预测人体关键点有什么作用?
- 还原人体姿态,输出脸部、手部的关键点坐标
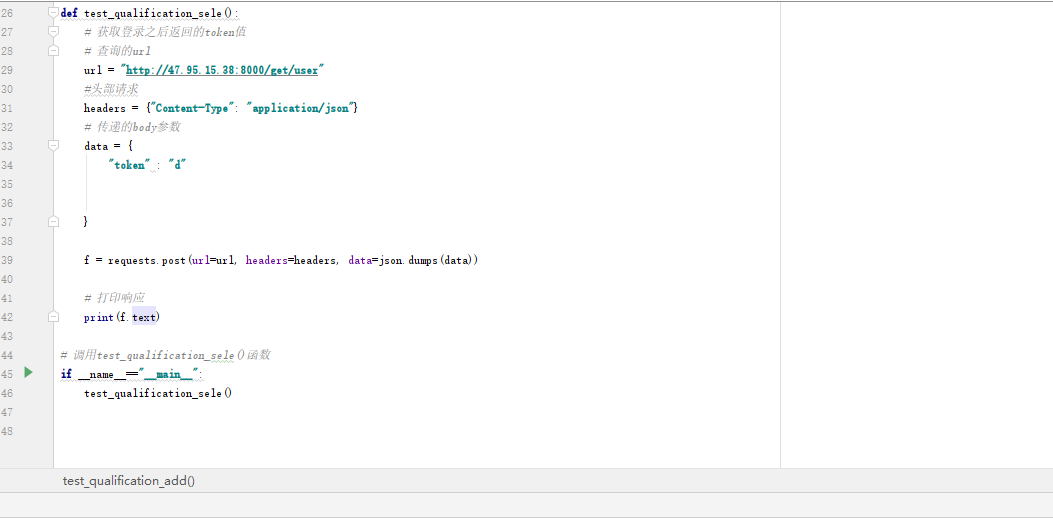
- 3D空间内,关键点变为3维坐标,可以在三维空间中还原人体姿态,可以实现一键换装
- 恢复3D的人体模型
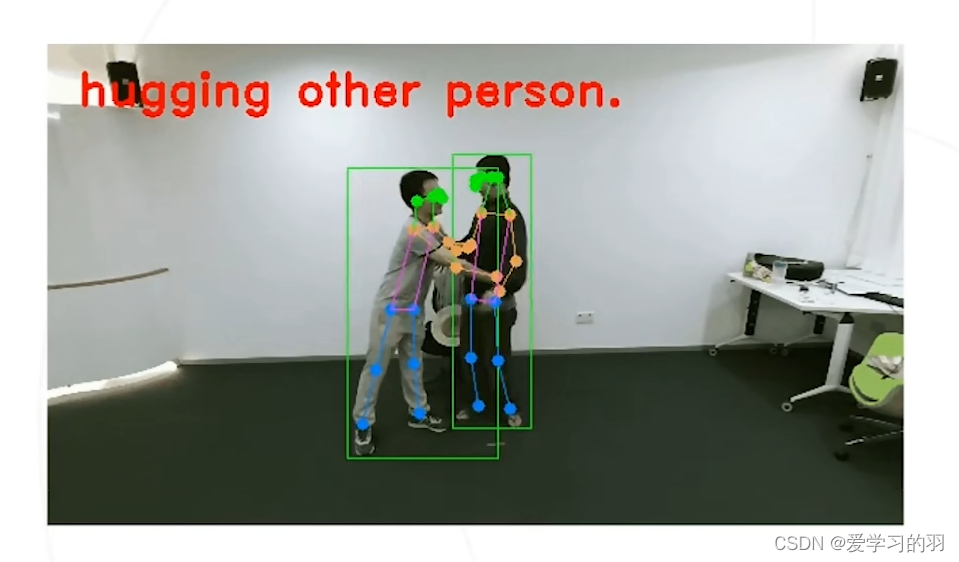
- 实现下游任务–行为理解,根据姿态判断人是否在拥抱
- CG动画:根据人的表情姿态驱动动漫人物做一些动作

- 手势识别
- 动物行为识别
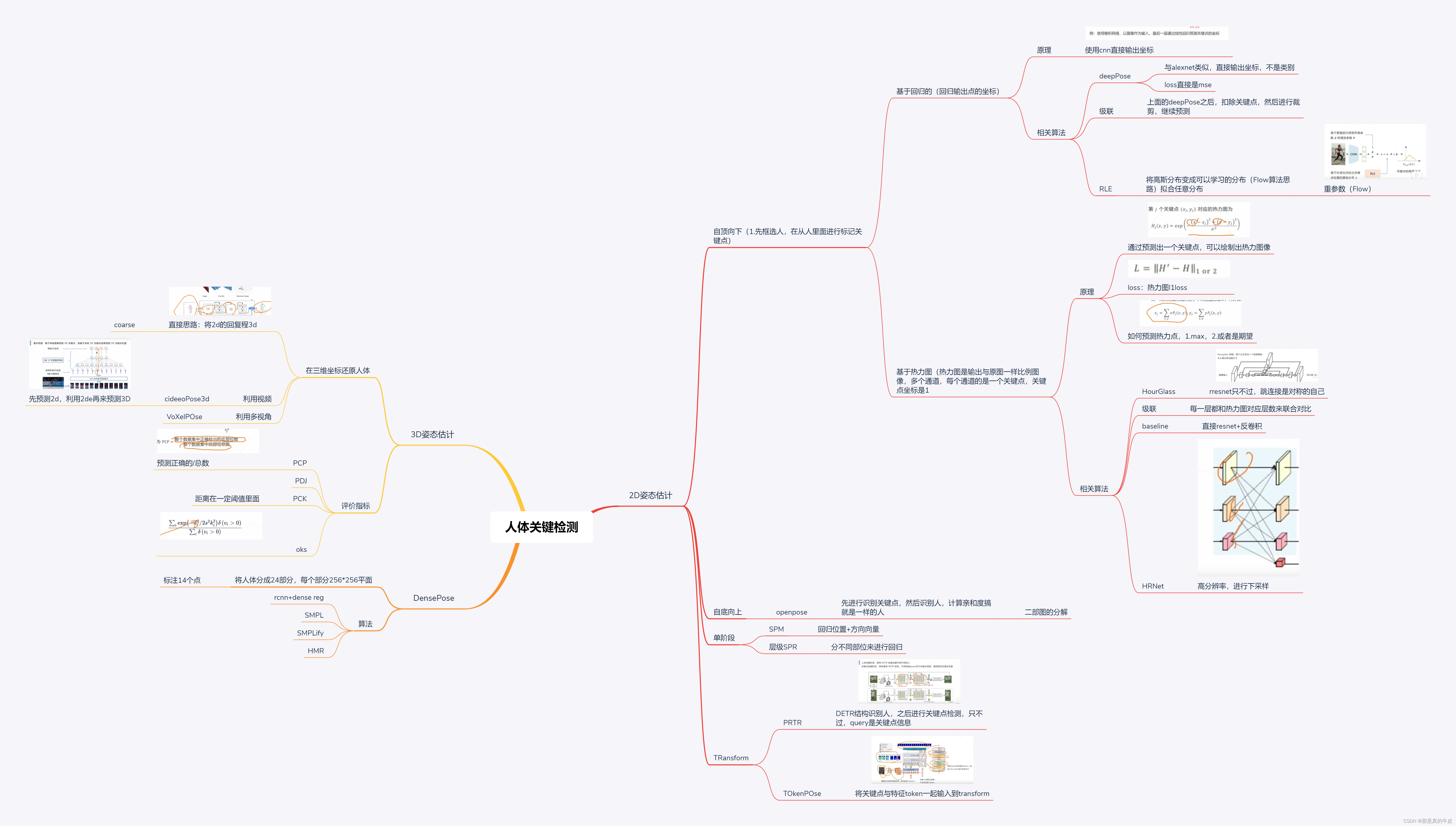
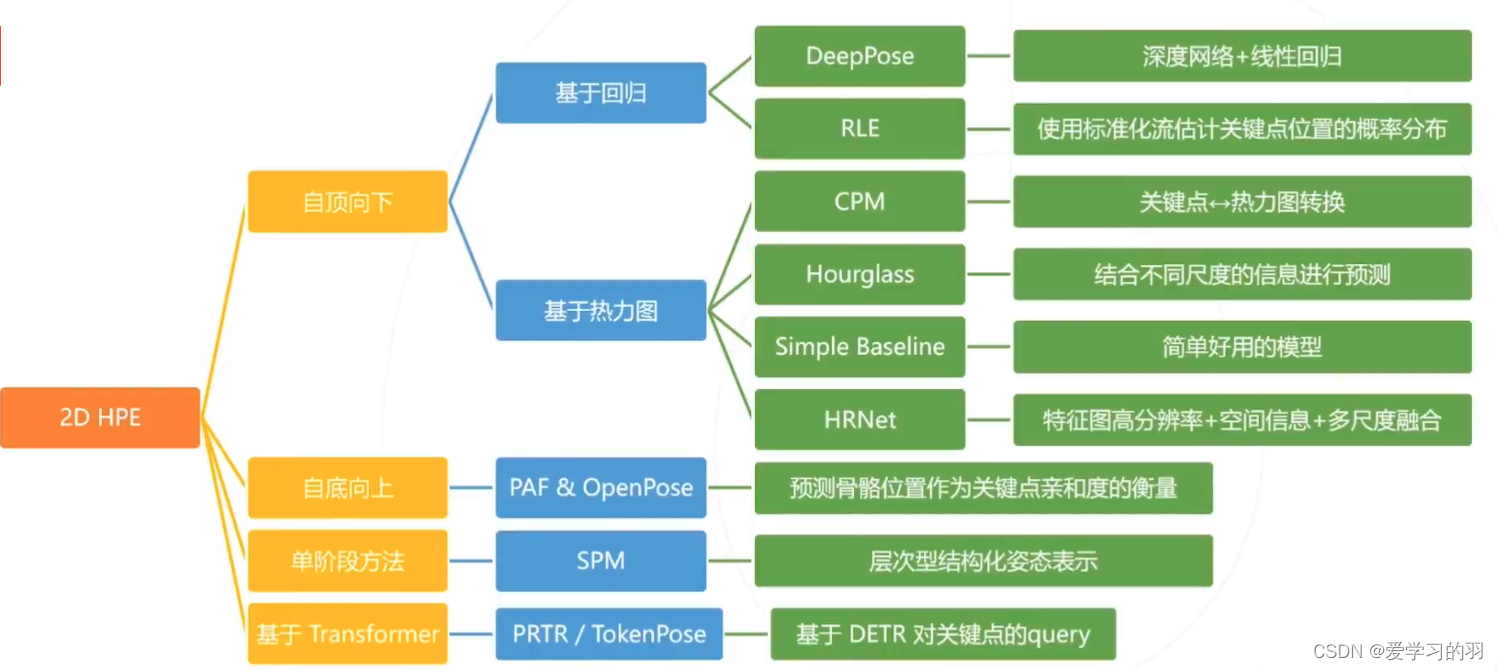
2D姿态估计的基本思路
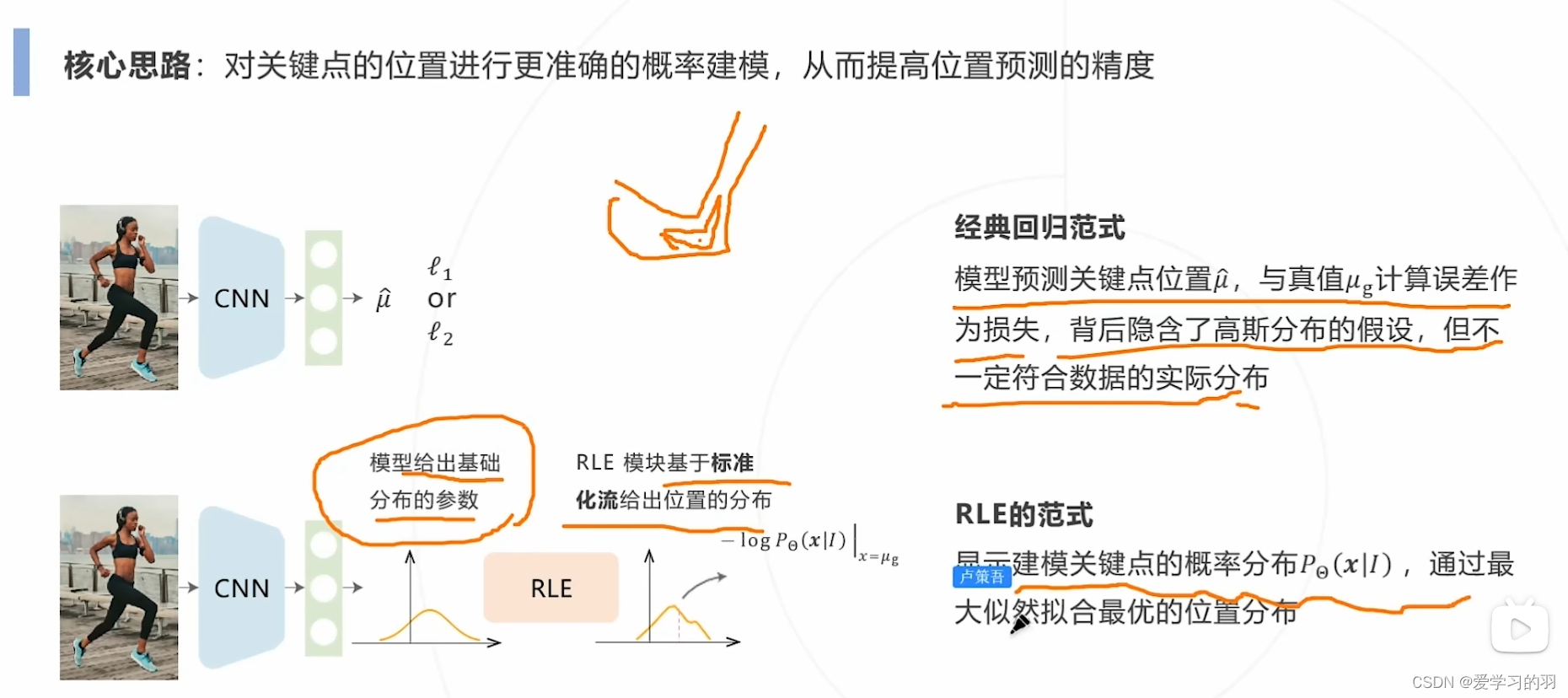
- 基于回归
将关键点检测问题建模成一个回归问题,使得模型直接回归关键点坐标
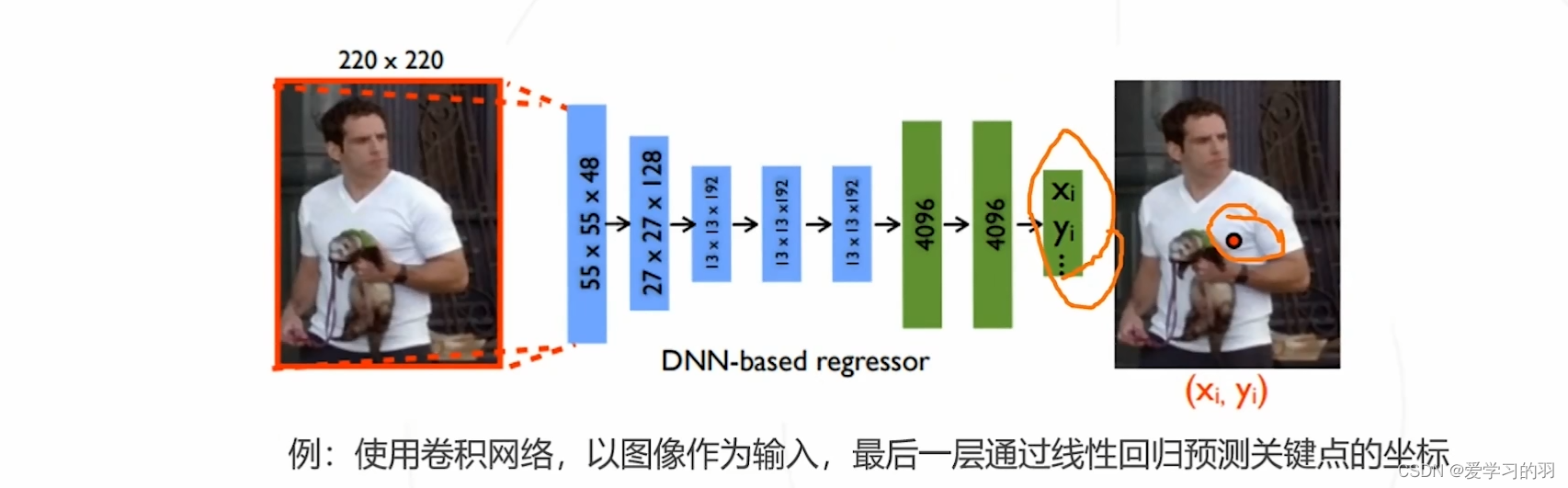
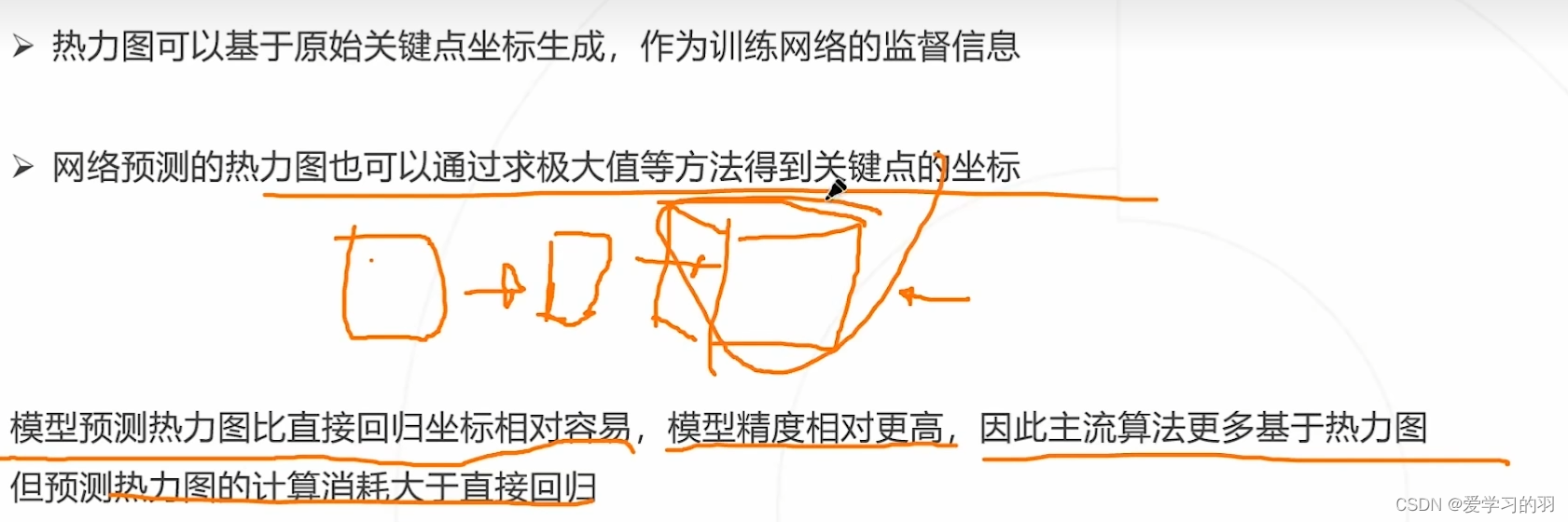
神经网络的最后一层作为回归预测,此方法精度不高 - 基于热力图
预测关键点位于每个位置的概率
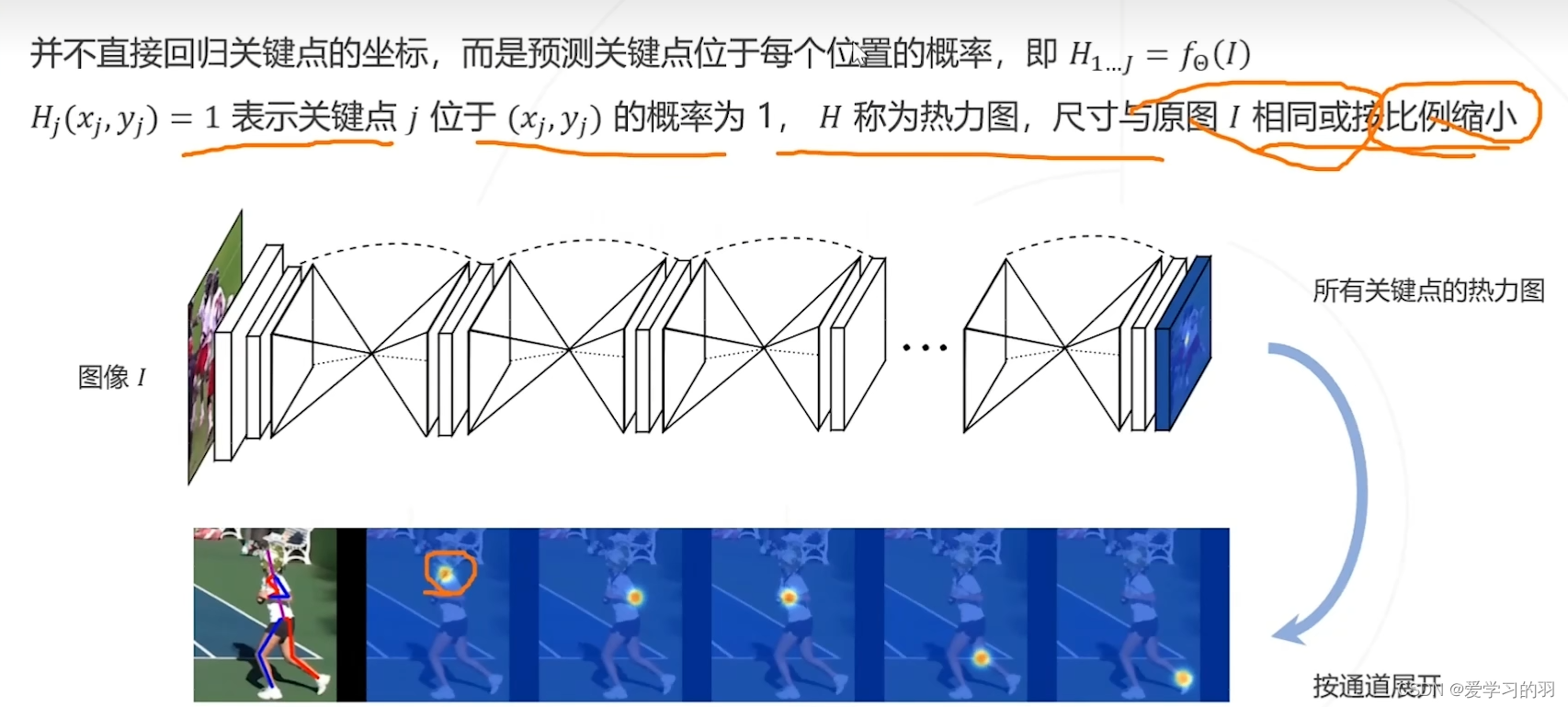
卷积神经网络关注局部信息,对图像上每处的权值(关注度)不同
多人姿态估计
-
自顶向下方法
先用目标检测算法框出人的位置,再基于单人图像估计每个人的姿态
缺点:人越多,计算量越大,耗时长;整体受限于目标检测器的精度 -
自底向上方法
先检测出关键点,再基于位置关系或者其他信息聚类成不同的人

优点:推理速度与人的数量无关
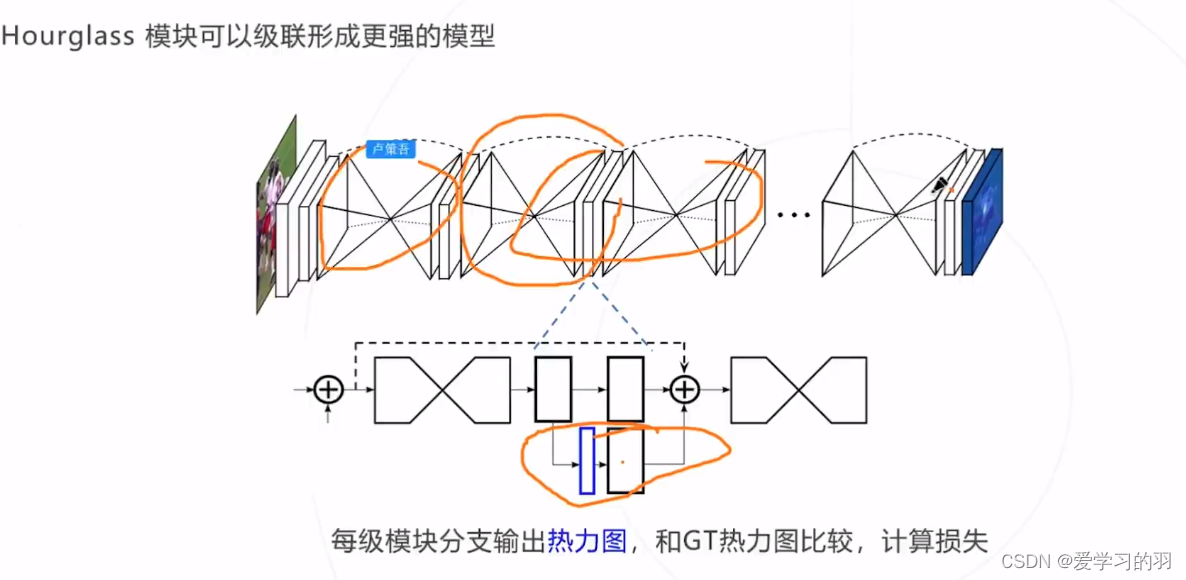
级联的好处:不仅看到局部信息,还能使得神经网络参考整体信息
K部图匹配问题,基于亲和度匹配关键点
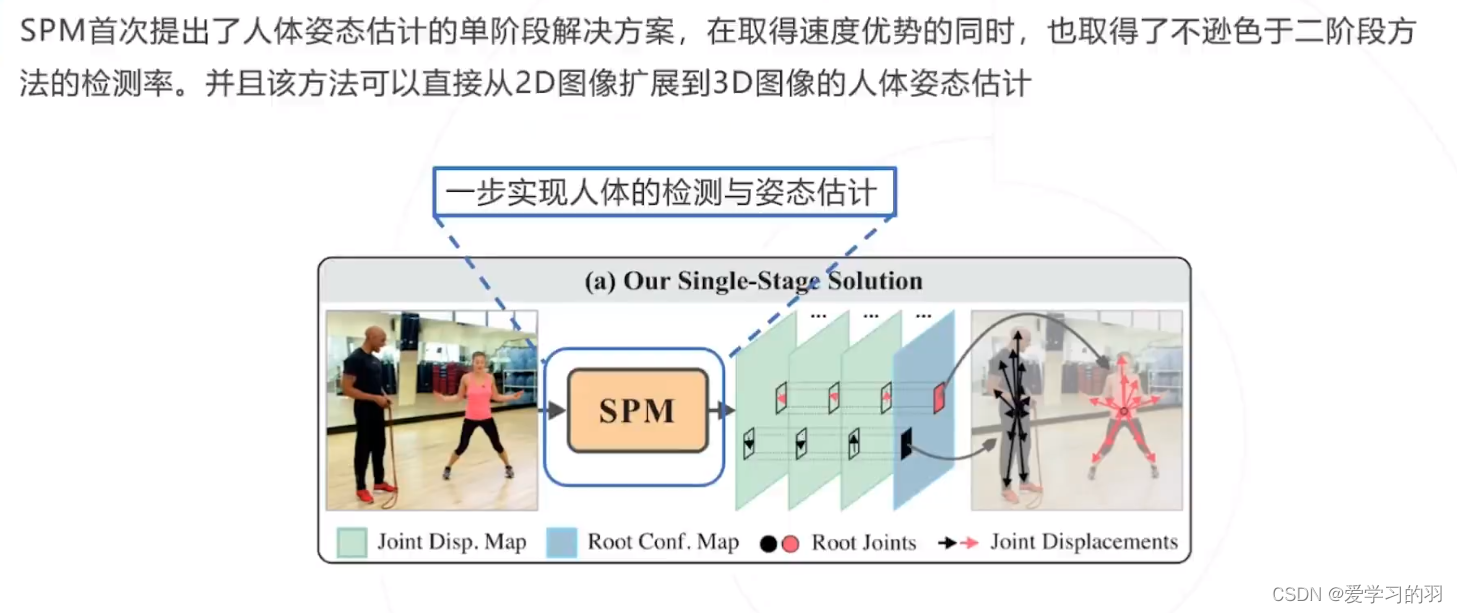
2D姿态估计小结
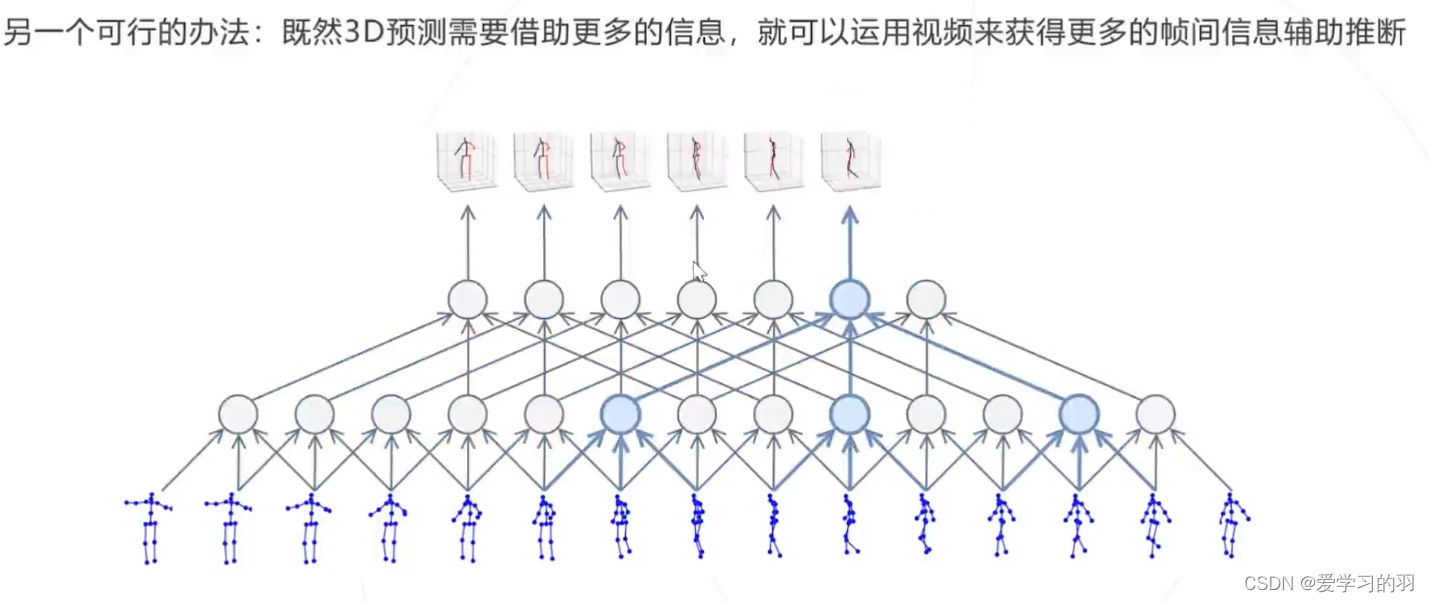
3D姿态估计
- 思路: 利用帧间的视频信息辅助判断
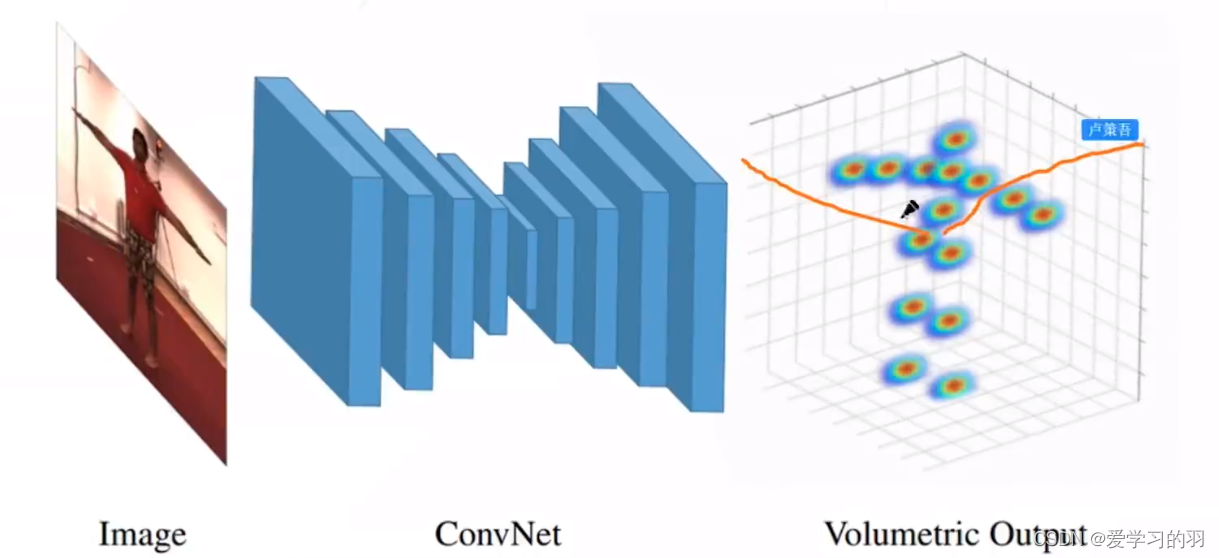
- 单张图像输入卷积网络,预测3D热力图
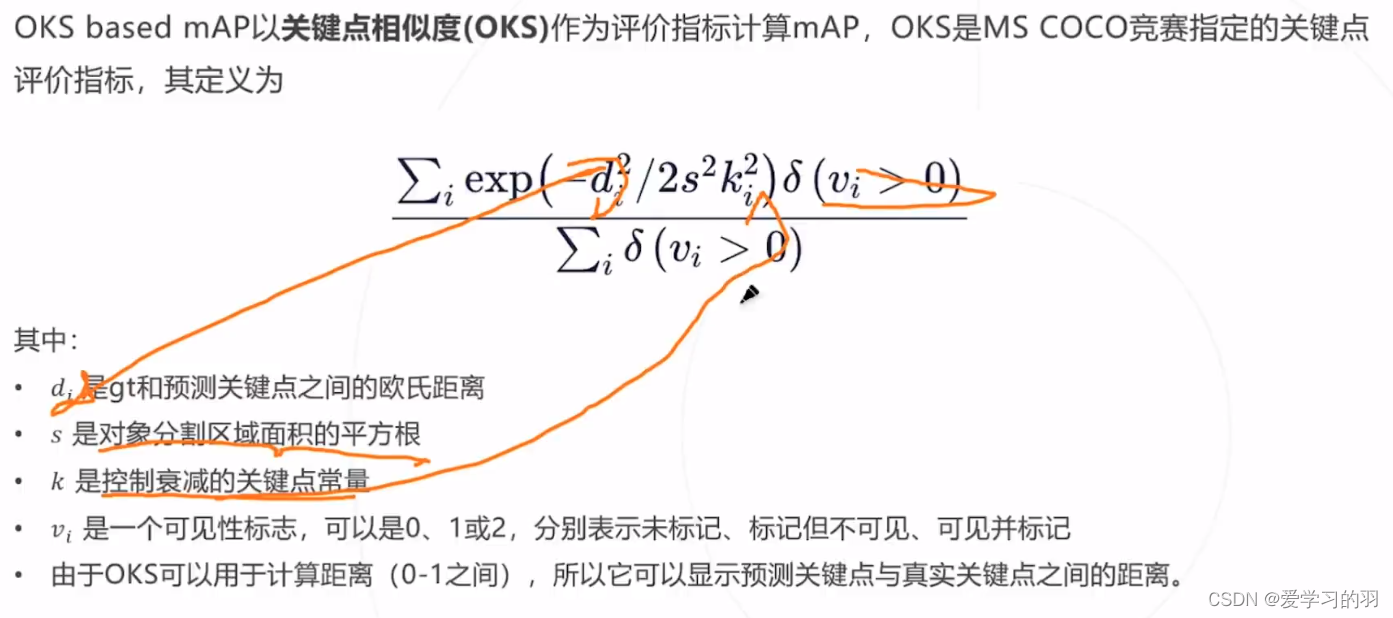
评估标准
使用关键点相似度(OKS)作为评价指标计算
小结