1. 计算用户8月每天的练题数量
题目:现在运营想要计算出2021年8月每天用户练习题目的数量,请取出相应数据。
示例:question_practice_detail
| id | device_id | question_id | result | date |
|---|---|---|---|---|
| 1 | 2138 | 111 | wrong | 2021-05-03 |
| 2 | 3214 | 112 | wrong | 2021-05-09 |
| 3 | 3214 | 113 | wrong | 2021-06-15 |
| 4 | 6543 | 111 | right | 2021-08-13 |
| 5 | 2315 | 115 | right | 2021-08-13 |
| 6 | 2315 | 116 | right | 2021-08-14 |
| 7 | 2315 | 117 | wrong | 2021-08-15 |
| …… |
根据示例,你的查询应返回以下结果:
| day | question_cnt |
|---|---|
| 13 | 5 |
| 14 | 2 |
| 15 | 3 |
| 16 | 1 |
| 18 | 1 |
#法一:like运算符
select
day(date) as day,
count(question_id) as question_cnt
from question_practice_detail
where date like '2021-08%'
group by day(date);
#法二:substring提取日期
select
day(date) as day,
count(question_id) as question_cnt
from question_practice_detail
where substring(date,1,7) = '2021-08'
group by day(date);
2. 计算用户的平均次日留存率
题目:现在运营想要查看用户在某天刷题后第二天还会再来刷题的平均概率。请你取出相应数据。
示例:question_practice_detail
| id | device_id | quest_id | result | date |
|---|---|---|---|---|
| 1 | 2138 | 111 | wrong | 2021-05-03 |
| 2 | 3214 | 112 | wrong | 2021-05-09 |
| 3 | 3214 | 113 | wrong | 2021-06-15 |
| 4 | 6543 | 111 | right | 2021-08-13 |
| 5 | 2315 | 115 | right | 2021-08-13 |
| 6 | 2315 | 116 | right | 2021-08-14 |
| 7 | 2315 | 117 | wrong | 2021-08-15 |
| …… |
根据示例,你的查询应返回以下结果:
| avg_ret |
|---|
| 0.3000 |
题目分析:
所谓次日留存,指的是同一用户(在本题中则为同一设备,即device_id)在当天和第二天都进行刷题。注意,在这题我们不关心同一用户(设备)在这天答了什么题、答题结果如何,只关心他是否答题,因此对于这题来说存在重复的数据(如下图红框所示),需要使用 DISTINCT 去重。 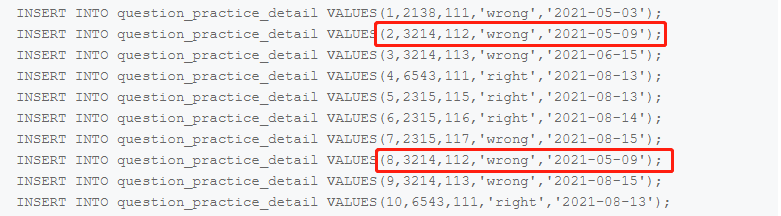
而次日留存率可以这样表示:

具体而言,使用两个子查询,查询出两个去重的数据表,并使用条件(q2.date应该是q1.date的后一天)进行筛选,如下所示(数据未显示完全,从左至右顺序,列表名为 q1.device_id, q1.date, q2.device_id, q2.date)
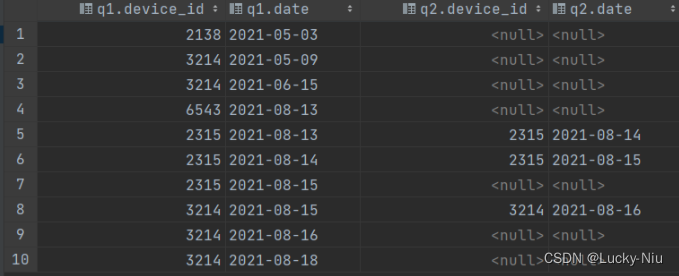
因为使用的是q1左级联q2,所以q1的所有信息是显示的;而q2中只显示留存的信息,否则为null。
最后,分别统计q1.device_id 和 q2.device_id 作去重后的所有条目数和去重后的次日留存条目数,即可算出次日留存率。
SELECT
COUNT(q2.device_id) / COUNT(q1.device_id) AS avg_ret
FROM
(SELECT DISTINCT device_id, date FROM question_practice_detail)as q1
LEFT JOIN
(SELECT DISTINCT device_id, date FROM question_practice_detail) AS q2
ON q1.device_id = q2.device_id AND q2.date = DATE_ADD(q1.date, interval 1 day)
# DATE_ADD(q1.date, interval expr type):返回一个日期/时间值加上一个时间间隔expr后的时间值
# DATEDIFF(date1, date2):返回起始时间date1和结束时间date2之间的天数
3. 找出每个学校GPA最低的同学
题目:现在运营想要找到每个学校gpa最低的同学来做调研,请你取出每个学校的最低gpa。
示例:user_profile
| id | device_id | gender | age | university | gpa | active_days_within_30 | question_cnt | answer_cnt |
|---|---|---|---|---|---|---|---|---|
| 1 | 2138 | male | 21 | 北京大学 | 3.4 | 7 | 2 | 12 |
| 2 | 3214 | male | 复旦大学 | 4 | 15 | 5 | 25 | |
| 3 | 6543 | female | 20 | 北京大学 | 3.2 | 12 | 3 | 30 |
| 4 | 2315 | female | 23 | 浙江大学 | 3.6 | 5 | 1 | 2 |
| 5 | 5432 | male | 25 | 山东大学 | 3.8 | 20 | 15 | 70 |
| 6 | 2131 | male | 28 | 山东大学 | 3.3 | 15 | 7 | 13 |
| 7 | 4321 | female | 26 | 复旦大学 | 3.6 | 9 | 6 | 52 |
根据示例,你的查询结果应参考以下格式,输出结果按university升序排序:
| device_id | university | gpa |
|---|---|---|
| 6543 | 北京大学 | 3.2000 |
| 4321 | 复旦大学 | 3.6000 |
| 2131 | 山东大学 | 3.3000 |
| 2315 | 浙江大学 | 3.6000 |
#法一
select
u.device_id,
u.university,
u.gpa
from
user_profile u
#先查出每个学校最低的gpa
join (select university ,min(gpa) gpa from user_profile u group by university) a
on u.university = a.university and u.gpa = a.gpa
order by university;
#法二
select
device_id,university,gpa
from
user_profile
where
#直接条件判断
(university,gpa) in (select university,min(gpa) from user_profile group by university)
order by university;