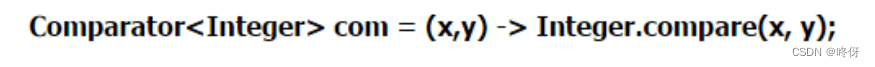回归测试:优先级
介绍
在确定优先级时,我们的目标是为测试用例找到一个好的顺序。理想情况下,我们希望尽早发生任何故障。这可以加快整体开发过程,例如:
有时,一旦发现失败,我们就会停止测试。
即使我们计划执行所有测试用例,我们越早发现失败,我们就可以越早开始尝试修复代码。
问题:我们事先不知道哪些测试用例会导致失败。
因此,我们无法在测试前知道“最佳”顺序。
相反,我们使用相关的指标和历史信息有缺陷:
我们优先考虑被认为更有可能导致失败的测试。
我们还致力于快速扩大覆盖范围。
希望:通过这样做,我们更有可能早点发现错误
使用覆盖
我们可能只看覆盖率。
我们的目标可能是:
尽快达到 100% 的覆盖率。
最大化给定预算的覆盖范围(例如测试用例的数量)。
无论何时停靠,“快速”实现覆盖以获得“良好”覆盖
贪心算法可能是次优的suboptimal

Coverage 的适应度函数Fitness function
考虑分支覆盖率(许多其他指标类似)。
我们如何为特定的测试顺序给出“分数”/适应度
案件?
我们想要奖励对所有前缀都有利的订单。
标准方法:使用加权平均百分比
覆盖测试用例序列。
如果我们有 n 个测试用例,m 个分支,TBi 是第一个执行分支 i 的测试用例的编号,那么适应度为:
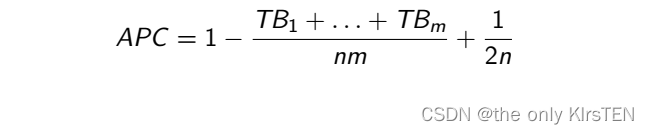
优化
类似于最小化,我们可能有多个目标
例如:
(1)覆盖形式不同。
(2) 对历史故障部件进行优先测试。
(3)基于故障预测技术对元器件进行优先测试。
有可能再次使用多目标优化。
概括
在某些情况下,将使用给定的测试套件:
回归测试; 持续集成
最小化和优先化都有好处。
两者都可以表示为优化问题。有许多不同的优化方法,从
多目标进化的简单贪心算法算法。