近年来,随着深度学习技术的发展,向量搜索引发了人们的广泛关注。早在 Elasticsearch在7.2.0 版本引入了dense_vector字段类型,支持存储高维向量数据,如词嵌入或文档嵌入,以进行相似度搜索等操作。在本文中,我将展示如何在Elasticsearch 8.X 版本中使用 dense_vector 进行向量搜索。
一、背景介绍
首先,我们需要了解一下dense_vector。dense_vector是Elasticsearch用于存储高维向量的字段类型,通常用于神经搜索,以便利用NLP和深度学习模型生成的嵌入来搜索相似文本。你可以在这个链接找到更多关于dense_vector的信息。
在接下来的部分,我将展示如何创建一个简单的Elasticsearch索引,该索引包含基于文本嵌入的向量搜索功能。
二、生成向量:利用Python处理
首先,我们需要用Python和BERT模型来生成文本嵌入。以下是我们如何做到这一点的示例:
import torch
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
model = BertModel.from_pretrained("bert-base-uncased")
def get_bert_embedding(text):
inputs = tokenizer(text, return_tensors="pt", max_length=128, truncation=True, padding="max_length")
with torch.no_grad():
outputs = model(**inputs)
return outputs.last_hidden_state[:, :3, :].numpy()
def print_infos():
docs = ["占地100亩的烧烤城在淄博仅用20天即成功新建,现在已成为万人争抢“烤位”的热门去处。",
"淄博新建的一座占地100亩的烧烤城在短短20天内建成,吸引了众多烧烤爱好者,如今“烤位”已是一位难求。",
"在淄博,一座耗时20天新建的占地100亩的烧烤城成为众人瞩目的焦点,各种美味烧烤让万人争夺“烤位”,可谓一座难求。",
"淄博一般指淄博市。 淄博市,简称“淄”,齐国故都,山东省辖地级市,Ⅱ型大城市"]
for doc in docs:
print( f"Vector for '{doc}':", get_bert_embedding( doc ) )
if __name__ == '__main__':
print_infos()在上述脚本中,我们定义了一个函数 get_bert_embedding 来生成每个文档的向量表示。然后,我们生成了四个不同的文档向量,并将其输出打印到控制台。如下图所示:
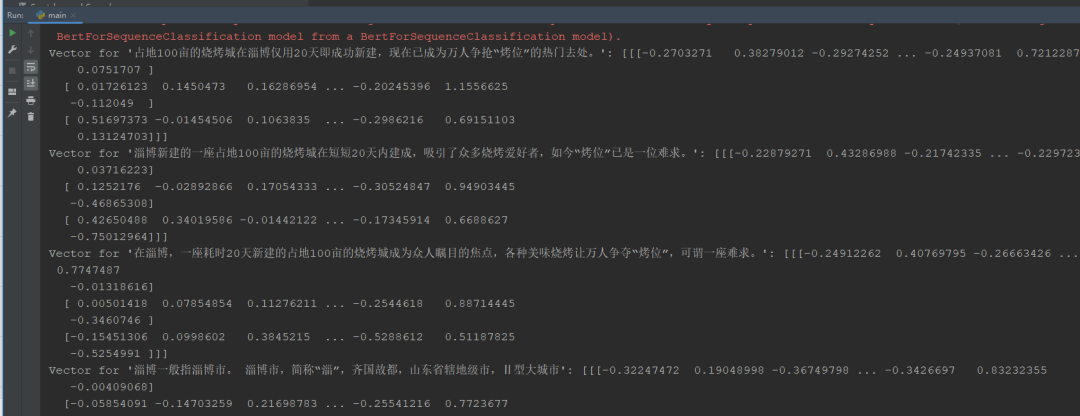
结果参考:
Vector for '占地100亩的烧烤城在淄博仅用20天即成功新建,现在已成为万人争抢“烤位”的热门去处。': [[[-0.2703271 0.38279012 -0.29274252 ... -0.24937081 0.7212287
0.0751707 ]
[ 0.01726123 0.1450473 0.16286954 ... -0.20245396 1.1556625
-0.112049 ]
[ 0.51697373 -0.01454506 0.1063835 ... -0.2986216 0.69151103
0.13124703]]]
Vector for '淄博新建的一座占地100亩的烧烤城在短短20天内建成,吸引了众多烧烤爱好者,如今“烤位”已是一位难求。': [[[-0.22879271 0.43286988 -0.21742335 ... -0.22972387 0.75263715
0.03716223]
[ 0.1252176 -0.02892866 0.17054333 ... -0.30524847 0.94903445
-0.46865308]
[ 0.42650488 0.34019586 -0.01442122 ... -0.17345914 0.6688627
-0.75012964]]]三、实战探索:向Elasticsearch中导入和搜索向量
3.1 创建索引
我们首先需要在Elasticsearch中创建一个新的索引来存储我们的文档和它们的向量表示。以下是创建索引的API调用:
PUT /my_vector_index
{
"mappings": {
"properties": {
"title": {
"type": "text"
},
"content_vector": {
"type": "dense_vector",
"dims": 3
}
}
}
}在上述代码中,我们创建了一个名为 my_vector_index 的索引,并定义了两个字段:title 和 content_vector。其中,content_vector 字段的类型被设置为 dense_vector,并指定其维度为3,这与我们前面生成的BERT向量维度一致。
3.2 导入数据
接下来,我们可以将我们的文档及其相应的向量导入到索引中。以下是一个示例的批量导入API调用:
POST my_vector_index/_bulk
{"index":{"_id":1}}
{"title":"占地100亩的烧烤城在淄博仅用20天即成功新建,现在已成为万人争抢“烤位”的热门去处。","content_vector":[-0.2703271, 0.38279012, -0.29274252]}
{"index":{"_id":2}}
{"title":"淄博新建的一座占地100亩的烧烤城在短短20天内建成,吸引了众多烧烤爱好者,如今“烤位”已是一位难求。","content_vector":[-0.22879271, 0.43286988, -0.21742335]}
{"index":{"_id":3}}
{"title":"在淄博,一座耗时20天新建的占地100亩的烧烤城成为众人瞩目的焦点,各种美味烧烤让万人争夺“烤位”,可谓一座难求。","content_vector":[-0.24912262, 0.40769795, -0.26663426]}
{"index":{"_id":4}}
{"title":"淄博一般指淄博市。 淄博市,简称“淄”,齐国故都,山东省辖地级市,Ⅱ型大城市","content_vector":["0.32247472, 0.19048998, -0.36749798]}在这个例子中,我们使用了Elasticsearch的_bulk 接口批量导入数据。每个文档的数据由两行组成:一行包含文档的ID,另一行包含文档的标题和内容向量。注意向量的值与我们在Python代码中生成的值是相同的。
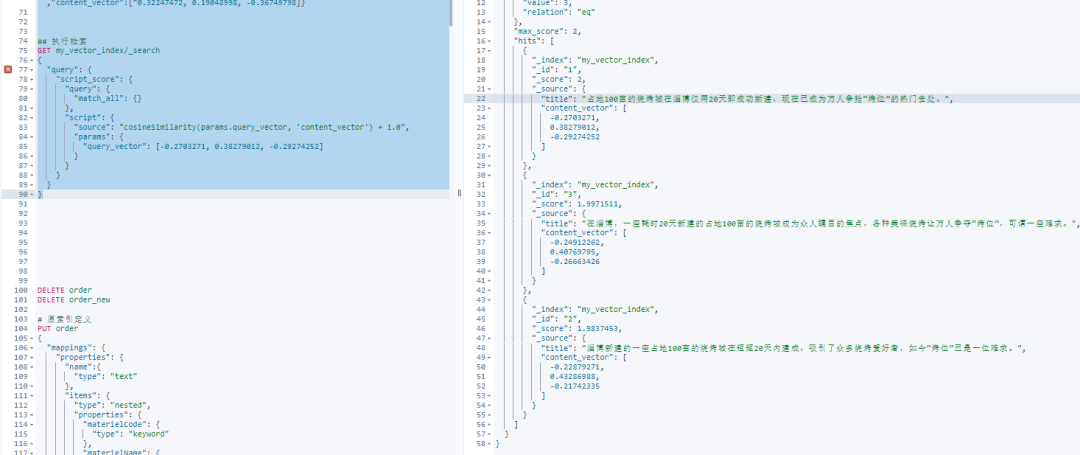
3.3 执行检索
创建并导入数据后,我们可以执行一次相似性检索。我们将使用脚本评分查询,其中我们的评分脚本将计算查询向量与每个文档的内容向量之间的余弦相似度。
以下是一个API调用的例子:
GET my_vector_index/_search
{
"query": {
"script_score": {
"query": {
"match_all": {}
},
"script": {
"source": "cosineSimilarity(params.query_vector, 'content_vector') + 1.0",
"params": {
"query_vector": [-0.2703271, 0.38279012, -0.29274252]
}
}
}
}
}在上述查询中,我们定义了一个脚本评分查询script_score。该查询首先执行一个匹配所有文档的查询(match_all),然后根据我们的脚本对每个文档进行评分。
评分脚本cosineSimilarity(params.query_vector, 'content_vector') + 1.0计算查询向量和每个文档的content_vector字段之间的余弦相似度,并将结果加1(因为余弦相似度的范围是-1到1,而Elasticsearch的评分必须是非负的)。
我们拿文档1的向量作为检索条件,执行结果如下:
四、结语
基于向量的搜索方法正在不断发展,Elasticsearch也在不断改进和扩展其功能以跟上这一趋势。
为了充分利用Elasticsearch的能力,请确保关注其官方文档和更新,以便了解最新的功能和最佳实践。使用dense_vector字段和相关的搜索方法,我们可以在Elasticsearch中实现复杂的向量搜索,为用户提供更精确和个性化的搜索体验。
推荐阅读
全网首发!从 0 到 1 Elasticsearch 8.X 通关视频
重磅 | 死磕 Elasticsearch 8.X 方法论认知清单
如何系统的学习 Elasticsearch ?
2023,做点事
Elasticsearch:普通检索和向量检索的异同?
干货 | Elasticsearch 向量搜索的工程化实战

更短时间更快习得更多干货!
和全球 近2000+ Elastic 爱好者一起精进!

大模型时代,抢先一步学习进阶干货!

![深度学习基础入门篇[9.3]:卷积算子:空洞卷积、分组卷积、可分离卷积、可变性卷积等详细讲解以及应用场景和应用实例剖析](https://img-blog.csdnimg.cn/img_convert/8458852e6b0157f98825fde38279e3c2.png)