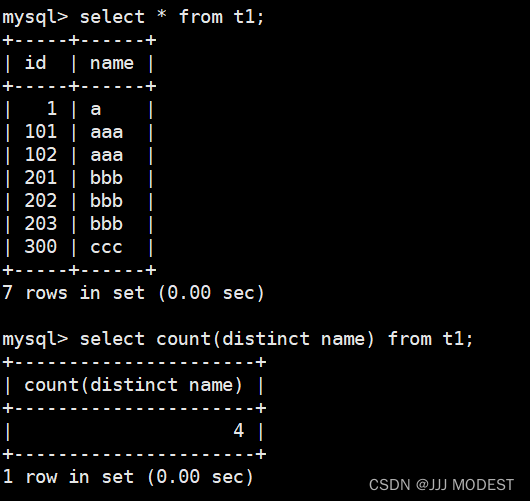
去重:
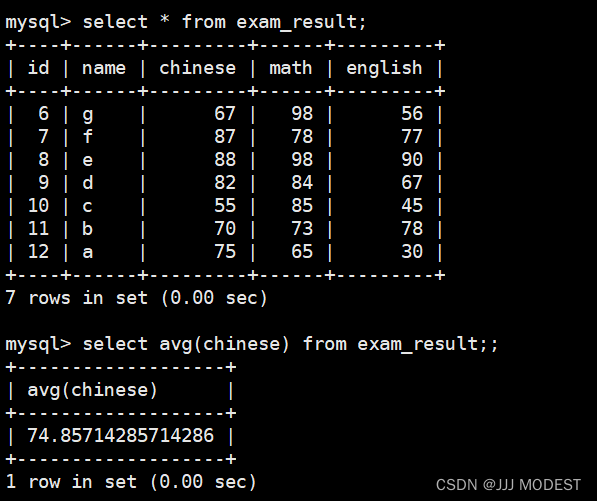
2.avg
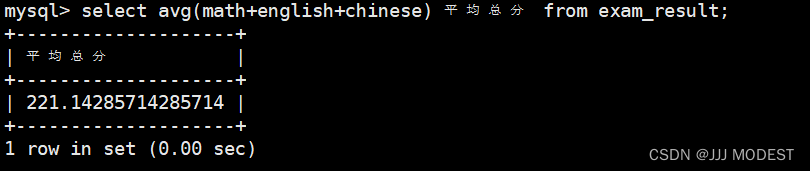
3.sum
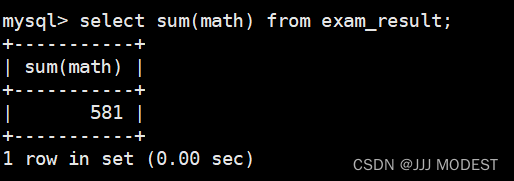
4.max
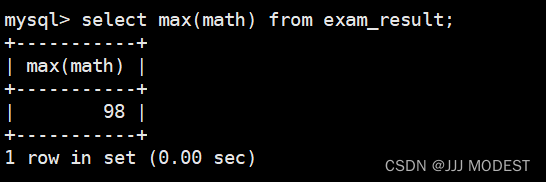
5.min
六、Group by
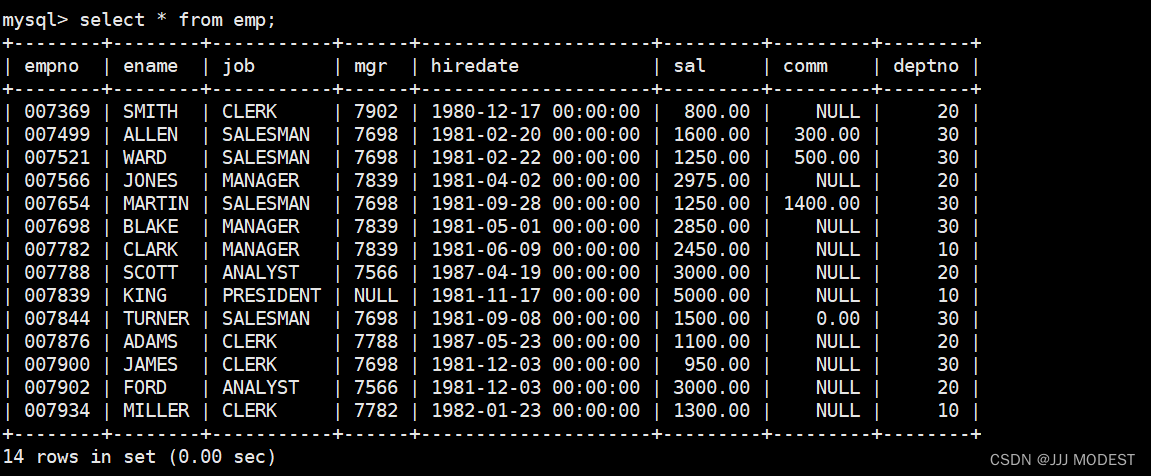
每个部门的平均薪资和最高工资:

每个部门的每种岗位的平均工资和最低工资: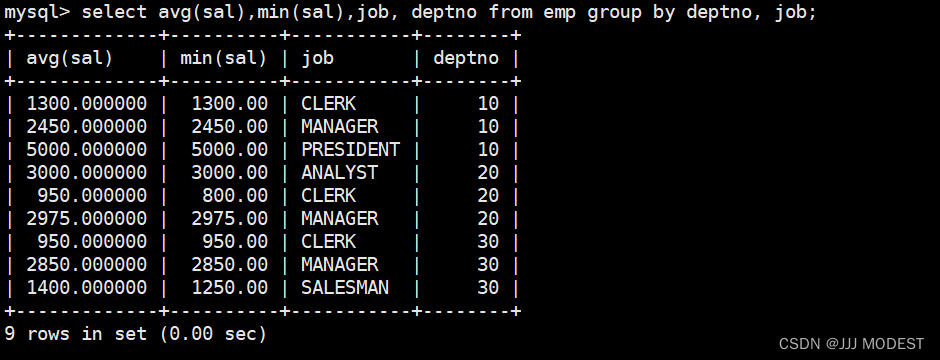
注意只有group by后面有的列才可以显示。
意思为:

我想显示ename但是我没有group by后跟ename,这样是错的。首先语法就错了,我要平均工资和最低工资显示员工名字显然不合理。
显示平均工资低于2000的部门和它的平均工资:
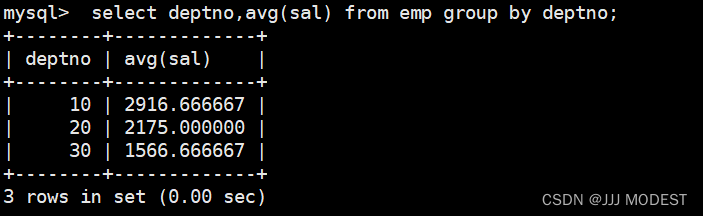
接下来:

这样不行,那这样呢?
![]()
还是不行,为什么呢?
首先where是筛选数据的,确定究竟操作的是哪些数据。
avg是聚合函数,根据数据来聚合。
他两个放一块就是where要确定数据但是avg要数据来聚合,他俩就会冲突。
要靠having的配合:
执行顺序为:
总结:
1.group by是通过分组的手段,为未来进行聚合统计时提供基本的功能支持。 group by一定是配合聚合统计使用的。
2.group by后面跟的都是分组的依据,只有在group by后出现的字段,未来在聚合统计时,才能在select后出现。
3.where和having时互补的,having通常是在整个分组聚合统计完,然后再进行筛选。而where是在表中初步筛选数据时起效果。