【CVPR2022】CSWin Transformer详解
- 0. 引言
- 1. 网络结构
- 2. 创新点
- 2.1 Cross-Shaped Window Self-Attention
- 2.2 Locally-Enhanced Positional Encoding(LePE)
- 3. 实验
- 总结
0. 引言
Transformer设计中一个具有挑战性的问题是,全局自注意力的计算成本非常高,而局部自注意力通常会限制每个词向量的交互域。为了解决这个问题,作者提出了CSWin Transformer。CSWin Transformer 在常见的视觉任务上展示了非常好的性能。具体来说,它在没有任何额外训练数据或标签的情况下,在 ImageNet-1K 分类任务上达到了 85.4% Top-1 准确率,在 COCO 检测任务上达到了 53.9 box AP 和 46.4 mask AP,在 ADE20K 语义分割任务上达到了 51.7 mIOU,均超过了SwinT。通过在更大的数据集 ImageNet-21K 上进一步预训练,在 ImageNet-1K 上达到了 87.5% 的 Top-1 准确率,在 ADE20K 上达到了最先进的分割性能,达到了 55.7 mIoU。
创新点:
- Cross-Shaped Window Self-Attention(交叉形状窗口注意力机制)
- Locally-Enhanced Positional Encoding(局部增加位置编码)
论文名称:CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows
论文地址:https://arxiv.org/pdf/2107.00652.pdf
代码地址:https://github.com/microsoft/CSWin-Transformer
1. 网络结构

图左为CSWin Transformer整体结构,与Swin Transformer 结构进行对比可以发现:两个网络结构整体是类似的,CSWin Transformer将Swin Transformer Block 变为了 CSwin Transformer Block,另外将Patch Merging 下采样 变为了 Conv下采样。图右为 CSwin Transformer Block 的具体结构,包含两个部分,一个是做LayerNorm和Cross-shaped window self-attention,另一个则是做LayerNorm和MLP。
数据经过模型的流程介绍:首先,输入数据是一个3通道彩色图像,尺寸为
H
×
W
×
3
H\times W \times 3
H×W×3。图像首先经过一组步长为
4
4
4,卷积核为
7
×
7
7\times 7
7×7 的卷积,得到的Feature Map的尺寸为
H
4
×
W
4
×
C
\frac{H}{4}\times \frac{W}{4} \times C
4H×4W×C。之后CSWin Transformer分成4个Stage,Stage之间通过步长为
2
2
2 的卷积对Feature Map来进行下采样。和典型的Resnet 50设计类似,每次下采样后,会减少token的数量,并将dimension增加一倍。一是为了提升感受野,二是为了增加特征。
2. 创新点
2.1 Cross-Shaped Window Self-Attention
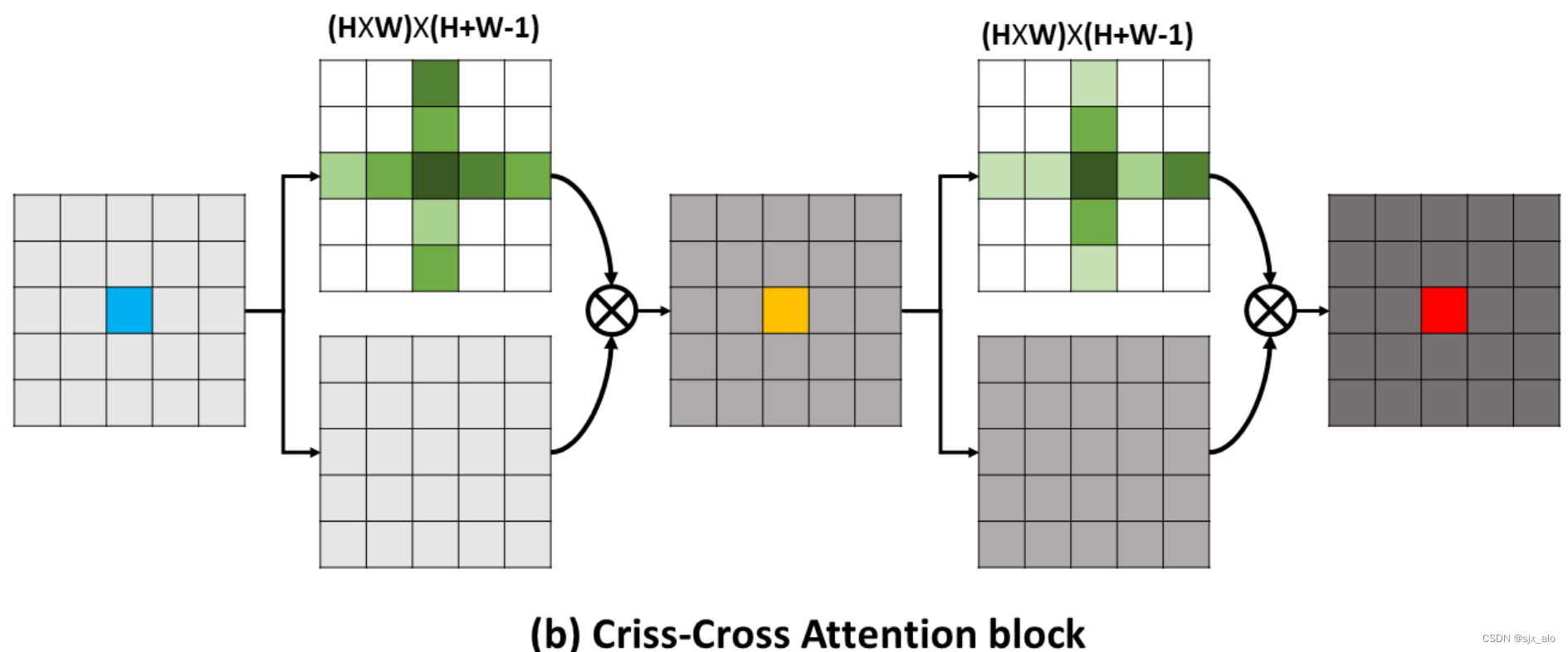
在全局注意力中,整个特征图被统一计算,计算成本非常高;而在Swin Transformer Block 中,SW-MSA被提出用来计算窗口注意力,在减少计算成本的基础上,通过对窗口进行平移重新计算注意力来打破不同窗口之间的限制,从而获取到全局信息。同样地,为了解决全局自注意力的计算成本非常高,而局部自注意力通常会限制每个词向量的交互域的问题。作者在基于criss-cross基础 (如上图所示)上对swin transformer进行了改进,将原有的非重叠和移动窗口改为了交叉型窗口,即Cross-Shaped Window Self-Attention 。

上图为Cross-Shaped Window Self-Attention 的计算流程。整体而言,整个特征图的计算分为横向计算和纵向计算,并将计算得到的特征进行合并作为Cross-Shaped Window Self-Attention 的结果。
具体而言:根据多头自注意机制,对于输入特征
X
∈
R
(
H
×
W
)
×
C
X\in R^{(H×W)×C}
X∈R(H×W)×C 。首先,将其线性投影到
K
K
K 个头部,然后每个头部将在水平或垂直条纹内执行局部自注意。
对于水平条纹自关注, X X X 被均匀拆分为 M = H S W M=\frac{H}{SW} M=SWH 个横条的数据,其中 S W SW SW 表示横条的宽度,可以调整以平衡学习能力和计算复杂度; X = [ X 1 , . . . , X M ] X=[X^1,...,X^M] X=[X1,...,XM] 。
对于每个条状特征
X
i
,
i
=
1
,
2
,
.
.
.
,
M
X^i,i=1,2,...,M
Xi,i=1,2,...,M,使用Transformer可以得到它的特征
Y
i
Y^i
Yi ,最后将这
M
M
M 个特征拼接到一起便得到了这个head的输入。假设它属于第
k
k
k 个head,那么横向自注意力
H
−
A
t
t
e
n
t
i
o
n
k
(
X
)
H-Attention_k(X)
H−Attentionk(X) 的计算方式为:
X
∈
R
(
H
×
W
)
×
C
X
=
[
X
1
,
X
2
,
.
.
.
,
X
M
]
,
w
h
e
r
e
X
i
∈
R
(
S
W
×
W
)
×
C
a
n
d
M
=
H
S
W
Y
k
i
=
A
t
t
e
n
t
i
o
n
(
X
i
W
k
Q
,
X
i
W
k
K
,
X
i
W
k
V
)
,
w
h
e
r
e
i
=
1
,
.
.
.
,
M
H
−
A
t
t
e
n
t
i
o
n
k
(
X
)
=
[
Y
k
1
,
Y
k
2
,
.
.
.
,
Y
k
M
]
X\in R^{(H×W)×C} \\\ X = [X^1,X^2,...,X^M], where\ X^i\in R^{(SW×W)×C}\ and \ M=\frac{H}{SW} \\\ Y^i_k = Attention(X^iW^Q_k, X^iW^K_k, X^iW^V_k), where \ i=1,...,M\\\ H-Attention_k(X) = [Y^1_k, Y^2_k,...,Y^M_k]
X∈R(H×W)×C X=[X1,X2,...,XM],where Xi∈R(SW×W)×C and M=SWH Yki=Attention(XiWkQ,XiWkK,XiWkV),where i=1,...,M H−Attentionk(X)=[Yk1,Yk2,...,YkM]
纵向自注意力 V − A t t e n t i o n V-Attention V−Attention 和 H − A t t e n t i o n H-Attention H−Attention 的计算方式类似,不同的是它是取的宽度为 S W SW SW 的竖条。
最终,这个block的输出表示为:
C
S
W
i
n
−
A
t
t
e
n
t
i
o
n
(
X
)
=
C
o
n
c
a
t
(
h
e
a
d
1
,
.
.
.
,
h
e
a
d
K
)
W
O
h
e
a
d
k
=
{
H
−
A
t
t
e
n
t
i
o
n
k
(
X
)
k
=
1
,
.
.
.
,
K
/
2
V
−
A
t
t
e
n
t
i
o
n
k
(
X
)
k
=
K
/
2
+
1
,
.
.
.
,
K
CSWin-Attention(X) = Concat(head_1,...,head_K)W^O \\\ head_k = \begin{cases} H-Attention_k(X) \ \ k=1,..., K/2 \\ V-Attention_k(X) \ \ k=K/2+1,...,K \end{cases}
CSWin−Attention(X)=Concat(head1,...,headK)WO headk={H−Attentionk(X) k=1,...,K/2V−Attentionk(X) k=K/2+1,...,K
其中
W
O
∈
R
C
×
C
W^O\in R^{C\times C}
WO∈RC×C 用来调整Feature Map的通道数,并可以将两个不同方向的自注意特征进行融合。
如上所述,我们的自注意机制设计的一个关键见解是将多头分成不同的组,并相应地应用不同的自注意操作。换句话说,通过多头分组扩大了一个Transformer块中每个令牌的关注区域。相比之下,现有的自注意机制在不同的多头中应用相同的自注意操作。在实验部分,我们将证明这种设计将带来更好的性能。
计算复杂度分析
CSWin自关注的计算复杂度为:
Ω
(
C
S
W
i
n
)
=
H
W
C
∗
(
4
C
+
S
W
∗
H
+
S
W
∗
W
)
Ω(CSWin) = HW C∗(4C + SW∗H + SW∗W)
Ω(CSWin)=HWC∗(4C+SW∗H+SW∗W)
对于高分辨率输入,考虑H, W在前期大于C,后期小于C,我们选择前期较小的SW,后期较大的SW。换句话说,调整SW提供了灵活性,可以在后期以有效的方式扩大每个令牌的关注区域。此外,为了使224 × 224输入的中间特征映射大小可以被SW整除,我们经验地将SW设置为1、2、7、7。
2.2 Locally-Enhanced Positional Encoding(LePE)

因为Transformer是输入顺序无关的,因此需要向其中加入位置编码。上图左边为ViT模型的PE,使用的绝对位置编码或者是条件位置编码,只在embedding的时候与token一起进入transformer,中间的是Swin,CrossFormer等模型的PE,使用相对位置编码偏差,通过引入token图的权重来和attention一起计算,灵活度更好相对APE效果更好。
本文所提出的LePE,相比于RPE更加直接,直接将位置编码添加加到了Value向量上,它的添加方式是通过将位置编码
E
E
E 和
V
V
V 相乘完成的。然后通过一个short-cut将添加了位置编码
V
V
V 的和通过自注意力加权的
V
V
V 单位加到一起,公式如下:
A
t
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
S
o
f
t
M
a
x
(
Q
K
T
/
d
)
V
+
E
V
Atttention(Q,K,V) = SoftMax(QK^T/\sqrt{d})V + EV
Atttention(Q,K,V)=SoftMax(QKT/d)V+EV
这里作者基于一个假设:对于一个输入元素,他附近的元素提供最重要的位置信息。所以对V做一个深度卷积
E
E
E ,加到softmax之后的结果上。公式为:
A
t
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
S
o
f
t
M
a
x
(
Q
K
T
/
d
)
V
+
D
W
C
o
n
v
(
V
)
Atttention(Q,K,V) = SoftMax(QK^T/\sqrt{d})V + DWConv(V)
Atttention(Q,K,V)=SoftMax(QKT/d)V+DWConv(V)
这样,LePE可以友好地应用于将任意输入分辨率作为输入的下游任务。从另一个角度看,CSWin-Transformer block是一个由十字形窗口自注意力和CNN组成的多分支的结构。
3. 实验
为了与类似设置下的其他Transformer进行公平的比较,作者构建了四种模型,CSWin-T, CSWin-S, CSWin-B, CSwin-L,这里的FLOPs都是在224x224条件下计算的。

为了证明有效性,作者对ImageNet- 1K 分类、COCO 目标检测和ADE20K 语义分割进行了实验。

CSWin-T仅4.3GFLOPs达到82.7%的Top-1准确度,超过CvT-13、Swin-T和DeiT-S。CSWin-S和CSWin-B也取得了最好的性能。当对384×384输入进行微调时,也观察到一样的趋势。作者发现CSWin是唯一一种基于Transformer架构并且在small和base设置下取得了和Effificient Net相当甚至更好的结果,同时计算复杂度更低。

Mask R-CNN的结果,CSWin Transformer优于所有的CNN和Transformer同行。

表5报告了使用Cascade Mask R-CNN 框架的结果。

使用ImageNet-21K预训练模型时,CSWin-L进一步达到55.7 mIoU,超过之前的最佳模型,计算复杂度更小。
消融实验:

当用用顺序的多头注意力机制替换并行方式时,CSWin在所有任务上的性能都会下降。CSWins w = 1 在ImageNet上的表现略优于Axial,但在下游任务上明显优于它。sw = 2 CSWin的表现略优于 Criss-Cross,而CSWin的速度比它在不同任务上的速度快2∼5,进一步证明了“并行”设计更有效。

在图4中,随着条纹宽度的增加,计算成本(FLOPS)增加,Top-1的分类准确度在开始时大大提高,当宽度足够大时则减慢。默认设置[1,2,7,7]在准确度和FLOPs之间实现了一个很好的权衡。

使用Swin-T作为主干,只改变了Self-Attention。

用CSWin-T作为主干,并且只使用位置编码。LePE与其他位置编码机制(APE、CPE 和RPE)进行了比较,用于图像分类、目标检测和图像分割。此外,还测试了没有PE和CPE*的变量。
根据比较结果,可以看到: 1)位置编码可以通过引入局部归纳偏置带来性能增益;2)虽然RPE在固定输入分辨率的分类任务中取得了相似的性能,但LePE在输入分辨率不同的下游任务上表现更好。
总结
CSWin Transformer的核心设计是Cross-Shaped Window Self-Attention,它通过将Multi-head分成并行组,水平和垂直条纹进行Self-Attention。这种设计可以有效地扩大一个Transformer块内每个token的注意区域,并且随着stage的加深,SW宽度变宽,感受野会迅速扩大。另一方面,将局部增强的位置编码引入到CSWin Transformer中,用于下游任务。在有限的计算复杂度下,在各种视觉任务上实现了先进的性能。
如果有什么疑问欢迎在评论区提出,对于共性问题可能会后续添加到文章介绍中。