1 文件系统和分布式文件系统
1.1 文件系统
- 文件系统:一种存储和组织数据的方法
- 实现了数据的存储、分级组织、访问、获取等操作
- 使得用户对文件的访问和查找更容易
- 使用树形目录的抽象概念代替了硬盘等物理设备中数据块的概念
- ——>用户不必关系数据底层存在硬盘的哪里(物理位置),只需要知道这个文件的所属路径(逻辑位置)即可
1.1.1 传统文件系统
- 单机文件系统
- 底层不会横跨多台机器
- 带有抽象的目录树结构,树都是从根目录开始向下蔓延
- 树中节点:目录or文件
- 从根目录开始,各节点路径唯一
1.2 数据 & 元数据
- 数据:存储内容本身
- 最终存在磁盘等存储介质上
- 元数据
- 解释性数据(记录数据的数据)
- eg,文件大小、最后修改时间、属性、权限。。。
- 解释性数据(记录数据的数据)
1.2.1 元数据记录
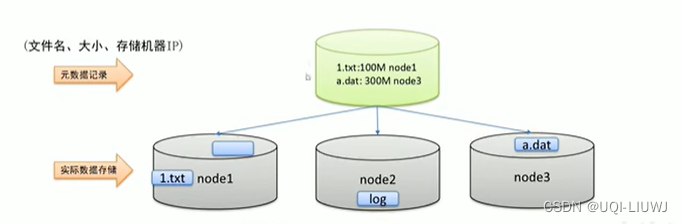
1.2.2 分块存储+元数据记录
一个文件存在多个机器上
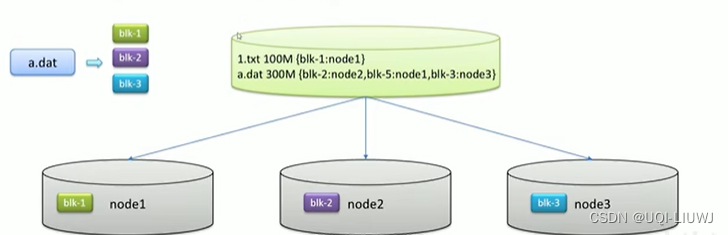
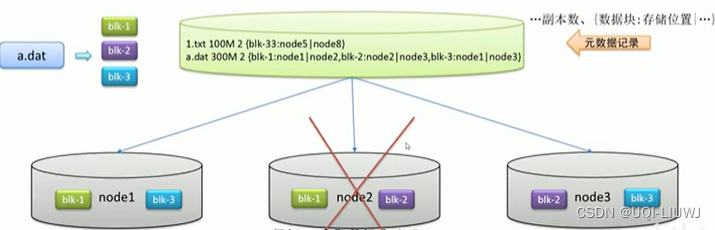
1.2.3 副本机制+分块存储+元数据记录
- 一个文件的一部分的副本存在多台机器上
- 冗余存储
- 防止万一一台机器坏了数据无法恢复
2 Hadoop 核心组件
- HDFS(hadoop distributed file system)
- 分布式文件存储系统
- ——>解决海量数据存储
- YARN
- 集群资源管理和任务调度框架
- ——>解决资源调度问题(整个集群多个程序同时执行,如何分配集群资源?)
- MapReduce
- 分布式计算框架
- ——>解决海量数据计算
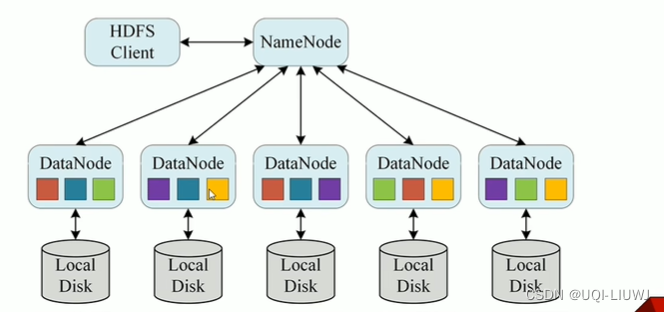
2.1 HDFS
- 横跨多台计算机的存储系统
- 使用统一的访问接口,像访问普通文件系统一样使用分布式文件系统
2.1.1 设计目标
- 硬件故障
- ——>故障检测+自动快速恢复
- 流式读取数据
- ——>批处理数据,并非用户交互式处理
- ——>相较于数据访问的反应时间(访问文件的延迟会很高),更注重数据访问的高吞吐量
2.1.2 一次写入多次读取(write-one-read-many)
- 数据一旦创建、写入、关闭后不需要修改
- HDFS不支持文件的直接编辑修改
- ——>简化了数据一致性问题,使得高吞吐量的数据访问成为可能
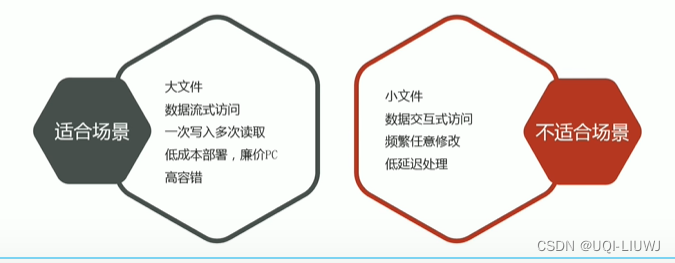
2.1.3 应用场景
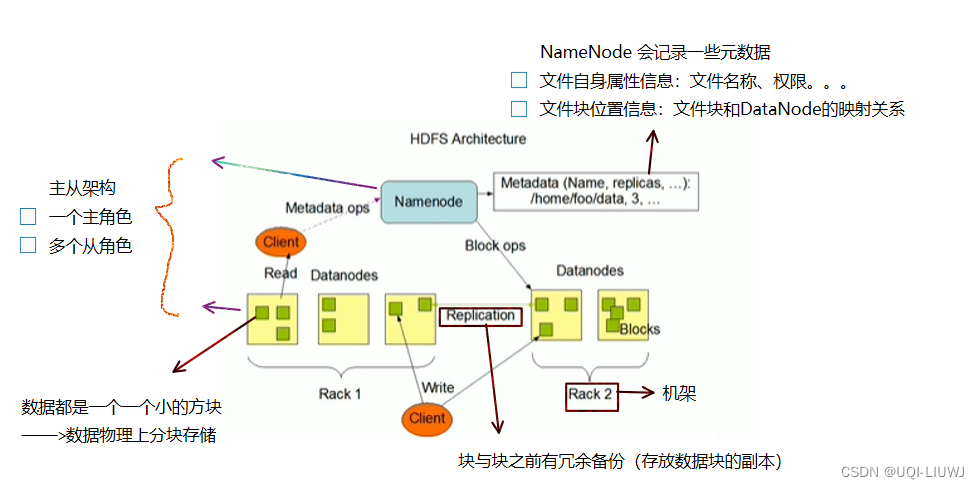
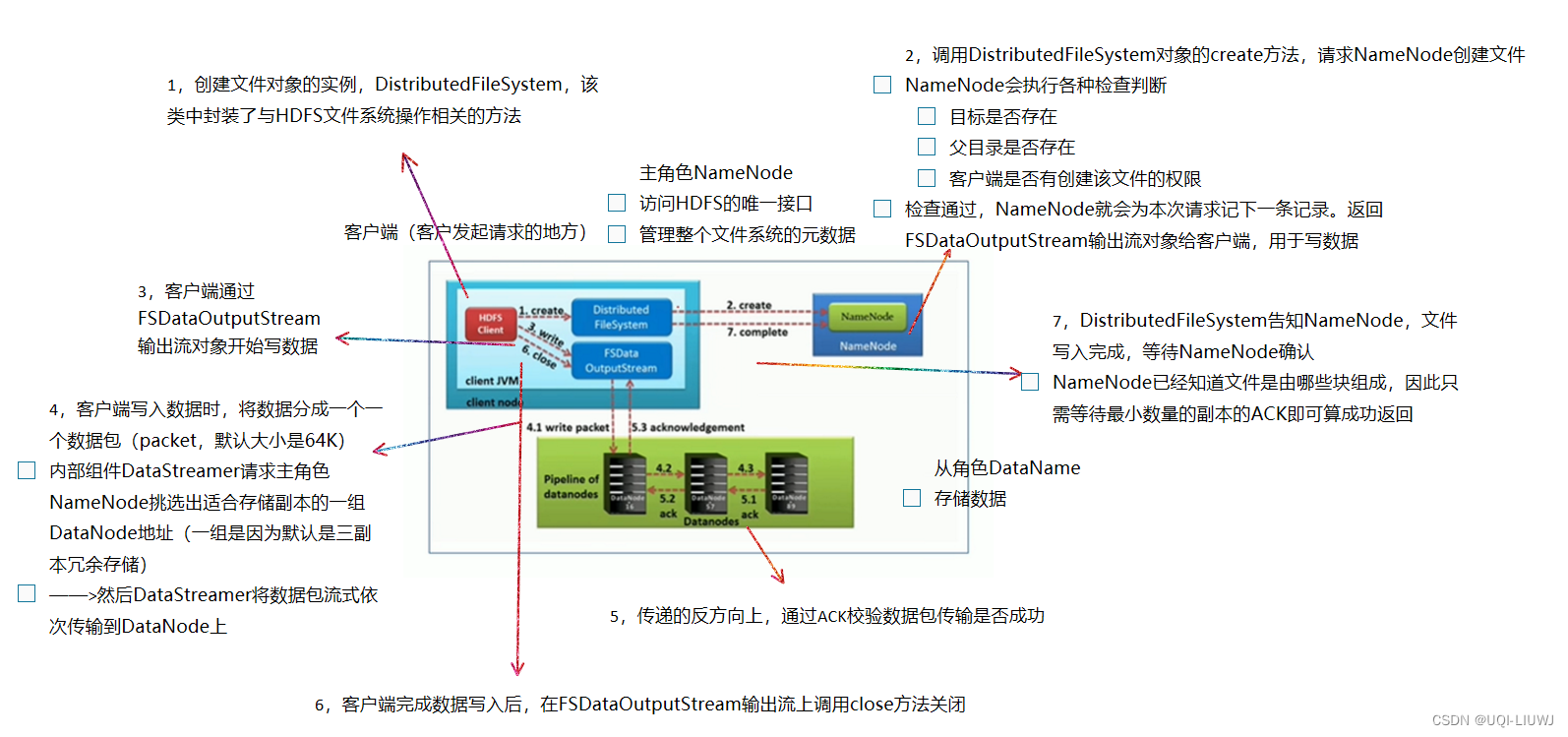
2.1.4 主角色 NameNode
- 维护和管理文件系统元数据
- 名称空间目录树结构
- 文件和块的位置信息
- 访问权限
- ——>仅储存元数据,不存储实际数据
- ——>NameNode 是访问HDFS的唯一入口
- NameNode 内部通过内存和磁盘文件两种方式管理元数据
- 内存:
- 交互和查找快
- 但是一旦断电,数据就丢失了
- 磁盘文件定期进行合并持久化,来保证元数据安全
- 磁盘上的元数据包括:
- Fsimage内存元数据镜像文件
- edits log (Journal)编辑日志
- 内存:
- NameNode不会持久化存储每个文件中各个块所在的DataNode的位置信息
- 断电了就没有了
- 重启之后需要从DataNode重建
- ——>DataNode会将自己注册到NameNode,并汇报自己持有的块列表
- NameNode所在机器需要配置大量内存
- NameNode是Hadoop集群中的单点故障
- 单点故障:一个软件由多个模块组成,当中一个模块出问题导致了整体出问题

2.1.5 从角色 DataNode
- 负责具体的数据块存储
- DataNode的数量决定了HDFS集群的整体数据存储能力
- 扩容集群——扩容DataNode数量
- 某个DataNode关闭时,不会影响数据的可用性
- 默认DataNode是3副本冗余存储
- NameNode会安排由其他DataNode管理的块进行副本复制
- DataNode所在机器通常需要配置有大量的硬盘空间(大磁盘),因为实际数据存储在DataNode中
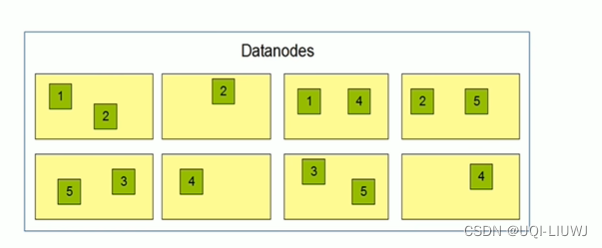
2.1.6 主角色辅助角色 SecondaryNameNode
- NameNode的辅助节点,但是不能替代NameNode(不是NameNode的备份)
- 帮助主角色进行元数据文件的合并操作
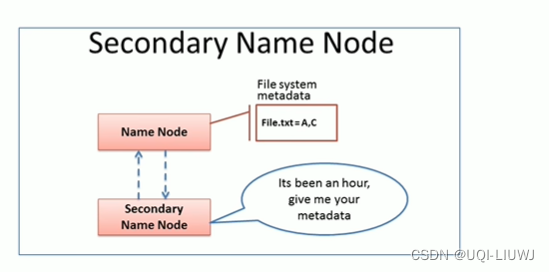
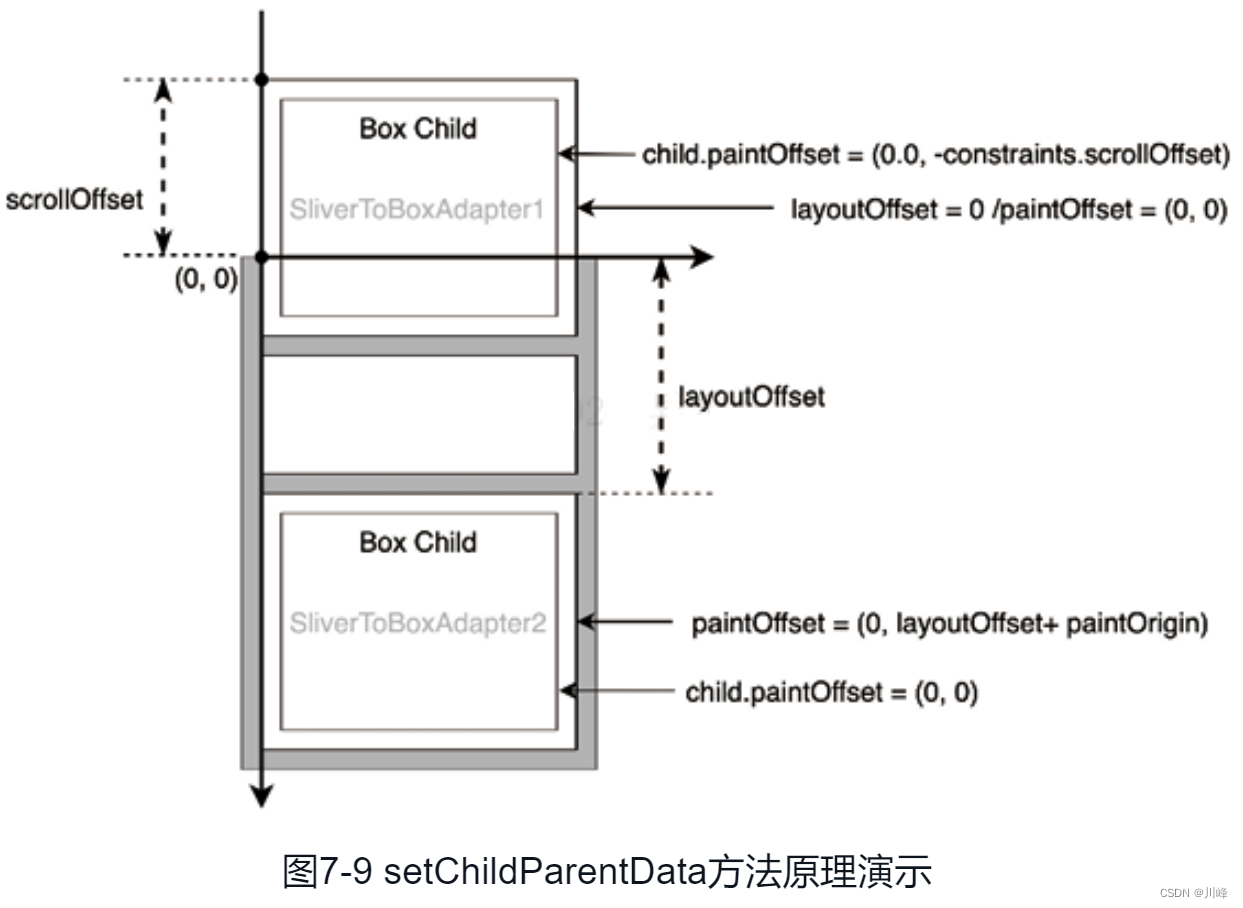
2.1.7 HDFS写数据流程
- 管道Pipeline
- HDFS上传文件写数据时采用的一种数据传输方式
- 冗余储存的多个副本,怎么写入?
- ——>客户端将数据块写入第一个数据节点
- ——>第一个数据节点保存数据之后再将数据块复制到第二个数据节点
- ——>第二个数据节点保存数据之后再将数据块复制到第三个数据节点
- (水流一样一次向下传递)
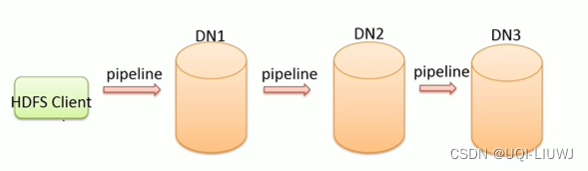
- 为什么是采用pipeline线性传输,而不是客户端一次给三个DataNode拓扑式传输?
- 数据以pipeline的方式,顺序地沿着一个方向传输的话,可以充分利用每台机器的带宽,避免网络瓶颈和高延迟连接
- ——>最小化写入所有数据的延时
- 数据以pipeline的方式,顺序地沿着一个方向传输的话,可以充分利用每台机器的带宽,避免网络瓶颈和高延迟连接
- 冗余储存的多个副本,怎么写入?
- HDFS上传文件写数据时采用的一种数据传输方式
- ACK 应答相应
- ack ——acknowledge character
- 确认字符
- 数据通信的时候,接收方给发送方一种传输类字符,表示发送的数据已经确认无误
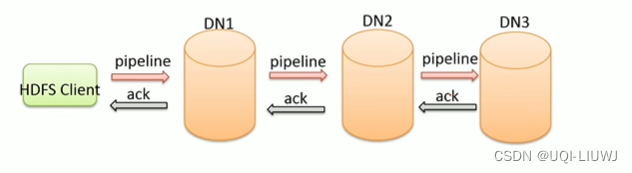
- 在HDFS pipeline传输数据的过程中,传输的反方向会进行ACK校验,以保证数据传输准确+安全
- 两两之间的校验
- ack ——acknowledge character
- 默认3副本存储策略
- 由BlockPlacementPolicyDefault决定
- 第一块副本:优先客户端本地,否则随机
- 第二块副本:不同于第一块副本的不同机架(rack)
- 第三块副本:和第二块副本相同机架的不同机器
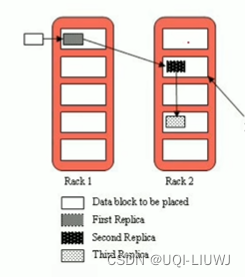
- 由BlockPlacementPolicyDefault决定
2.2 MapReduce
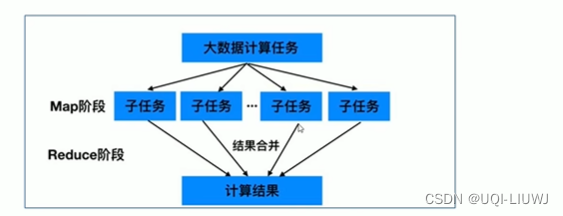
2.2.1 Map
- Map
- 拆分,把复杂的任务分解成若干个简单的子任务来并行处理
- 多个进程、多个机器
- 可以进行拆分的前提是这些小任务可以并行计算,且彼此之间几乎没有依赖关系
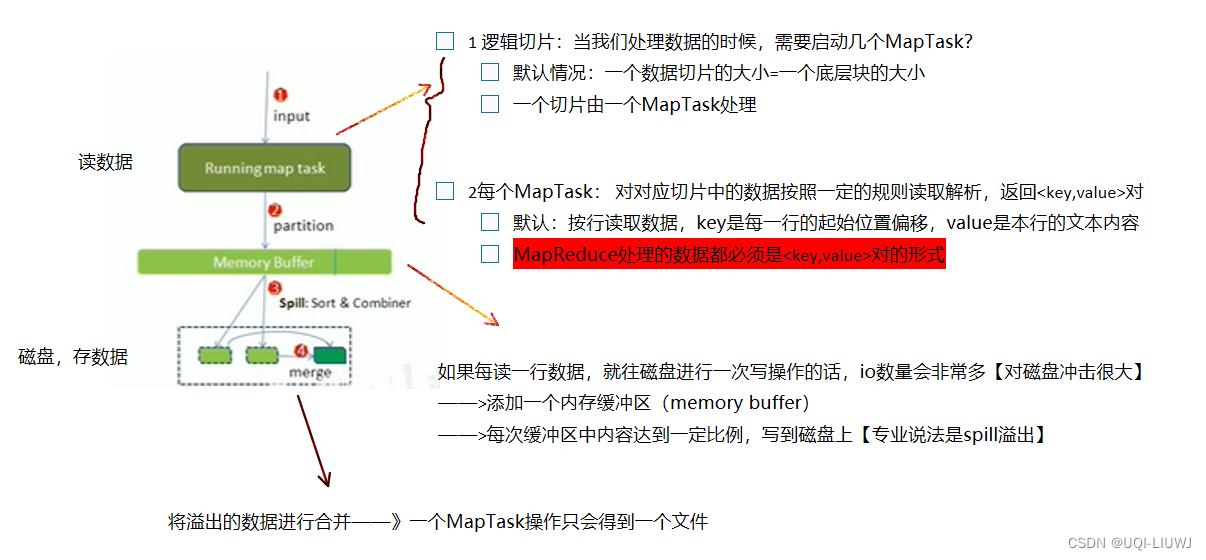
- 拆分,把复杂的任务分解成若干个简单的子任务来并行处理
2.2.2 Reduce
- Reduce
- 合并
- 对map阶段的结果进行全局处理
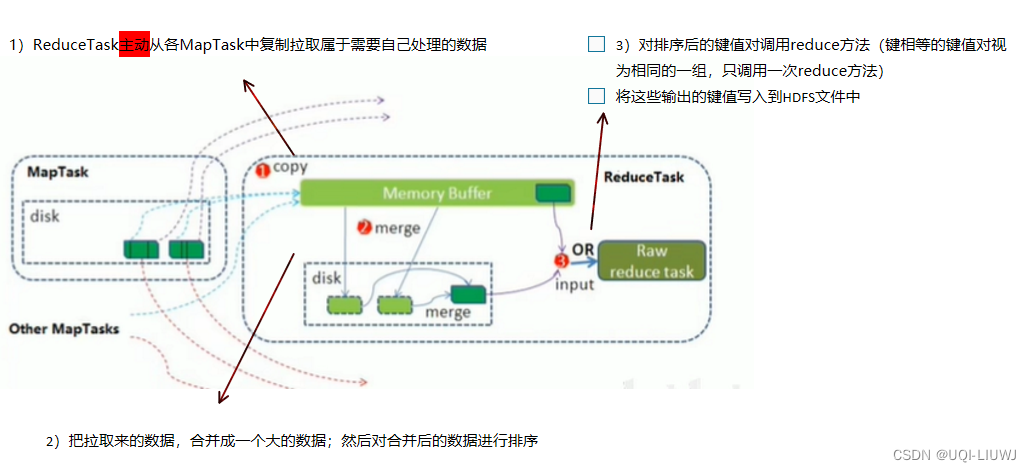
2.2.3 Shuffle
- MapReduce的核心
- 频繁涉及数据在内存、磁盘之间的多次往复
- map完每个切片写到内存缓冲区、内存缓冲区数据Spill溢出到磁盘
- reduce:copy数据现在内存,merge到磁盘
- 频繁涉及数据在内存、磁盘之间的多次往复
- 这里的shuffle更像是“洗牌”的逆过程:将map端的无规则输出按照指定的规则“打乱”成具有一定规则的数据
- ——>作用是方便reduce端处理
- 一般把Map产生输出之后,到Reduce取得数据作为输入之前的过程称为shuffle
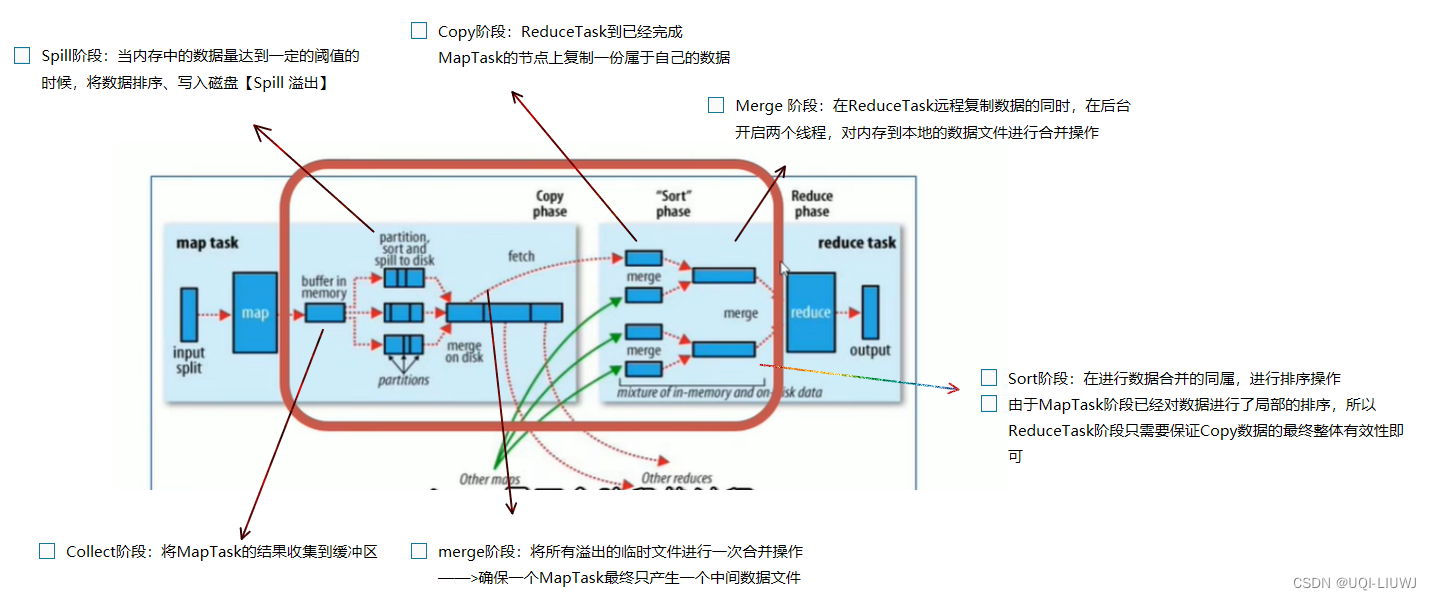
Shuffle中的大部分步骤在Map和Reduce中都提到
2.3 YARN
2.3.0 介绍
- Yet Another Resource Negotiator,另一种资源协调者
- 另一种Hadoop资源管理器
- 资源指的是集群的硬件资源:比如内存、CPU等【磁盘不归YARN管,由HDFS管】
- 为上层应用提供统一的资源管理和调度
- 不仅支持MapReduce,理论上支持各种计算程序(比如Spark)
- ——>通用、可迁移
- 另一种Hadoop资源管理器
2.3.1 组件
- Yarn 3大组件
- 集群物理层面的组件(搭建机器必须要有的)
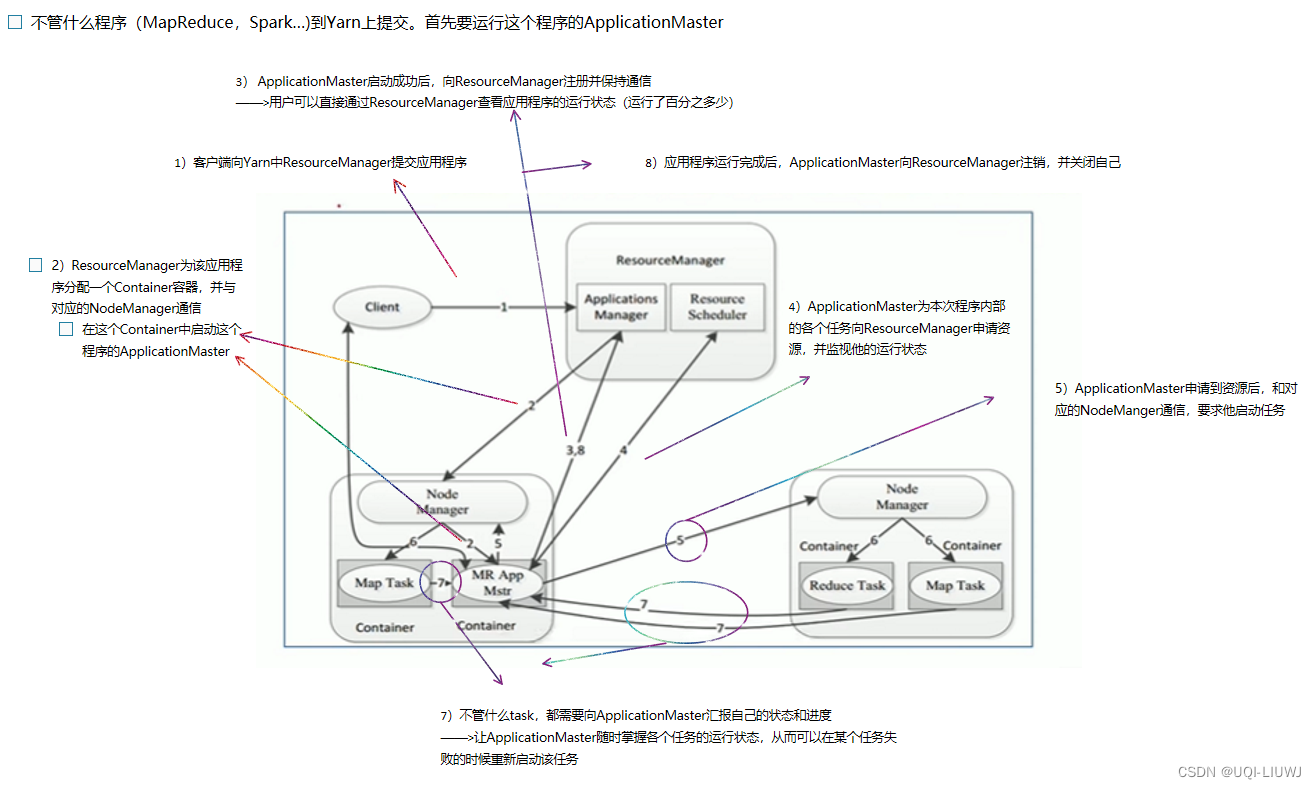
- ResourceManager
- YARN集群的主角色
- 决定系统中所有应用程序之间资源分配的最终权限、
- 接受用户(客户端Cient)的作业提交,通过NodeManager分配,管理各个机器上的计算资源
- NodeManager
- YARN集群的从角色
- 一台机器一个,负责管理本机器上的计算资源
- 根据ResourceManager 的命令,启动Container容器,监视容器的资源使用情况;同时向ResourceManager汇报资源使用情况
- 程序运行完之后:释放容器,回收资源
- ResourceManager
- APP层面的组件
- ApplicationMaster
- 用户(客户端)提交的每一个程序都需要包含一个ApplicationMaster
- 负责程序内部各阶段的资源申请,监督程序的执行情况
- ——>AM进程是任何程序在YARN上运行启动的第一个进程
- ApplicationMaster
- 集群物理层面的组件(搭建机器必须要有的)
- 其他组件
- Client:提交程序,让YARN给分配资源
- Container容器:一台机器上硬件资源的抽象
- 容器之间逻辑上是互相隔离的
- 一个程序运行完之后将容器释放掉
2.3.2 流程
2.3.3 资源调度器Scheduler
- 根据一定的策略为应用程序分配资源
- Hadoop提供三种调度器
- FIFO 先进先出
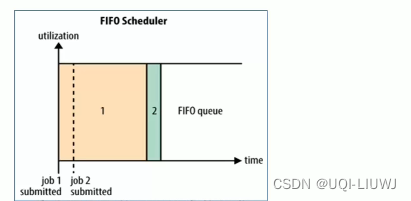
- 劣势:优先级无法调整,高优先级的程序需要等待
- Capacity 容量(默认)
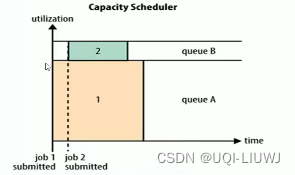
- 集群划分不同的队列
- 队列A专门提交大程度,队列B专门提交小程序
- 如有需要,在队列中继续划分子队列
各个程序提交到指定队列上
- 如有需要,在队列中继续划分子队列
- 队列A专门提交大程度,队列B专门提交小程序
- —》多个组织共享整个集群资源,各获得集群的一部分计算能力,互不干扰
- 缺点:假如当下全都是小程序,那么队列A就会一直空着
- Fair 公平
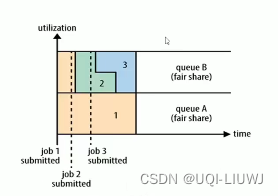
- eg:有两个用户A和B,每个用户都有自己的队列
- 一开始A用户启动一个作业,由于没有B用户的需求,所以A用户分配了集群所有可用的资源
- 过一会儿B用户启动了一个作业,此时A用户的作业还在运行
- ——>经过一段时间的资源分配,A,B各自作业都使用了一半的资源
- 再过一会儿B用户开始了第二个作业,那么B用户的两个作业共享B用户的资源,A用户继续拥有自己的 一半资源
- eg:有两个用户A和B,每个用户都有自己的队列
- FIFO 先进先出

3 Hadoop 集群
- Hadoop集群主要包括两个集群
- HDFS集群
- 分布式存储
- 包含三个组成部分:主角色(NameNode,NN)、从角色(DataNode,DN)、主角色辅助角色(SecondaryNameNode.SNN)【角色是各自独立的进程】
- YARN集群
- 资源管理与调度
- 包括两个组成成分:主角色(ResourceManager,DM)、从角色(NodeManage,NM)【角色是各自独立的进程】
- HDFS集群
- 两个集群都是标准的主从架构
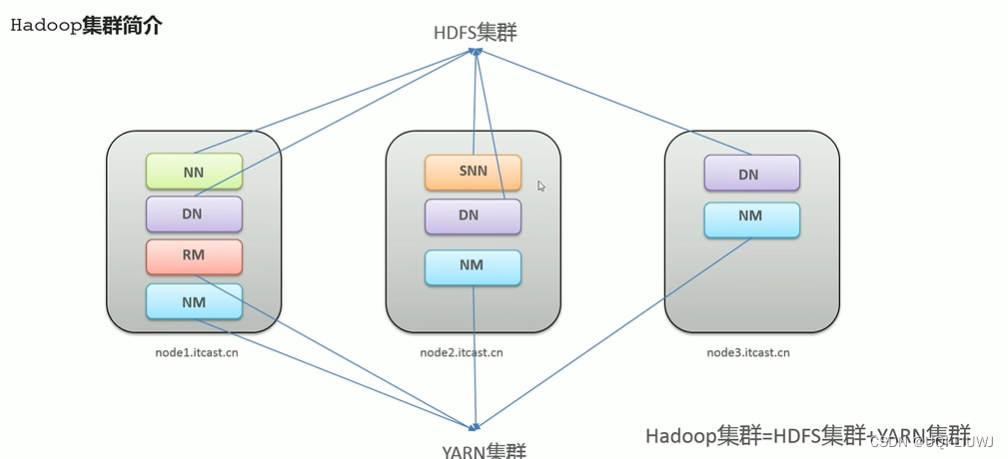
- 两个集群逻辑上分离、物理上在一起
- 逻辑上分离:两个集群之间互相没有依赖、进程互不影响
- 物理上在一起:两个集群的进程都部署在同一台机器上
3.1 HDFS 集群
4 Hadoop 命令
4.1 多种文件系统
- HDFS shell 命令行支持操作多种文件系统
- 本地文件系统:
-
hadoop fs -ls file:///
-
- 分布式操作系统
-
hadoop fs -ls hdfs://node1:8020/
-
- 本地文件系统:
4.2 主要命令
和linux很像
| 创建文件夹 | -p:沿着路径创建父路径 |
| 查看指定目录下内容 | -h 人性化显示 -R 递归查看 |
| 上传文件 | -f 覆盖目标文件(如果已存在) -p 保留访问和修改时间 |
| 查看文件 | 读取指定文件全部内容,显示在标准输出控制台 !!对于大文件内容读取,需要慎重!! |
| 下载文件 | -f 覆盖目标文件(如果已存在) -p 保留访问和修改时间 |
| 拷贝 | -f 覆盖目标文件(如果已存在) |
| 追加数据到HDFS | 这个是linux命令中没有的 将所有给定本地文件的内容追加到给定dst文件(尾部) 如果dst文件不存在,那么创建该文件 如果localsrc为-,那么从标准输入中获取 |
| 数据移动 | |
参考内容:01-课程内容大纲学习目标_哔哩哔哩_bilibili