目录
1 主要内容
聚类中心选取步骤
核方法
2 部分代码
3 程序结果
4 程序链接
1 主要内容
程序复现文献《基于机器学习的短期电力负荷预测和负荷曲线聚类研究》第三章《基于改进ISODATA算法的负荷场景曲线聚类》模型,该方法不止适用于负荷聚类,同样适用于风光等可再生能源聚类,只需要改变聚类的数据即可,该方法的通用性和可创新性强。
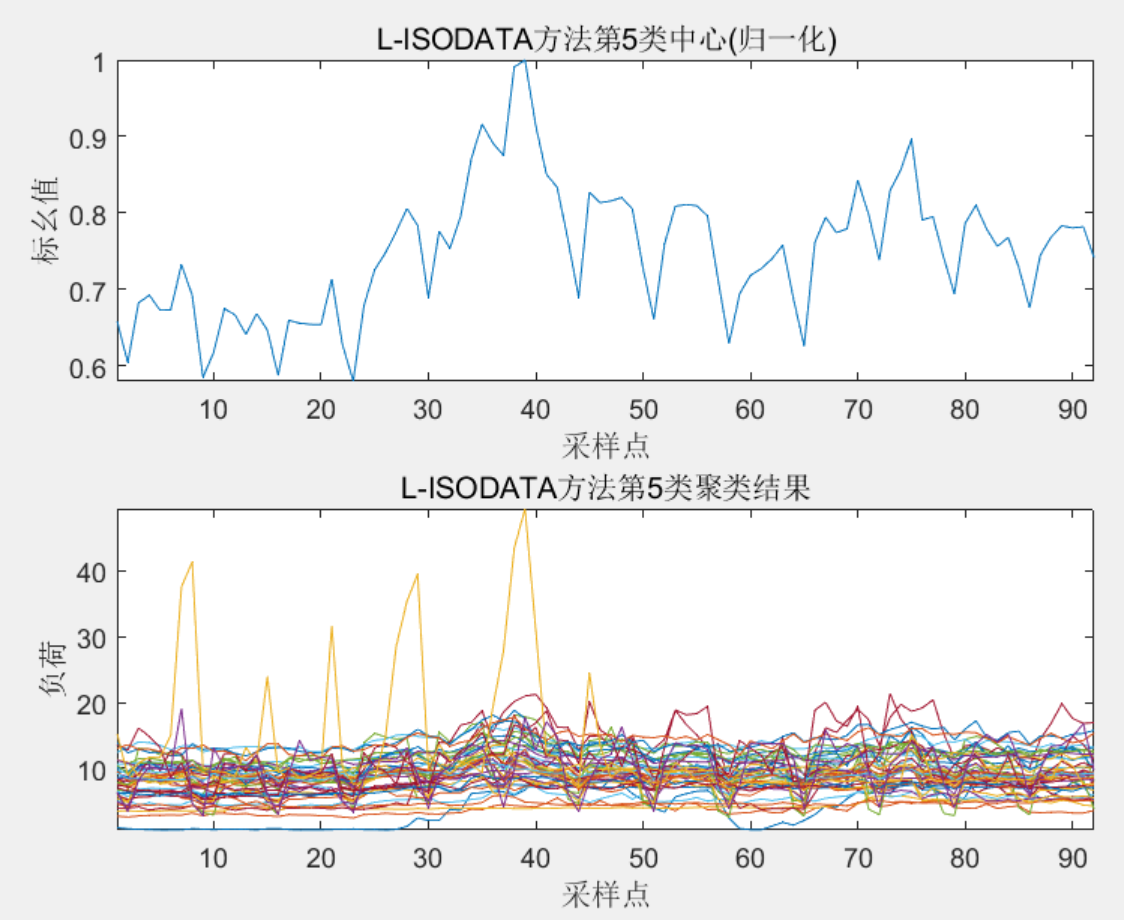
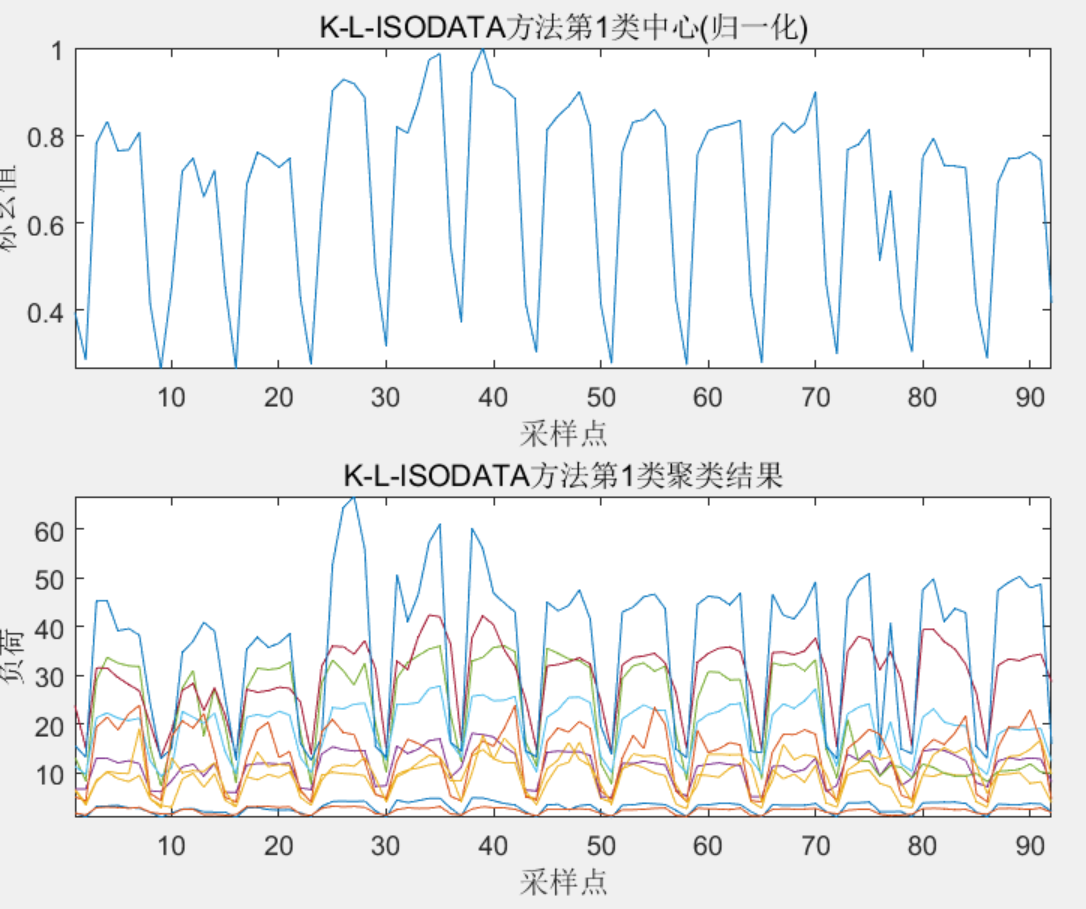
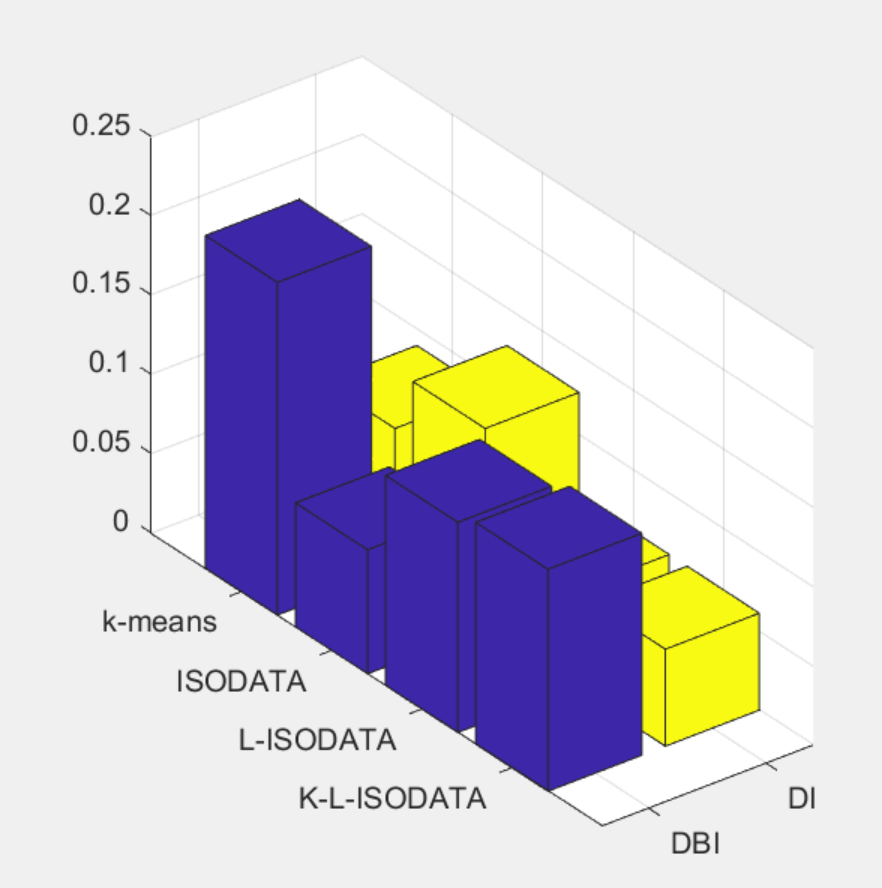
该代码实现一种基于改进ISODATA算法的负荷场景曲线聚类方法,代码中,主要做了四种聚类算法,包括基础的K-means算法、ISODATA算法、L-ISODATA算法以及K-L-ISODATA算法,并且包含了对聚类场景以及聚类效果的评价,通过DBI的计算值综合对比评价不同方法的聚类效果,程序将四种方法均进行了实现,非常方便大家对照学习!

-
聚类中心选取步骤


-
核方法

2 部分代码
data_load=xlsread('日平均负荷.xls');
x=data_load;
k_num=0;k_num1=0;
%% 初始化
km=6;K=6;Kl=6;K3=6;%定义预期的聚类中心数
theta_N=1;% theta_N : 每一聚类中心中最少的样本数,少于此数就不作为一个独立的聚类
theta_S=1;% theta_S :一个聚类中样本距离分布的标准差
theta_c=3;% theta_c : 两聚类中心之间的最小距离,如小于此数,两个聚类进行合并
L=1;% L : 在一次迭代运算中可以和并的聚类中心的最多对数
%% K=means 方法聚类结果
[IDW,CW,sumdw,DW] = kmeans(x,km);
Clust = cell(km,1);
for i=1:km
CW1{i,1}=CW(i,:);
end
for i=1:km
clustw1=find(IDW==i);
Clust{i} = x(clustw1,:);
end
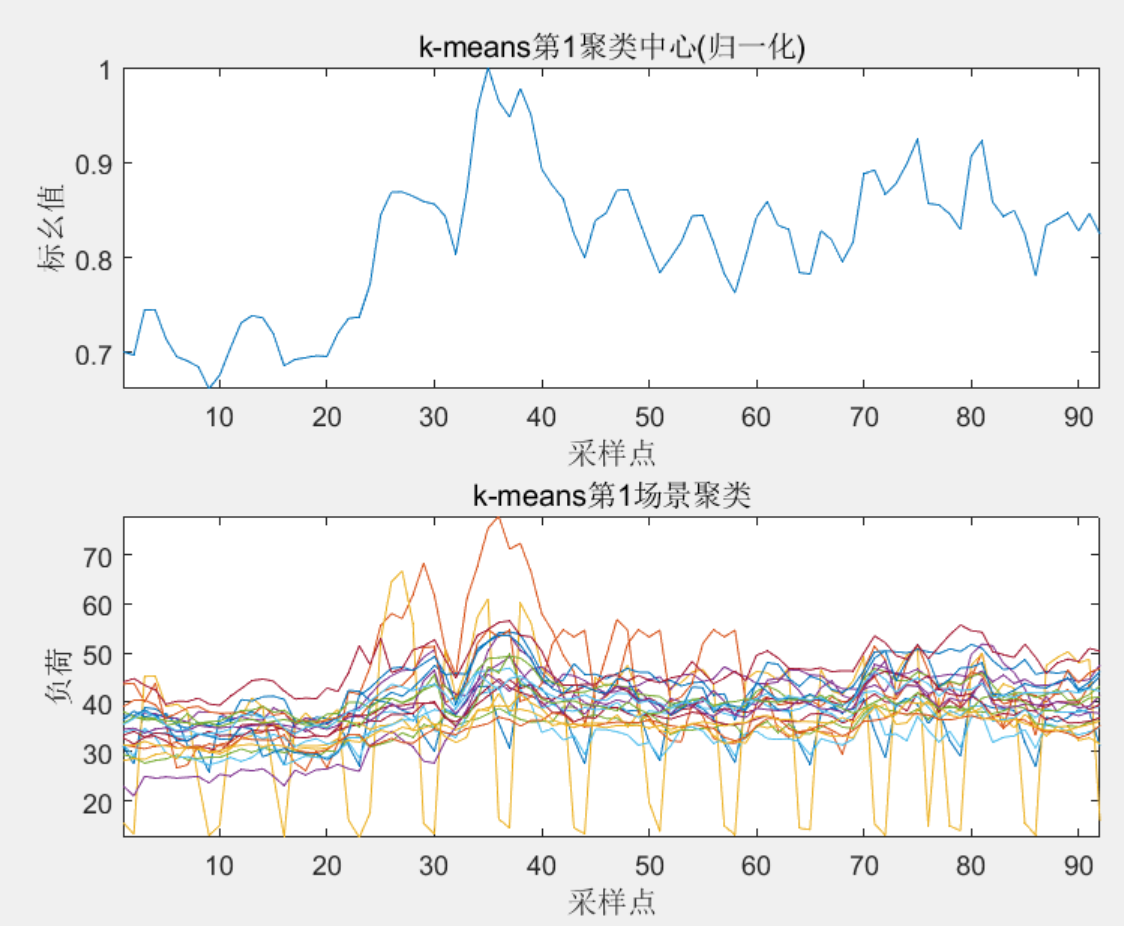
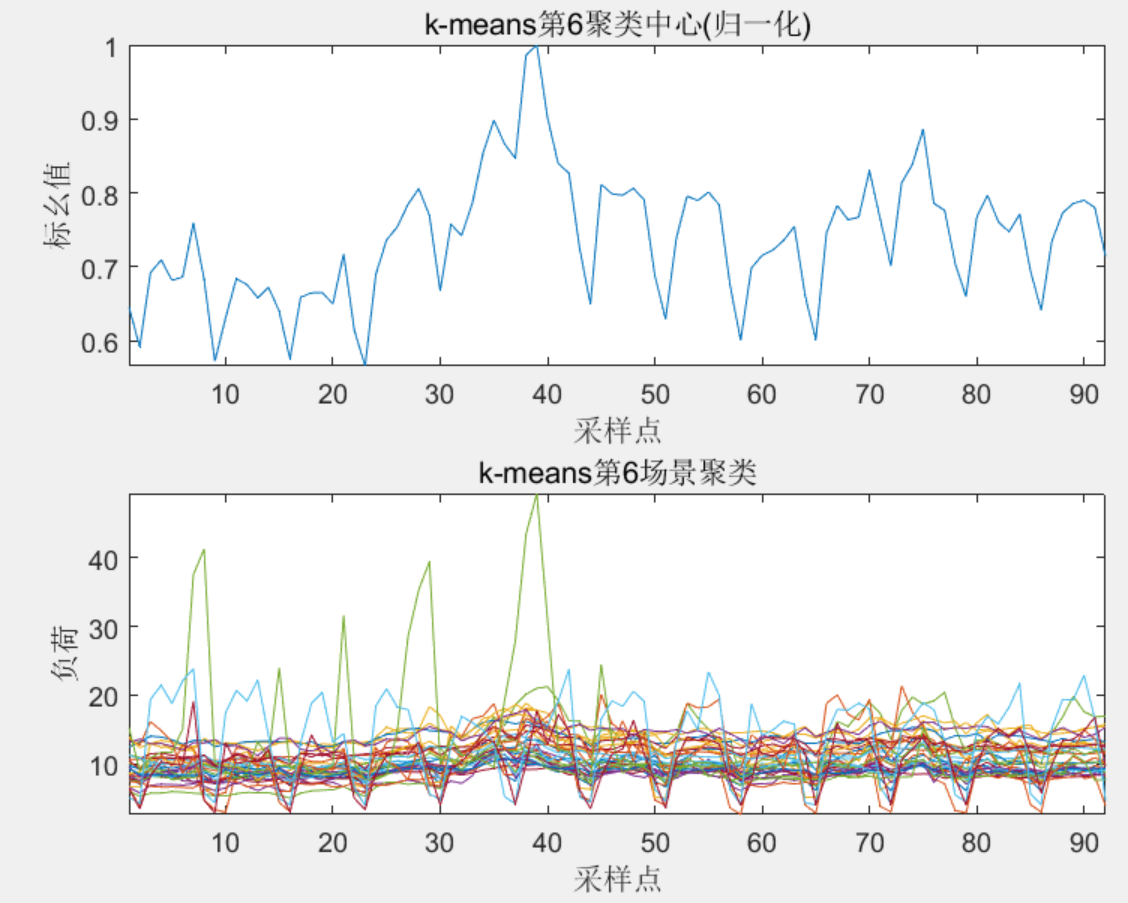
%% K-means 聚类结果图
for i=1:km
figure
subplot(2,1,1);
plot(CW(i,:)/(max(CW(i,:))),'-');xlabel('采样点');ylabel('标幺值');axis([1 92 -inf inf])
titlemane=strcat('k-means第',num2str(i),'聚类中心(归一化)');
title(titlemane)
subplot(2,1,2);
cu=Clust{i};
plot(cu','-');xlabel('采样点');ylabel('负荷');axis([1 92 -inf inf])
titlemane=strcat('k-means第',num2str(i),'场景聚类');
title(titlemane)
end
%% ISODATA聚类方法
[AA,BB]=ISODATA(x,K,theta_N,theta_S,theta_c,L);
for i=1:K
if size(AA{i},2)==1
k_num1=k_num1+1;
AA{i,1}=[];
BB{i,1}=[];
end
end
AA(cellfun(@isempty,AA))=[];
BB(cellfun(@isempty,BB))=[];
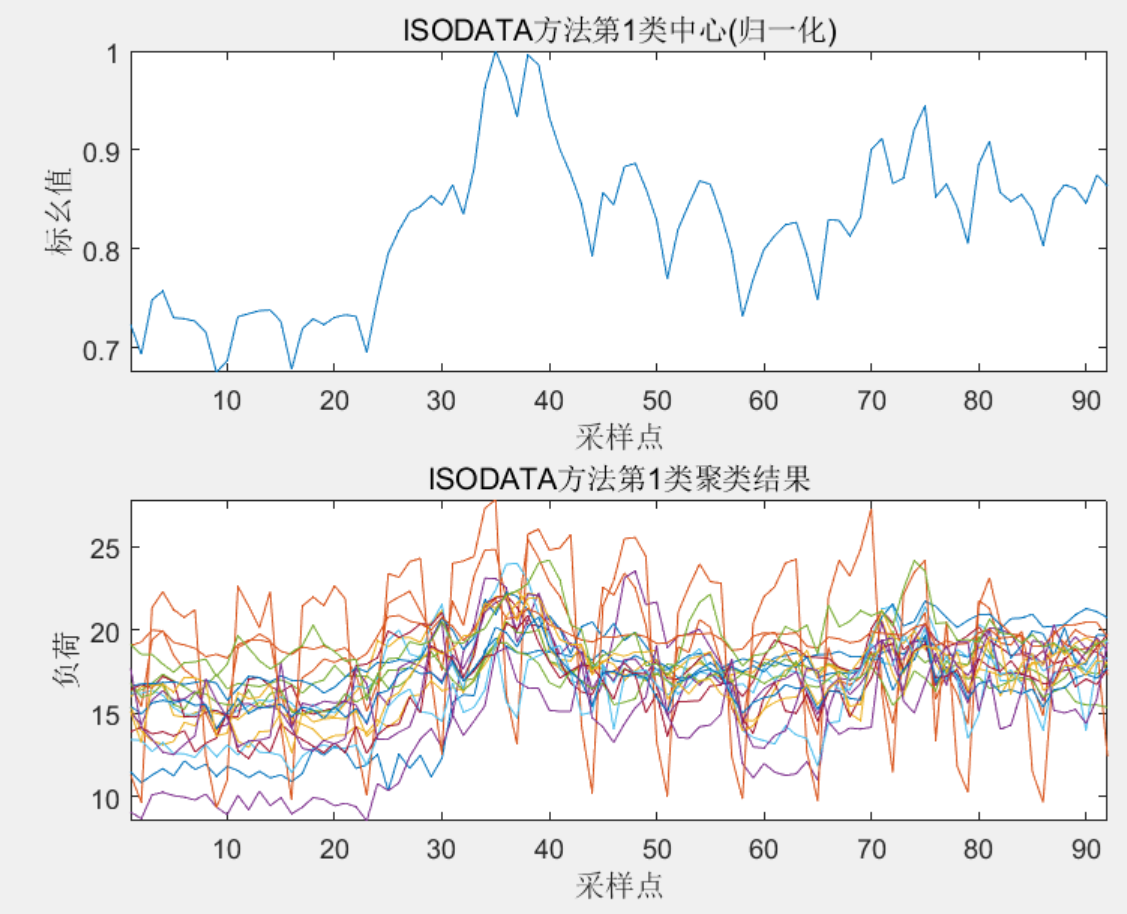
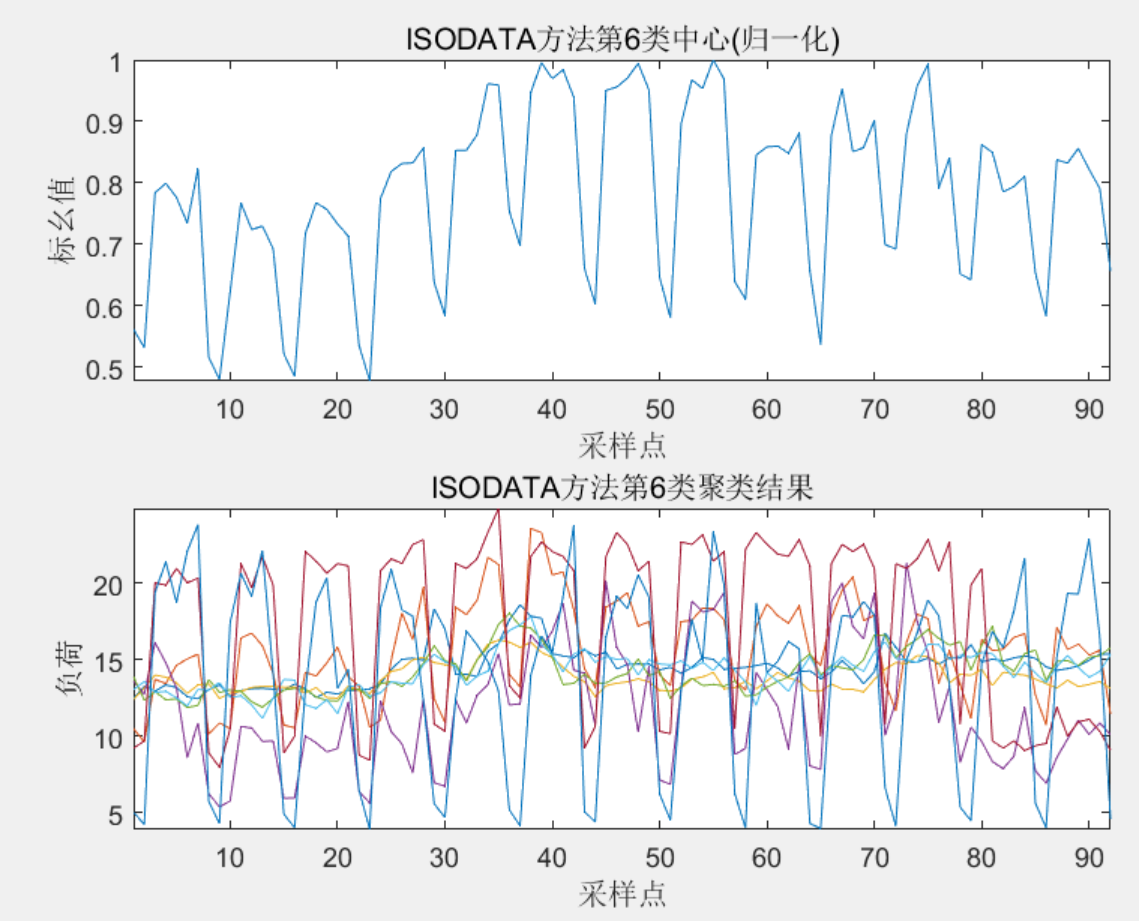
%% ISODATA 聚类结果图
for i=1:K
figure
subplot(2,1,1)
plot(AA{i}/max(AA{i}));xlabel('采样点');ylabel('标幺值');axis([1 92 -inf inf])
titlemane=strcat('ISODATA方法第',num2str(i),'类中心(归一化)');
title(titlemane)
subplot(2,1,2)
cla=BB{i};
plot(cla','-');xlabel('采样点');ylabel('负荷');axis([1 92 -inf inf])
titlemane2=strcat('ISODATA方法第',num2str(i),'类聚类结果');
title(titlemane2)
end
3 程序结果
4 程序链接
点击直达!