Text Summarization with Pretrained Encoders(PreSumm模型)
论文地址
摘要
在本文中,我们展示了如何在文本摘要中有效地应用BERT,并为提取性模型和抽象模型提出了一个通用框架。我们介绍了基于BERT的新颖文档级编码器,该编码器能够表达文档的语义并获得其句子的表示形式。我们的提取模型是通过堆叠几个句子之间的 Transformer层来建立在该编码器之上的。对于抽象性摘要,我们提出了一个新的微调计划,该计划对encoder和decoder采用不同的优化器,作为减轻两者之间不匹配的手段(前者经过预训练,后者没有)。我们还证明,两级微调方法可以进一步提高生成的摘要的质量。三个数据集的实验表明,我们的模型在提取和抽象设置中全面达到了状态结果。
介绍
在大多数情况下,预训练的语言模型已被用作句子和段落级的自然语言理解问题的编码器,涉及各种分类任务(例如,预测任何两个句子是否处于综合关系;或确定在四个可选择的句子中完成句子的完成)。在本文中,我们研究了预训练的语言模型对文本摘要的影响。与以前的任务不同,摘要需要广泛覆盖的自然语言理解超出单个单词和句子的含义。目的是将文档浓缩到一个较短的版本中,同时保留其大部分含义。此外,在抽象建模公式下,任务需要语言生成功能,以创建包含源文本中未列出的新颖单词和短语的摘要,而提取性摘要通常定义为带有标签的二进制分类任务句子应包括在摘要中。
本文研究了语言模型预训练对文本摘要的影响。摘要不同于以往的任务,它要求广泛的自然语言理解超出单个单词和句子的意义。其目的是将文档压缩成较短的版本,同时保留其大部分含义。此外,在抽象摘要任务中,该任务需要语言生成能力,以便创建包含源文本中未出现的新单词和短语的摘要。
我们探讨了BERT在包含提取性和抽象建模范式的一般框架下的文本摘要的潜力。我们提出了一个基于BERT的新颖的文档级别水平的编码器,该编码器能够编码文档并获得其句子的表示形式。我们的提取式模型是通过堆叠几个句子间的 Transformer层来捕获用于提取句子的文档级别特征的基础上构建的。我们的抽象式模型采用encoder-decoder架构,将相同的预训练Bert的encoder和随机初始化的Transformers的decoder结合。我们设计了一个新的训练计划,该计划将encoder和decoder的优化器分开,以适应已经预训练的encoder和decoder必须从头开始训练的实际情况。最后,以前的工作表明,提取性和抽象式的结合可以帮助产生更好的摘要,我们提出了一种两阶段的方法,其中encoder进行了两次微调,第一次是提取式目标,然后是抽象性摘要任务。
2.背景
2.1预训练模型
最近,预训练语言模型成为在各种自然语言任务中获得令人印象深刻的成就的关键技术。这些模型扩展了词嵌入的想法,通过使用语言建模目标从大规模语料库中学习上下文表示。BERT是一种新的语言表示模型,该模型经过3300万单词的语料库进行了“掩盖语言建模”和“下一个句子预测”任务的训练。
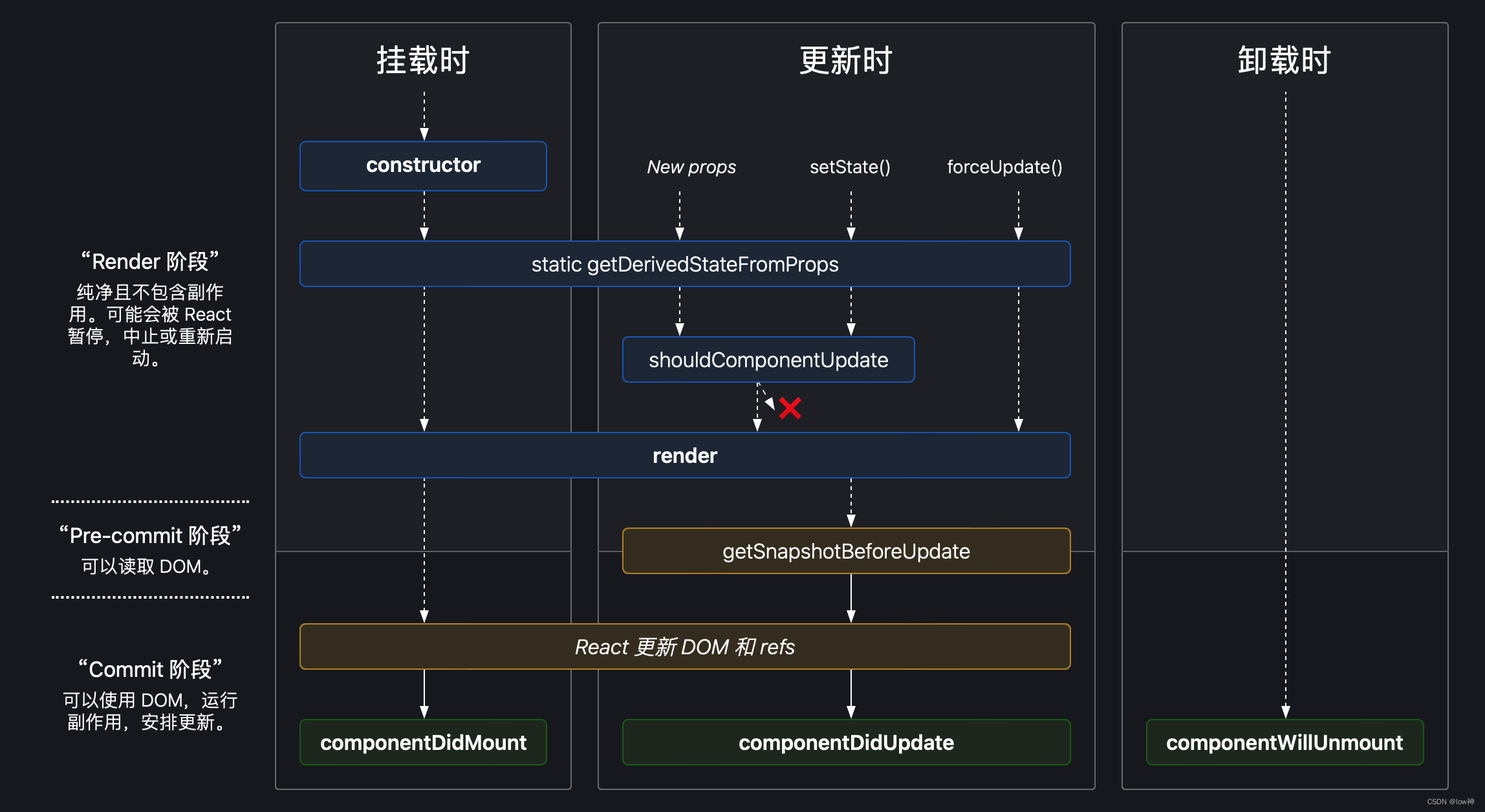
BERT的一般架构如图1左侧所示。
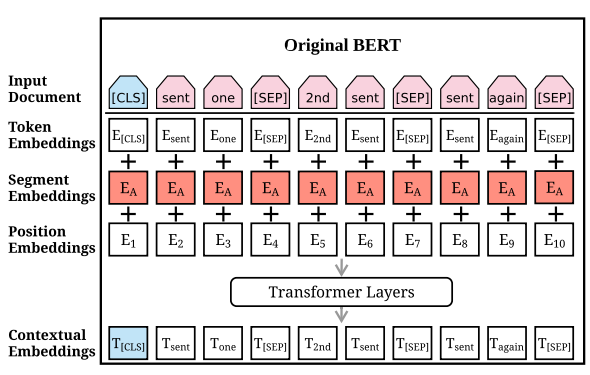
输入文本首先通过插入两个特殊token进行预处理。[CLS]添加到文本的开头;该token的输出表示形式用于从整个序列(例如,用于分类任务)中汇总信息。在每个句子之后,将token[SEP]作为一个句子的边界指标插入。然后,修改后的文本表示为一个token序列
X
=
[
w
1
,
w
2
,
w
3
,
.
.
.
,
w
n
]
X=[w_{1},w_{2},w_{3},...,w_{n}]
X=[w1,w2,w3,...,wn]。每个token
w
i
w_{i}
wi被分配三个种类的Embedding:token Embedding表示每个token的含义,segmentation embedding被用于区分两个句子(例如,在句子对分类任务中),position embedding表明每个token在文本序列中的位置。三个embedding相加,作为一个输入向量
x
i
x_{i}
xi,输入到多层双向Transformer中:
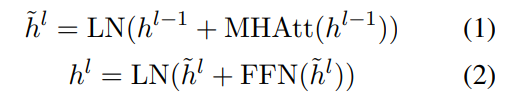
h
0
=
x
h^{0}=x
h0=x是输入向量;LN是层归一化操作;MHAtt是多头注意力操作;上标
l
l
l表示堆叠层的深度。在最顶层,BERT为每一个token产生一个输出向量
t
i
t_{i}
ti,它有着丰富上下文信息。
预训练的语言模型通常用于增强语言理解任务的效果。最近,已经尝试将预训练模型应用于各种生成任务。当对特定任务进行微调时,与通常固定参数的Elmo不同,BERT中的参数与其他特定任务的参数共同参与微调。
2.2提取式摘要
提取性摘要系统通过识别文档中最重要的句子来创建摘要。神经网络模型把提取式摘要作为一个句子分类任务:神经编码器创建句子表示,分类器预测应选择哪些句子作为摘要。SUMMARUNNER是采用基于RNN神经网络编码器的最早神经方法之一。REFRESH是一种基于强化学习的系统,该系统通过全局优化ROUGE指标进行训练。最近的工作通过更复杂的模型结构实现了更高的性能。LATENT框架提取摘要作为一个潜在变量推理问题。它们的潜在模型不是最大化“gold”标准标签的可能性,而是直接使基于被选择的句子的人类摘要的可能性最大化。SUMO利用结构化注意的概念,以促使文档的多根依赖树表示,同时预测输出摘要。NEUSUM同时使用打分和选择句子,代表了提取式摘要的最先进的技术。
2.3抽象式摘要
抽象性摘要的神经方法将任务概念化为序列到序列问题,其中encoder映射原始文档中的token序列 x = [ x 1 , . . . , x n ] x = [x_{1},...,x_{n}] x=[x1,...,xn]到连续表示的序列 z = [ z 1 , . . . , z n ] z = [z_{1},...,z_{n}] z=[z1,...,zn],然后decoder以自回归方式生成目标摘要 y = [ y 1 , . . . , y m ] y=[y_{1},...,y_{m}] y=[y1,...,ym],因此对条件概率进行建模: p ( y 1 , . . . , y m ∣ x 1 , . . . , x n ) p(y_{1},...,y_{m}|x_{1},...,x_{n}) p(y1,...,ym∣x1,...,xn)。
……
3.微调BERT用于摘要
3.1 摘要编码器
尽管BERT已用于微调各种NLP任务,但其用于摘要的应用并不那么简单。由于BERT被作为掩盖语言模型进行训练,因此输出向量直接到token而不是句子,而在提取性摘要中,大多数模型都操纵句子级表示。尽管segmentation embedding 代表BERT中的不同句子,但它们仅适用于 句子对 条件输入,而在摘要任务中,我们必须编码和操纵多个句话输入。图1右侧说明了我们提出的BERT架构以进行摘要。
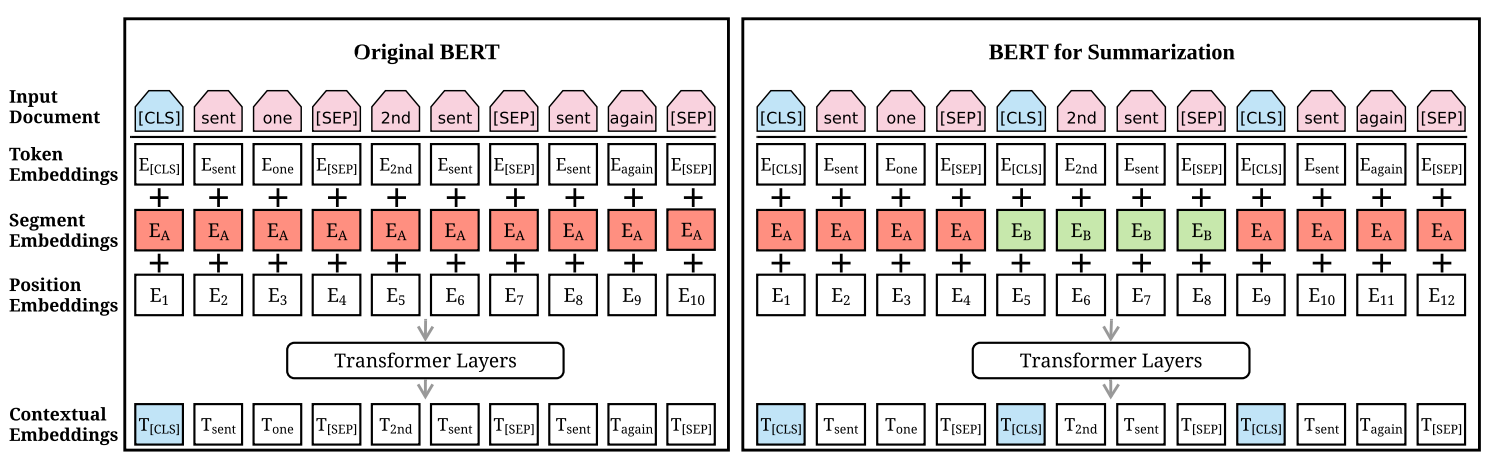
左边是原始BERT架构,右边是BERTSUM架构。顶部的序列是输入文档,然后将三个embedding的和作为每个token。和向量被用于作为几个双向transformer层的输入embedding,生成每个token的上下文向量。BERTSUM扩展了BERT:插入多个[CLS]符号学习句子表示,使用间隔segment embeddings(在图中以红色和绿色说明)来区分多个句子。
为了表示单个句子,我们在每个句子的开头插入 [CLS] Token,每个 [CLS] 符号都会收集该句子之前的句子的特征。我们还使用segment embedding 来区分文档中的多个句子。对每个句子 s e n t i sent_{i} senti,我们根据 i i i是奇数还是偶数来分配segment embedding E A E_{A} EA 或者 E B E_{B} EB。例如,对于一个文档 [ s e n t 1 , s e n t 2 , s e n t 3 , s e n t 4 , s e n t 5 ] [sent_{1},sent_{2},sent_{3},sent_{4},sent_{5}] [sent1,sent2,sent3,sent4,sent5],我们应当分配embeddings [ E A , E B , E A , E B , E A ] [E_{A},E_{B},E_{A},E_{B},E_{A}] [EA,EB,EA,EB,EA]。这样,从层次上学习了文档表示,其中较低的Transformer层代表相邻的句子,而较高的层与自注意力结合使用,代表有多个句子的话语。
原始BERT模型中的位置嵌入最大长度为512;我们通过添加更多的位置嵌入来克服此限制,这些位置嵌入将随机初始化并用编码器中的其他参数进行微调。
3.2 提取式摘要
用 d d d表示一个包含句子 [ s e n t 1 , s e n t 2 , . . . , s e n t m ] [sent_{1},sent_{2},...,sent_{m}] [sent1,sent2,...,sentm]的文档,其中 s e n t i sent_{i} senti是文档中第 i i i个句子。提取性摘要可以定义为将标签 y i y_{i} yi∈{0,1}分配给每个 s e n t i sent_{i} senti的任务,以表明句子是否应包含在摘要中。它假定了摘要句子代表文档中最重要的内容。
使用BERTSUM,向量
t
i
t_{i}
ti是模型最顶层的第
i
i
i个[CLS]符号对应的向量,作为对
s
e
n
t
i
sent_{i}
senti的表示。然后将几个句子间Transformer层堆叠在BERT输出的上面,以捕获用于提取摘要的文档级特征:
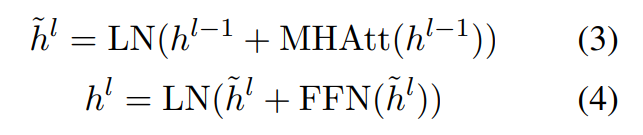
其中,
h
0
=
P
o
s
E
m
b
(
T
)
h^{0}=PosEmb(T)
h0=PosEmb(T);
T
T
T表示BERTSUM的句子向量输出,函数PosEmb将正弦位置嵌入添加到
T
T
T,表明每个句子的位置。
最终的输出层是一个sigmoid分类器:
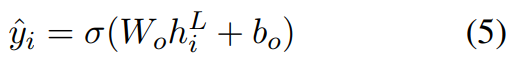
其中
h
i
L
h_{i}^{L}
hiL是第
L
L
L层Transformer的句子
s
e
n
t
i
sent_{i}
senti的向量。在实验中,我们实现了
L
=
1
,
2
,
3
L=1,2,3
L=1,2,3的Transformer,发现
L
=
2
L=2
L=2的Transformer表现最佳。我们把这个模型命名为BERTSUMEXT。
模型的损失是预测
y
i
y_{i}
yi和真实标签
y
i
y_{i}
yi的二分类熵。句间Transformer层和BERTSUM共同微调。我们使用Adam优化器,
β
1
=
0.9
,
β
2
=
0.999
β_{1}=0.9,β_{2}=0.999
β1=0.9,β2=0.999。学习率计划遵循
w
a
r
m
u
p
=
10
,
000
warmup = 10,000
warmup=10,000 ,
l
r
=
2
e
−
3
⋅
m
i
n
(
s
t
e
p
−
0.5
,
s
t
e
p
⋅
w
a
r
m
u
p
−
1.5
)
lr=2e_{-3} · min (step_{-0.5},step · warmup_{-1.5})
lr=2e−3⋅min(step−0.5,step⋅warmup−1.5)
3.3 抽象式摘要
抽象式摘要使用标准的encoder-decoder框架。encoder是预训练的BertSum,decoder是随机初始化的6层Transformer。可以想象,编码器和解码器之间存在不匹配,因为前者经过预训练,而后者必须从头开始训练。这会使微调不稳定;例如,编码器可能在解码器不足时过度拟合数据,反之亦然。为了解决这个问题,我们设计了一个新的微调计划,该计划将编码器和解码器的优化器分开。
我们为编码器和解码器分别使用两个具有
β
1
=
0.9
β_{1}= 0.9
β1=0.9和
β
2
=
0.999
β_{2}= 0.999
β2=0.999的Adam优化器,每个Adam优化器具有不同的热身步骤和学习率:
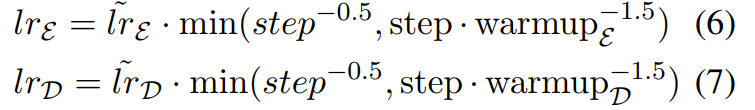
其中encoder的
l
r
ε
=
2
e
−
3
lr_{\varepsilon }=2e^{-3}
lrε=2e−3,
w
a
r
m
u
p
ε
=
20
,
000
warmup_{\varepsilon }=20,000
warmupε=20,000。decoder的
l
r
D
=
0.1
lr_{D }=0.1
lrD=0.1,
w
a
r
m
u
p
D
=
10
,
000
warmup_{D }=10,000
warmupD=10,000。这是基于以下假设:预训练的encoder应以较小的学习率和更平滑的衰减进行微调(以便在decoder变得稳定时可以用更准确的梯度训练encoder)。
此外,我们提出了一种两阶段的微调方法,在该方法中,我们首先在提取性摘要任务(第3.2节)中对编码器进行微调,然后在抽象性摘要任务(第3.3节)中对其进行微调。先前的工作表明,使用提取式可以提高抽象式摘要的性能。还要注意,这种两阶段的方法在概念上非常简单,该模型可以利用这两个任务之间共享的信息,而无需改变其体系结构。我们把默认的抽象式模型命名为BertSumABS,两阶段微调的模型命名为BertSumEXTABS。











![【群智能算法改进】一种改进的蝴蝶优化算法 改进蝴蝶优化算法 改进BOA[1]【Matlab代码#35】](https://img-blog.csdnimg.cn/8ba49ef24ec74927804e9927ffac56e4.png#pic_center)