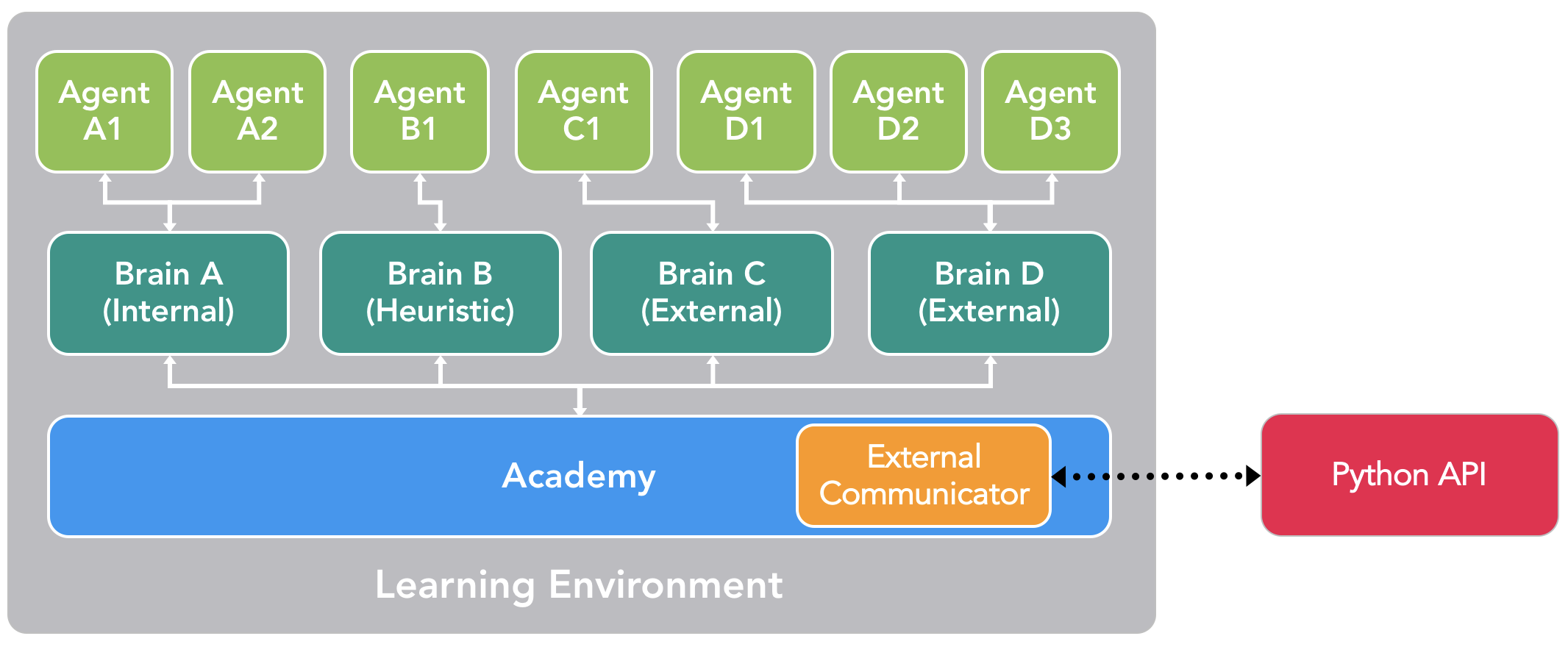
数据准备
# 选择感兴趣的列
mydata <- mtcars %>%
select(mpg, disp, hp, drat, wt, qsec)
# 添加一些缺失值
mydata$hp[3] <- NA
# 检查数据
head(mydata, 3)## mpg disp hp drat wt qsec
## Mazda RX4 21.0 160 110 3.90 2.62 16.5
## Mazda RX4 Wag 21.0 160 110 3.90 2.88 17.0
## Datsun 710 22.8 108 NA 3.85 2.32 18.6
相关视频:复杂网络分析CNA简介与R语言对婚礼数据聚类(社区检测)和可视化|数据分享
复杂网络分析CNA简介与R语言对婚礼数据聚类(社区检测)和可视化
计算相关矩阵
res.cor <- correlate(mydata)
res.cor## # A tibble: 6 x 7
## rowname mpg disp hp drat wt qsec
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 mpg NA -0.848 -0.775 0.681 -0.868 0.419
## 2 disp -0.848 NA 0.786 -0.710 0.888 -0.434
## 3 hp -0.775 0.786 NA -0.443 0.651 -0.706
## 4 drat 0.681 -0.710 -0.443 NA -0.712 0.0912
## 5 wt -0.868 0.888 0.651 -0.712 NA -0.175
## 6 qsec 0.419 -0.434 -0.706 0.0912 -0.175 NA该函数的其他参数correlate()包括:
method:字符串,指示要计算哪个相关系数(或协方差)。“pearson”(默认),“kendall”或“spearman”之一。diagonal:将对角线设置为的值(通常为数字或NA)。
探索相关矩阵
过滤相关性高于0.8:
## # A tibble: 6 x 3
## rowname colname cor
## <chr> <chr> <dbl>
## 1 disp mpg -0.848
## 2 wt mpg -0.868
## 3 mpg disp -0.848
## 4 wt disp 0.888
## 5 mpg wt -0.868
## 6 disp wt 0.888特定的列/行
此函数的作用与dplyr类似slect(),但也会从行中排除选定的列。
- 选择相关的结果。所选列将从行中排除:
## # A tibble: 3 x 4
## rowname mpg disp hp
## <chr> <dbl> <dbl> <dbl>
## 1 drat 0.681 -0.710 -0.443
## 2 wt -0.868 0.888 0.651
## 3 qsec 0.419 -0.434 -0.706- 选定的列:
## # A tibble: 3 x 4
## rowname mpg disp hp
## <chr> <dbl> <dbl> <dbl>
## 1 mpg NA -0.848 -0.775
## 2 disp -0.848 NA 0.786
## 3 hp -0.775 0.786 NA- 删除不需要的列:
## # A tibble: 3 x 4
## rowname drat wt qsec
## <chr> <dbl> <dbl> <dbl>
## 1 mpg 0.681 -0.868 0.419
## 2 disp -0.710 0.888 -0.434
## 3 hp -0.443 0.651 -0.706- 按正则表达式选择列
## # A tibble: 4 x 3
## rowname disp drat
## <chr> <dbl> <dbl>
## 1 mpg -0.848 0.681
## 2 hp 0.786 -0.443
## 3 wt 0.888 -0.712
## 4 qsec -0.434 0.0912- 选择高于0.8的相关性:
## # A tibble: 2 x 3
## rowname disp wt
## <chr> <dbl> <dbl>
## 1 disp NA 0.888
## 2 wt 0.888 NA- 关注一个变量与所有其他变量的相关性:
# 提取相关系数
## # A tibble: 5 x 2
## rowname mpg
## <chr> <dbl>
## 1 disp -0.848
## 2 hp -0.775
## 3 drat 0.681
## 4 wt -0.868
## 5 qsec 0.419# 绘制mpg与其他变量之间的相关性
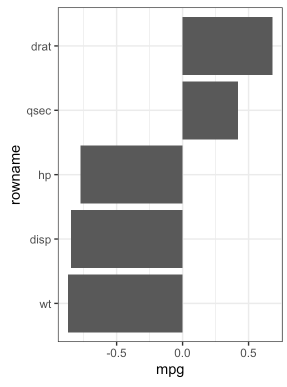
重新排序相关矩阵
## # A tibble: 6 x 7
## rowname wt drat disp mpg hp qsec
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 wt NA -0.712 0.888 -0.868 0.651 -0.175
## 2 drat -0.712 NA -0.710 0.681 -0.443 0.0912
## 3 disp 0.888 -0.710 NA -0.848 0.786 -0.434
## 4 mpg -0.868 0.681 -0.848 NA -0.775 0.419
## 5 hp 0.651 -0.443 0.786 -0.775 NA -0.706
## 6 qsec -0.175 0.0912 -0.434 0.419 -0.706 NA上/下三角
上/下三角形到缺失值
res.cor %>% shave()## # A tibble: 6 x 7
## rowname mpg disp hp drat wt qsec
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 mpg NA NA NA NA NA NA
## 2 disp -0.848 NA NA NA NA NA
## 3 hp -0.775 0.786 NA NA NA NA
## 4 drat 0.681 -0.710 -0.443 NA NA NA
## 5 wt -0.868 0.888 0.651 -0.712 NA NA
## 6 qsec 0.419 -0.434 -0.706 0.0912 -0.175 NA将数据拉伸为长格式
res.cor %>% stretch()## # A tibble: 36 x 3
## x y r
## <chr> <chr> <dbl>
## 1 mpg mpg NA
## 2 mpg disp -0.848
## 3 mpg hp -0.775
## 4 mpg drat 0.681
## 5 mpg wt -0.868
## 6 mpg qsec 0.419
## # … with 30 more rows使用tidyverse和corrr包处理相关性
可视化相关系数的分布:
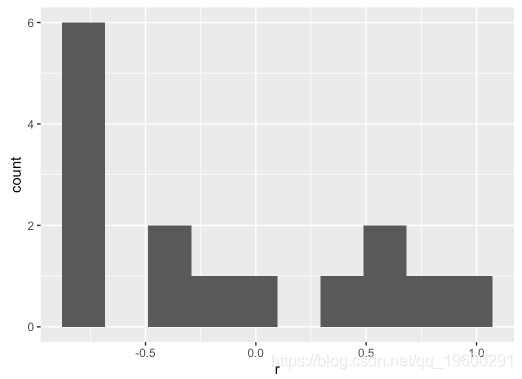
重新排列并过滤相关矩阵:
res.cor %>%
focus(mpg:drat, mirror = TRUE) %>%
## # A tibble: 3 x 4
## rowname mpg disp drat
## <chr> <dbl> <dbl> <dbl>
## 1 hp -0.775 0.786 -0.443
## 2 mpg NA -0.848 0.681
## 3 disp NA NA -0.710解释相关性
## rowname mpg disp hp drat wt qsec
## 1 mpg -.85 -.77 .68 -.87 .42
## 2 disp -.85 .79 -.71 .89 -.43
## 3 hp -.77 .79 -.44 .65 -.71
## 4 drat .68 -.71 -.44 -.71 .09
## 5 wt -.87 .89 .65 -.71 -.17
## 6 qsec .42 -.43 -.71 .09 -.17res.cor %>%
focus(mpg:drat, mirror = TRUE)
## rowname mpg disp drat
## 1 hp -.77 .79 -.44
## 2 mpg -.85 .68
## 3 disp -.71- 制作相关图:
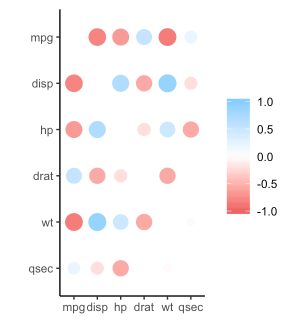
- 重新排列然后绘制下三角形:
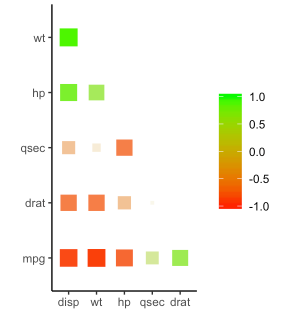
- 制作网络
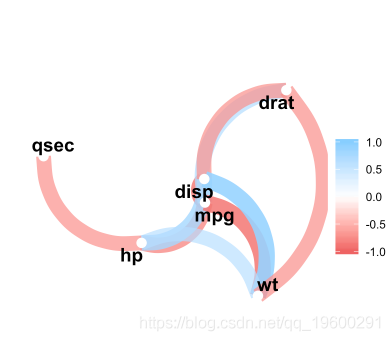
关联数据库中的数据
- 使用SQLite数据库:
con <- DBI::dbConnect(RSQLite::SQLite(), path = ":dbname:")
db_mtcars <- copy_to(con, mtcars)
class(db_mtcars)correlate()检测数据库后端,用于tidyeval计算数据库中的相关性,并返回相关数据。
db_mtcars %>% correlate(use = "complete.obs")- 使用spark:
sc <- sparklyr::spark_connect(master = "local")
mtcars_tbl <- copy_to(sc, mtcars)
correlate(mtcars_tbl, use = "complete.obs")
非常感谢您阅读本文,有任何问题请在下方留言!