访问【WRITE-BUG数字空间】_[内附完整源码和文档]
原始串行快速排序算法中有“分而治之”的递归调用部分,在每次选择pivoit并把序列按照小于pivoIt和大于pivoit分成两类后,左右两部分的递归排序可以并发执行。
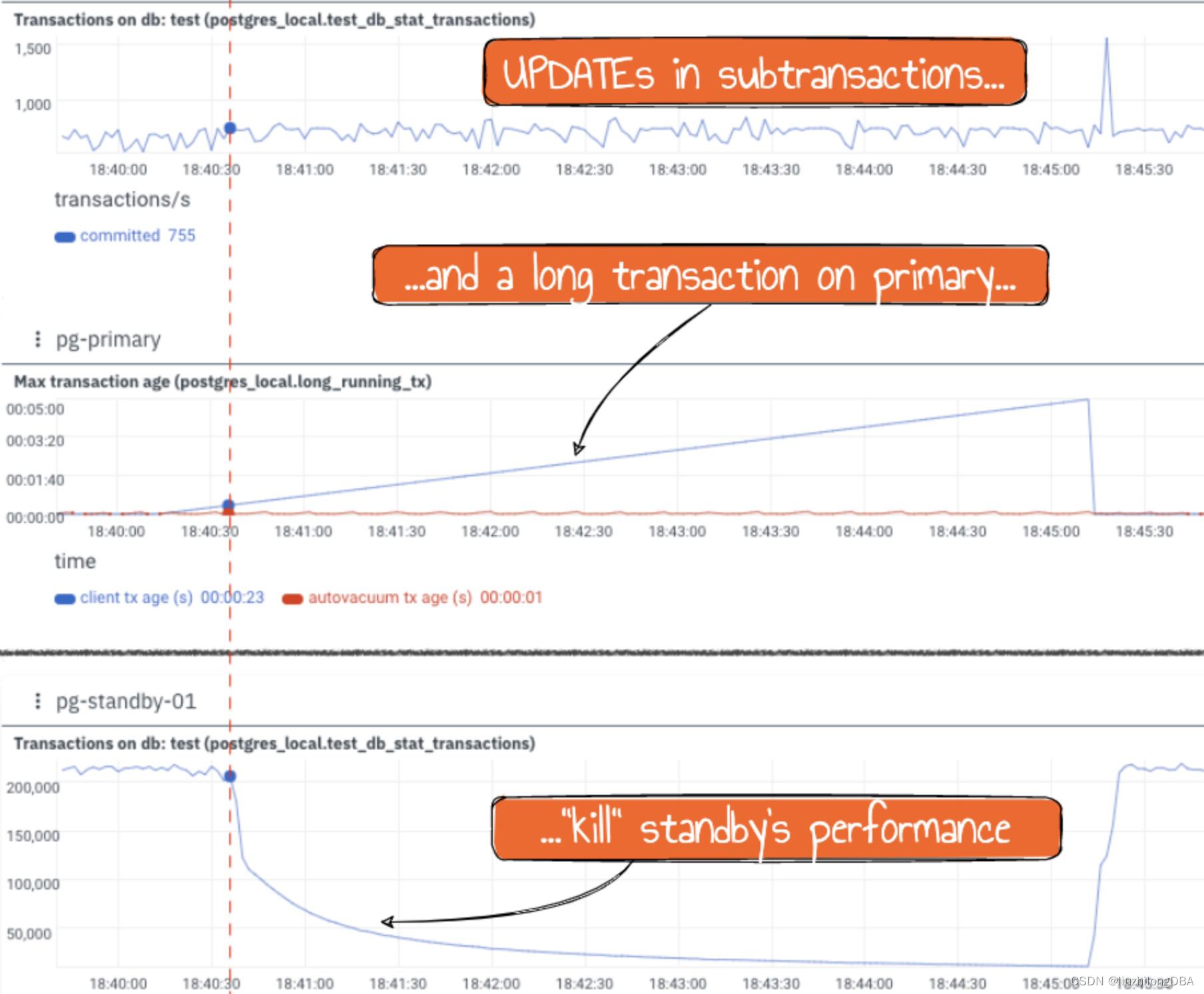
运行时间
为了减小偶然性因素造成的时间差异,对每一个算法重复运行10000次,取平均耗时。
考虑到“枚举排序”所需时间(
O
(
n
2
)
O(n^2)
O(n2))远远长于另外两者,因此“枚举排序”只运行一遍。
时间(毫秒) 快速排序 枚举排序 归并排序
串行 1.6889 2204 3.4941
并行 0.8604 277 1.5046
并行算法实现
快速排序
原始串行快速排序算法中有“分而治之”的递归调用部分,在每次选择pivoit并把序列按照小于pivoIt和大于pivoit分成两类后,左右两部分的递归排序可以并发执行,伪代码如下。
ParallelQucikSort(data, p, r)
q = Partition(data, p, r) // partition会返回pivoit
task[1] = ParallelQuickSort(data, p, q - 1)
task[2] = ParallelQuickSort(data, q + 1, r)
for j = 1 to 2 par-do
task[i]
return data
枚举排序
枚举排序原本会依次对每个元素进行计数的操作,我们可以使这些操作并行化,伪代码如下
ParallelEnumerateSort(data)
sorted_data = new List
for i = 1 to data.length par-do
counter = 0
for j = 1 to data.length do
if data[j] < data[i]
counter = counter + 1
sorted_data[counter+1] = data[i]
return sorted_data
归并排序
归并排序的并行化改进与快速排序类似,都是在“分而治之”分完之后,对两个子任务并行执行,伪代码如下
ParallelMergeSort(data)
if (data.length==1)
return data
else
new_data[1] = data[:data.length/2]
new_data[2] = data[data.length/2:]
for i = 1 to 2 par-do
ParallelMergeSort(new_data[i])
data = MergeData(new_data[1],new_data[2])
return data