文章目录
- Vision transformer
- Swin transformer
- Convolutional vision Transformer
Vision transformer
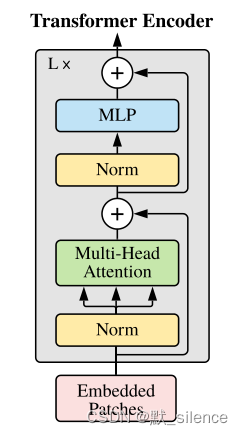
假设每个图像有 h ∗ w h*w h∗w 个patch,维度是 C C C
输入的图像
X
X
X ( 大小为
h
w
∗
C
hw* C
hw∗C ),和三个系数矩阵相乘 ( 大小为
C
∗
C
C*C
C∗C ),得到
q
k
v
qkv
qkv 三个向量 (
h
w
∗
C
hw*C
hw∗C ),复杂度为:
3
h
w
C
2
3hwC^2
3hwC2
q q q ( h w ∗ C hw*C hw∗C ) 和 k k k ( C ∗ h w C*hw C∗hw ) 相乘得到矩阵 A A A ( h w ∗ h w hw*hw hw∗hw ),复杂度为: ( h w ) 2 C (hw)^2C (hw)2C
A A A ( h w ∗ h w hw*hw hw∗hw ) 和 v v v ( h w ∗ C hw*C hw∗C )相乘,得到多头注意力的结果 ( h w ∗ C hw*C hw∗C ),复杂度为: ( h w ) 2 C (hw)^2C (hw)2C
经过MLP投影层 (
C
∗
C
C*C
C∗C ),得到 (
h
w
∗
C
hw*C
hw∗C ),复杂度为:
h
w
C
2
hwC^2
hwC2
所以复杂度之和为: 4 h w C 2 + 2 ( h w ) 2 C 4hwC^2 + 2(hw)^2C 4hwC2+2(hw)2C
Swin transformer

基于滑动窗口的多头注意力,是在每个窗口内计算注意力
假设每个窗口有 M × M M×M M×M 个patch
在一个窗口内的复杂度为:
4 M 2 ∗ C + 2 M 4 C 4M^2*C+2M^4C 4M2∗C+2M4C
共有 h w / M 2 hw /M^2 hw/M2 个窗口,所以复杂度之和为:
4 h w C + 2 M 2 h w C 4hwC+2M^2hwC 4hwC+2M2hwC
Convolutional vision Transformer
使用 s × s s×s s×s 卷积进行卷积投影,有 h w hw hw 个patch,通道维度为 C C C
输入的图像 X X X ( 大小为 h w ∗ C hw* C hw∗C ),使用三个标准卷积进行投影 ( 大小为 s ∗ s ∗ C s*s*C s∗s∗C ),得到 q k v qkv qkv 三个向量 ( h w ∗ C hw*C hw∗C ),投影的复杂度为:
3 h w s 2 C 2 3hws^2C^2 3hws2C2
使用深度可分离卷积,投影的复杂度为:
3 h w s 2 C 3hws^2C 3hws2C
使用步长大于1的卷积进行多头注意力的投影,减小后面注意力的计算花销。
key和value的步长为2,query的步长为1,key和value的token数量减小了4倍,所以后续的多头注意力计算花销也减小了4倍。