目录
- 1.什么是线程池?有什么优缺点?
- 2.创建线程池的方式有哪些?
- 2.1.通过 Executor 框架的工具类 Executors 来创建不同类型的线程池
- 2.2.使用 ThreadPoolExecutor 类自定义线程池
- 2.3.注意事项
- 3.自定义线程池时有哪些参数?它们各有说明含义?
- 3.1.构造函数
- 3.2.参数含义
- 3.3.使用示例
- 4.线程池的饱和策略有哪些?
- 5.线程池处理任务的流程是什么样的?
- 6.ThreadPoolExecutor 执行 execute() 方法的执行流程是什么样的?
- 7.如何给线程池命名?
- 7.1.使用 guava 的 ThreadFactoryBuilder
- 7.2.实现 ThreadFactor 接口
- 8.线程池的状态有哪些?
- 9.如何设置线程池的大小?
- 10.如何对线程池进行监控?
- 11.如何动态地修改线程池的参数?
参考文章:
《Java 并发编程的艺术》
1.什么是线程池?有什么优缺点?
(1)线程池 (ThreadPool) 是一种用于管理和复用线程的机制,它是在程序启动时就预先创建一定数量的线程,将这些线程放入一个池中,并对它们进行有效的管理和复用,从而在需要执行任务时,可以从线程池中获取一个可用线程来执行任务,任务执行完毕后线程不会被销毁而是返回线程池,以便下次使用。
(2)线程池的优点主要有以下几个方面:
- 降低资源消耗:线程的创建和销毁都需要一定的系统资源和时间,如果每个任务都单独创建一个线程,则会浪费大量的系统资源和时间。而使用线程池可以避免这种浪费,通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度:由于线程的创建和销毁需要一定的时间和系统资源,如果任务的数量很多,频繁地创建和销毁线程会造成系统的负载过重,导致性能下降。而线程池可以预先创建一定数量的线程,当任务到达时,任务可以不需要等到线程创建就能立即执行。
- 提高线程的可管理性:线程是稀缺资源,如果无限制地创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一分配、调优和监控。但是要做到合理利用线程池,必须对其实现原理了如指掌。
(3)线程池的缺点主要有以下几个方面:
- 内存泄漏:如果线程池中的线程没有正确地释放或回收,可能会导致内存泄漏问题。
- 阻塞问题:如果线程池中的线程都被占满,可能会导致任务被阻塞,从而降低应用程序的响应性。
- 线程安全问题:如果线程池中的线程共享数据,可能会导致线程安全问题,例如竞态条件和死锁。
- 性能问题:如果线程池的大小不合适或者线程的执行时间不均衡,可能会导致性能问题,例如响应延迟和系统负载过高。
2.创建线程池的方式有哪些?
2.1.通过 Executor 框架的工具类 Executors 来创建不同类型的线程池
(1)通过工具类 Executors,可以创建以下 3 种类型的 ThreadPoolExecutor:
- FixedThreadPool:FixedThreadPool 被称为可重用固定线程数的线程池。该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务。
//创建一个固定大小的线程池,大小为 3
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(3);
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
- SingleThreadExecutor: SingleThreadExecutor是使用单个 worker 线程的 Executor。若多余一个任务被提交到该线程池,任务会被保存在一个任务队列中,待线程空闲,按先入先出的顺序执行队列中的任务。
//创建一个单线程的线程池
ExecutorService singleThreadPool = Executors.newSingleThreadExecutor();
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
- CachedThreadPool:CachedThreadPool 是一个会根据需要创建新线程的线程池。线程池的线程数量不确定,但若有空闲线程可以复用,则会优先使用可复用的线程。若所有线程均在工作,又有新的任务提交,则会创建新的线程处理任务。所有线程在当前任务执行完毕后,将返回线程池进行复用。
//创建一个单线程的线程池
ExecutorService singleThreadPool = Executors.newSingleThreadExecutor();
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
(2)通过工具类 Executors,可以创建下面的 ScheduledThreadPoolExecutor(继承自 ThreadPoolExecutor):
- ScheduledThreadPool:该返回一个用来在给定的延迟后运行任务或者定期执行任务的线程池。
//创建一个定时执行的线程池
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(3);
2.2.使用 ThreadPoolExecutor 类自定义线程池
ThreadPoolExecutor 是 Executor 框架的一个具体实现,通过自定义 ThreadPoolExecutor 类可以创建更加灵活、符合需求的线程池。ThreadPoolExecutor 的 4 个构造函数如下所示,有关每个参数的具体含义可参考面试题 3。

2.3.注意事项
《阿里巴巴 Java 开发手册》中有如下规定:
(1)【强制】线程资源必须通过线程池提供,不允许在应用中自行显式创建线程。
说明:线程池的好处是减少在创建和销毁线程上所消耗的时间以及系统资源的开销,解决资源不足的问题。如果不使用线程池,有可能造成系统创建大量同类线程而导致消耗完内存或者“过度切换”的问题。
(2)【强制】线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
说明:Executors 返回的线程池对象的弊端如下:
1) FixedThreadPool 和 SingleThreadPool:允许的请求队列长度为 Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM。
2) CachedThreadPool:允许的创建线程数量为 Integer.MAX_VALUE,可能会创建大量的线程,从而导致 OOM。
3.自定义线程池时有哪些参数?它们各有说明含义?
3.1.构造函数
使用下面 ThreadPoolExecutor 类的构造函数可以自定义线程池,参数最全的构造函数如下:
public class ThreadPoolExecutor extends AbstractExecutorService {
//...
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
}
3.2.参数含义
其中的参数含义如下所示:
| 参数 | 含义 |
|---|---|
| corePoolSize | 线程池基本大小,当提交一个任务到线程池时,线程池会创建一个线程来执行任务,即使其他空闲的基本线程能够执行新任务也会创建线程,等到需要执行的任务数大于线程池基本大小时就不再创建 |
| maximumPoolSize | 线程池允许创建的最大线程数,如果队列满了,并且已创建的线程数小于最大线程数,则线程池会再创建新的线程执行任务,值得注意的是,如果使用了无界的任务队列,那么这个参数就没什么效果 |
| keepAliveTime | 线程活动保持时间,线程池中的线程数量大于 corePoolSize 时,如果这时没有新的任务提交,核心线程外的线程不会立即销毁,而是会等待,直到等待的时间超过了 keepAliveTime 才会被回收销毁 |
| unit | 线程活动保持时间的单位,即 keepAliveTime 的时间单位 |
| workQueue | 用于保存等待执行的任务的阻塞队列,新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被存放在任务队列中。值得注意的是,如果使用了无界的工作队列 SynchronousQueue,那么当任务数超过线程池的核心线程数时,该任务不会进入队列 |
| threadFactory | 用于设置创建线程的工厂,可以通过线程工厂给每个创建出来的线程设置更有意义的名字。使用开源框架 guava 提供的 ThreadFactoryBuilder 可以快速给线程池里的线程设置有意义的名字 |
| handler | 当队列和线程池都满了,说明线程池处于饱和状态,那么必须采取一种策略处理提交的新任务。这个策略默认情况下是 AbortPolicy,表示无法处理新任务时抛出异常 |
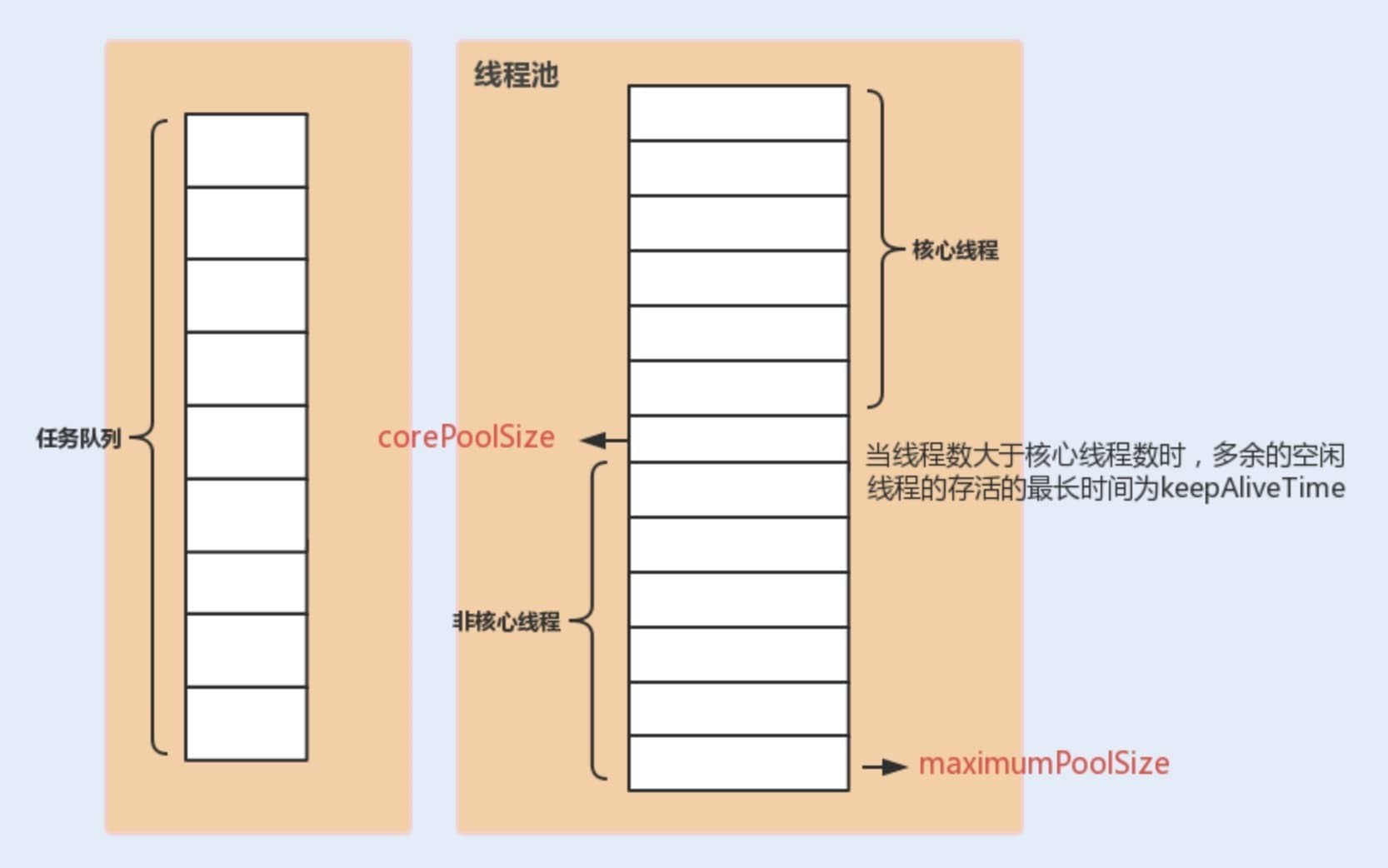
① 上图来源:《Java 性能调优实战》
② 上述提到的 7 个参数中,corePoolSize、maximumPoolSize、workQueue这 3 个参数是核心参数。
③ 上述 workQueue 就是 BlockingQueue,有关 BlockingQueue 的相关知识可以参考Java 并发编程面试题——BlockingQueue这篇文章。
3.3.使用示例
import com.google.common.util.concurrent.ThreadFactoryBuilder;
import java.util.concurrent.*;
class Solution {
public static void main(String[] args) throws ExecutionException, InterruptedException {
//自定义线程池
int corePoolSize = 2;
int maximumPoolSize = 5;
long keepAliveTime = 50;
// keepAliveTime 的单位
TimeUnit unit = TimeUnit.MICROSECONDS;
//工作队列 workQueue
BlockingQueue<Runnable> blockingQueue = new ArrayBlockingQueue<>(3);
//使用开源框架 guava 提供的 ThreadFactoryBuilder 可以给线程池里的线程自定义名字
ThreadFactory threadFactory = new ThreadFactoryBuilder().setNameFormat("demo-task-%d").build();
//饱和策略
RejectedExecutionHandler handler = new ThreadPoolExecutor.AbortPolicy();
ThreadPoolExecutor threadsPool = new ThreadPoolExecutor(
corePoolSize, maximumPoolSize,
keepAliveTime, unit,
blockingQueue, threadFactory,
handler);
//执行无返回值的任务
Runnable taskWithoutRet = new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " is running");
}
};
threadsPool.execute(taskWithoutRet);
//执行有返回值的任务
FutureTask<Integer> taskWithRet = new FutureTask<>(new Callable<Integer>() {
@Override
public Integer call() throws Exception {
System.out.println(Thread.currentThread().getName() + " is running");
//线程睡眠 1000 ms
Thread.sleep(1000);
return 100;
}
});
threadsPool.submit(taskWithRet);
System.out.println("有返回值的任务的结果为: " + taskWithRet.get());
//关闭线程池
threadsPool.shutdown();
}
}
输出结果如下:
demo-task-0 is running
demo-task-1 is running
有返回值的任务的结果为: 100
在 Java 8 中可以使用 lambda 表达式来对创建任务的代码进行简化:
Runnable taskWithoutRet = () -> System.out.println(Thread.currentThread().getName() + " is running");
FutureTask<Integer> taskWithRet = new FutureTask<>(() -> {
System.out.println(Thread.currentThread().getName() + " is running");
//线程睡眠 1000 ms
Thread.sleep(1000);
return 100;
});
与 FutureTask 有关的知识可以参考Java 并发编程面试题——Future这篇文章。
4.线程池的饱和策略有哪些?
如果线程到达 maximumPoolSize 仍然有新任务,这时线程池会执行饱和策略。ThreadPoolExecutor 为接口 RejectedExecutionHandler 提供了以下 4 种实现,它们都是 ThreadPoolExecutor 中的静态内部类:
- AbortPolicy:抛出
RejectedExecutionException异常来拒绝新任务的处理,这也是默认的策略; - CallerRunsPolicy:只用调用者所在线程来运行任务,也就是直接在调用 execute 方法的线程中运行 (run) 被拒绝的任务,如果执行程序已关闭,则会丢弃该任务。因此这种策略会降低对于新任务提交速度,影响程序的整体性能。如果应用程序可以承受此延迟并且你要求任何一个任务请求都要被执行的话,那么可以选择这个策略;
- DiscardPolicy:不处理本次任务,选择直接放弃;
- DiscardOldestPolicy:放弃队列中最早的任务,本任务取而代之;

5.线程池处理任务的流程是什么样的?
(1)线程池的主要处理流程如下图所示:
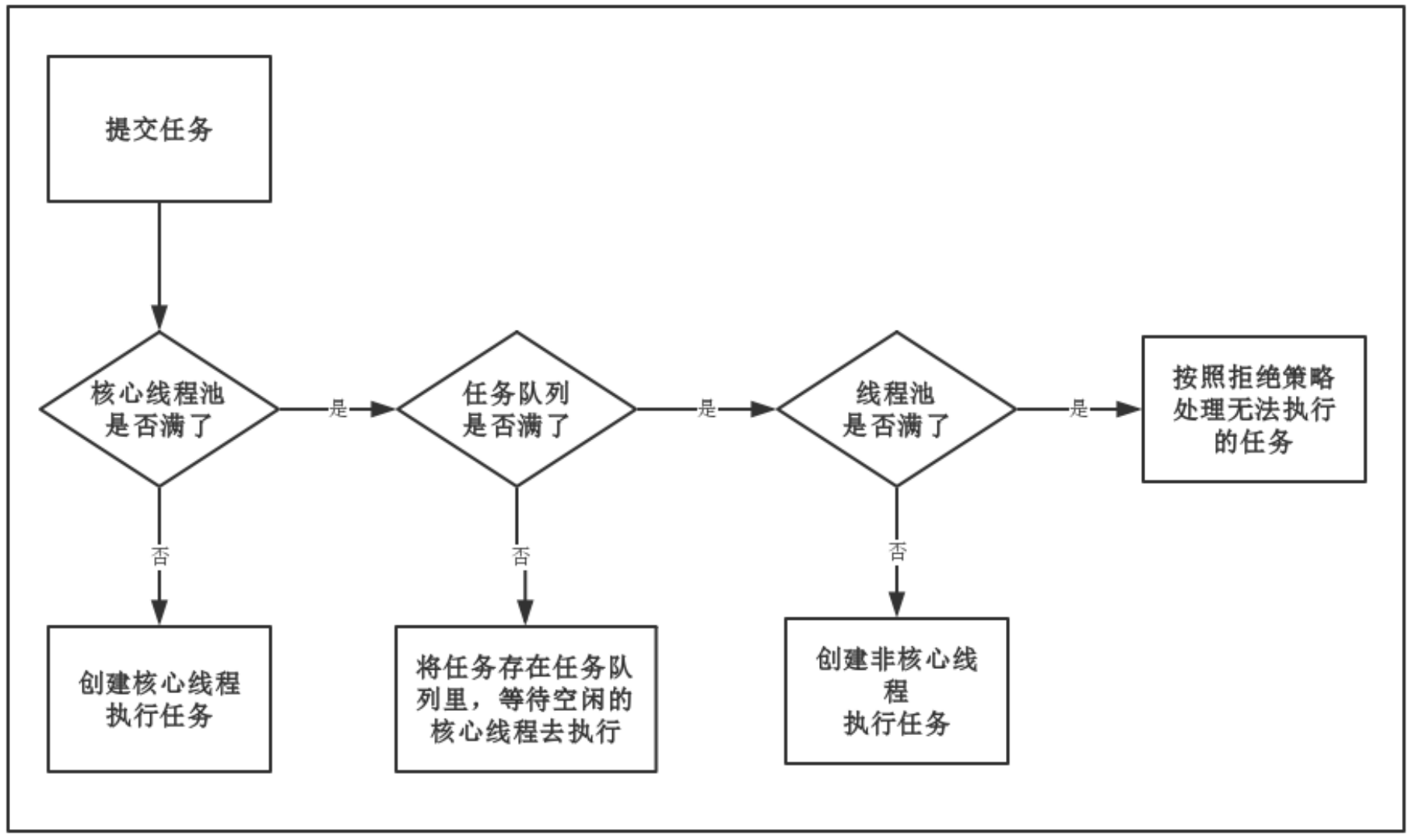
(2)从图中可以看出,当提交一个新任务到线程池时,线程池的处理流程如下:
- 线程池判断
核心线程池 (其大小为 corePoolSize)里的线程是否都在执行任务。如果不是,则创建一个新的工作线程来执行任务。如果核心线程池里的线程都在执行任务,则进入下个流程; - 线程池判断
工作队列 (workQueue)是否已经满。如果工作队列没有满,则将新提交的任务存储在这个工作队列里。如果工作队列满了,则进入下个流程; - 线程池判断
线程池的线程 (大小为 maximumPoolSize)是否都处于工作状态。如果没有,则创建一个新的工作线程来执行任务。如果已经满了,则交给饱和策略 (RejectedExecutionHandler)来处理这个任务;
6.ThreadPoolExecutor 执行 execute() 方法的执行流程是什么样的?
(1)ThreadPoolExecutor 执行 execute() 方法的执行流程如下如所示,我们可以将其看作线程池执行流程在代码中的具体表现。
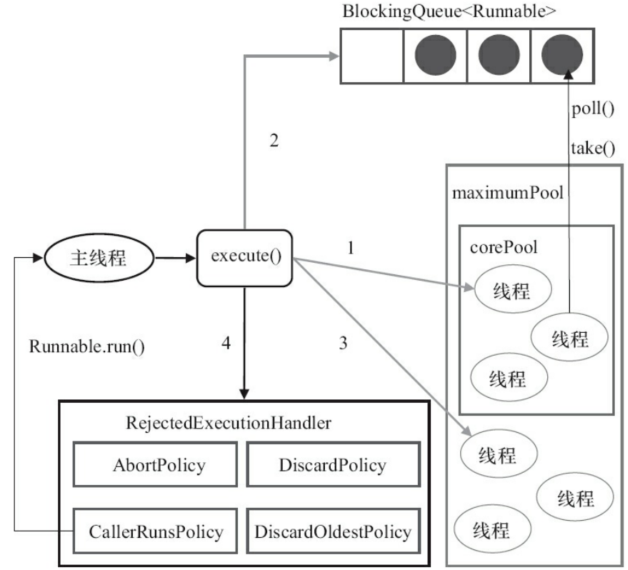
(2)ThreadPoolExecutor 执行 execute 方法分下面 4 种情况:
① 如果当前运行的线程少于 corePoolSize,则创建新线程来执行任务(注意,执行这一步骤需要获取全局锁)。
② 如果运行的线程等于或多于 corePoolSize,则将任务加入 BlockingQueue。
③ 如果无法将任务加入 BlockingQueue(队列已满),则创建新的线程来处理任务(注意,执行这一步骤需要获取全局锁)。
④ 如果创建新线程将使当前运行的线程超出 maximumPoolSize,任务将被拒绝,并调用 RejectedExecutionHandler.rejectedExecution() 方法。
ThreadPoolExecutor 采取上述步骤的总体设计思路,是为了在执行 execute() 方法时,尽可能地避免获取全局锁(那将会是一个严重的可伸缩瓶颈)。在 ThreadPoolExecutor 完成预热之后(当前运行的线程数大于等于 corePoolSize),几乎所有的 execute() 方法调用都是执行步骤 ②,而步骤 ② 不需要获取全局锁。
7.如何给线程池命名?
初始化线程池的时候需要显示命名(设置线程池名称前缀),有利于定位问题。默认情况下创建的线程名字类似 pool-1-thread-n 这样的,没有业务含义,不利于定位问题。给线程池里的线程命名通常有下面两种方式:
7.1.使用 guava 的 ThreadFactoryBuilder
ThreadPoolExecutor 的构造函数中的参数 ThreadFactory 是用于设置创建线程的工厂,可以通过线程工厂给每个创建出来的线程设置更有意义的名字。使用开源框架 guava 提供的 ThreadFactoryBuilder 可以快速给线程池里的线程设置有意义的名字,代码如下:
ThreadFactory threadFactory = new ThreadFactoryBuilder().setNameFormat("XX-task-%d").build();
7.2.实现 ThreadFactor 接口
//带有前缀名称的线程工厂
public static class NamedThreadFactory implements ThreadFactory {
//线程名前缀
private final String prefix;
//线程编号
private final AtomicInteger threadNumber = new AtomicInteger(1);
public NamedThreadFactory(String prefix) {
this.prefix = prefix;
}
//重写 newThread 方法
@Override
public Thread newThread(Runnable r) {
return new Thread(null, r, prefix + threadNumber.getAndIncrement());
}
}
8.线程池的状态有哪些?
ThreadPoolExecutor 使用 int 的高 3 位来表示线程池状态,低 29 位表示线程数量。
| 状态名 | 高 3 位 | 接收新任务 | 处理阻塞队列任务 | 说明 |
|---|---|---|---|---|
| RUNNING | 111 | Y | Y | |
| SHUTDOWN | 000 | N | Y | 不会接收新任务,但会处理阻塞队列剩余任务 |
| STOP | 001 | N | N | 会中断正在执行的任务,并抛弃阻塞队列任务 |
| TIDYING | 010 | - | - | 任务全执行完毕,活动线程为 0 即将进入终结 |
| TERMINATED | 011 | - | - | 终结状态 |
从数字上比较,TERMINATED > TIDYING > STOP > SHUTDOWN > RUNNING。这些信息存储在一个原子变量 ctl 中,目的是将线程池状态与线程个数合二为一,这样就可以用一次 CAS 原子操作进行赋值。
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
// c 为旧值, ctlOf 返回结果为新值
ctl.compareAndSet(c, ctlOf(targetState, workerCountOf(c))));
// rs 为高 3 位代表线程池状态, wc 为低 29 位代表线程个数,ctl 是合并它们
private static int ctlOf(int rs, int wc) {
return rs | wc;
}
9.如何设置线程池的大小?
(1)首先,需要明确的是线程池大小不能设置地过大或者过小:
- 如果线程池设置地太大,那么大量的线程可能会同时在竞争 CPU 资源,这样会导致大量的上下文切换,从而增加线程的执行时间,影响了整体执行效率。
- 如果线程池设置地太小,那么当同一时间有大量任务需要处理时,可能会导致它们在任务队列中排队等待执行,甚至会出现任务队列满了之后任务无法处理的情况,或者大量任务堆积在任务队列导致 OOM。这样一来,CPU 没有得到充分的利用。
(2)要想合理地配置线程池,可以从任务特性入手来进行分析:
- 任务的性质,性质不同的任务可以用不同规模的线程池分开处理:
- CPU 密集型任务:应配置尽可能小的线程,如配置 N c p u N_{cpu} Ncpu + 1个线程的线程池;
- I/O 密集型任务:由于 I/O 密集型任务线程并不是一直在执行任务,则应配置尽可能多的线程,如 2 ∗ N c p u 2 * N_{cpu} 2∗Ncpu
- 混合型任务:如果可以拆分,将其拆分成一个 CPU 密集型任务和一个 I/O 密集型任务,只要这两个任务执行的时间相差不是太大,那么分解后执行的吞吐量将高于串行执行的吞吐量。如果这两个任务执行时间相差太大,则没必要进行分解。
- 任务的优先级:高、中和低。优先级不同的任务可以使用优先级队列
PriorityBlockingQueue来处理。它可以让优先级高的任务先执行。不过需要注意的是,如果一直有优先级高的任务提交到队列里,那么优先级低的任务可能永远不能执行。 - 任务的执行时间:长、中和短。执行时间不同的任务可以交给不同规模的线程池来处理,或者可以使用优先级队列,让执行时间短的任务先执行。
- 任务的依赖性:是否依赖其他系统资源,如数据库连接。依赖数据库连接池的任务,因为线程提交SQL后需要等待数据库返回结果,等待的时间越长,则 CPU 空闲时间就越长,那么线程数应该设置得越大,这样才能更好地利用 CPU。
① 如何判断是 CPU 密集任务还是 I/O 密集任务?
答:简单来说,CPU 密集型任务指需要利用 CPU 计算能力的任务,例如对大量数据进行运算。而 I/O 密集型指涉及到网络读取、文件读取等的任务,其特点在于 I/O 操作完成的时间远大于 CPU 计算耗费的时间,即大部分时间都花在了等待 I/O 操作完成上。
② Java 中如何获取当前 CPU 的核心数?
答:使用int cores = Runtime.getRuntime().availableProcessors();这行代码即可获取当前 CPU 的核心数。
10.如何对线程池进行监控?
(1)如果在系统中大量使用线程池,则有必要对线程池进行监控,方便在出现问题时,可以根据线程池的使用状况快速定位问题。可以通过线程池提供的参数进行监控,在监控线程池的时候可以使用以下属性:
- taskCount:线程池需要执行的任务数量。
- completedTaskCount:线程池在运行过程中已完成的任务数量,小于或等于taskCount。
- largestPoolSize:线程池里曾经创建过的最大线程数量。通过这个数据可以知道线程池是否曾经满过。如该数值等于线程池的最大大小,则表示线程池曾经满过。
- getPoolSize:线程池的线程数量。如果线程池不销毁的话,线程池里的线程不会自动销毁,所以这个大小只增不减。
- getActiveCount:获取活动的线程数。
(2)此外,我们还可以通过扩展线程池进行监控。可以通过继承线程池来自定义线程池,重写线程池的 beforeExecute、afterExecute 和 terminated 方法,也可以在任务执行前、执行后和线程池关闭前执行一些代码来进行监控。例如,监控任务的平均执行时间、最大执行时间和最小执行时间等,这几个方法在线程池里是空方法。
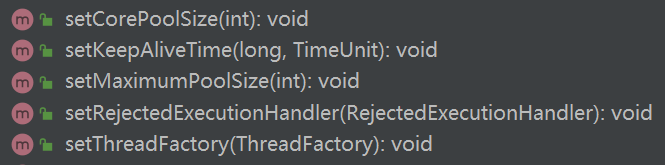
11.如何动态地修改线程池的参数?
ThreadPoolExecutor 类中提供了以下这些方法来动态修改参数: