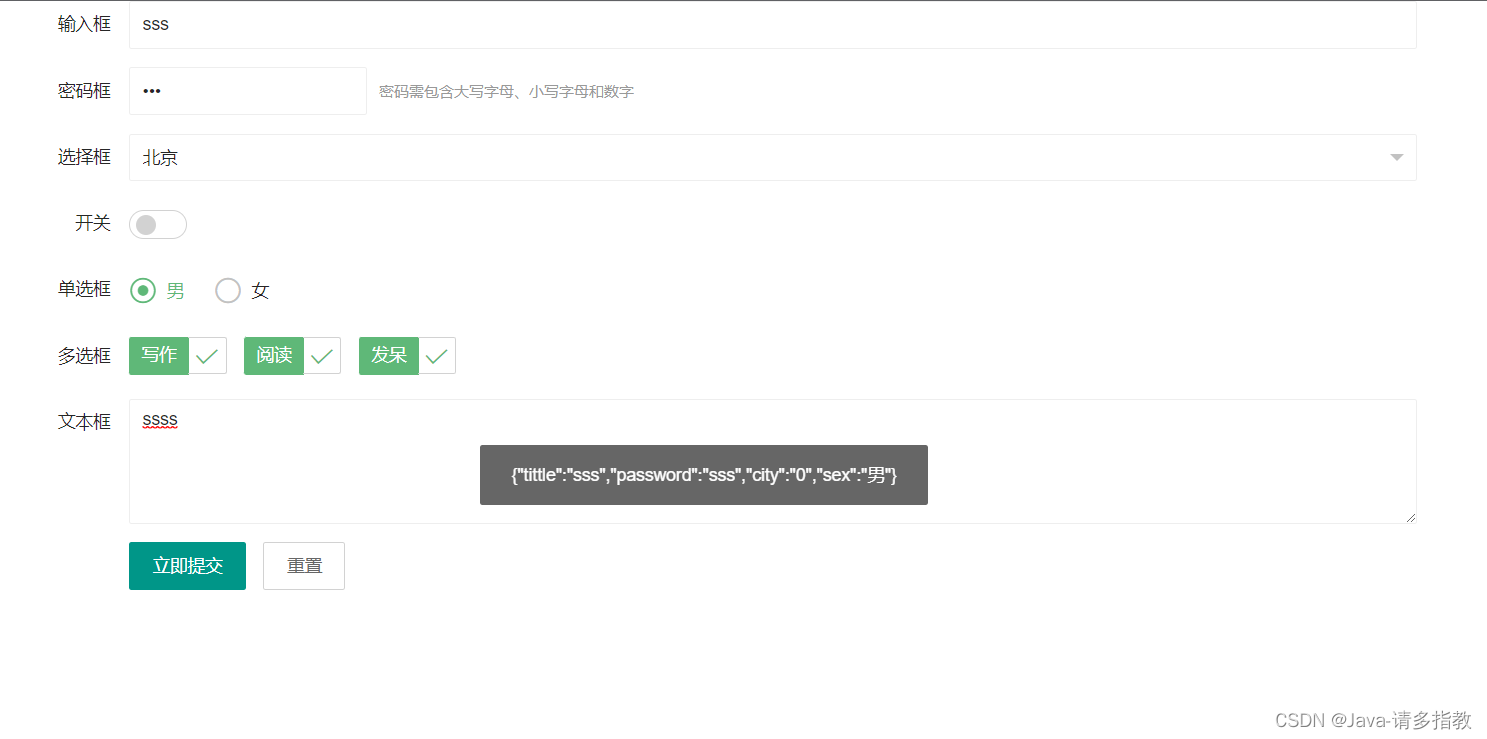
DCN
- 动机
- 简介
- 方法
- 动态连接评分器
- 候选生成
- 拼音增强候选生成器
- 训练
- 损失函数
- 预训练
- 预测
- 实验
- 数据集
- 方法比较
- 消融

Paper:https://aclanthology.org/2021.findings-acl.216.pdf
Code:https://github.com/destwang/DCN [Pytorch]
哈工大+讯飞
动机
大多数关于 CSC 的方法都是基于 BERT 的非自回归语言与模型,这些模型依赖于输出独立性假设。而不适当的独立性假设阻止了这些模型学习目标字符之间的依赖关系,从而导致输出的字符不连贯的问题。
例如下图,”户秃“ 可以被更正为 ”糊涂“ 或者 ”尴尬“,由于每个字符的独立性,非自回归模型可能会将其纠正为 ”尴涂“。

简介
为了解决以上问题,本文提出了动态连接网络(Dynamic Connected Networks - DCN),包括拼音增强候选生成器(Pinyin Enhanced Candidate Generator)和动态连接评分器(Dynamic Connected Scorer - DCScorer)。此网络可以学习到输出汉字之间的依赖关系,缓解不连贯问题。
首先,本文使用 RoBERTa 和拼音增强候选生成器结合拼音信息,并在每个位置生成 k 个候选字符。
然后,对于每两个相邻的字符,使用 DCScorer 学习一个不同的连接分数,来确定它们之间的依赖关系的强度。DCScorer 通过将当前和下一个位置的上下文表示和候选字符嵌入同时输入到注意力层来计算连接分数。
最终,模型生成
k
n
k^n
kn 个候选路径,利用维特比算法快速找到得分最高的路径作为最终的校正结果。
方法

动态连接评分器

动态连接评分器需要同时考虑上下文信息、当前和下一个位置的候选字符。因此,本文使用注意力机制去学习当前候选字符的上下文表示 p p p 和下一个候选字符的上下文表示 q q q。两个相邻候选字符之间的依赖关系强度通常与当前位置和下一位置的 RoBERTa 的隐藏表示更相关,因此注意力机制中的 Key 和 Value 仅包含这两个隐藏表示。更详细的,DCScore 的定义如下:

其中
i
i
i 表示字符的位置,
m
m
m 和
n
n
n 分别表示当前位置和下一位置的候选字符的索引。
然后把候选字符嵌入加入到候选上下文表示中,把输出输入到归一化层中得到两个输出表示
p
i
,
m
′
p_{i, m}'
pi,m′ 和
q
i
,
n
′
q_{i, n}'
qi,n′ :

然后把这个两个向量拼接起来输入到 FFN 层中,使用一个线性层计算两个候选字符的连接分数

其中
v
v
v 是训练权重,
g
(
y
i
,
m
,
y
i
+
1
,
n
)
g(y_{i, m}, y_{i+1, n})
g(yi,m,yi+1,n) 是第
i
i
i 个字符的第
m
m
m 个候选字符和第
i
+
1
i+1
i+1 个字符的第
n
n
n 个候选字符的连接分数。
由于将
k
2
k^2
k2 对候选组合输入到 DCScorer 中,将在每个位置生成
k
2
k^2
k2 个分数。最终,模型将生成
k
n
k^n
kn 个候选路径,每条路径的分数使用以下公式计算:

其中
y
y
y 是候选字符,
f
(
y
i
,
m
)
f(y_{i,m})
f(yi,m) 是拼音增强候选生成器在第
i
i
i 个字符位置的第
m
m
m 个候选字符的预测分数。
候选生成
拼音增强候选生成器
根据统计数据,超过 80% 的拼写错误与发音相似度有关。由于语音错误占汉字错误的很大一部分,因此引入语音信息的方法在生成候选词和纠正拼写错误方面右很大帮助。从单个汉语拼音到汉字的转换有很大的歧义,很难正确转换,因为一个拼音通常对应许多汉字。然后,当有多个连续的拼音时,就会有很大的置信度将拼音转换为正确的汉字。而本文提出的拼音增强候选生成器可以有效的减少歧义,生成更好的字符。

使用卷积层对连续的拼音进行编码,并将卷积层的输出、RoBERTa 的隐藏表示金额字符嵌入相加。然后输入到归一化层并通过线性层得到预测分数
f
(
y
i
,
m
)
f(y_{i, m})
f(yi,m) :

其中
p
′
′
p''
p′′ 时拼音嵌入,
ω
i
\omega_i
ωi 是中文字符嵌入,
h
i
h_i
hi 是 RoBERTa 的最后隐藏层,
v
′
v'
v′ 是第
m
m
m 个候选字符训练权重向量。
训练
损失函数
序列
Y
Y
Y 的概率可以表示为:

其中
Y
′
Y'
Y′ 是候选字符生成的路径。
损失函数是概率分布的最大似然:

损失函数类似于 LSTM-CRF 使用的损失函数。它只学习采样的负候选字符及其之间的依赖关系,这将过度降低潜在候选者的排名。这可能使更相似的候选者排名较低。为了避免上述问题,当黄金分数高于或等于所有候选路径的最大分数时,我们通过将损失函数设置为 0 来对损失函数进行限制。
预训练
通过大规模训练语料库可以更充分地学习汉字之间的依赖关系。在本文中,使用下表所示的中文维基百科数据预训练本文提出的模型。本文随机替换 15% 的字符,包括混淆集中的 70% MASK、15% 的字符和 15% 的随机字符。利用 SIGHAN 2013 发布的混淆集,其中包含发音相似性和形状相似性字符。基于 RoBERTa 模型,本文冻结了主要参数,只微调拼音增强候选生成器和动态连接评分器。
预测
在预测阶段,词汇表中的前 k k k 个候选字符由拼音增强候选生成器生成。最终,有 k n k^n kn 条路径。为了快速选择得分最高的路径,本文使用基于动态规划的维特比算法来解码输出序列。
实验
数据集
预训练数据:中文维基百科
微调数据:生成数据、SIGHAN 2013、SIGHAN 2014、SIGHAN 2015
测试数据:SIGHAN 2013、SIGHAN 2014、SIGHAN 2015
方法比较

消融
候选字符生成方法的消融研究

模型各模块的消融研究

候选字符数量的消融研究

一个解码的例子