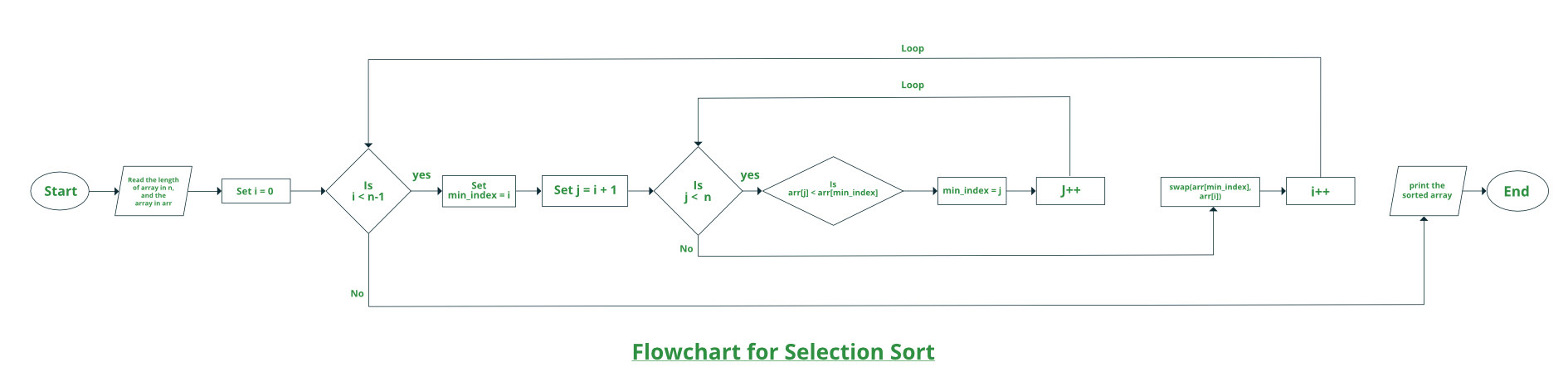
冒泡排序是最简单的排序算法,如果相邻元素的顺序错误,则通过重复交换它们来工作。该算法不适用于大数据集,因为它的平均和最坏情况时间复杂度都很高。
原理

输入: arr[] = {6, 3, 0, 5}
第一步:
冒泡排序从最前面的两个元素开始,比较它们以检查哪个更大。 ( 6 3 0 5 ) –> ( 3 6 0 5 ),这里,算法比较前两个元素,并从 6 > 3 开始交换。 ( 3 6 0 5 ) –> ( 3 0 6 5 ), 从 6 > 0 开始交换 ( 3 0 6 5 ) –> ( 3 0 5 6 ), Swap since 6 > 5 第二步:
现在,在第二次迭代期间,它应该如下所示: ( 3 0 5 6 ) –> ( 0 3 5 6 ), Swap since 3 > 0 ( 0 3 5 6 ) –> ( 0 3 5 6 ), 不变为 5 > 3 第三步:
现在,数组已经排序了,但是我们的算法不知道它是否完成了。
该算法需要一个
完整的传递,而不进行任何交换才能知道它已排序。
( 0 3 5 6 ) –> ( 0 3 5 6 ), 没有变化 3 > 0
数组现在已排序,不会再发生传递。
算法实战
请按照以下步骤解决问题:
-
运行嵌套的 for 循环以使用两个变量 i和 j遍历输入数组,使得 0 ≤ i < n-1 和 0 ≤ j < ni-1 -
如果**arr[j] 大于arr[j+1]**则交换这些相邻元素,否则继续 -
打印排序后的数组
下面是上述方法的实现:
-
Java版本
import java.util.*;
class BubbleSort {
void bubbleSort(int arr[])
{
int n = arr.length;
for (int i = 0; i < n - 1; i++)
for (int j = 0; j < n - i - 1; j++)
if (arr[j] > arr[j + 1]) {
// swap arr[j+1] and arr[j]
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
void printArray(int arr[])
{
int n = arr.length;
for (int i = 0; i < n; ++i)
System.out.print(arr[i] + " ");
System.out.println();
}
public static void main(String args[])
{
BubbleSort ob = new BubbleSort();
int arr[] = { 5, 1, 4, 2, 8 };
ob.bubbleSort(arr);
System.out.println("Sorted array");
ob.printArray(arr);
}
}
输出
排序数组:
1 2 4 5 8
时间复杂度: O(N 2 ) 辅助空间: O(1)
冒泡排序的优化实现:
即使数组已排序,上述函数也始终运行O(N 2 )时间。如果内部循环没有引起任何交换,可以通过停止算法来优化它。
下面是上述方法的实现:
-
Java版本实现
import java.io.*;
class GFG
{
// 冒泡排序的优化版本
static void bubbleSort(int arr[], int n)
{
int i, j, temp;
boolean swapped;
for (i = 0; i < n - 1; i++)
{
swapped = false;
for (j = 0; j < n - i - 1; j++)
{
if (arr[j] > arr[j + 1])
{
// swap arr[j] and arr[j+1]
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
swapped = true;
}
}
// 如果内循环没有交换任何两个元素,那么就跳出循环。
if (swapped == false)
break;
}
}
static void printArray(int arr[], int size)
{
int i;
for (i = 0; i < size; i++)
System.out.print(arr[i] + " ");
System.out.println();
}
public static void main(String args[])
{
int arr[] = { 64, 34, 25, 12, 22, 11, 90 };
int n = arr.length;
bubbleSort(arr, n);
System.out.println("Sorted array: ");
printArray(arr, n);
}
}
输出
排序数组:
11 12 22 25 34 64 90
时间复杂度: O(N 2 ) 辅助空间: O(1)
冒泡排序的最坏情况分析:
冒泡排序的最坏情况发生在数组元素按降序排列时。 在最坏的情况下,对给定数组进行排序所需的迭代或遍历总数为**(n-1)。**其中“n”是数组中存在的元素数量。
在第 1 遍: 比较次数 = (n-1) 交换次数 = (n-1)
在第 2 遍: 比较次数 = (n-2) 交换次数 = (n-2)
在第 3 遍: 比较次数 = (n-3) 交换次数 = (n-3) 。 . . 在第 n-1 次: 比较次数 = 1 交换次数 = 1
现在,计算排序数组所需的比较总数 = (n-1) + (n-2) + (n-3) + 。. . 2 + 1 = (n-1)*(n-1+1)/2 { 用N个自然数求和公式} = n (n-1)/2
对于最坏的情况:
交换总数 = 比较总数 比较 总数(最坏情况)= n(n-1)/2 交换总数(最坏情况)= n(n-1)/2
最坏和平均情况时间复杂度: O(N 2 )。最坏的情况发生在数组被反向排序时。 最佳情况时间复杂度: O(N)。最好的情况发生在数组已经排序时。 辅助空间: O(1)
冒泡排序的递归实现:
这个想法是将最大的元素放在它的位置上,并对所有其他元素继续做同样的事情。
算法:
-
从一组未排序的数字开始 -
定义一个名为“ bubbleSort ”的函数,它将数组和数组的长度作为参数 -
在函数中,创建一个名为“ sorted ”的变量,并将其设置为 true -
创建一个 for 循环,遍历从索引 0开始到数组长度**-1结束的数组** -
在 for 循环中,将当前元素与数组中的下一个元素进行比较 -
如果当前元素大于下一个元素,交换它们的位置并将“ sorted ”设置为false -
for循环后,检查“ sorted ”是否为假 -
如果“ sorted ”为假,以相同的数组和长度作为参数再次调用“ bubbleSort ”函数 -
如果“ sorted ”为真,则数组现在已排序,函数将返回排序后的数组 -
使用初始未排序数组及其长度作为参数调用“ bubbleSort ”函数以开始排序过程。
下面是上述方法的实现:
-
Java版本
import java.util.*;
class GFG
{
public static void main(String[] args) {
int[] ar={5,4,8,2,9,7,3};
bubbleSort(ar,ar.length);
System.out.print("Sorted array : ");
for(int ele:ar)
{
System.out.print(ele+" ");
}
System.out.println();
}
public static void bubbleSort(int[] a,int n)
{
boolean sorted=true;
//我们假设该数组已经排序。
for(int i=0;i<n-1;i++)
{
if(a[i]>a[i+1])
{
int t=a[i];
a[i]=a[i+1];
a[i+1]=t;
sorted=false;
//现在数组没有排序。
}
//如果没有交换,那么我们可以说数组已经排序。
}
if(sorted==false)
{
//递归调用直到它被排序。
bubbleSort(a,n);
}
}
}
输出
排序数组:2 3 4 5 7 8 9
时间复杂度:O (N 2 )
辅助空间:O(1)
冒泡排序的边界情况是什么?
当元素已经排序时,冒泡排序需要最短时间(n 的顺序)。因此最好事先检查数组是否已经排序,以避免 O(N 2 ) 时间复杂度。
排序是否在冒泡排序中发生?
是的,冒泡排序在不使用任何主要数据结构的情况下执行相邻对的交换。因此冒泡排序算法是一种就地算法。
冒泡排序算法稳定吗?
是的,冒泡排序算法是稳定的。
冒泡排序算法用在哪里?
由于其简单性,冒泡排序通常用于介绍排序算法的概念。 在计算机图形学中,它因其能够检测几乎已排序的数组中的微小错误(如仅交换两个元素)并仅以线性 复杂度 (2n) 修复它而广受欢迎。
示例:它用于多边形填充算法,其中边界线按特定扫描线(平行于 x 轴的线)的 x 坐标排序,并且随着 y 的递增,它们的顺序仅发生变化(交换两个元素)在两条线的交叉点(来源:维基百科)
优点:
-
冒泡排序易于理解和实现。 -
它不需要任何额外的内存空间。 -
它对不同类型的数据具有适应性。 -
它是一种稳定的排序算法,意味着具有相同键值的元素在排序后的输出中保持它们的相对顺序。
缺点
-
冒泡排序的时间复杂度为 O(n^2),这使得它对于大型数据集非常慢。 -
它对于大型数据集效率不高,因为它需要多次遍历数据。 -
冒泡排序是一种基于比较的排序算法,这意味着它需要一个比较运算符来确定输入数据集中元素的相对顺序。虽然这不一定是缺点,但在某些情况下它会限制算法的效率。
本文由 mdnice 多平台发布