最近刚刚接触Python,安装了Anaconda, 编程小白一个,照着教程准备做一个中考成绩录取分数线分析的案例, 使用read_excel()读入数据后,
import pandas as pd
data =pd.read_excel(r'C:\2021-2022深圳中考录取分数线(1).xlsx',header=[0,1])
data
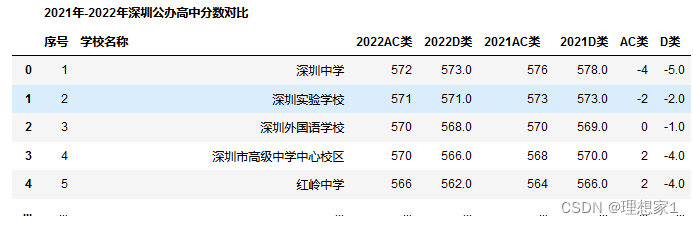
数据读取到了,表头内容占据两行
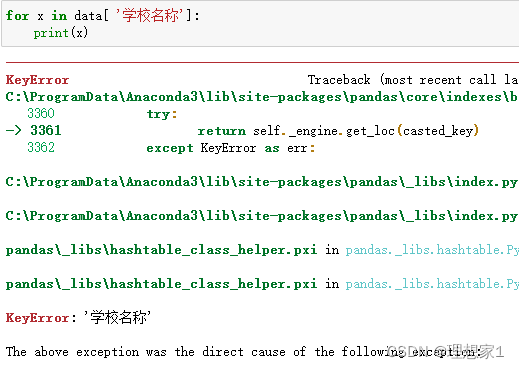
如果想要取某列数据,使用单个表头,是会报错的
for x in data[ '学校名称']:
print(x)
正确的做法是
for x in data['2021年-2022年深圳公办高中分数对比', '学校名称']:
print(x)

具体查看各个列名称,可以使用这个命令
print(data.columns.values)
这个问题应该是很简单的小白问题,我自己不会,简单记录下








![[论文评析]mixup: B EYOND E MPIRICAL R ISK M INIMIZATION, ICLR 2018,](https://img-blog.csdnimg.cn/2263dee926184499bb67522704475276.png#pic_center)